使用Python的sklearn包来统计模型的结果,首先要知道常用来模型的指标有哪些
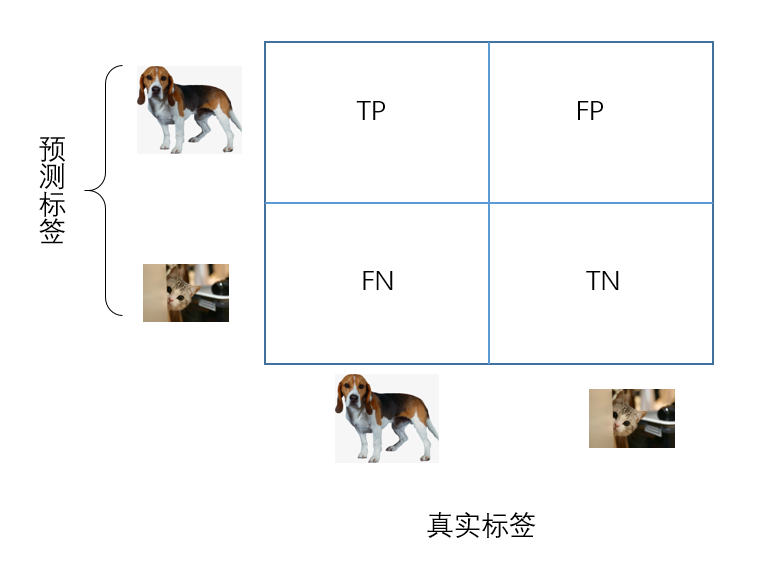
首先了解最基本的四个指标:TP, TN, FP, FN
- True positives: 简称为TP,即正样本被正确识别为正样本。
- True negatives: 简称为TN,即负样本被正确识别为负样本。
- False Positives: 简称为FP,即负样本被错误识别为正样本。
- False negatives: 简称为FN,即正样本被错误识别为负样本。
一、准确率accuracy

二、灵敏度sensitivity/recall
灵敏度:表示的是正例中被分对的比例,衡量了分类器对正例的识别能力
三、特异性specifity
特异性:表示的是负例中被分对的比例,衡量了分类器对负例的识别能力
四、精确度precision

五、综合指标F-score

六、sklearn实现
from sklearn.metrics import accuracy_scorefrom sklearn.metrics import recall_scorefrom sklearn.metrics import confusion_matrixfrom sklearn.metrics import precision_scorefrom sklearn.metrics import roc_auc_scorey_true = [0, 0, 0, 1, 1, 1, 1, 1]y_pred = [0, 1, 0, 1, 0, 1, 0, 1]tn, fp, fn, tp = confusion_matrix(y_true, y_pred).ravel()acc = accuracy_score(y_true, y_pred) # 1.准确率recall = recall_score(y_true, y_pred) # 2.灵敏度/召回率specificity = tn / (tn+fp) # 3.特异性precision = precision_score(y_true, y_pred) # 4.精确度fmeasure = (2 * precision * recall / (precision + recall)) # 5.F-scoreroc = roc_auc_score(y_true, y_pred)
补充一个指标:roc,这个roc是曲线,上述的roc_auc_score(y_true, y_pred)是使用roc曲线计算出来的准确率

若有收获,就点个赞吧
0 人点赞
