概念
官方文档:https://kafka.apache.org/
Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用与大数据实时处理领域。
一个分布式的流平台应该包含3点关键的能力:
- 发布和订阅流数据流,类似于消息队列或者是企业消息传递系统
- 以容错的持久化方式存储数据流
-
相关术语
Broker:一台 Kafka 机器就是一个 Broker。一个集群由多个 Broker 组成。一个 Broker 可以容纳多个 Topic。
- Producer: 消息生产者,向 Kafka Broker 发消息的客户端。
- Consumer:消息消费者,从 Kafka Broker 取消息的客户端。
- Consumer Group:消费者组(CG),消费者组内每个消费者负责消费不同分区的数据,提高消费能力。一个分区只能由组内一个消费者消费,消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Topic:可以理解为一个队列,Topic 将消息分类,生产者和消费者面向的是同一个 Topic。
- Partition:为了实现扩展性,提高并发能力,一个非常大的 Topic 可以分布到多个 Broker (即服务器)上,一个 Topic 可以分为多个 Partition,每个 Partition 是一个 有序的队列。
- Replica:副本,为实现备份的功能,保证集群中的某个节点发生故障时,该节点上的 Partition 数据不丢失,且 Kafka 仍然能够继续工作,Kafka 提供了副本机制,一个 Topic 的每个分区都有若干个副本,一个 Leader 和若干个 Follower。
- Offset:消费者消费的位置信息,监控数据消费到什么位置,当消费者挂掉再重新恢复的时候,可以从消费位置继续消费。
Zookeeper:Kafka 集群能够正常工作,需要依赖于 Zookeeper,Zookeeper 帮助 Kafka 存储和管理集群信息。
