节点嵌入:将节点映射到d维嵌入,这样图中相似的节点的嵌入靠得很近。
两个关键点:
- Encoder:将节点映射到低维向量,

- Similarity funcion:定义输入网络的关系如何映射到嵌入空间的关系中,

shallow encoders:一层数据转换,单一的隐藏层通过函数 将节点
将节点 映射到嵌入
映射到嵌入 ,即
,即

shallow embedding方法的限制:
- 需要
 个参数,节点之间不共享参数,每个节点有单独的嵌入;
个参数,节点之间不共享参数,每个节点有单独的嵌入; - 固有的转换,不能在训练中为节点生成看不见的嵌入;
- 不能结合节点的特征,许多图的特征我们应该加以利用。
文章节介绍Deep Graph Encoders,ENC(v)=图结构的多层非线性变换
注:所有这些deep encoders能够与节点相似函数结合(见下一章节)。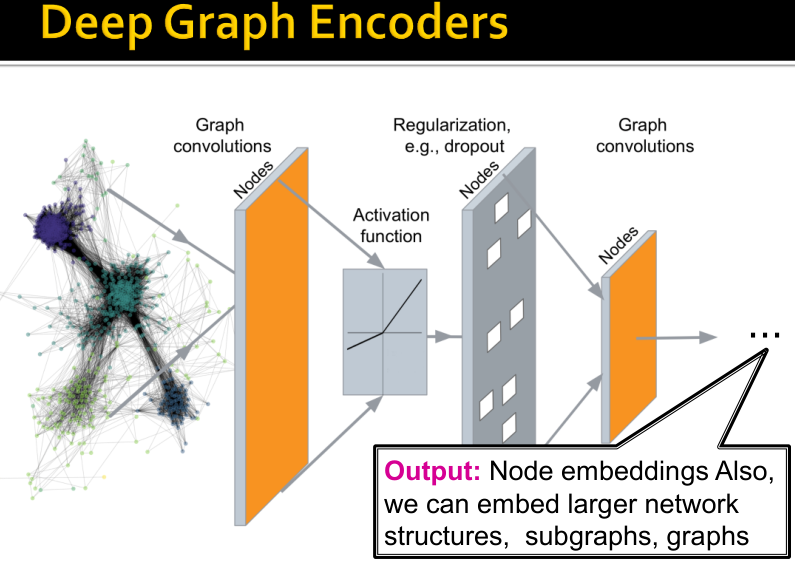
A naive approach是将邻接矩阵及相关特征传入深度神经网络中,但该想法有以下问题:
- O(N)个参数;
- 不能够处理图的不同大小;
-
Basics of Deep Learning for Graphs
内容:
局部网络的邻居:描述聚合策略,定义计算图
- 多层叠加:描述模型、参数、训练,如何拟合模型,无监督和有监督训练的简单例子
Setup:
设图 :
:
 是顶点集合
是顶点集合 是邻接矩阵(假设是0-1)
是邻接矩阵(假设是0-1) 是节点特征的矩阵
是节点特征的矩阵- 节点特征 :
- 社交网络:用户画像、用户图像等
- 生物网络:基因表达谱、基因功能信息
