网络中信息传播公式


反向传播算犯法
梯度下降法需要计算损失函数对参数的偏导数,在神经网络的训练中经常使用反向传播算法来计算高效地梯度。
交叉熵损失函数:
其中, 为标签
为标签 对应的向量表示,
对应的向量表示, 对权重求偏导,只列出最终结果
对权重求偏导,只列出最终结果 对偏移量的偏导:
对偏移量的偏导:
其中,具体来说
误差项
第l层的误差可以通过第l+1层的误差计算得到,这就是误差的反向传播,可得
可得
练习题
1.全连接神经网络
问题描述:利用numpy和tensorflow、pytorch搭建全连接神经网络。使用numpy实现此练习需要自己手动求导,而tensorflw和pytorch具有自动求导机制
2.函数拟合
问题描述:理论和实践证明,一个两层的ReLU网络可以模拟任何函数,请自行定义一个函数,并使用基于ReLU的神经网络来拟合此函数。
3.数据集描述
mnist_dataset.rar
MNIST数据集是一个手写体数据集,简单说就是一堆这样东西
这个数据集由四部分组成,分别是

也就是一个训练图片集,一个训练标签集,一个测试图片集,一个测试标签集;我们可以看出这个其实并不是普通的文本文件或是图片文件,而是一个压缩文件,下载并解压出来,我们看到的是二进制文件,其中训练图片集的内容部分如此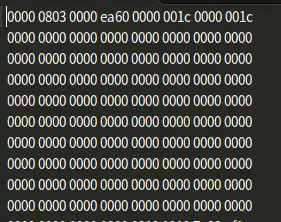
这些二进制数据如何解释呢?在这里我们只针对官网的说法,对训练图片集和训练标签集进行解说,测试集是一样的道理。
针对训练标签集,官网上陈述有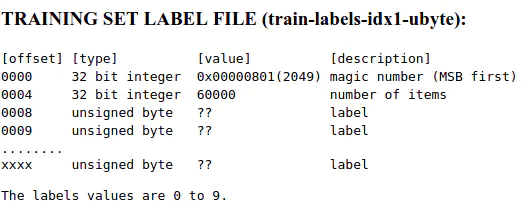
其解说与上面的标签文件类似,但是这里还要补充说明一下,在MNIST图片集中,所有的图片都是28×28的,也就是每个图片都有28×28个像素;
看回我们的上述图片,其表示,我们的train-images-idx3-ubyte文件中偏移量为0字节处有一个4字节的数为0000 0803表示魔数;
接下来是0000ea60值为60000代表容量,接下来从第8个字节开始有一个4字节数,值为28也就是0000 001c,表示每个图片的行数;
从第12个字节开始有一个4字节数,值也为28,也就是0000001c表示每个图片的列数;从第16个字节开始才是我们的像素值,用图片说话;而且每784个字节代表一幅图片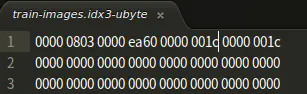
补充说明:在图示中我们可以看到有一个MSB first,其全称是”Most Significant Bit first”,相对称的是一个LSB first,“Least Significant Bit”; MSB first是指最高有效位优先,也就是我们的大端存储,而LSB对应小端存储;关于大端,小端,可以参考
参考链接
'''使用python解析二进制文件'''import numpy as npimport structdef loadImageSet(filename):binfile = open(filename, 'rb') # 读取二进制文件buffers = binfile.read()head = struct.unpack_from('>IIII', buffers, 0) # 取前4个整数,返回一个元组offset = struct.calcsize('>IIII') # 定位到data开始的位置imgNum = head[1]width = head[2]height = head[3]bits = imgNum * width * height # data一共有60000*28*28个像素值bitsString = '>' + str(bits) + 'B' # fmt格式:'>47040000B'imgs = struct.unpack_from(bitsString, buffers, offset) # 