Kafka架构
Kafka 存储的消息来自任意多被称为 Producer 生产者的进程。数据从而可以被发布到不同的 Topic 主题下的不同 Partition 分区。在一个分区内,这些消息被索引并连同时间戳存储在一起。其它被称为 Consumer 消费者的进程可以从分区订阅消息。Kafka 运行在一个由一台或多台服务器组成的集群上,并且分区可以跨集群结点分布。
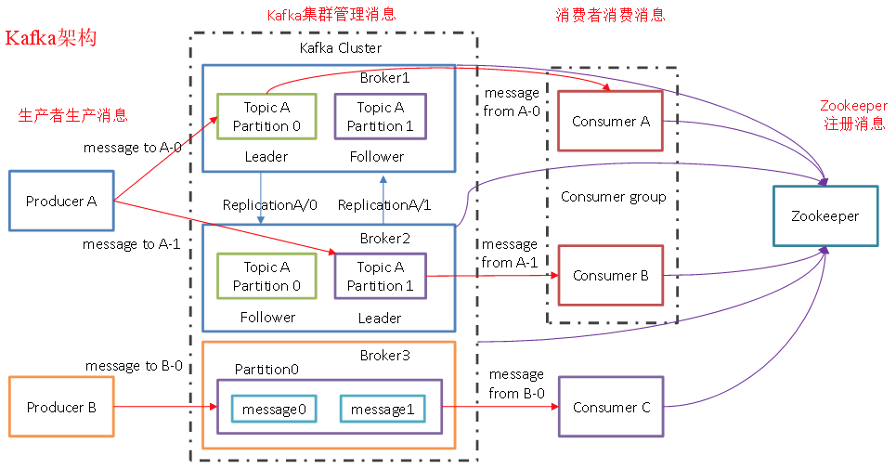
Leader和Follower
Leader:
每个分区多个副本的“主”副本,生产者发送数据的对象,以及消费者消费数据的对象,都是 Leader。Kafka中的leader负责处理读写操作,而follower只负责副本数据的同步
- 如果leader出现故障,其他follower会被重新选举为leader
- Kafka启动时,会在所有的broker中选择一个controller,是针对broker的;创建topic、或者添加分区、修改副本数量之类的管理任务都是由controller完成的;Kafka分区leader的选举,也是由controller决定的
- follower像一个consumer一样,拉取leader对应分区的数据,并保存到日志数据文件中
Follower:
每个分区多个副本的“从”副本,实时从 Leader 中同步数据,保持和 Leader 数据的同步。Leader 发生故障时,某个 Follower 还会成为新的 Leader。
生产者消费者工作流程
数据写入流程
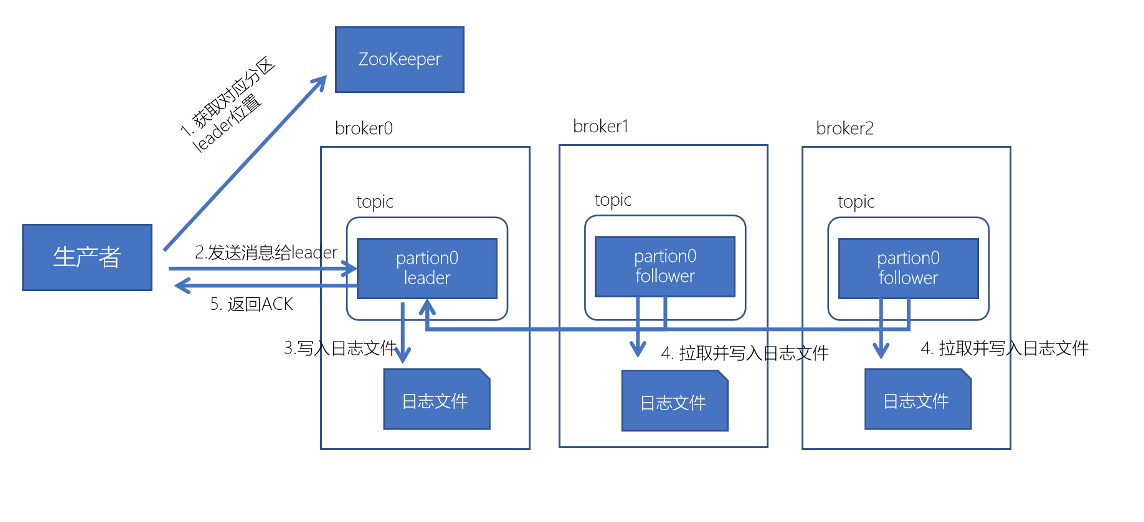
- 生产者先从 zookeeper 的 “/brokers/topics/主题名/partitions/分区名/state”节点找到该 partition 的leader
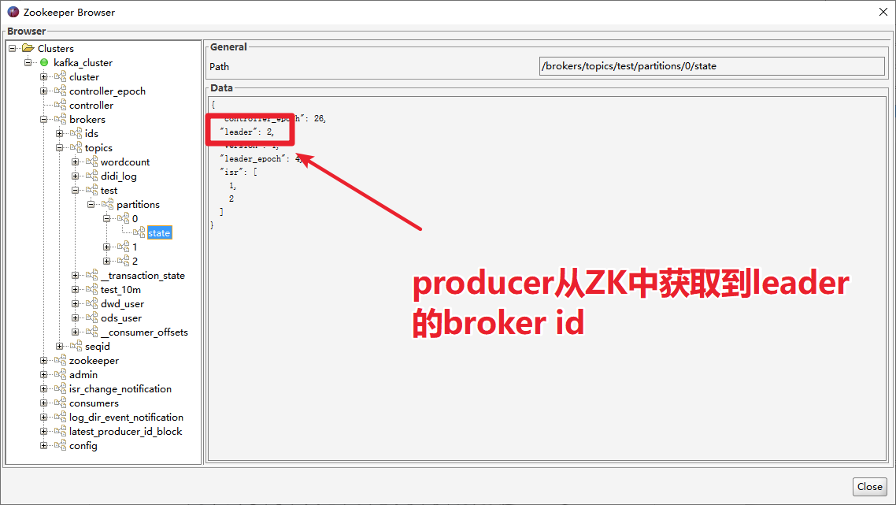