- 无特征:指示向量(一个节点的one-hot编码),常数1向量([1,1,…,1])
Graph Convolutional Networks
思想:节点的邻居定义一个计算图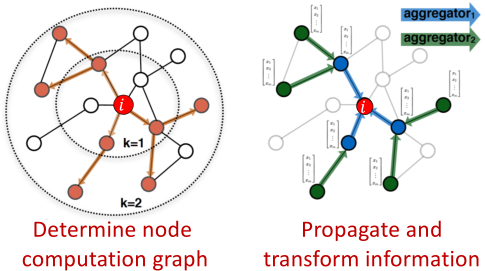
学习如何在图上传播信息以计算节点特征
聚合邻居的关键点:基于局部网络邻居生成节点嵌入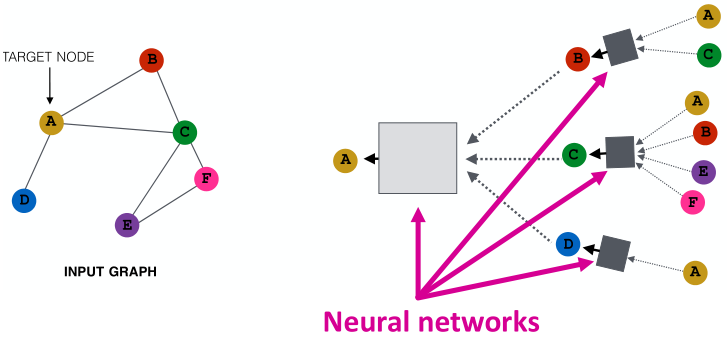
如上图所示,节点利用神经网络汇总来自邻居的信息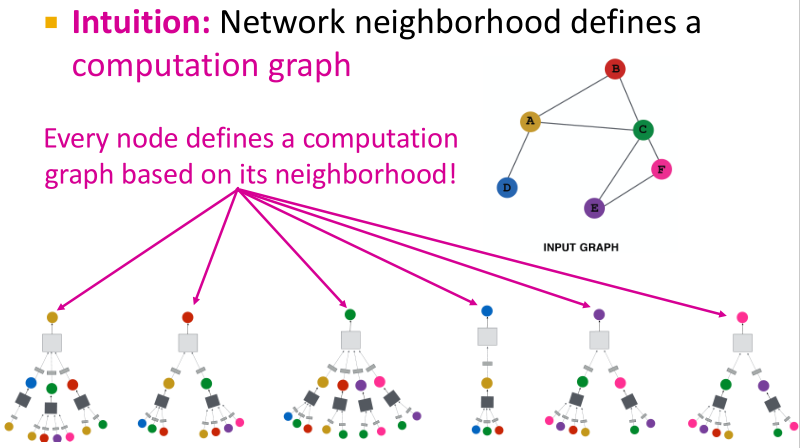
网络邻居定义一个计算图。每个节点基于其邻居定义一个计算图。
模型可以为任意深度:
- 在每层节点有嵌入
- 节点的Layer-0嵌入是其输入特征

- 从节点得到信息的Layer-K嵌入是K个距离
