原文链接
这部分主要是来介绍如何使用长短期记忆神经网络处理分类和回归任务的。
长短期记忆神经网络是循环神经网络的一类,可以学习序列数据的时间不长之间的长期依赖性。
LSTM网络架构
LSTM网络的核心组成是一个序列输入层和一个LSTM层。下面的图表阐述了一个简单的用于分类的LSTM网络的结构,在序列输入层后紧跟着的是LSTM层。最后使用一个全连接层、一个softmax层和一个分类输出层来预测类型标签。
图1. 用于分类的LSTM的架构
下面的这个图是用于回归的LSTM的架构
图2. 用于回归的LSTM的架构
下面这个图表阐明了对于视频分类的网络结构。使用序列输入层将图片序列输入到网络中,使用卷积层提取特征,紧跟着使用一个序列折叠层。为了使用LSTM层学习向量序列,使用一个flatten层->LSTM->输出层。
图3. 图片作为输入的LSTM架构
LSTM分类神经网络
如上面图1所示,我们需要建立输入层->LSTM神经网络->全连接层->softmax层->分类输出层。输入层的大小为输入数据的特征数量,全连接层的大小是类别的数量。我们并不需要考虑序列的长度。对于LSTM层,要确定隐藏单元的数量和最后的输出模式。
numFeatures = 12;numHiddenUnits = 100;numClasses = 9;layers = [...sequenceInputLayer(numFeatures)lstmLayer(numHiddenUnits, 'OutputMode', 'last')fullyConnectedLayer(numClasses)softmaxLayerclassificationLayer];
创建一个LSTM网络用于序列-序列的分类,使用同样的架构用于序列-标签的分类,但是要设置LSTM层的OutputMode为’sequence’。
numFeatures = 12;numHiddenUnits = 100;numClasses = 9;layers = [ ...sequenceInputLayer(numFeatures)lstmLayer(numHiddenUnits,'OutputMode','sequence')fullyConnectedLayer(numClasses)softmaxLayerclassificationLayer];
LSTM回归神经网络
要创建一个序列-回归值的回归网络,要创建输入层->LSTM层->全连接层->回归输出层。
输入层的大小是输入数据的特征个数,全连接层的大小是标签的个数,不需要知道序列的长度。
numFeatures = 12;numHiddenUnits = 125;numResponses = 1;layers = [ ...sequenceInputLayer(numFeatures)lstmLayer(numHiddenUnits,'OutputMode','last')fullyConnectedLayer(numResponses)regressionLayer];
创建一个LSTM网络用于序列-序列的回归,使用同样的架构用于序列-标签的回归,但是要设置LSTM层的OutputMode为’sequence’。
numFeatures = 12;numHiddenUnits = 125;numResponses = 1;layers = [ ...sequenceInputLayer(numFeatures)lstmLayer(numHiddenUnits,'OutputMode','sequence')fullyConnectedLayer(numResponses)regressionLayer];
视频分类网络
创建一个用于处理像视频和流媒体这样的神经网络,使用输入层输入数据,使用卷积层提取特征,紧跟着使用一个序列折叠层。为了使用LSTM层学习向量序列,使用一个flatten层->LSTM->输出层。