- 生产者在ZK中找到该ID找到对应的broker
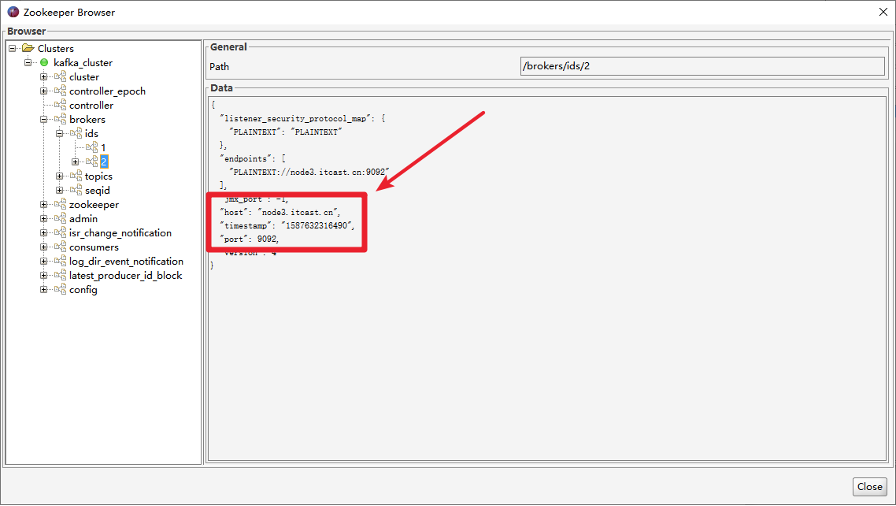
- broker进程上的leader将消息写入到本地log中
- follower从leader上拉取消息,写入到本地log,并向leader发送ACK
leader接收到所有的ISR中的Replica的ACK后,并向生产者返回ACK
数据消费流程
2种消费模式:
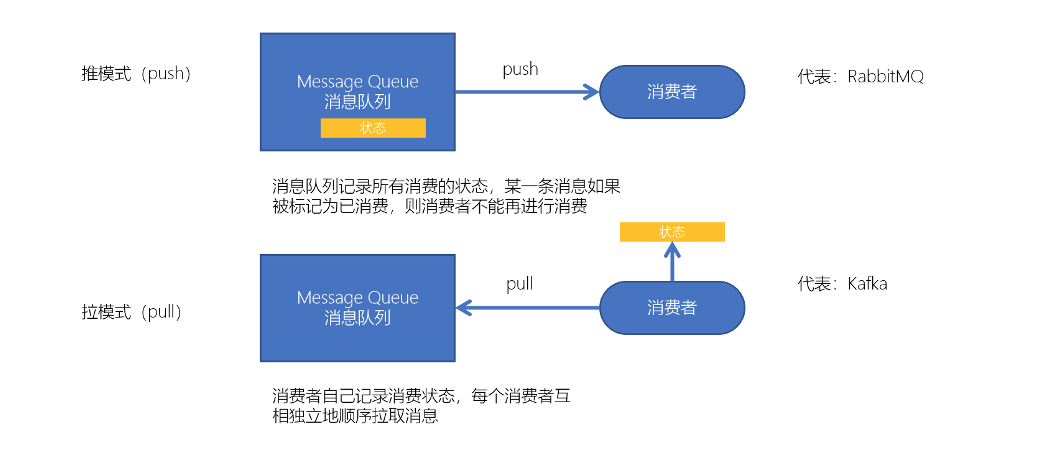
消费流程: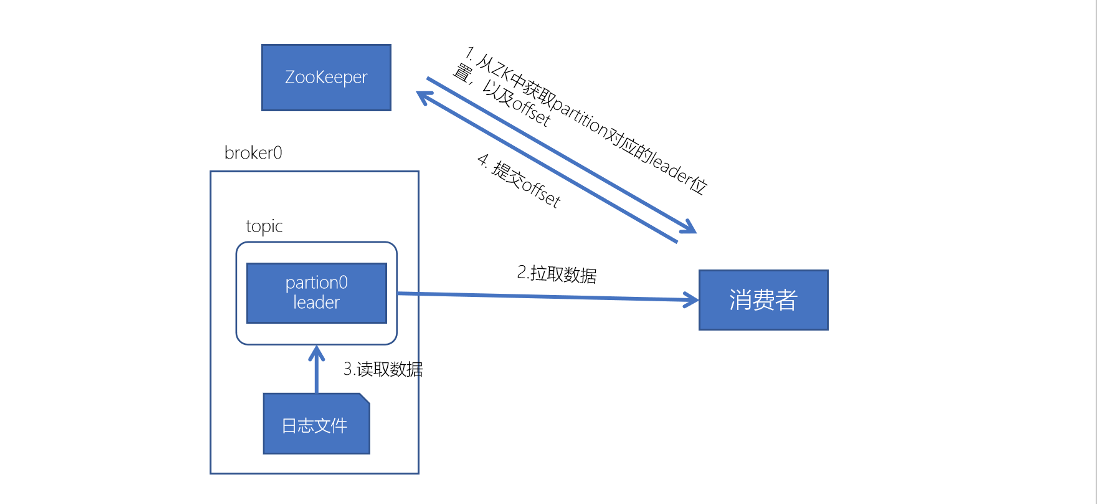
每个consumer都可以根据分配策略(默认RangeAssignor),获得要消费的分区
- 获取到consumer对应的offset(默认从ZK中获取上一次消费的offset)
- 找到该分区的leader,拉取数据
-
分区和副本机制
生产者分区写入策略
生产者写入消息到topic,Kafka将依据不同的策略将数据分配到不同的分区中:
轮询分区策略(默认)
- 随机分区策略(不推荐)
- 按key分区分配策略
按key分配策略,有可能会出现「数据倾斜」,例如:某个key包含了大量的数据,因为key值一样,所有所有的数据将都分配到一个分区中,造成该分区的消息数量远大于其他的分区。 - 自定义分区策略
乱序问题:
轮询策略、随机策略都会导致一个问题,生产到Kafka中的数据是乱序存储的。而按key分区可以一定程度上实现数据有序存储——也就是局部有序,但这又可能会导致数据倾斜,所以在实际生产环境中要结合实际情况来做取舍。
消费者分区分配策略
- Range范围分配策略
ange范围分配策略是Kafka默认的分配策略,它可以确保每个消费者消费的分区数量是均衡的。注意:Rangle范围分配策略是针对每个Topic的。
配置消费者的partition.assignment.strategy为org.apache.kafka.clients.consumer.RangeAssignor。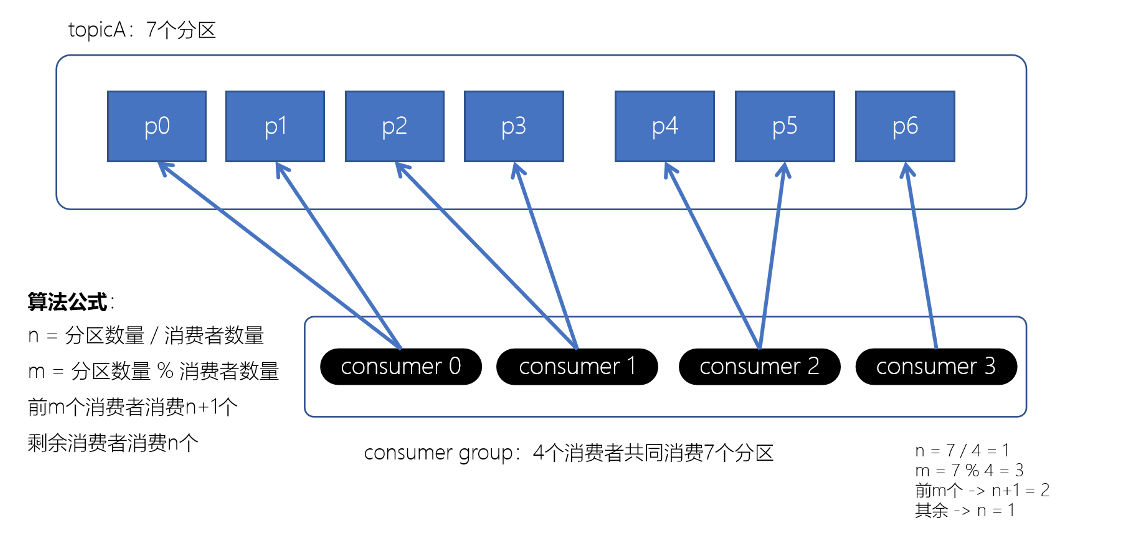