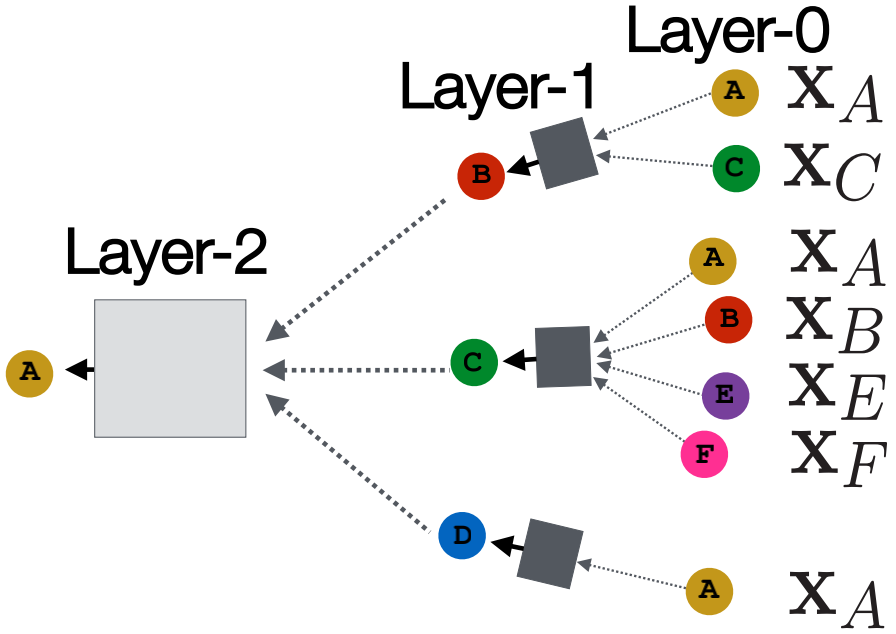
邻居聚合:关键的区别在于不同的方法如何将各层的信息汇总起来。
基本方法:对邻居的信息进行平均,并应用神经网络。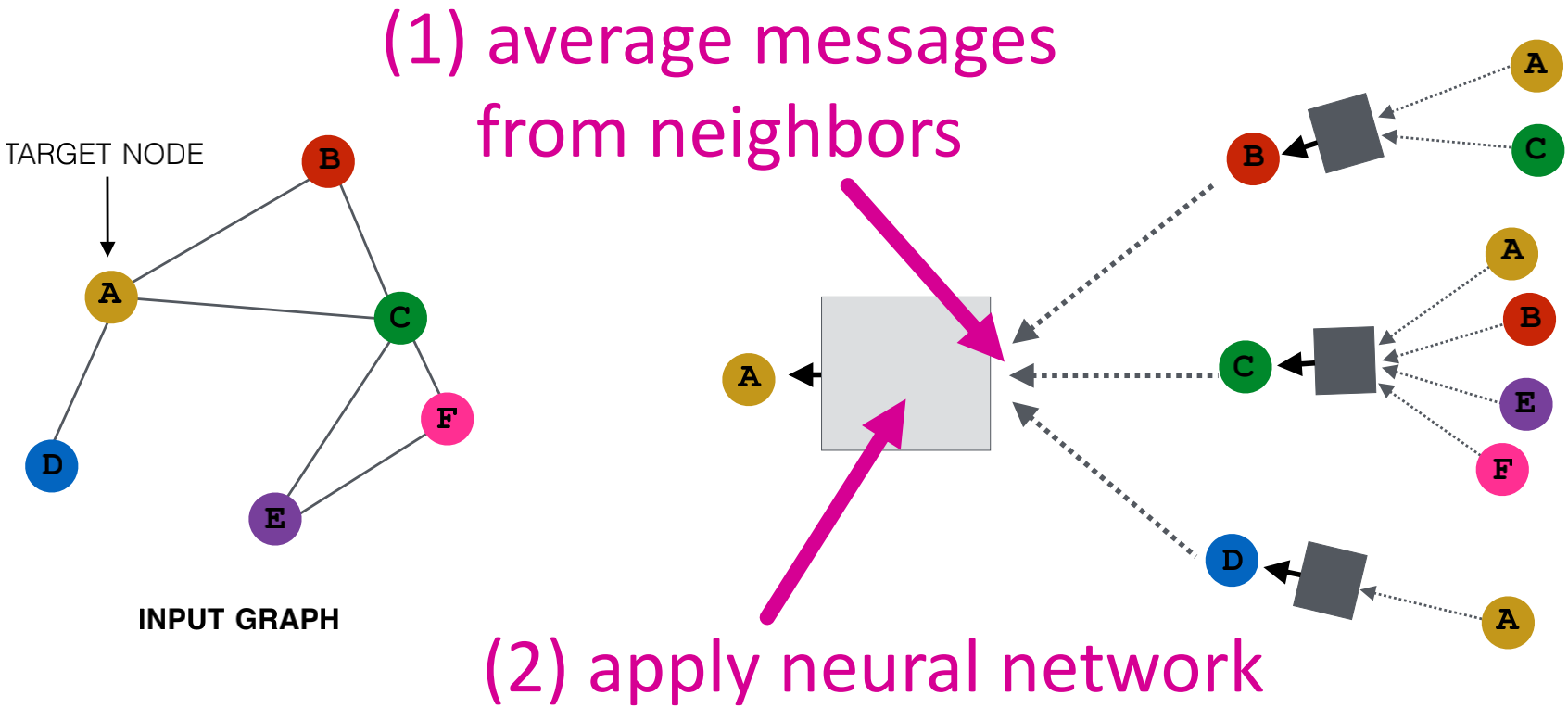

 是初始第0层嵌入是节点的特征
是初始第0层嵌入是节点的特征 是非线性函数,如ReLU
是非线性函数,如ReLU 是邻居的前一层嵌入均值
是邻居的前一层嵌入均值 是节点
是节点 的前一层嵌入
的前一层嵌入 是K层的邻居聚合后的嵌入
是K层的邻居聚合后的嵌入 与
与 是训练的权重矩阵,即我们需要训练估计出的值
是训练的权重矩阵,即我们需要训练估计出的值- 我们可以将这些嵌入放入任意损失函数中,然后使用随机梯度下降法来训练权重参数
- 等价地,向量形式为

无监督训练:
- 以无监督方式训练,仅使用图的结构,相似节点有相似的embeddings
