函数
- struct.error: 参数是出现错误的字符串
- struct.pack(format, v1, v2, …)
返回一个包含值”v1”和”v2”的”bytes”对象,这个”bytes”对象是根据括号中的”format”参数封装得到的,参数必须”v1”和”v2”必须和”format”要求的格式相匹配
- struct.pack_int(format, buffer, offset, v1, v2, …)
将”v1”和”v2”封装进入”buffer”(缓冲器)中,起始位置为”offset”(偏移量),这个偏移量是必须的。
- struct.unpack(format, buffer)
按照”format”格式,从”buffer”这个缓冲区中解析出包来,解析出来的结果是一个元组。注意:这个缓冲区的字节大小必须与”format”这个格式所需的大小相一致,就像calcsize()所映射的那样
- struck.unpack_from(format, buffer, offset=0)
根据”format”格式从起始位置为”offset”的”buffer”(缓冲区中)解析数据,结果仍然为一个元组。这个buffer(缓冲区)的字节大小,起始位置都至少要满足”format”格式的要求。
- struct.iter_unpack(format, buffer)
根据”format”这个格式迭代地从”buffer”这个缓冲器中解析出包来,这个函数最终会返回一个不断读取缓冲器的迭代器,知道读取完这个缓冲区,这个缓冲区的字节大小必须是”format”要求的大小的倍数。
- struct.calcsize(format)
Format Strings
Format strings(格式字符串)是在打包和解析数据的时候确定容器大小的时候用的,它们是从格式符号得来的,定义了打包和解析数据的类型。另外,还有一些特殊符号能够控制字节的顺序、大小和对齐方式(Byte Order, Size, and Alignment)。
Byte Order, Size, and Alignment
C语言默认是被表示为本机的格式和字节顺序,如有必要,通过跳过填充字节来正确对齐(根据C语言的编译器的使用规则)。
或者,可以使用格式字符串(format string)的第一个字符指示字节顺序、大小和打包数据的对齐方式,这个根据下面的表格得到。
| Character | Byte order | Size | Alignment |
|---|---|---|---|
@ |
native | native | native |
= |
native | standard | none |
< |
little-endian | standard | none |
> |
big-endian | standard | none |
! |
network (= big-endian) | standard | none |
如果第一个字符不是上述中的某一个,那么就假设为”@”。
本地的字节顺序取决于本机的顺序,一般为大端(big-endian)或者小端(little-endian)。例如,因特尔x86和AMD64(x86-64)是小端,Motorola 68000和PowerPC G5是大端,ARM和Intel Itanium是可以切换到大段的,使用sys.byteorder检测自己电脑系统的端。
本机大小和对齐方式取决于C编译器的表达方式,这个通常与本地字节顺序相关联。
标准大小却决于格式符号,下表中有可选择的格式符号。
注意:’@’和”=”的不同,两者都是适用的本地字节顺序,但是后者的大小和对齐方式都是规范化的。
‘!’是对于那些搞不清楚自己的网络字节顺序究竟是大端还是小端的可怜人准备的。
现在没办法表明非本地字节顺序(强制字节交换),可以使用’<’或者’>’。
注意:
- 1.仅在连续的结构成员之间自动添加填充,在编码结构的开头和结尾处是不会添加填充的。
- 2.当使用想’<’,’>’和’!’这样的非本地的大小和对齐方式的时候,是不会添加填充的。
- 3.要将结构的末尾与特定类型的对齐要求对齐,请使用该类型的代码结束该格式,并重复计数为零。 查看范例
Format characters
格式字符(format characters)有如下的意义:在C语言和Python之间的数据值交换的时候应该明确的给定他们的类型,“标准大小”列是指使用标准大小时打包值的大小(以字节为单位),就是指使用’<’,’>’或者’=’中的任意一个作为格式字符的开头。当使用本地大小的时候,被打包数据的值的大小就依赖于本机系统。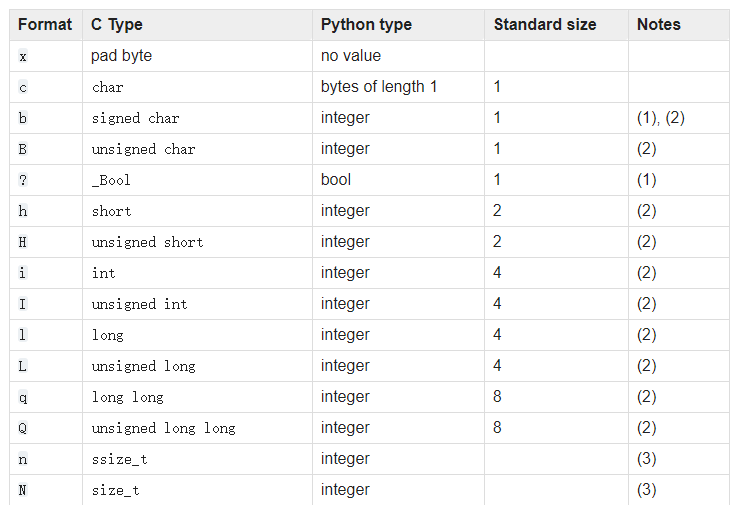

例子
注意:所有示例均假定本机字节顺序,大小以及与big-endian机器的对齐方式。 ```python from struct import * pack(‘hhl’,1,2,3) +++++ b’\x00\x01\x00\x02\x00\x00\x00\x03’ +++++
unpack(‘hhl’,b’\x00\x01\x00\x02\x00\x00\x00\x03’) +++++ (1,2,3) +++++
clacsize(‘hhl’) 8
上面的例子结果有点蒙圈,这个C语言的内容,有时间要补上。<br />可以通过将未打包的字段分配给变量或将结果包装在一个命名的元组中来命名它们:```pythonrecord = b'raymond \x32\x12\x08\x01\x08'name, serialnum, school, gradelevel = unpack('<10sHHb', record)from collections import namedtupleStudent = namedtuple('Student', 'name serialnm school gradelevel')Student._make(unpack('<10sHHb', record))+++++Student(name=b'raymond ', serialnum=4568, school=264, gradelevel=8)+++++
格式字符的顺序可能会影响大小,因为满足对齐要求所需的填充不同:
pack('ci', b'*', 0x12131415)+++++b'*\x00\x00\x12\x13\x14\x15+++++pack('ic', 0x12131415, b'*')+++++b'\x12\x13\x14\x15*'+++++calcsize('ci')+++++8+++++calcsize('ic')+++++5+++++
以下格式“ llh0l”在末尾指定了两个填充字节,假设长整数在4字节边界上对齐:
pack('llh0l', 1, 2, 3)+++++b'\x00\x00\x00\x01\x00\x00\x00\x02\x00\x03\x00\x00+++++

若有收获,就点个赞吧
0 人点赞