取data数据,返回一个元组binfile.close()imgs = np.reshape(imgs, [imgNum, width * height]) # reshape为[60000,784]型数组return imgs,headdef loadLabelSet(filename):binfile = open(filename, 'rb') # 读二进制文件buffers = binfile.read()head = struct.unpack_from('>II', buffers, 0) # 取label文件前2个整形数labelNum = head[1]offset = struct.calcsize('>II') # 定位到label数据开始的位置numString = '>' + str(labelNum) + "B" # fmt格式:'>60000B'labels = struct.unpack_from(numString, buffers, offset) # 取label数据binfile.close()labels = np.reshape(labels, [labelNum]) # 转型为列表(一维数组)return labels,headif __name__ == "__main__":file1= 'E:/pythonProjects/dataSets/mnist/train-images.idx3-ubyte'file2= 'E:/pythonProjects/dataSets/mnist/train-labels.idx1-ubyte'imgs,data_head = loadImageSet(file1)print('data_head:',data_head)print(type(imgs))print('imgs_array:',imgs)print(np.reshape(imgs[1,:],[28,28])) #取出其中一张图片的像素,转型为28*28,大致就能从图像上看出是几啦print('----------我是分割线-----------')labels,labels_head = loadLabelSet(file2)print('labels_head:',labels_head)print(type(labels))print(labels)
Pytorch和Numpy搭建全连接神经网络
Pytorch语法基础
PyTorch是一个基于Python的科学计算库,它有以下特点:
- 类似于Numpy,但是可以使用GPU
- 可以用它定义深度学习模型,可以灵活地进行深度学习模型的训练和使用
其中的函数Tensor类似于Numpy的ndarray,唯一的区别就是Tensor可以在GPU上加速运算。 下面给出一些基本的运算操作
下面给出一些基本的运算操作
import torch#构建一个随机初始化的矩阵x = torch.rand(5,3)#构建一个全部为0,类型为long的矩阵x = torch.zeros(5,3,dtype=torch.long)#构建一个全部为0,类型为long的矩阵,有两种等价形式x = torch.zeros(5,3,dtype=torch.long)x = torch.zeros(5,3).long()#从数据直接直接构建tensorx = torch.tensor([5.5,3])#也可以从一个已有的tensor构建一个tensor。#这些方法会重用原来tensor的特征。#例如,数据类型,除非提供新的数据。