- RoundRobin轮询策略
RoundRobinAssignor轮询策略是将消费组内所有消费者以及消费者所订阅的所有topic的partition按照字典序排序(topic和分区的hashcode进行排序),然后通过轮询方式逐个将分区以此分配给每个消费者。
配置消费者的partition.assignment.strategy为org.apache.kafka.clients.consumer.RoundRobinAssignor。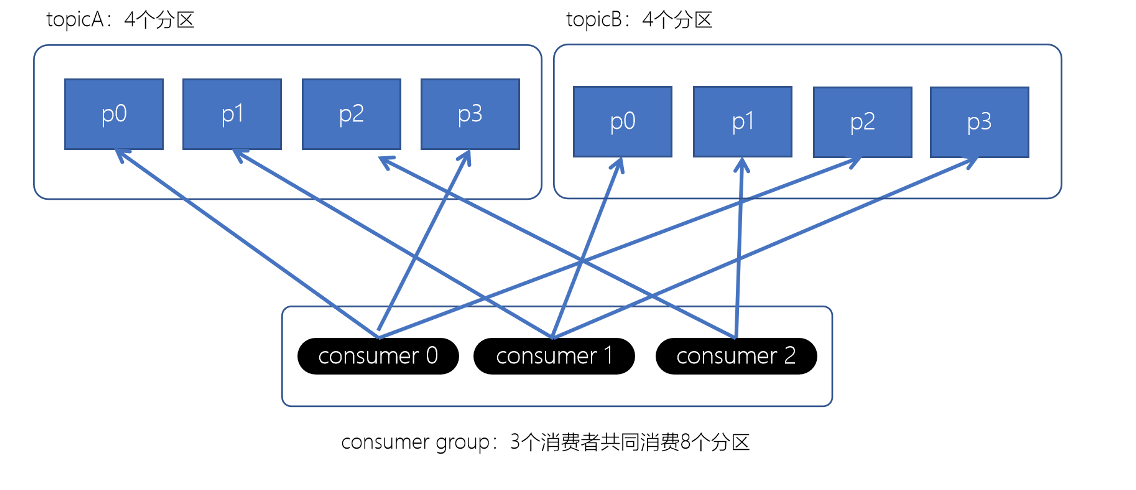
Stricky粘性分配策略
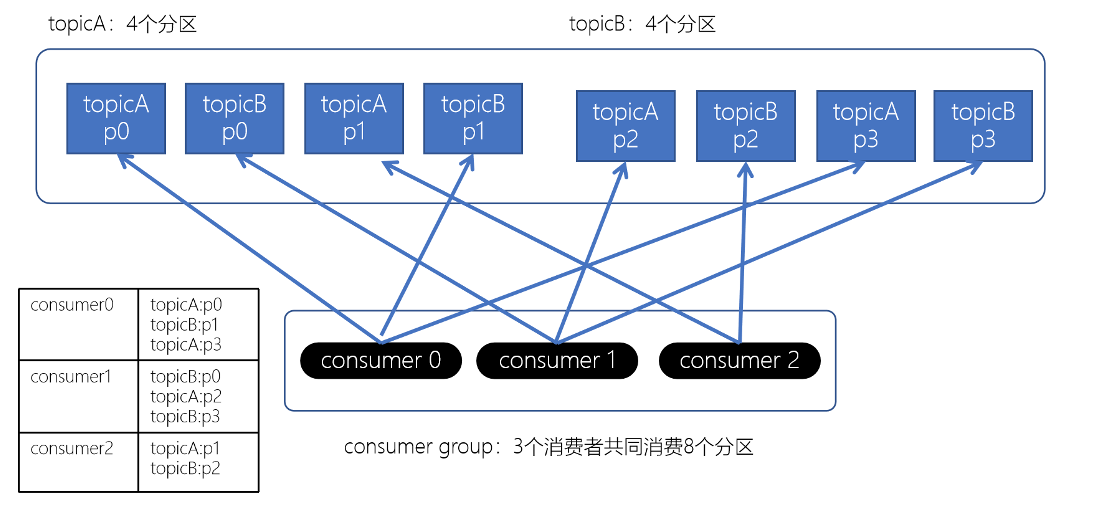

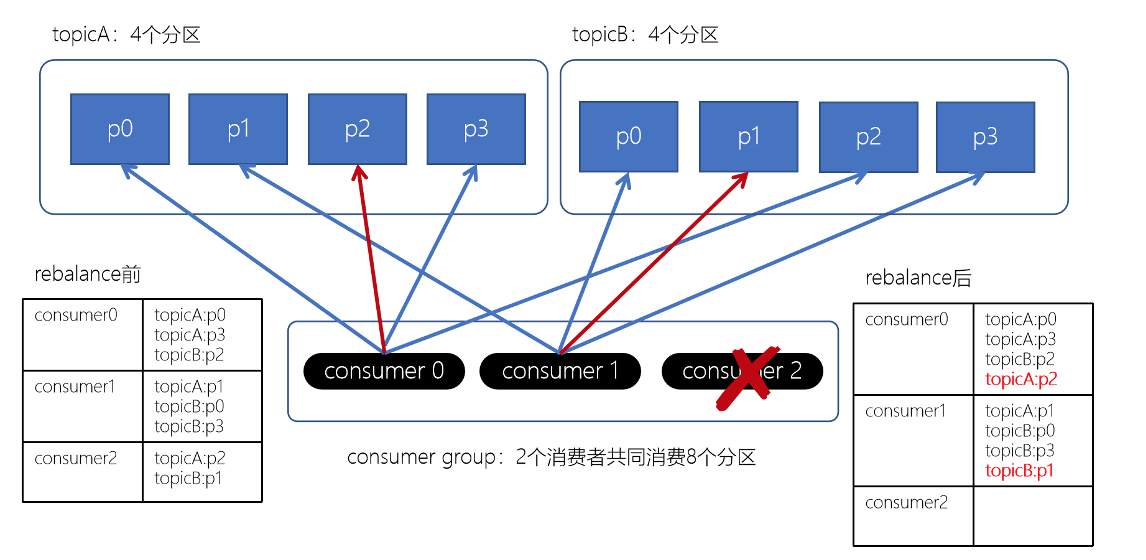
Striky粘性分配策略,保留rebalance之前的分配结果。这样,只是将原先consumer2负责的两个分区再均匀分配给consumer0、consumer1。这样可以明显减少系统资源的浪费消费者组Rebalance机制
Kafka中的Rebalance称之为再均衡,是Kafka中确保Consumer group下所有的consumer如何达成一致,分配订阅的topic的每个分区的机制。
Rebalance触发的时机有:消费者组中consumer的个数发生变化。例如:有新的consumer加入到消费者组,或者是某个consumer停止了。
- 订阅的topic个数发生变化
消费者可以订阅多个主题,假设当前的消费者组订阅了三个主题,但有一个主题突然被删除了,此时也需要发生再均衡。 - 订阅的topic分区数发生变化
注意:发生Rebalance时,consumer group下的所有consumer都会协调在一起共同参与,Kafka使用分配策略尽可能达到最公平的分配;Rebalance过程会对consumer group产生非常严重的影响,Rebalance的过程中所有的消费者都将停止工作,直到Rebalance完成。
