您可以使用经过预先训练的图像分类网络,该网络已经学会从自然图像中提取强大而有用的功能,并将其用作学习新任务的起点。大多数预训练网络都在ImageNet数据库的子集上进行训练[1],该子集用于ImageNet大规模视觉识别挑战赛(ILSVRC)[2]。这些网络已经接受了超过一百万张图像的训练,可以将图像分类为1000个对象类别,例如键盘,咖啡杯,铅笔和许多动物。与从头开始训练网络相比,将预训练的网络与迁移学习一起使用通常会更快,更容易。
您可以使用先前训练有素的网络执行以下任务:
| 目的 | 描述 |
|---|---|
| 分类 | 将经过预训练的网络直接应用于分类问题。要分类新图像,请使用classify。有关显示如何使用预训练网络进行分类的示例,请参见使用GoogLeNet对图像进行分类。 |
| 特征提取 | 通过将图层激活用作要素,将预训练网络用作要素提取器。您可以将这些激活作为功能来训练另一个机器学习模型,例如支持向量机(SVM)。有关更多信息,请参见特征提取。有关示例,请参见使用预训练网络提取图像特征。 |
| 转移学习 | 从经过大型数据集训练的网络中获取图层,然后对新数据集进行微调。有关更多信息,请参见转学。有关简单的示例,请参见迁移学习入门。要尝试更多的预训练网络,请参阅训练深度学习网络对新图像进行分类。 |
比较预先训练好的网络
预训练的网络具有不同的特征,这些特征在选择适用于您的问题的网络时很重要。最重要的特征是网络准确性,速度和大小。选择网络通常是这些特征之间的权衡。使用下面的图将ImageNet验证准确性与使用网络进行预测所需的时间进行比较。
- 建议
要开始进行迁移学习,请尝试选择速度更快的网络之一,例如SqueezeNet或GoogLeNet。然后,您可以快速进行迭代并尝试其他设置,例如数据预处理步骤和培训选项。一旦感觉到哪些设置效果良好,请尝试使用更精确的网络(例如Inception-v3或ResNet),看看是否可以改善您的结果。
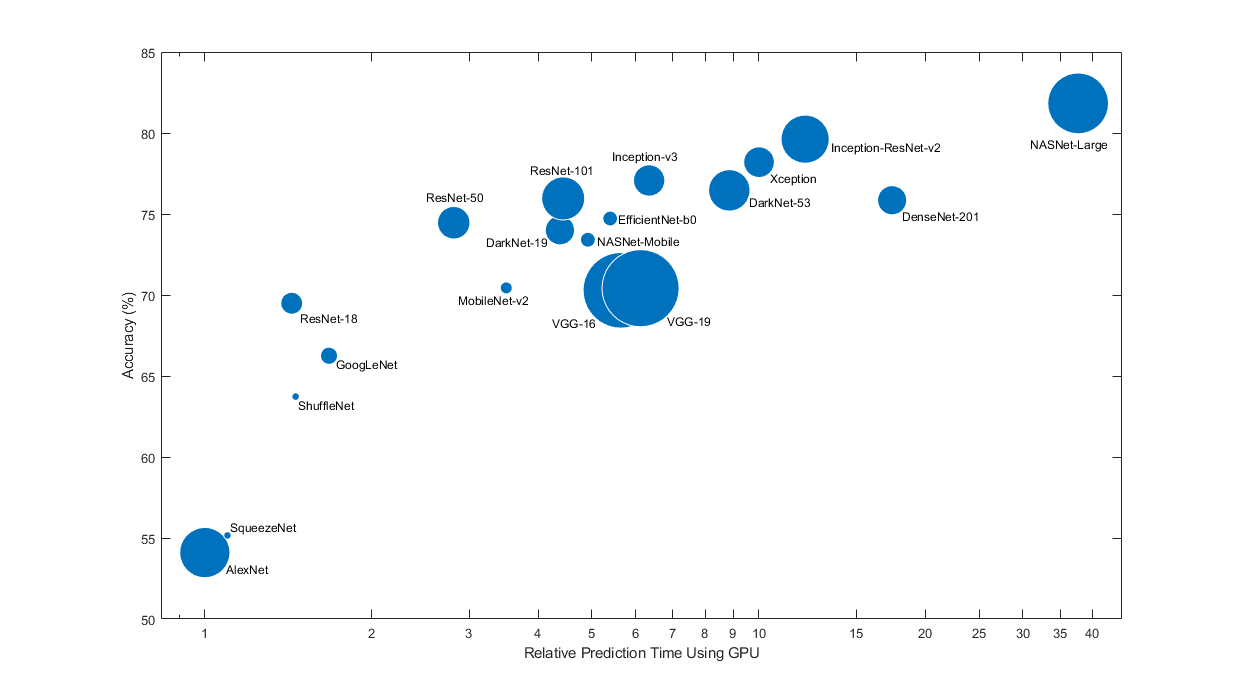
图1. 相关网络
- 注意
上面的图仅显示了不同网络的相对速度。确切的预测和训练迭代时间取决于您使用的硬件和最小批量大小。
一个好的网络具有很高的准确性,而且速度很快。该图显示的分类精度与预测时间使用现代GPU(的时NVIDIA 特斯拉 P100)和128.预测时间迷你批量大小相对于最快的网络测量。每个标记的面积与磁盘上网络的大小成正比。
ImageNet验证集上的分类准确性是衡量在ImageNet上训练的网络的准确性的最常用方法。当您使用转移学习或特征提取将网络应用于其他自然图像数据集时,在ImageNet上准确的网络通常也很准确。这种归纳是可能的,因为网络已经学会了从自然图像中提取强大而有用的特征,这些特征可以归纳为其他相似的数据集。但是,ImageNet上的高精度并不总是直接转移到其他任务上,因此尝试多个网络是一个好主意。
如果要使用受限的硬件执行预测或通过Internet分布网络,则还要考虑磁盘和内存中网络的大小。
- 网络精度
在ImageNet验证集上有多种计算分类准确度的方法,不同的来源使用不同的方法。有时会使用多个模型的集合,有时会使用多个裁剪对每个图像进行多次评估。有时会引用top-5精度而不是标准(top-1)精度。由于存在这些差异,通常无法直接比较不同来源的精度。深度学习工具箱™中的预训练网络的精度是使用单个模型和单个中心图像裁剪的标准(top-1)精度。
加载预训练网络
要加载预训练好的网络,在命令行中输入
net = squeezenet;
对于其他网络,请使用诸如googlenet获取链接的功能,以从附加资源管理器中下载经过预训练的网络。
下表列出了在ImageNet上训练的可用预训练网络及其某些属性。网络深度定义为从输入层到输出层的路径上最大数量的顺序卷积或完全连接的层。所有网络的输入均为RGB图像。
| 网络 | 深度 | 尺寸 | 参数(百万) | 影像输入尺寸 |