x = x.new_ones(5,3, dtype=torch.double)+++++++++++tensor([[1., 1., 1.],[1., 1., 1.],[1., 1., 1.],[1., 1., 1.],[1., 1., 1.]], dtype=torch.float64)++++++++++++x = torch.randn_like(x, dtype=torch.float)+++++++++++tensor([[ 0.2411, -0.3961, -0.9206],[-0.0508, 0.2653, 0.4685],[ 0.5368, -0.3606, -0.0073],[ 0.3383, 0.6826, 1.7368],[-0.0811, -0.6957, -0.4566]])+++++++++++#得到tensor的形状x.shape+++++++++++torch.Size([5, 3])+++++++++++#复制tensor,不指向同一块内存地址,但requires_grad属性相同y = x.clone()#返回一个新的tensor,新的tensor和原来的tensor共享数据内存,但不涉及梯度计算#即requires_grad=Falsey = x.clone().detach()#加法运算有两种等价形式x_sum_y = x + y #第一种x_sum_y = torch.empty(5,3) #第二种,先声明一个空矩阵,然后使用"out="赋值torch.add(x, y, out=x_sum_y)#加法运算后替换掉y的值y.add_(x)#各种类似NumPy的indexing都可以在PyTorch tensor上面使用x[1:, 1:]#如果你希望resize/reshape一个tensor,可以使用torch.viewx = torch.randn(4,4)y = x.view(16)z = x.view(-1,8) #有一个 -1 则会根据另一项进行自动求解,得到合适的维度。#如果你有一个只有一个元素的tensor,使用.item()方法可以把里面的value变成Python数值。x = torch.randn(1) # x是一个tensory = x.item() # y是一个数值#张量的转置z.transpose(1,0)"""在Torch Tensor和NumPy array之间相互转化非常容易。Torch Tensor和NumPy array会共享内存。所以改变其中一项也会改变另一项。"""#把Torch Tensor转变成NumPy Arraya = torch.ones(5) # a是tensorb = a.numpy() # b是array#把NumPy ndarray转成Torch Tensorimport numpy as npa = np.ones(5)b = torch.from_numpy(a)
Numpy搭建全连接神经网络
numpy中要建立的网络,包括一个隐藏层,没有bias,用来从x预测y,使用LLoss 这一实现完全使用numpy来计算:前向神经网络、loss和反向传播
这一实现完全使用numpy来计算:前向神经网络、loss和反向传播
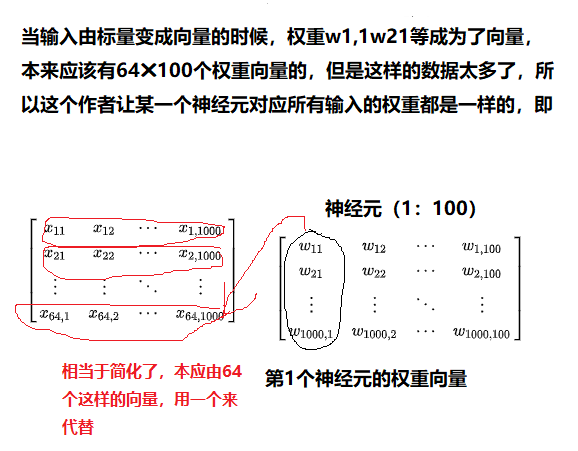
numpy ndarray是一个普通的n维array,它不知道任何关于深度学习或者梯度(gradient)的知识,也不知道计算图(computation graph),只是一种用来计算数学运算的数据结构。假设有64个训练数据,输入是100维的,隐藏的神经元个数为100,输出为10维。
N,D_in,H,D_out = 64,1000,100,10
随机创建一些训练数据
x = np.random.randn(N,D_in)y = np.random.randn(N,D_out)w1 = np.random.randn(D_in,H)w2 = np.random.randn(H,D_out)
在构建全连接神经网络的时候,最重要的是要知道用到的矩阵的大小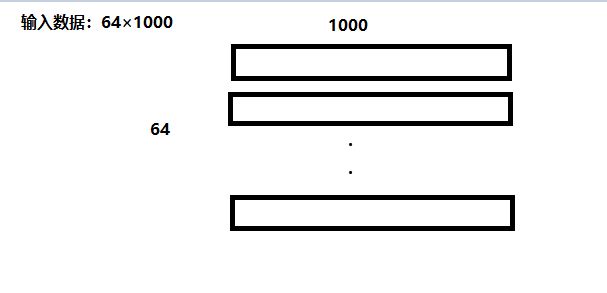
我们拿个例子来推导
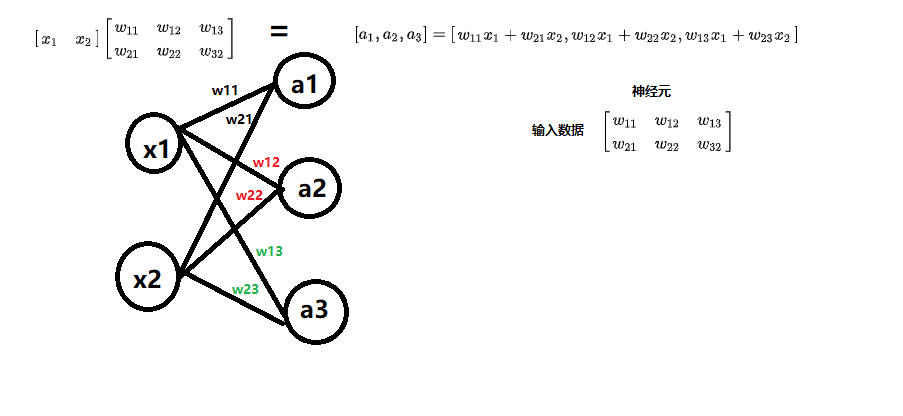