副本机制
副本的目的就是冗余备份,当某个Broker上的分区数据丢失时,依然可以保障数据可用。因为在其他的Broker上的副本是可用的。
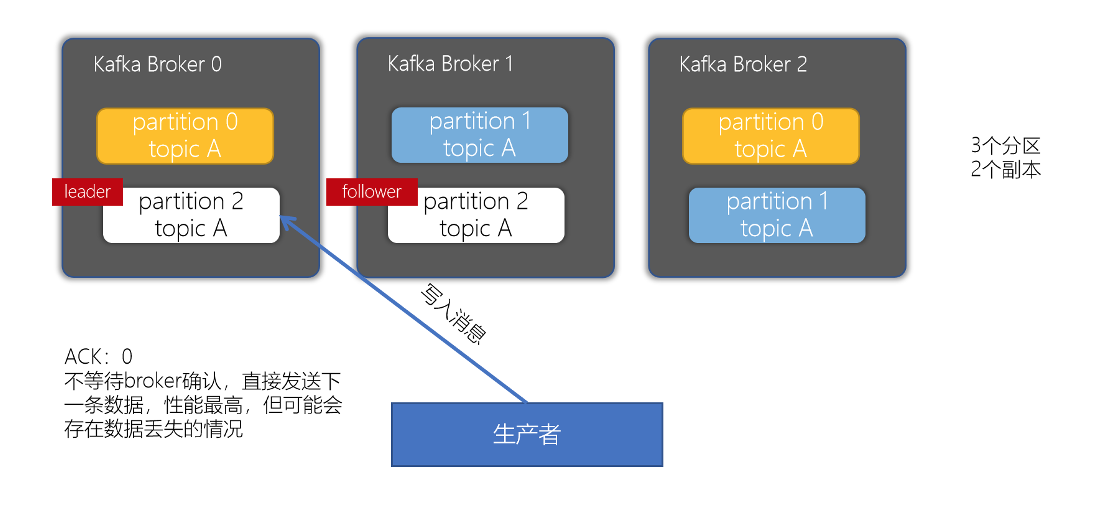
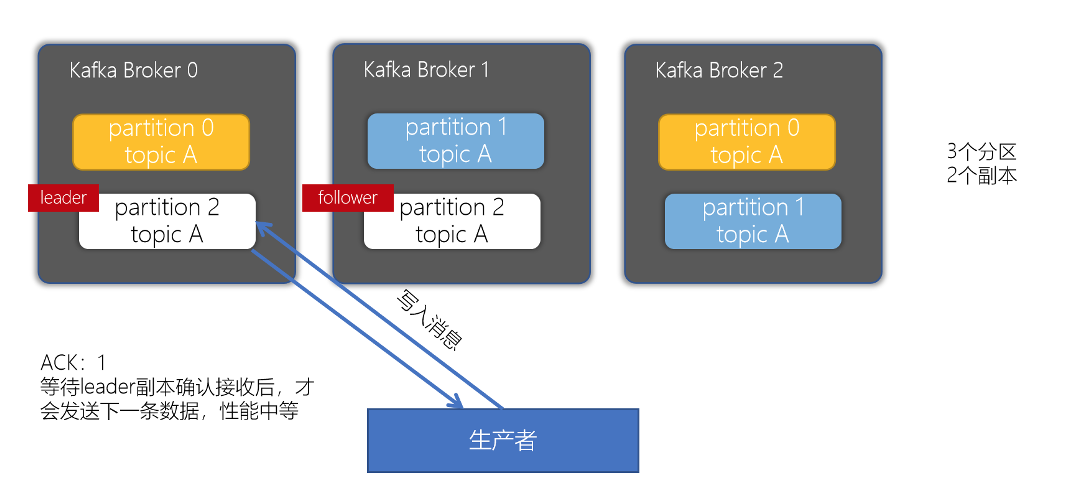
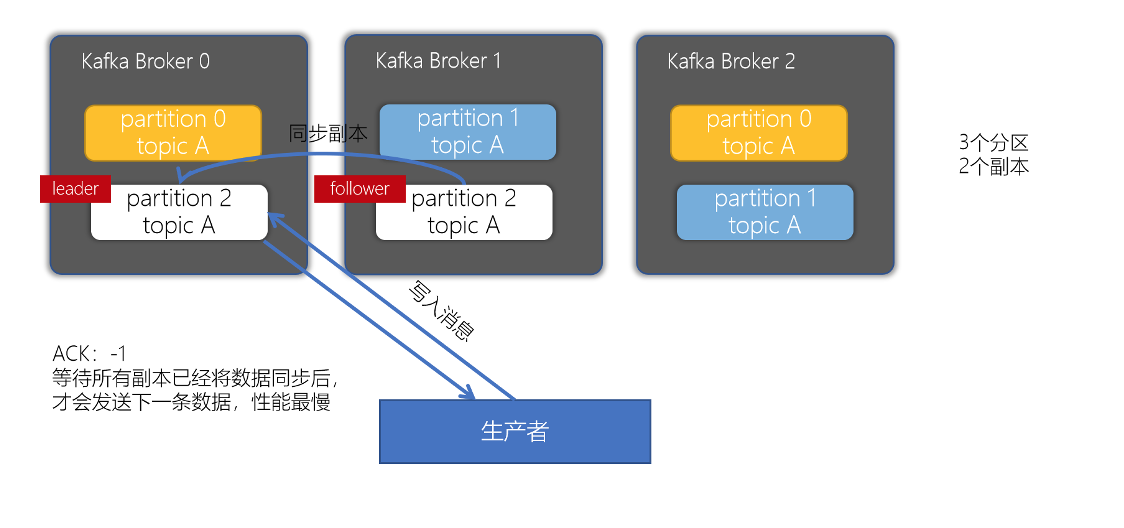
对副本关系较大的就是,producer配置的acks参数了,acks参数表示当生产者生产消息的时候,写入到副本的要求严格程度。它决定了生产者如何在性能和可靠性之间做取舍。
- acks配置为0
- acks配置为1
-
数据存储形式
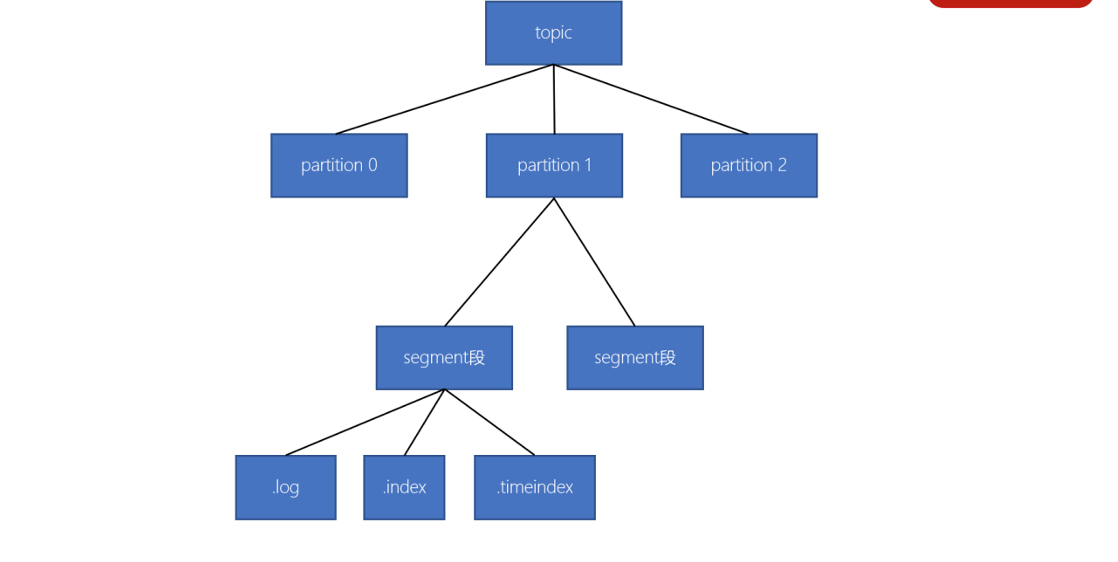
一个topic由多个分区组成
- 一个分区(partition)由多个segment(段)组成
- 一个segment(段)由多个文件组成(log、index、timeindex)
消息存储:
设置segment大小:kafka-topics.sh —create —zookeeper master01 —topic test_10m —replication-factor 2 —partitions 3 —configsegment.bytes=10485760
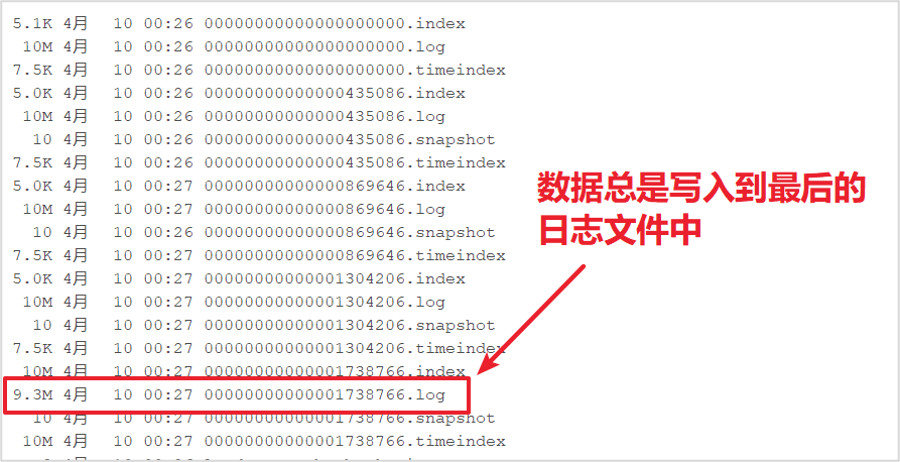
- 新的消息总是写入到最后的一个日志文件中该
- 文件如果到达指定的大小(默认为:1GB)时,将滚动到一个新的文件中
消息读取:
- 根据「offset」首先需要找到存储数据的 segment 段(注意:offset指定分区的全局偏移量)
- 然后根据这个「全局分区offset」找到相对于文件的「segment段offset」
- 最后再根据 「segment段offset」读取消息