|---|---|---|---|---|
squeezenet |
18 | 5.2兆字节 | 1.24 | 227乘227 |
googlenet |
22 | 27兆字节 | 7.0 | 224乘224 |
inceptionv3 |
48 | 89兆字节 | 23.9 | 299乘299 |
densenet201 |
201 | 77兆字节 | 20.0 | 224乘224 |
mobilenetv2 |
53 | 13兆字节 | 3.5 | 224乘224 |
resnet18 |
18 | 44兆字节 | 11.7 | 224乘224 |
resnet50 |
50 | 96兆字节 | 25.6 | 224乘224 |
resnet101 |
101 | 167兆字节 | 44.6 | 224乘224 |
xception |
71 | 85兆字节 | 22.9 | 299乘299 |
inceptionresnetv2 |
164 | 209兆字节 | 55.9 | 299乘299 |
shufflenet |
50 | 5.4兆字节 | 1.4 | 224乘224 |
nasnetmobile |
* | 20兆字节 | 5.3 | 224乘224 |
nasnetlarge |
* | 332兆字节 | 88.9 | 331乘331 |
darknet19 |
19 | 78兆字节 | 20.8 | 256乘256 |
darknet53 |
53 | 155兆字节 | 41.6 | 256乘256 |
efficientnetb0 |
82 | 20兆字节 | 5.3 | 224乘224 |
alexnet |
8 | 227兆字节 | 61.0 | 227乘227 |
vgg16 |
16 | 515兆字节 | 138 | 224乘224 |
vgg19 |
19 | 535兆字节 | 144 | 224乘224 |
- NASNet-Mobile和NASNet-Large网络不包含线性的模块序列。
GoogLeNet在Places365上进行了训练
标准的GoogLeNet网络在ImageNet数据集上受过训练,但是您也可以加载在Places365数据集上受过训练的网络[3] [4]。在Places365上训练的网络将图像分类为365个不同的场所类别,例如田野,公园,跑道和大厅。
要加载在Places365数据集上经过训练的预先训练好的GoogLeNet网络,请使用googlenet('Weights','places365')。在执行迁移学习以执行新任务时,最常见的方法是使用在ImageNet上预训练的网络。如果新任务类似于对场景进行分类,则使用在Places365上训练的网络可以提供更高的准确性。特征提取
特征提取是一种使用深度学习功能的便捷方法,而无需花费时间和精力来训练整个网络。由于只需要对训练图像进行一次传递,因此如果没有GPU,则特别有用。您可以使用预先训练的网络提取学习的图像特征,然后使用这些特征来训练分类器,例如使用(统计和机器学习工具箱)的支持向量机fitcsvm
当新数据集非常小时,请尝试特征提取。由于仅对提取的特征训练简单的分类器,因此训练速度很快。由于几乎没有要学习的数据,因此微调网络的较深层也不太可能提高准确性。
- 如果您的数据与原始数据非常相似,则在网络中更深层提取的更具体的功能可能对新任务很有用。
- 如果您的数据与原始数据有很大不同,则从网络中更深层提取的功能可能对您的任务不太有用。尝试对从早期网络层提取的更一般的特征进行最终分类器训练。如果新数据集很大,那么您也可以尝试从头开始训练网络。
ResNets通常是好的特征提取器。有关显示如何使用预训练网络进行特征提取的示例,请参见使用预训练网络提取图像特征。
迁移学习
您可以通过以预先训练的网络为起点在新数据集上训练网络来微调网络中的更深层次。通过迁移学习对网络进行微调通常比构建和培训新网络更快,更容易。网络已经学习了丰富的图像功能,但是当您微调网络时,它可以学习特定于新数据集的功能。如果您的数据集非常大,那么迁移学习可能不会比从头开始训练要快。