当我们的输入由标量变成向量的时候,变化为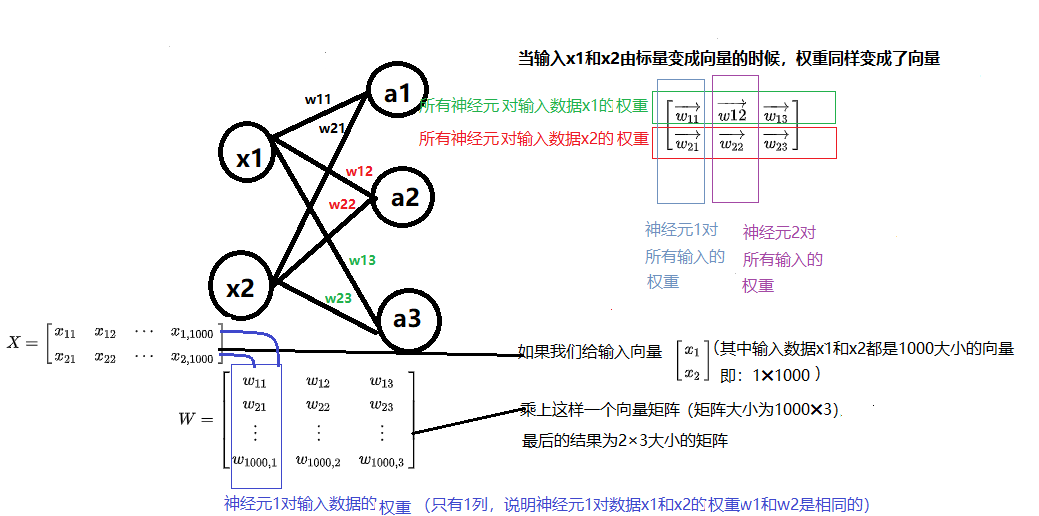
 指定学习率
指定学习率
learning_rate = 1e-6
假设训练500轮,分别计算前向传播、loss、反向传播,并且更新权重。
for it in range(500):
前向传播```h = x.dot(w1) #权重*数据h_relu = np.maximum(h,0) #激活函数y_pred = h_relu.dot(w2) #预测函数```计算损失```loss = np.square(y_pred-y).sum()使用MSE损失print(it,loss)
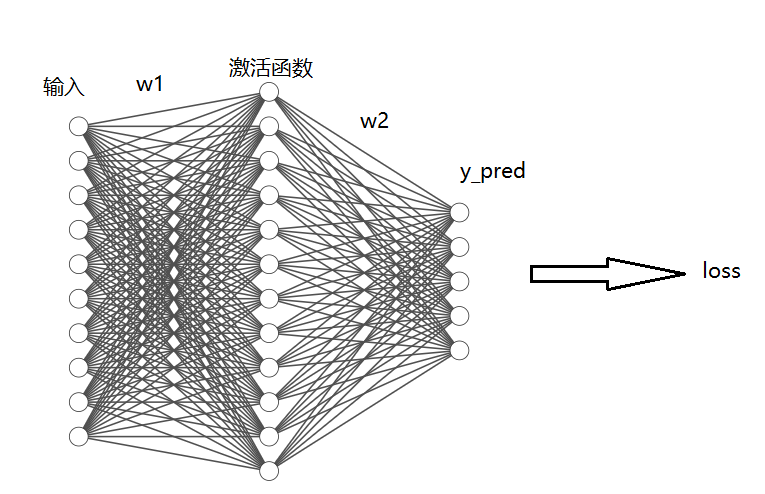<br />反向传播公式:<br />```pythongrad_y_pred = 2*(y_pred - y)
因为我们随机定了2个参数 ,从而造成了预测结果的不准确,所以我们要迭代这两个参数:
,从而造成了预测结果的不准确,所以我们要迭代这两个参数:
因为:
grad_w2 = h_relu.T.dot(grad_y_pred)
接下来是迭代计算 ,同样是上述的方法
,同样是上述的方法
#按照上述公式得到四项为:grad_y_pred,w2.T,下面的grad_h和x.T#主要求得就是激活函数求导得部分,激活函数得导数分为两部分,但是可以直接使用一个式子来判断h_copy = h.copy()h_copy[h<0] = 0#直接让h<0的部分导数为0即可grad_h = h_copygrad_w1 = x.T.dot(grad_h.dot(grad_y_pred.dot(w2.T)))#更新w1和w2w1 -= learning_rate * grad_w1w2 -= learning_rate * grad_w2
Pytorch逐步实现前馈神经网络
(原文链接)下面我们使用Pytorch tensor来创建前向神经网络,计算损失,以及反向传播
一个PyTorch Tensor很像一个numpy的ndarray。但是它和numpy ndaary最大的区别就是,PyTorch Tensor可以在CPU或者GPU上运算,如果想要在GPU上运算,就需要把Tensor换成cuda类型。(下面我们来看一下创建随机矩阵的大小怎么确定)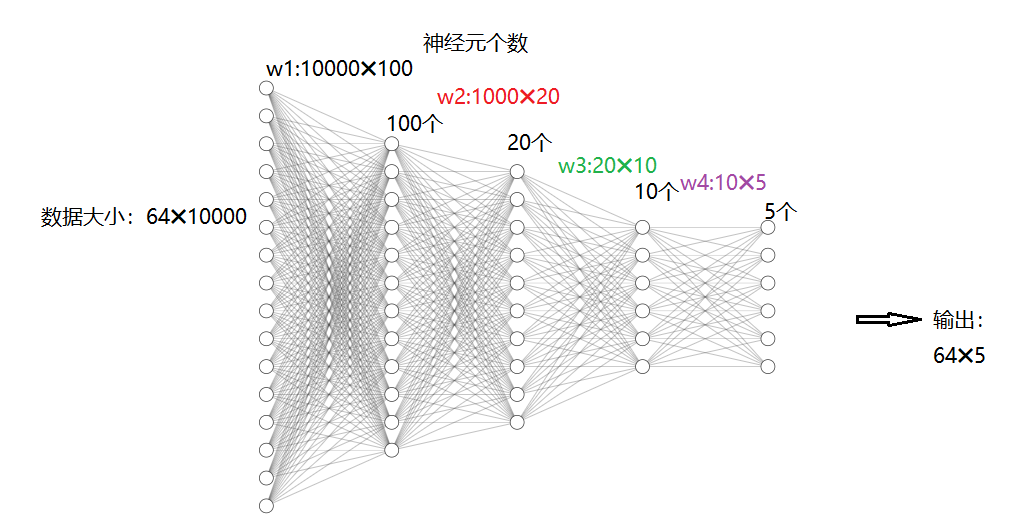
N,D_in,H,D_out = 64,1000,100,10#随机创建一些训练数据x = torch.randn(N,D_in)y = torch.randn(N,D_out)w1 = torch.randn(D_in,H)w2 = torch.randn(H,D_out)learning_rate = 1e-6for it in range(500):h = x.mm(w1)# x* w第一层卷积后的结果h_relu = h.clamp(min=0)#relu 函数(h<0则,h_relu = 0;h>0,h_relu = h)y_pred = h_relu.mm(w2)#激活后的函数 * w2#计算损失loss = (y_pred-y).pow(2).sum().item()print(it,loss)
反向传播计算梯度,这整段代码其实等价于loss.backforward(),后面会看到```grad_y_pred = 2*(y_pred-y)grad_w2 = h_relu.t().mm(grad_y_pred)#因为涉及到激活函数,所以要每一步单独拿出来处理,由上面求偏导我们可以得到偏导组成grad_h_relu = w2.t().mm(grad_y_pred)#激活函数的导数grad_h = grad_h_relu.clone()grad_h[h<0] = 0grad_w1 = x.t().mm(grad_h_relu)#开始更新w1 -= learning_rate * grad_w1w2 -= learning_rate * grad_w2++++++++++++++++++++++++++