- 为了提高查询效率,每个文件都会维护对应的范围内存,查找的时候就是使用简单的二分查找
消息删除:
- 在Kafka中,消息是会被定期清理的。一次删除一个segment段的日志文件
Kafka的日志管理器,会根据Kafka的配置,来决定哪些文件可以被删除
数据不丢失机制
broker数据不丢失
生产者通过分区的leader写入数据后,所有在ISR中follower都会从leader中复制数据,这样,可以确保即使leader崩溃了,其他的follower的数据仍然是可用的
生产者数据不丢失
生产者连接leader写入数据时,可以通过ACK机制来确保数据已经成功写入。ACK机制有三个可选配置:
配置ACK响应要求为 -1时 —— 表示所有的节点都收到数据(leader和follower都接收到数据)
- 配置ACK响应要求为 1 时 —— 表示leader收到数据
- 配置ACK影响要求为 0 时 —— 生产者只负责发送数据,不关心数据是否丢失(这种情况可能会产生数据丢失,但性能是最好的)
说明:如果broker迟迟不给ack,而buffer又满了,开发者可以设置是否直接清空buffer中的数据。
生产者可以采用同步和异步两种方式发送数据
- 同步:发送一批数据给kafka后,等待kafka返回结果
-
消费者数据不丢失
在消费者消费数据的时候,只要每个消费者记录好offset值即可,就能保证数据不丢失。
数据积压
Kafka消费者消费数据的速度是非常快的,但如果由于处理Kafka消息时,由于有一些外部IO、或者是产生网络拥堵,就会造成Kafka中的数据积压(或称为数据堆积)。如果数据一直积压,会导致数据出来的实时性受到较大影响。
数据清理(Log Deletion)
Kafka的消息存储在磁盘中,为了控制磁盘占用空间,Kafka需要不断地对过去的一些消息进行清理工作。Kafka的每个分区都有很多的日志文件,这样也是为了方便进行日志的清理。在Kafka中,提供两种日志清理方式:
