一 GCN做了什么
首先,我们得知道GCN要做什么,现在我们是对CNN网络比较熟悉了,那么在图中加入卷积会做什么呢?这篇博客给了一张图: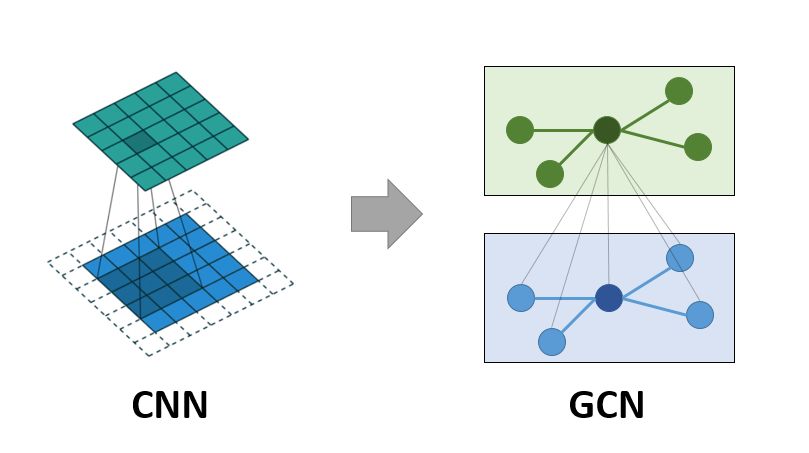
图1. CNN和GCN的对比
通过上面的PyT消息传递网络中的公式(1),我们可以知道某个节点 第
第 层的状态是由
层的状态是由 层的
层的 的状态和其邻边节点
的状态和其邻边节点 的状态通过一些列函数得到的,这个过程对应的就是上图1的GCN
的状态通过一些列函数得到的,这个过程对应的就是上图1的GCN
接下来,就看一下PyT是怎么实现这个过程的:博客原文链接
二 API接口
我们首先调用一下PyT给我们的函数,看看其输入和输出长什么样子
from torch_geometric.nn import GCNConvimport torch# 定义网络conv = GCNConv(1, 2) # emb(in), emb(out)# 定义边edge_index = torch.tensor([[1, 2, 3],[0, 0, 0]], dtype=torch.long) # 2 x E# 定义输入特征向量x = torch.tensor([[1], [1], [1], [1]], dtype=torch.float) # N x emb(in)# 输入网络x = conv(x, edge_index)print(x)
tensor([[0.4282, 2.2683], [0.2447, 1.2962], [0.2447, 1.2962], [0.2447, 1.2962]], grad_fn=
)
可以看到,我们输入的特征向量的长度为1,输出的向量长度的特征为2,为什么特征向量的长度发生了改变?
三 消息传递过程
这一部分和PyT消息传递网络部分相似,只不过这里是具体针对GCN的实现。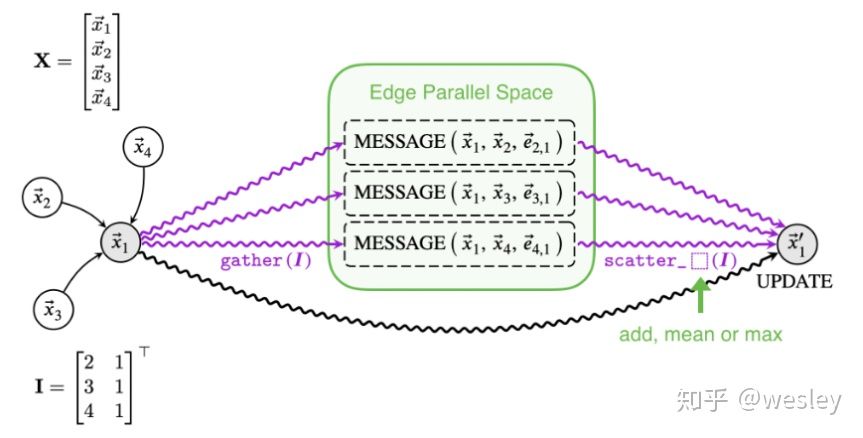
图2. 节点和节点消息传递过程
这个消息传递的过程是PyTorch Geometric中的内置代码的所实现的过程,首先是针对中心节点 和其邻边节点
和其邻边节点 ,通过消息传递机制传递它们的信息,之后通过不同的聚合方式将每个邻边节点得到的特征联合起来。
,通过消息传递机制传递它们的信息,之后通过不同的聚合方式将每个邻边节点得到的特征联合起来。
图2中的左半部分对应的是下面的公式2:
我们的邻边矩阵的特征首先通过一个权重矩阵 进行改变,就类似于线性变换层的操作一样,所以我们的输出的维度
进行改变,就类似于线性变换层的操作一样,所以我们的输出的维度out_channels会发生改变:
之后通过度degree进行归一化,然后再进行整合。
现在使用矩阵的变化形式来描述整个过程:
其中的 表示带有自循环(
表示带有自循环( )的邻接矩阵,其中的
)的邻接矩阵,其中的 表示度矩阵(用于归一化)
表示度矩阵(用于归一化)
四 PyT的GCN过程
1. 初始化参数
首先是初始化相关的参数
# 做类似于Linear层的操作,改变输出的维度self.weight = torch.nn.Parameter(torch.Tensor(in_channels, out_channels))# 添加最后Update部分的biasself.bias = torch.nn.Parameter(torch.Tensor(out_channels))
2. 改变输出维度
我们在上述调用API接口时候,可以看到输出变为2,所以这里我们将它手动实现,看看它是怎么改变的
# N x emb(out) = N x emb(in) @ emb(in) x emb(out)x = torch.matmul(x, self.weight)
3. 实现自循环邻接矩阵
def add_self_loops(edge_index, num_nodes=None):loop_index = torch.arange(0, num_nodes, dtype=torch.long,device=edge_index.device)loop_index = loop_index.unsqueeze(0).repeat(2, 1)edge_index = torch.cat([edge_index, loop_index], dim=1)return edge_indexedge_index = add_self_loops(edge_index, x.size(0)) # 2 x (E+N)
4. 计算归一化
现在实现通过degree矩阵实现归一化:
edge_weight = torch.ones((edge_index.size(1),),dtype=x.dtype,device=edge_index.device) # [E+N]row, col = edge_index # [E+N], [E+N]deg = scatter_add(edge_weight, row, dim=0, dim_size=x.size(0)) # [N]deg_inv_sqrt = deg.pow(-0.5) # [N]deg_inv_sqrt[deg_inv_sqrt == float('inf')] = 0 # [N] #same to use masked_fill_norm = deg_inv_sqrt[row] * edge_weight * deg_inv_sqrt[col] # [E+N]
5. 节点消息传播
计算完上述的矩阵以后,就需要将这一层的节点消息传递到下一层
self.propagate(edge_index, x=x, norm=norm) # 2 x (E+N), 4 x emb(out), [E+N]
之后,归一化节点的特征:
def message(self, x_j, norm):return norm.view(-1, 1) * x_j
之后,将得到的特征进行聚合,在PyT中,使用的是scatter函数,这个函数重新写一篇来看一下PyT中的scatter函数是怎么实现聚合的。
6. Update层
在图2中,我们可以看到最后有一个Update,就是对整合好的邻边节点的特征是否添加bias
def update(self, aggr_out):if self.bias is not None:return aggr_out + self.biaselse:return aggr_out
五 自写GCN的实现
将四中的6个步骤写成一个类