0 29762046.0 1 23066852.0 2 18711686.0 …
497 2.4027987819863483e-05 498 2.394388684479054e-05 499 2.353984564251732e-05 ++++++++++++++++++++++++++
同样随着迭代,损失在下降<a name="EE2jE"></a>### autogradPyTorch的一个重要功能是autograd,也就是说只要**定义了forward pass(前向神经网络)**,**计算了loss之后**,**PyTorch可以自动求导模型所有参数的梯度**。<br />一个PyTorch的Tensor表示计算图中的一个节点,如果x是一个Tensor并且x.requires_grad = True,那么x.grad是另一个储存着x当前梯度(相当于一个scalar,常常是loss)的向量。<br />更新后的脚本如下:```pythonN,D_in,H,D_out = 64,1000,100,10#随机创建一些训练数据x = torch.randn(N,D_in)y = torch.randn(N,D_out)w1 = torch.randn(D_in,H,requires_grad = True)#需要梯度w2 = torch.randn(H,D_out,requires_grad = True)#需要梯度learning_rate = 1e-6for it in range(500):#前向传播y_pred = x.mm(w1).clamp(min=0).mm(w2) #计算x*w1,然后激活,然后再乘以w2#计算损失loss = (y_pred-y).pow(2).sum() #computation graph计算图print(it,loss.item())#反向传播loss.backward() #自动反向传播,不用自己求偏导#更新权重w1和w2,使用with torch.no_grad()避免w的梯度被记录with torch.no_grad():w1 -= learning_rate * w1.grad #computation graph 计算图w2 -= learning_rate * w2.grad #computation graph计算图#梯度清零,inplace形式,因为每次的更新都会使得w1和w2改变,所以其梯度需要改变w1.grad.zero()w2.grad.zero()
使用nn库来构建网络
 这次我们使用PyTorch中nn这个库来构建网络,用PyTorch autograd来构建计算图和计算gradients,然后Pytorch会帮我们自动计算gradient。
这次我们使用PyTorch中nn这个库来构建网络,用PyTorch autograd来构建计算图和计算gradients,然后Pytorch会帮我们自动计算gradient。
并且不再手动更新模型的weights,而是使用optim这个包来帮助我们更新参数。optim这个package提供了各种不同的模型优化方法,包括SGD+momentum,RMSProp,Adam等等。