日志删除(Log Deletion):按照指定的策略直接删除不符合条件的日志。
- 日志压缩(Log Compaction):按照消息的key进行整合,有相同key的但有不同value值,只保留最后一个版本。
在Kafka的broker或topic配置中:
| 配置项 | 配置值 | 说明 |
|---|---|---|
| log.cleaner.enable | true(默认) | 开启自动清理日志功能 |
| log.cleanup.policy | delete(默认) | 删除日志 |
| log.cleanup.policy | compaction | 压缩日志 |
| log.cleanup.policy | delete,compact | 同时支持删除、压缩 |
如果消息达到一定的条件(时间、日志大小、offset大小),Kafka就会自动将日志设置为待删除(segment端的后缀名会以 .delete结尾),日志管理程序会定期清理这些日志,默认是7天
发布/订阅模式
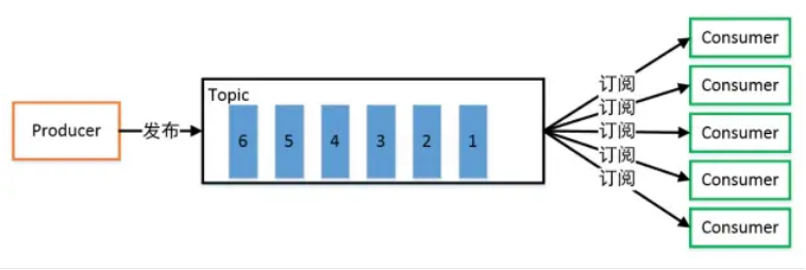
一对多,生产者将消息发布到 Topic 中,有多个消费者订阅该主题,发布到 Topic 的消息会被所有订阅者消费,被消费的数据不会立即从 Topic 清除。
Kafka幂等性
在生产者生产消息时,如果出现retry时,有可能会一条消息被发送了多次,如果Kafka不具备幂等性的,就有可能会在partition中保存多条一模一样的消息。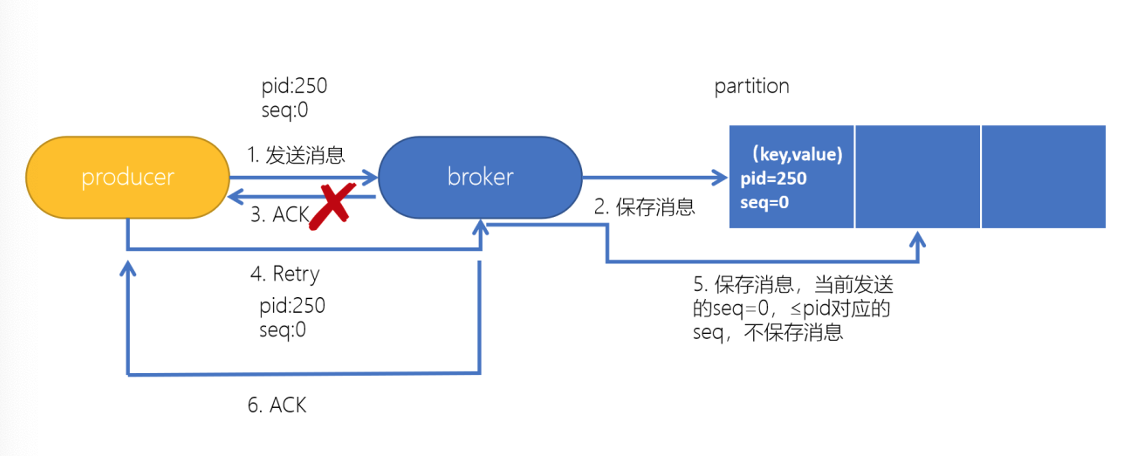
幂等性配置
props.put(“enable.idempotence”,true);
幂等性原理
为了实现生产者的幂等性,Kafka引入了 Producer ID(PID)和 Sequence Number的概念。
- PID:每个Producer在初始化时,都会分配一个唯一的PID,这个PID对用户来说,是透明的。