inputSize = [28 28 1];filterSize = 5;numFilters = 20;numHiddenUnits = 200;numClasses = 10;layers = [ ...sequenceInputLayer(inputSize,'Name','input')sequenceFoldingLayer('Name','fold')convolution2dLayer(filterSize,numFilters,'Name','conv')batchNormalizationLayer('Name','bn')reluLayer('Name','relu')sequenceUnfoldingLayer('Name','unfold')flattenLayer('Name','flatten')lstmLayer(numHiddenUnits,'OutputMode','last','Name','lstm')fullyConnectedLayer(numClasses, 'Name','fc')softmaxLayer('Name','softmax')classificationLayer('Name','classification')];
将各层转换为层图,并将序列折叠层的miniBatchSize输出与序列展开层的相应输入相连接。
lgraph = layerGraph(layers);lgraph = connectLayers(lgraph,'fold/miniBatchSize','unfold/miniBatchSize');
更深的LSTM网络
通过在LSTM层之前插入带有输出模式“序列”的额外LSTM层,可以使LSTM网络更深。 为了防止过度拟合,您可以在LSTM层之后插入退出层。
对于序列-标签分类网络,LSTM最后一层的模式必须是’last’。
numFeatures = 12;numHiddenUnits1 = 125;numHiddenUnits2 = 100;numClasses = 9;layers = [ ...sequenceInputLayer(numFeatures)lstmLayer(numHiddenUnits1,'OutputMode','sequence')dropoutLayer(0.2)lstmLayer(numHiddenUnits2,'OutputMode','last')dropoutLayer(0.2)fullyConnectedLayer(numClasses)softmaxLayerclassificationLayer];
对于序列-序列分类网络,最后一层的输出模式必须是’sequence’
numFeatures = 12;numHiddenUnits1 = 125;numHiddenUnits2 = 100;numClasses = 9;layers = [ ...sequenceInputLayer(numFeatures)lstmLayer(numHiddenUnits1,'OutputMode','sequence')dropoutLayer(0.2)lstmLayer(numHiddenUnits2,'OutputMode','sequence')dropoutLayer(0.2)fullyConnectedLayer(numClasses)softmaxLayerclassificationLayer];
层
| Layer | Description |
|---|---|
 sequenceInputLayer |
A sequence input layer inputs sequence data to a network. |
 lstmLayer |
An LSTM layer learns long-term dependencies between time steps in time series and sequence data. |
 bilstmLayer |
A bidirectional LSTM (BiLSTM) layer learns bidirectional long-term dependencies between time steps of time series or sequence data. These dependencies can be useful when you want the network to learn from the complete time series at each time step. |
 gruLayer |
A GRU layer learns dependencies between time steps in time series and sequence data. |
 sequenceFoldingLayer |