import torch.nn as nnN,D_in,H,D_out = 64,1000,100,10#随机创建一些训练数据x = torch.randn(N,D_in)y = torch.randn(N,D_out)#相当于w_1*x+b_1,无偏置项的线性回归model = torch.nn.Sequential(torch.nn.Linear(D_in,H,bias = False),torch.nn.ReLU(),torch.nn.Linear(H,D_out,bias = False),)#随机初始化参数torch.nn.init.normal_(model[0].weight)torch.nn.init.normal_(model[2].weight)model = model.cuda()#指定损失loss_fn = nn.MSELoss(reduction = 'sum')#指定学习率learning_rate = 1e-6#定义一个参数更新器optimizer = torch.optim.SGD(model.parameters(),lr = learning_rate)for it in range(500):#前向传播y_pred = model(x) #model.forward()#计算损失loss = loss_fn(y_pred,y) #computation graphprint(it,loss.item())#梯度清零optimizer.zero_grad()#反向传播loss.backforward()#参数自动一步更新optimizer.step()
定义一个模型,继承自nn.Module类
因为如果需要定义一个比Sequential模型更加复杂的模型,就需要定义nn.Module模型,下面函数的区别就是,module换成了自定义的nn.Module,主要区别是必须定义前行传播的过程。
import torch.nn as nnN,D_in,H,D_out = 64,1000,100,10#随机创建一些训练数据x = torch.randn(N,D_in)y = torch.randn(N,D_out)class TwoLayerNet(torch.nn.Module):def __init__(self,D_in,D_out):super(TwoLayerNet,self).__init__()#定义模型计算图self.linear1 = torch.nn.Linear(D_in,H,bias = False)self.linear2 = torch.nn.Linear(H,D_out,bias = False)#在class 中必须定于前向传播过程,torch.nn.Sequential则不需要def forward(self,x):#两个模型相连的前向传播y_pred = self.linear2(self.linear(x.clamp(min = 0)))return y_pred#model使用前面定义的类model = TwoLayerNet(D_in,H,D_out)loss_fn = nn.MSELoss(reduction = 'sum')learning_rate = 1e-4optimizer = torch.optim.Adam(model.parameters(),lr = learning_rate)for it in range(500):#前行传播y_pred = model(x) #model.forward和moel(x)是一样的#计算损失loss = loss_fn(y_pred,y) #computation graphprint(it,loss.item())#梯度清零optimizer.zero_grad()#反向传播loss.backforward()#参数自动一步更新optimizer.step()+++++++++++++++++++++++++++0 675.53186035156251 659.02276611328122 642.9276123046875...497 3.5824149335894617e-07498 3.3695400247779617e-07499 3.168272826314933e-07+++++++++++++++++++++++++++
二分类任务
对于二分类任务,可能需要计算他的AUC值,或者在每一轮训练的时候,观察其AUC变化。
