定义
MapReduce是一个分布式运算程序的编程框架,是用户开发”基于Hadoop的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
核心思想
MapReduce思想核心是”分而治之”,适用于大量复杂的任务处理场景。
二阶段:map和reduce是一种阻塞关系
map阶段
Map负责”分”,即把复杂的任务分解为若干个”简单任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
reduce阶段

MapReduce工作机制
- 读取文件,解析成key-value
- 自定义map逻辑接收key-value,转换成为新的key-value,写入环形缓冲区
- 分区:写入环形缓冲区的过程,给每个k-v加上分区Partition index(同一分区数据,将会被发送到同一个reduce)
- 排序:当缓冲区使用80%,开始溢写文件;先按照Partition index排序,相同分区数据汇聚一起;每个分区数据再按key排序
- combiner:调优过程,对数据进行map阶段合并(并不是所以mr都适合combiner)
- 将环形缓冲区的数据溢写到本地磁盘小文件
- 归并排序:本地磁盘小文件进行归并排序
- 等待reduceTask启动线程进行拉取数据
- reduceTask启动线程,从各个mapTask拉取数据自己分区数据
- 从mapTask拉取数据继续进行归并排序
- 进行groupingComparator分组操作
- 调用reduce逻辑,写结果数据
- 通过outputFormat进行数据输出,写入文件,一个reduceTask对应一个结果文件
数据压缩shuffle
比较常用的是:LZ4和Snappy压缩算法
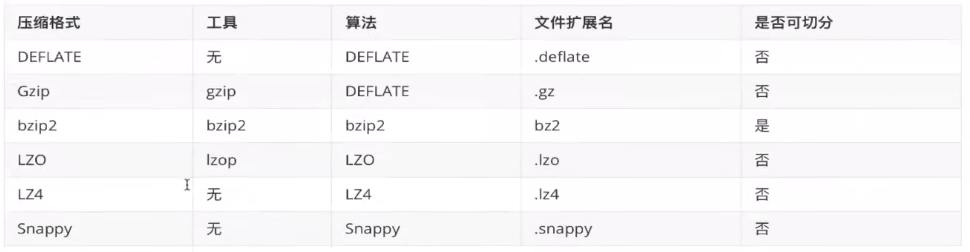
压缩java类
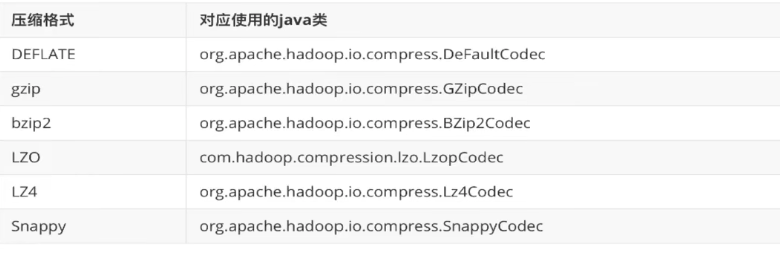
压缩速率比
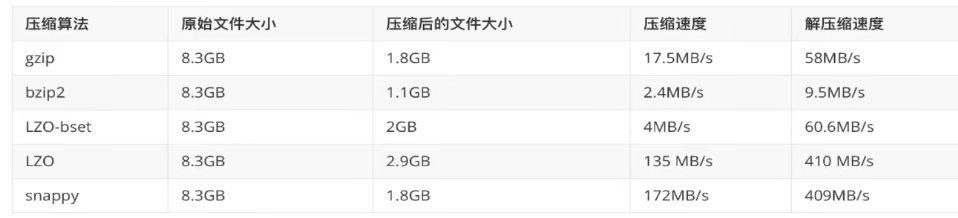
使用方式
编码方式