A sequence folding layer converts a batch of image sequences to a batch of images. Use a sequence folding layer to perform convolution operations on time steps of image sequences independently. |
 sequenceUnfoldingLayer |
A sequence unfolding layer restores the sequence structure of the input data after sequence folding. |
 flattenLayer |
A flatten layer collapses the spatial dimensions of the input into the channel dimension. |
 wordEmbeddingLayer (Text Analytics Toolbox) |
A word embedding layer maps word indices to vectors. |
分类和预测
要对新数据进行分类或预测,使用 classify和 predict,LSTM网络能够记住网络的预测结果间的状态。如果没有预先得到完整的时间序列,或者想对一个长时间序列进行多次预测,那么网络状态是有用的。
要对一部分时间序列进行预测和分类,要使用 predictAndUpdateState和 classifyAndUpdateState;如果要重置预测之间的状态,使用 resetState
序列的填充、截断和分割
LSTM网络支持具有不同序列长度的输入数据。 当通过网络传递数据时,软件会填充,截断或拆分序列,以使每个小型批处理中的所有序列都具有指定的长度。 您可以使用trainingOptions中的SequenceLength和SequencePaddingValue名称-值对参数指定序列长度和用于填充序列的值。
通过长度对序列排序
为了减少填充或截断序列时填充或丢弃的数据量,请尝试按序列长度对数据进行排序。 要按序列长度对数据进行排序,请首先使用cellfun将size(X,2)应用于每个序列,以获取每个序列的列数。 然后使用sort对序列长度进行排序,并使用第二个输出对原始序列进行重新排序。
sequenceLengths = cellfun(@(X) size(X,2), XTrain);[sequenceLengthsSorted,idx] = sort(sequenceLengths);XTrain = XTrain(idx);
下面这个图就在条形图中展示了排序的数据和未排序的数据的序列长度。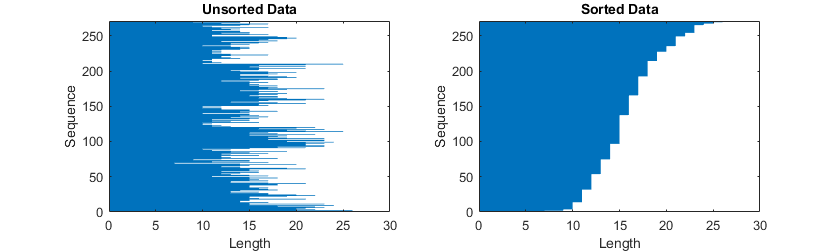
图4. 已排序和未排序数据的序列长度
填充序列
如果将序列长度指定为“最长”,将填充序列,以使微型批次中的所有序列的长度与微型批次中的最长序列的长度相同。 此选项是默认选项。
下图说明了将“ SequenceLength”设置为“最长”的效果。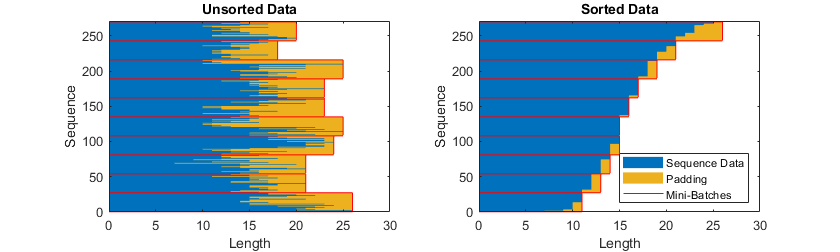
图5. 序列填充
截断序列
如果指定序列长度为“最短”,那么将截断序列,以便一个迷你批处理中的所有序列与该迷你批处理中的最短序列具有相同的长度。序列中的其余数据将被丢弃。下面的图说明了将“SequenceLength”设置为“short”的效果。
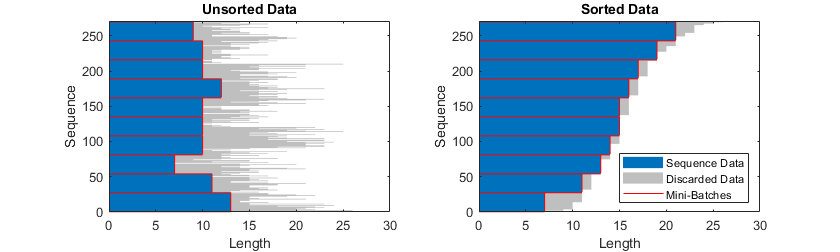
序列分割
如果将序列长度设置为整数值,则将小批次处理中的所有序列填充到指定长度的最接近倍数,该指定长度大于小批次批处理中的最长序列长度。 然后,将每个序列分成指定长度的较小序列。 如果发生拆分,则会创建额外的小批次。
如果完整序列不适合内存,请使用此选项。 另外,您可以尝试通过将trainingOptions中的’MiniBatchSize’选项设置为较低的值来减少每个小批量的序列数。
如果您将序列长度指定为正整数,则软件会在连续的迭代中处理较小的序列。 网络更新分割序列之间的网络状态。
下图说明了将“ SequenceLength”设置为5的效果。
图7. 序列分割
指定填充方向