如果想要调用sklearn.metrics import roc_auc_score来计算AUC,需要把带grad的tensor转为numpy。
import torchimport torch.nn as nnimport numpy as npfrom sklearn.metrics import roc_auc_scoreN,D_in,H,D_out = 64,1000,100,1#随机创建训练数据x = torch.randn(N,D_in)print(x.shape)y = torch.tensor(np.random.randint(0,2,N),dtype= torch.float32)#生成0-2之间的64个随机数y = torch.reshape(y,(N,D_out))#将上述生成的向量转置成列向量print(y.shape)class TwoLayerNet(torch.nn.Module):def__init__(self,D_in,D_out):super(TwoLayerNet,self).__init__()#定义模型计算图self.linear1 = torch.nn.Linear(D_in,H,bias = False)self.linear2 = torch.nn.Linear(H,D_out,bias = False)#在class中必须定义前行传播过程,torch.nn.Sequential则不需要def forward(self,x):#两个模型相连的前向传播y_pred = torch.sigmoid(self.linear2(self.linear1(x).clamp(min = 0)))#梯度剪裁return y_pred#model 使用前面定义的类model = TwoLayerNet(D_in,H,D_out)loss_fn = nn.BCELoss(reduction = 'sum')#返回梯度之和learning_rate = 1e-4optimizer = torch.optim.Adam(model.parameters(),lr = learning_rate)for it in range(10000):#前向传播y_pred = model(x) #model.forward()和model(x)是一样的#计算损失loss = loss_fn(y_pred,y) #computation graphif it%100 == 0:print(it,loss.item())#梯度清零optimizer.zero_grad()#反向传播loss.backward()#参数自动一步更新optimizer.step()#计算AUC,带grad的tensor转为numpyy_pred = model(x).clone().detach().requires_grad_(False).numpy()test_x = torch.randn(N,D_in)test_y = torch.tensor(np.random.randint(0,2,N),dtype = torch.float32)test_y = torch.reshape(test_y,(N,D_out))test_pred = y_pred = model(x).clone().detach().requires_grad_(False).numpy()print('开发样本AUC',roc_auc_score(y.numpy(),y_pred))print('测试样本AUC',roc_auc_score(test_y.numpy(),test_pred))+++++++++++++++++++++++++++开发样本AUC: 1.0测试本AUC: 0.61+++++++++++++++++++++++++++
以上。

若有收获,就点个赞吧
0 人点赞
