原文链接
本示例说明如何使用长短期记忆(LSTM)网络对序列进行分类。
要训练深度神经网络对数据进行分类,可以使用LSTM网络。LSTM网络可以将序列数据输入网络,并根据序列数据的各个时间步长进行预测。
本示例使用[1]和[2]所述的日语元音数据集,此示例训练LSTM网络以识别给定时间序列数据的说话者,该时间序列数据表示连续讲话的两个日语元音。训练数据包含九位发言人的时间序列数据。每个序列具有12个特征,并且长度不同。数据集包含270个训练观察和370个测试观察数据集。
加载序列数据
加载日语元音训练数据。XTrain是包含长度可变的维度12的270个序列的单元数组。Y是标签’1’, ‘2’, …, ‘9’的分类向量,分别对应于9个扬声器。XTrain是具有12行(每个要素一行)和不同列数(每个时间步长一列)的矩阵。
[XTrain, YTrain] = japaneseVowelsTrainData;XTrain(1:5)
ans=5×1 cell array {12×20 double} {12×26 double} {12×22 double} {12×20 double} {12×21 double}
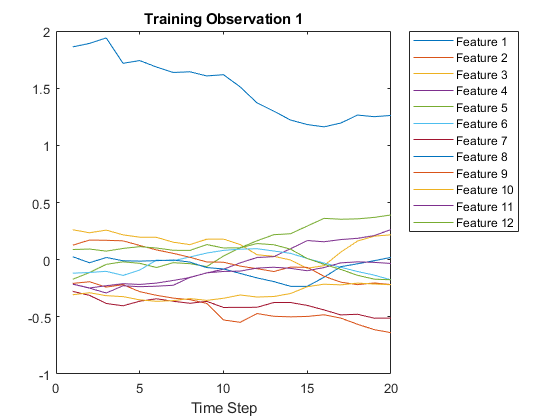
在图中可视化第一段时间序列,每一条线对应一个特征。
figureplot(XTrain{1}');xlabel('Time Step');title('Training Observation 1');numFeatures = size(XTrain{1}, 1);legend('Feature' + string(1:numFeatures), 'Location', 'northeastoutside');
准备用于填充的数据
默认在训练阶段,将训练数据分割成小批量数据然后填充数据使得它们有得同样的长度,但是如果填充的数据太多的话会对使得整个网络表现得不太好。
为了防止在训练过程中填充过多的数据,可以通过序列长度来对训练数据集进行排序,然后选择小批量数据的大小使得小批量有相似的长度。下面这张图展示了我们原来填充序列和对数据集进行排序后所产生的影响: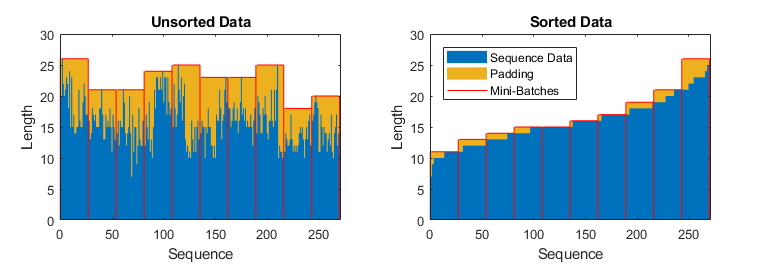
图2. 对数据排序前和排序后的结果影响
得到每个真实值的序列长度
numObservations = numel(XTrain);for i = 1:numObservationssequence = XTrain{i};sequenceLengths{i} = size(sequence, 2);end
根据序列长度进行分类
[sequenceLengths, idx] = sort(sequenceLengths);XTrain = XTrain(idx);YTrain = YTrain(idx);
将排好序的序列长度在条形图中展示
figurebar(sequenceLengths)ylim([0 30])xlabel("Sequence")ylabel("Length")title("Sorted Data")
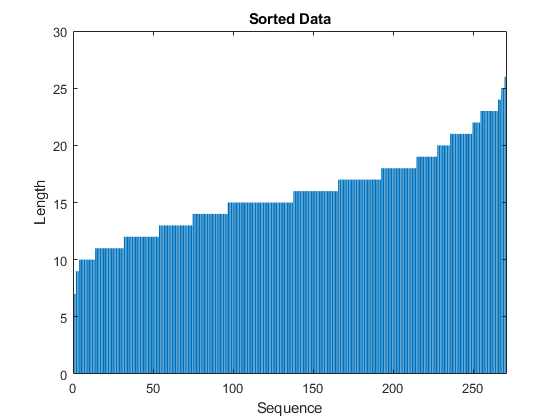
图3. 序列长度
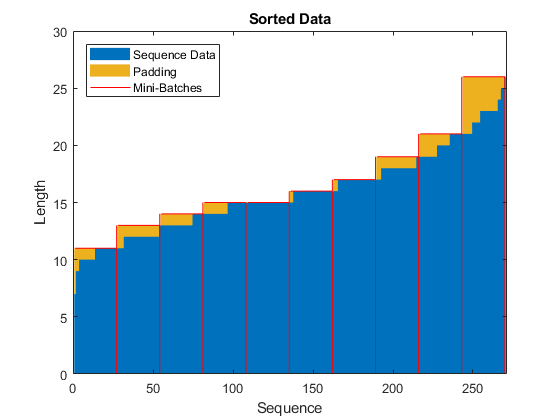
选择大小长度为27的将训练数据均衡地分开,然后能够减少每批数据的填充数据量,下面这张图展示了我们添加给序列的填充量。
miniBatchSize = 27;
定义LSTM网络结构
输入层大小为12(因为输入数据的特征维度为12)->100个隐藏层->9个全连接层->softmax层->分类层。
如果可以在预测时访问完整序列,则可以在网络中使用双向LSTM层。 双向LSTM层在每个时间步都从完整序列中学习。 例如,如果您无法在预测时访问整个序列,则例如,在预测值或一次预测一个时间步长时,请改用LSTM层。
定义网络大小