mapred-site.xml配置
角色(1.x版本,2.x使用yarn)
JobTracker
从hdfs中获取【split清单】;再根据自身收到的TaskTracker汇报的资源,最终确定每一个split对应map节点【确定清单】;未来,TaskTracker根据心跳获取分配的任务信息
- 检查job的input and output
- 计算数据,咨询NameNode元数据Block,得到一个切片的split清单
split是逻辑的,block是物理的,block本身有(offset、locations),而split和block有映射关系(结论:split包含偏移量以及对应map任务的节点locations) - 生成计算程序未来运行的xml配置文件
- 未来移动应该相对可靠
(客户端将jar、split清单、配置xml上传到hdfs目录【默认副本数10】) - 客户端调用JobTracker,通知启动计算程序,并告知文件存放位置
1.x版本带来的三个问题
- 单点故障
- 压力过大
集成【资源管理、任务调度】,二者耦合
弊端:未来新的计算框架不能复用资源管理,同一批资源硬件资源隔离,并不能感知对方,造成资源争抢Block 与 Split 区别
Block
文件上传到HDFS时,文件会被分块,这个是真实物理上的划分。每块的大小可以通过hadoop-default.xml里配置选项进行设置。系统也提供默认大小,Hadoop 1.x中的默认大小为64M,而Hadoop 2.x中的默认大小为128M。每个Block分别存储在多个DataNode上(默认是3个),用于数据备份进而提供数据容错能力和提高可用性。
在很多分布式文件系统中我们都可以看到Block的存在,这种设计的优点是:存储的文件大小可以大于集群中任意一个磁盘的容量。这很好理解,文件被划分到多个Block中存储,对磁盘透明;
- 使用Block抽象而非整个文件作为存储单元,可以极大简化存储子系统的设计。因为Block size是统一的,因此一个节点上可以存储多少Block就是可以推算的;
- Block 非常适合用于数据备份,进而提供数据容错能力和可用性。
- 同样在磁盘中,每个磁盘都有默认的数据块大小,这是磁盘进行数据读/写的最小单位,磁盘块一般为512字节。但是在分布式文件系统中数据块一般远大于磁盘数据块的大小,并且为磁盘块大小的整数倍,例如HDFS Block size默认为64MB。
分布式存储系统中选择大Block size的主要原因是为了最小化寻址开销,使得磁盘传输数据的时间可以明显大于定位这个块所需的时间。然而,在HDFS中Block size也不好设置的过大,这是因为MapReduce中的map任务通常一次处理一个块中的数据,因此如果Block太大,则map数就会减少,作业运行的并行度就会受到影响,速度就会较慢。
Split
split 是逻辑意义上的split。 通常在 M/R 程序或者其他数据处理技术上用到。根据你处理的数据量的情况,split size是允许用户自定义的。
split size 定义好了之后,可以控制 M/R 中 Mapper 的数量。如果M/R中没有定义split size,就用默认的HDFS配置作为 input split。
输入分片(Input Split):在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split),每个输入分片(input split)针对一个map任务,输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组。
InputSplit是MapReduce对文件进行处理和运算的输入单位,只是一个逻辑概念,每个InputSplit并没有对文件实际的切割,只是记录了要处理的数据的位置(包括文件的path和hosts)和长度(由start和length决定)
通常一个split就是一个block(FileInputFormat仅仅拆分比block大的文件),这样做的好处是使得Map可以在存储有当前数据的节点上运行本地的任务,而不需要通过网络进行跨节点的任务调度。总结
block是物理上的数据分割,而split是逻辑上的分割
- 如果没有特别指定,split size就等于 HDFS 的 block size
- MapReduce可自定义split size
一个split可以包含多个blocks,也可以把一个block应用多个split操作
对于一个记录行形式的文本,会不会造成一行记录被分到两个Block当中?或者一行记录被分成两个InputSplit?
查看源码:org.apache.hadoop.mapred.FileInputFormat
public InputSplit[] getSplits(JobConf job, int numSplits)throws IOException {FileStatus[] files = listStatus(job);// Save the number of input files for metrics/loadgenjob.setLong(NUM_INPUT_FILES, files.length);long totalSize = 0; // compute total sizefor (FileStatus file: files) { // check we have valid filesif (file.isDirectory()) {throw new IOException("Not a file: "+ file.getPath());}totalSize += file.getLen();}long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);// generate splitsArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits);NetworkTopology clusterMap = new NetworkTopology();for (FileStatus file: files) {Path path = file.getPath();FileSystem fs = path.getFileSystem(job);long length = file.getLen();BlockLocation[] blkLocations = fs.getFileBlockLocations(file, 0, length);if ((length != 0) && isSplitable(fs, path)) {long blockSize = file.getBlockSize();long splitSize = computeSplitSize(goalSize, minSize, blockSize);long bytesRemaining = length;while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {String[] splitHosts = getSplitHosts(blkLocations,length-bytesRemaining, splitSize, clusterMap);splits.add(makeSplit(path, length-bytesRemaining, splitSize,splitHosts));bytesRemaining -= splitSize;}if (bytesRemaining != 0) {splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,blkLocations[blkLocations.length-1].getHosts()));}} else if (length != 0) {String[] splitHosts = getSplitHosts(blkLocations,0,length,clusterMap);splits.add(makeSplit(path, 0, length, splitHosts));} else {//Create empty hosts array for zero length filessplits.add(makeSplit(path, 0, length, new String[0]));}}LOG.debug("Total # of splits: " + splits.size());return splits.toArray(new FileSplit[splits.size()]);}
org.apache.hadoop.mapred.TextInputFormat
public RecordReader<LongWritable, Text> getRecordReader( InputSplit genericSplit, JobConf job, Reporter reporter) throws IOException { reporter.setStatus(genericSplit.toString()); return new LineRecordReader(job, (FileSplit) genericSplit); }org.apache.hadoop.mapred.LineRecordReader
/** Read a line. */ public synchronized boolean next(LongWritable key, Text value) throws IOException { // We always read one extra line, which lies outside the upper // split limit i.e. (end - 1) while (getFilePosition() <= end) { key.set(pos); int newSize = in.readLine(value, maxLineLength, Math.max(maxBytesToConsume(pos), maxLineLength)); if (newSize == 0) { return false; } pos += newSize; if (newSize < maxLineLength) { return true; } // line too long. try again LOG.info("Skipped line of size " + newSize + " at pos " + (pos - newSize)); } return false; }结论:
获取文件在HDFS上的路径和Block信息,然后根据splitSize对文件进行切分,splitSize = computeSplitSize(goalSize, minSize, blockSize);goalSize,minSize,blockSize都可以配置
- FileInputFormat对文件的切分是严格按照偏移量来的,因此一行记录比较长的话,可能被切分到不同的InputSplit。 但这并不会对Map造成影响,尽管一行记录可能被拆分到不同的InputSplit,但是与FileInputFormat关联的RecordReader被设计的足够健壮,当一行记录跨InputSplit时,其能够到读取不同的InputSplit,直到把这一行记录读取完成 。
- 对于跨InputSplit的行,LineRecordReader会自动跨InputSplit去读取
- 如果不是first split,则会丢弃第一个record,避免了重复读取的问题

若有收获,就点个赞吧
0 人点赞