- 建议
微调网络通常可以提供最高的精度。对于非常小的数据集(每个类少于20张图像),请尝试使用特征提取。
与简单的特征提取相比,微调网络速度较慢并且需要更多的精力,但是由于网络可以学习提取一组不同的特征,因此最终的网络通常更准确。只要新数据集不是很小,微调通常会比特征提取更好,因为这样网络就具有从中学习新特征的数据。有关显示如何执行转移学习的示例,请参阅使用Deep Network Designer进行转移学习和训练Deep Learning Network对新图像进行分类。
图2. 预训练好的网络
导入和导出网络
您可以从TensorFlow导入网络和网络架构 -Keras,来自Caffe和ONNX™(开放式神经网络交换)模型格式。您也可以将训练好的网络导出为ONNX模型格式。
导入Keras
使用导入来自TensorFlow-Keras的预训练网络importKerasNetwork。您可以从相同的HDF5(.h5)文件或单独的HDF5和JSON(.json)文件导入网络和权重。有关更多信息,请参见importKerasNetwork。
通过使用从TensorFlow-Keras导入网络体系结构importKerasLayers。您可以导入网络体系结构,无论有无权重。您可以从相同的HDF5(.h5)文件或单独的HDF5和JSON(.json)文件导入网络体系结构和权重。有关更多信息,请参见importKerasLayers。
导入Caffe
使用该importCaffeNetwork功能从Caffe导入预训练的网络。Caffe Model Zoo [5]中有许多可用的预训练网络。下载所需.prototxt和.caffemodel 文件,并使用importCaffeNetwork进口预训练的网络到MATLAB 。有关更多信息,请参见importCaffeNetwork。
您可以导入Caffe网络的网络体系结构。下载所需的 .prototxt文件,并将其用于importCaffeLayers 将网络层导入MATLAB。有关更多信息,请参见importCaffeLayers。
导入和导出ONNX
通过使用ONNX作为中间格式,您可以与其他深度学习框架互操作的支持ONNX模型出口或进口,如TensorFlow,PyTorch,Caffe2,微软认知工具包(CNTK),核心ML和Apache MXNet™。
使用该exportONNXNetwork功能将训练有素的深度学习工具箱网络导出为ONNX模型格式。然后,您可以将ONNX模型导入其他支持ONXX模型导入的深度学习框架。
使用ONNX导入预训练的网络,使用importONNXNetwork导入带有或不带有权重的网络体系结构importONNXLayers。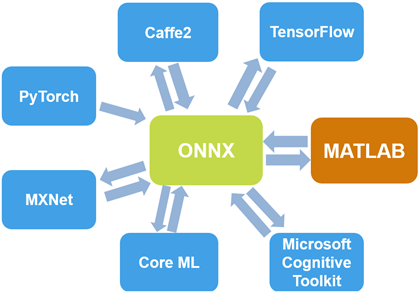
图3. 导入和导出网络
适用于音频的网络
通过结合使用Deep Learning Toolbox和Audio Toolbox™,将预训练的网络用于音频和语音处理应用程序。
音频工具箱提供了预先训练的VGGish和YAMNet网络。使用(音频工具箱)和 (音频工具箱)功能直接与预训练的网络进行交互。该(音频工具箱)函数执行所需的预处理和后处理的YAMNet这样你可以找到和分类的声音到521个类别之一。您可以使用(音频工具箱)功能来探索YAMNet本体。该 (音频工具箱)vggishyamnetclassifySoundyamnetGraphvggishFeatures函数对VGGish执行必要的预处理和后处理,以便您可以提取特征嵌入以输入到机器学习和深度学习系统。有关将深度学习用于音频应用程序的更多信息,请参阅音频应用程序深度学习简介(音频工具箱)。
使用VGGish和YAMNet进行转移学习和特征提取。例如,请参阅使用预训练的音频网络进行转移学习(音频工具箱)。

若有收获,就点个赞吧
0 人点赞