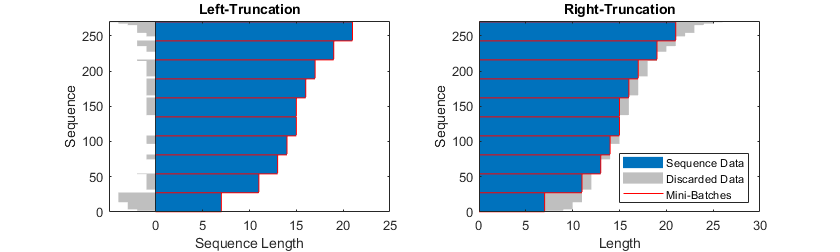
填充和截断的位置可能会影响训练,分类和预测准确性。 尝试将trainingOptions中的选项设为’left’或’right’,然后查看哪个最适合您的数据。
由于LSTM层一次处理一个时间步长的序列数据,因此当层OutputMode属性为“ last”时,最后时间步长中的任何填充都会对层输出产生负面影响。 要填充或截断左侧的序列数据,请将“ SequencePaddingDirection”选项设置为“ left”。
对于序列到序列的网络(当每个LSTM层的OutputMode属性为“ sequence”时),第一时间步长中的任何填充都可能对较早时间步长的预测产生负面影响。 在右侧填充或截断序列数据,将“SequencePaddingDirection”选项设置为“ right”。
下图显示了左侧和右侧的填充序列数据。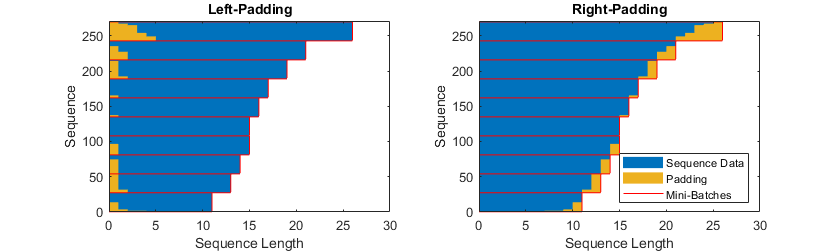
图8. 左侧和右侧填充数据
下图在左侧和右侧说明了截断序列数据。
归一化序列数据
要使用零中心归一化在训练时自动更新训练数据,请将sequenceInputLayer的Normalization选项设置为“ zerocenter”。 另外,您可以通过首先计算所有序列的每特征均值和标准偏差来标准化序列数据。 然后,对于每个训练观察,减去平均值并除以标准偏差。
mu = mean([XTrain{:}],2);sigma = std([XTrain{:}],0,2);XTrain = cellfun(@(X) (X-mu)./sigma,XTrain,'UniformOutput',false);
LSTM层的架构
下面这个图表展示了带有 个通道,长度为
个通道,长度为 的序列
的序列 通过一个LSTM层,在这个图中,
通过一个LSTM层,在这个图中, 和
和 表示输出和单元在时间
表示输出和单元在时间 的状态。
的状态。

图10. LSTM结构
第一个LSTM块使用的是神经网络的初始状态,在时间,LSTM块使用的的是神经网络的 的状态,然后计算下一个块的状态。
的状态,然后计算下一个块的状态。
下面的组成控制着单元和隐藏层的状态。
| Component | Purpose |
|---|---|
| Input gate (i) | Control level of cell state update |
| Forget gate (f) | Control level of cell state reset (forget) |
| Cell candidate (g) | Add information to cell state |
| Output gate (o) | Control level of cell state added to hidden state |
下面这个图阐述了在时间 的数据状态,这个图强调了forget, update和ouput门。
的数据状态,这个图强调了forget, update和ouput门。
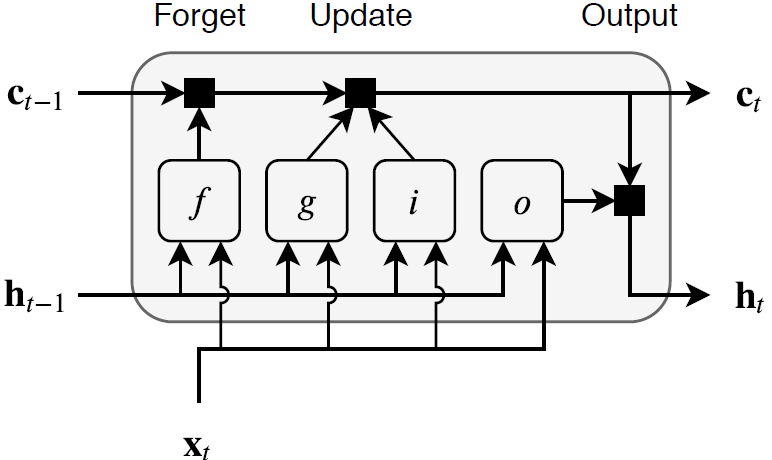
图11. 时间t的块图
下面的 和
和 分别表示输入的权重,循环权重和每部分的偏置:
分别表示输入的权重,循环权重和每部分的偏置:
其中的 和
和 分别表示输入门,遗忘门,候选单元和输出门,在时间的单元状态如下:
分别表示输入门,遗忘门,候选单元和输出门,在时间的单元状态如下:
在时间的隐藏状态如下:
其中的 表示的是状态激活函数,
表示的是状态激活函数,lstmLayer函数默认的是使用 tanh函数激活。下面这个表表示了在时刻的各个成分:
| Component | Formula |
|---|---|
| Input gate |  |
| Forget gate | 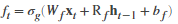 |
| Cell candidate | 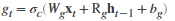 |
| Output gate | 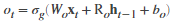 |
其中的 表示的是门激活函数,
表示的是门激活函数,lstmLayer函数默认使用  来激活
来激活

若有收获,就点个赞吧
0 人点赞