Sequence Number:针对每个生产者(对应PID)发送到指定主题分区的消息都对应一个从0开始递增的Sequence Number。
Kafka配额限速机制(Quotas)
生产者和消费者以极高的速度生产/消费大量数据或产生请求,从而占用broker上的全部资源,造成网络IO饱和。有了配额(Quotas)就可以避免这些问题。Kafka支持配额管理,从而可以对Producer和Consumer的produce&fetch操作进行流量限制,防止个别业务压爆服务器。
限制producer端速率
bin/kafka-configs.sh —zookeeper node1.itcast.cn:2181 —alter —add-config ‘producer_byte_rate=1048576’ —entity-type clients —entity-default
- 限制consumer端速率
bin/kafka-configs.sh —zookeeper node1.itcast.cn:2181 —alter —add-config ‘consumer_byte_rate=1048576’ —entity-type clients —entity-default
- 取消Kafka的Quota配置
使用以下命令,删除Kafka的Quota配置
| bin/kafka-configs.sh —zookeeper node1.itcast.cn:2181 —alter —delete-config ‘producer_byte_rate’ —entity-type clients —entity-default |
|---|
| bin/kafka-configs.sh —zookeeper node1.itcast.cn:2181 —alter —delete-config ‘consumer_byte_rate’ —entity-type clients —entity-default |

若有收获,就点个赞吧
0 人点赞