import torchfrom torch_scatter import scatter_addfrom torch_geometric.nn import MessagePassingimport mathdef glorot(tensor):if tensor is not None:stdv = math.sqrt(6.0 / (tensor.size(-2) + tensor.size(-1)))tensor.data.uniform_(-stdv, stdv)def zeros(tensor):if tensor is not None:tensor.data.fill_(0)def add_self_loops(edge_index, num_nodes=None):print("Begin self_loops")loop_index = torch.arange(0, num_nodes, dtype=torch.long,device=edge_index.device)print(loop_index)loop_index = loop_index.unsqueeze(0).repeat(2, 1)print(loop_index)edge_index = torch.cat([edge_index, loop_index], dim=1)print(edge_index)print("End self_loops")return edge_indexclass GCNConv(MessagePassing):def __init__(self, in_channels, out_channels, bias=True):super(GCNConv, self).__init__(aggr='add') # "Add" aggregation.# super(GCNConv, self).__init__(aggr='max') # "Max" aggregation.self.weight = torch.nn.Parameter(torch.Tensor(in_channels, out_channels))if bias:self.bias = torch.nn.Parameter(torch.Tensor(out_channels))else:self.register_parameter('bias', None)self.reset_parameters()def reset_parameters(self):glorot(self.weight)zeros(self.bias)def forward(self, x, edge_index):# 1. Linearly transform node feature matrix (XΘ)x = torch.matmul(x, self.weight) # N x emb(out) = N x emb(in) @ emb(in) x emb(out)print('x', x)# 2. Add self-loops to the adjacency matrix (A' = A + I)edge_index = add_self_loops(edge_index, x.size(0)) # 2 x (E+N)print('edge_index', edge_index)# 3. Compute normalization ( D^(-0.5) A D^(-0.5) )edge_weight = torch.ones((edge_index.size(1),),dtype=x.dtype,device=edge_index.device) # [E+N]print('edge_weight', edge_weight)row, col = edge_index # [E+N], [E+N]print("row", row)print("col", col)deg = scatter_add(edge_weight, row, dim=0, dim_size=x.size(0)) # [N]print("deg", deg)deg_inv_sqrt = deg.pow(-0.5) # [N]deg_inv_sqrt[deg_inv_sqrt == float('inf')] = 0 # [N] # same to use masked_fill_norm = deg_inv_sqrt[row] * edge_weight * deg_inv_sqrt[col] # [E+N]print('norm', norm)# 4. Start propagating messagesreturn self.propagate(edge_index, x=x, norm=norm) # 2 x (E+N), N x emb(out), [E+N]def message(self, x_j, norm): # 4.1 Normalize node features.# x_j: after linear x and expand edge (N+E) x emb(out) = N x emb(in) @ emb(in) x emb(out) (+) E x emb(out)print('x_j', x_j)print('norm', norm)print(f'Norm*x_j: {norm.view(-1, 1) * x_j}')return norm.view(-1, 1) * x_j # (N+E) x emb(out)# return: each row is norm(embedding) vector for each edge_index pairdef update(self, aggr_out): # 4.2 Return node embeddingsprint('aggr_out', aggr_out) # N x emb(out)# for Node 0: Based on the directed graph, Node 0 gets message from three edges and one self_loop# for Node 1, 2, 3: since they do not get any message from others, so only self_loopif self.bias is not None:return aggr_out + self.biaselse:return aggr_outtorch.manual_seed(0)edge_index = torch.tensor([[1, 2, 3], [0, 0, 0]], dtype=torch.long) # 2 x Ex = torch.tensor([[1], [1], [1], [1]], dtype=torch.float) # N x emb(in)print('x', x)print('edge_index', edge_index)# from 1 dim -> 2 dimconv = GCNConv(1, 2) # emb(in), emb(out)# forwardx = conv(x, edge_index)print(x) # N x emb(out) =aggr_out
六 原文链接

若有收获,就点个赞吧
0 人点赞