inputSize = 12;numHiddenUnits = 100;numClasses = 9;layers = [ ...sequenceInputLayer(inputSize)bilstmLayer(numHiddenUnits,'OutputMode','last')fullyConnectedLayer(numClasses)softmaxLayerclassificationLayer]
layers = 5×1 Layer array with layers:
1 '' Sequence Input Sequence input with 12 dimensions2 '' BiLSTM BiLSTM with 100 hidden units3 '' Fully Connected 9 fully connected layer4 '' Softmax softmax5 '' Classification Output crossentropyex
定义网络参数
现在,确认训练过程中的参数。确定求解的方法为’adam’,梯度阈值为1,每个epochs的最大数量为100。为了防止填充过量,设定每个小批量数据的大小为27.要将数据填充到和最长的序列一样的长度,确认序列的长度为’longest’。不要打乱数据,这样能够保证数据是通过序列长度来进行分类的。
maxEpochs = 100;miniBatchSize = 27;options = trainingOptions('adam', ...'ExecutionEnvironment','cpu', ...'GradientThreshold',1, ...'MaxEpochs',maxEpochs, ...'MiniBatchSize',miniBatchSize, ...'SequenceLength','longest', ...'Shuffle','never', ...'Verbose',0, ...'Plots','training-progress');
训练LSTM网络
通过 trainNetwork函数来训练LSTM网络
net = trainNetwork(XTrain, YTrain, layers, options);
测试LSTM网络
加载测试集,然后进行分类。XTest是一个元胞数组,包含370个维度大小为12的序列,每个维度的序列长度不定。YTest是一个标签向量,分别是’1’, ‘2’, …, ‘9’,对应着9位说话的人。
[XTest,YTest] = japaneseVowelsTestData;XTest(1:3)
ans=3×1 cell array
{12×19 double}{12×17 double}{12×19 double}
因为我们的训练集的每个小批量的长度大小最后都是相似的,所以我们的测试集同样也需要这样来处理。通过序列长度对测试集数据进行分类。
numObservationsTest = numel(XTest);for i=1:numObservationsTestsequence = XTest{i};sequenceLengthsTest(i) = size(sequence,2);end[sequenceLengthsTest,idx] = sort(sequenceLengthsTest);XTest = XTest(idx);YTest = YTest(idx);
对测试集数据进行分类。同样地,为了减少分类过程中的填充量的大小,设定小批量数据的大小为27,和测试集的填充过程的参数设定一致,我们的序列长度大小设为’longest’。
miniBatchSize = 27;YPred = classify(net,XTest, ...'MiniBatchSize',miniBatchSize, ...'SequenceLength','longest');
计算最后的预测的准确率
acc = sum(YPred == YTest) ./ numel(YTest)
acc = 0.9730

若有收获,就点个赞吧
0 人点赞