- 无监督损失函数可以是任何形式,如基于Random walks(node2vec, DeepWalk, struc2vec)、Graph factorization、Node proximity in the graph的损失函数
有监督训练:以有监督任务形式直接训练模型,如节点分类。此时,
 节点类别标签
节点类别标签 节点嵌入的编码输出
节点嵌入的编码输出 分类权重
分类权重
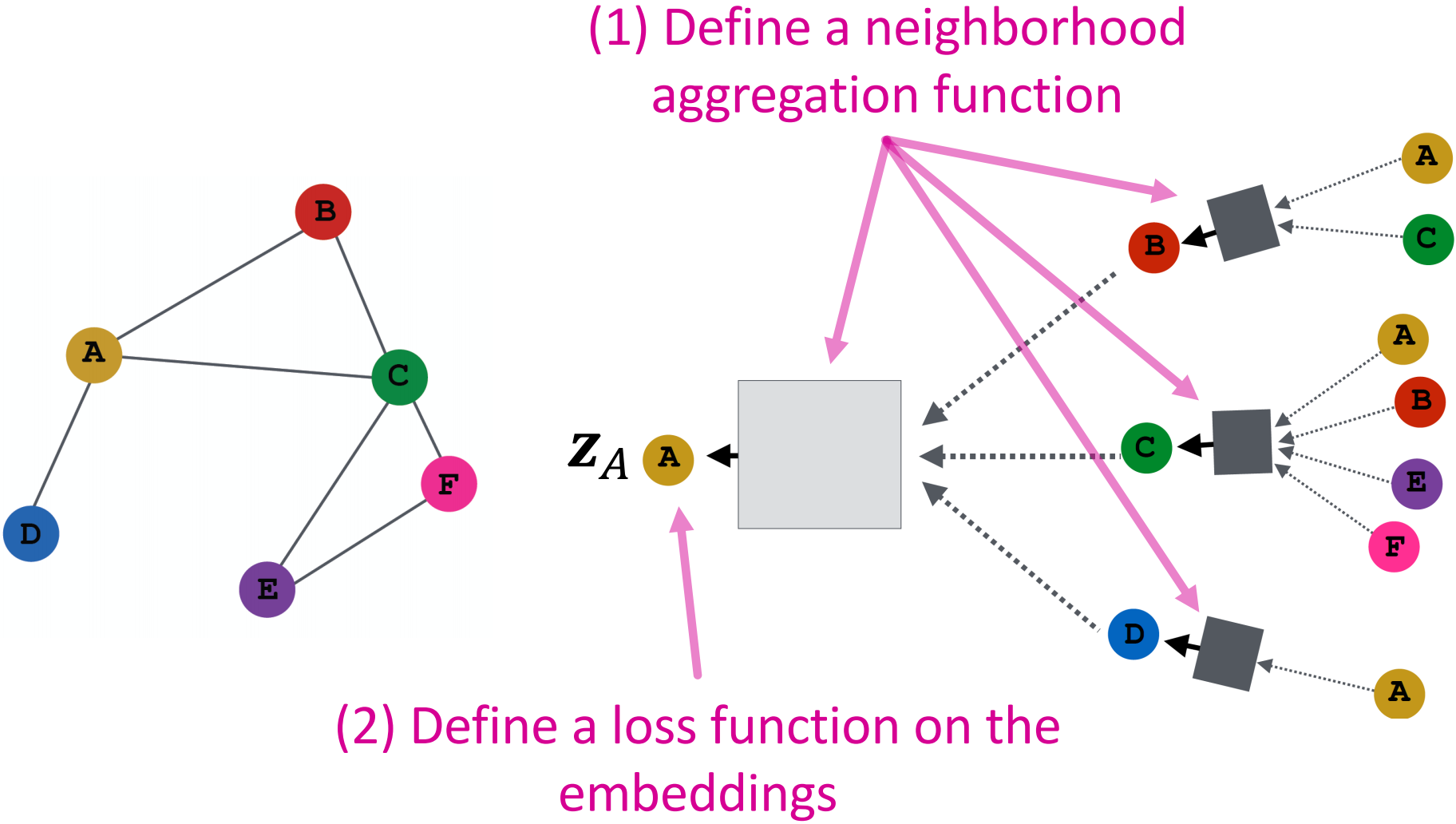
模型设计的概述:
- 定义邻居的聚合函数
- 定义嵌入的损失函数
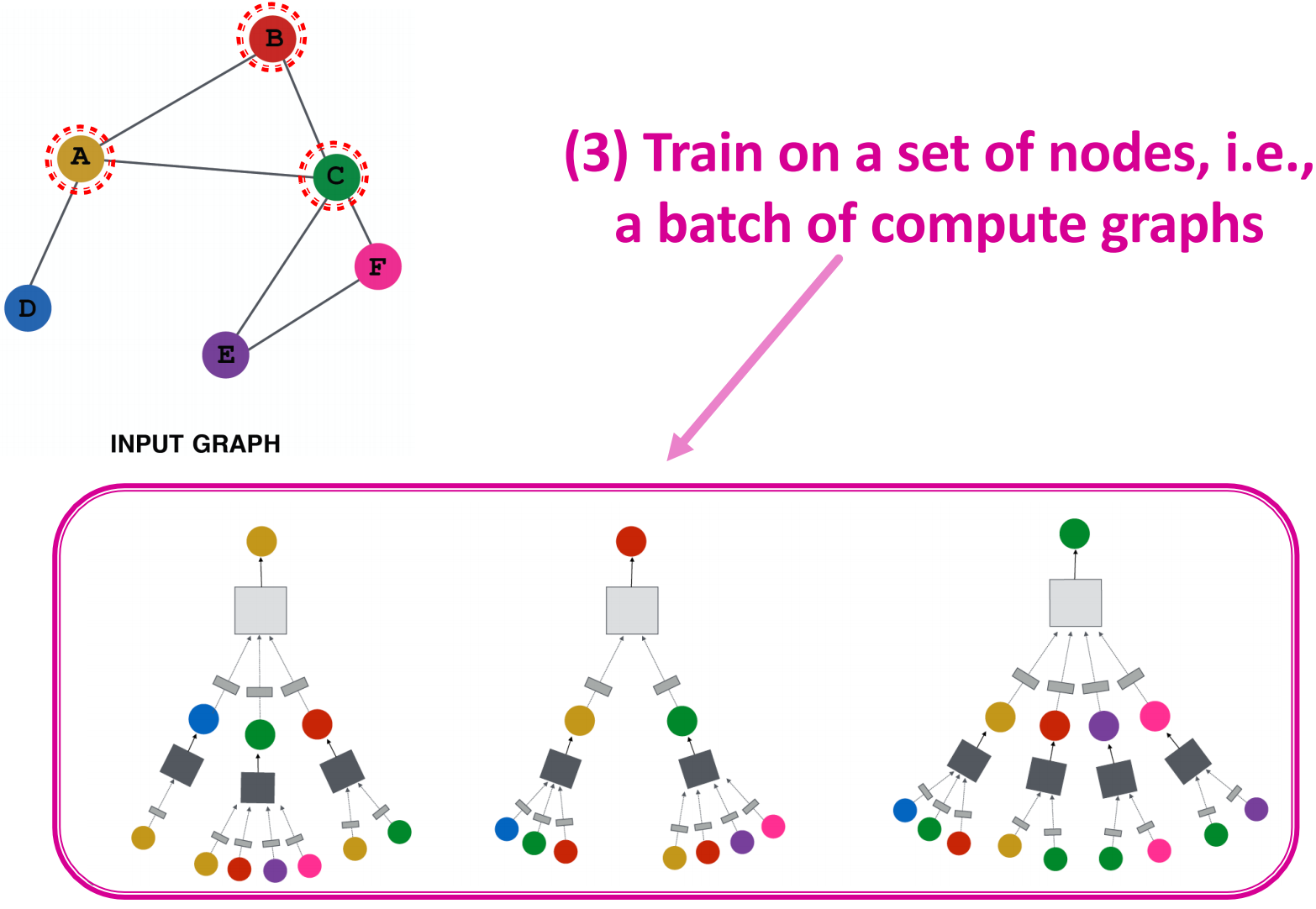
- 基于节点集来训练,即一批计算图
- 根据需要生成节点的嵌入(即使是我们从未训练过的节点)
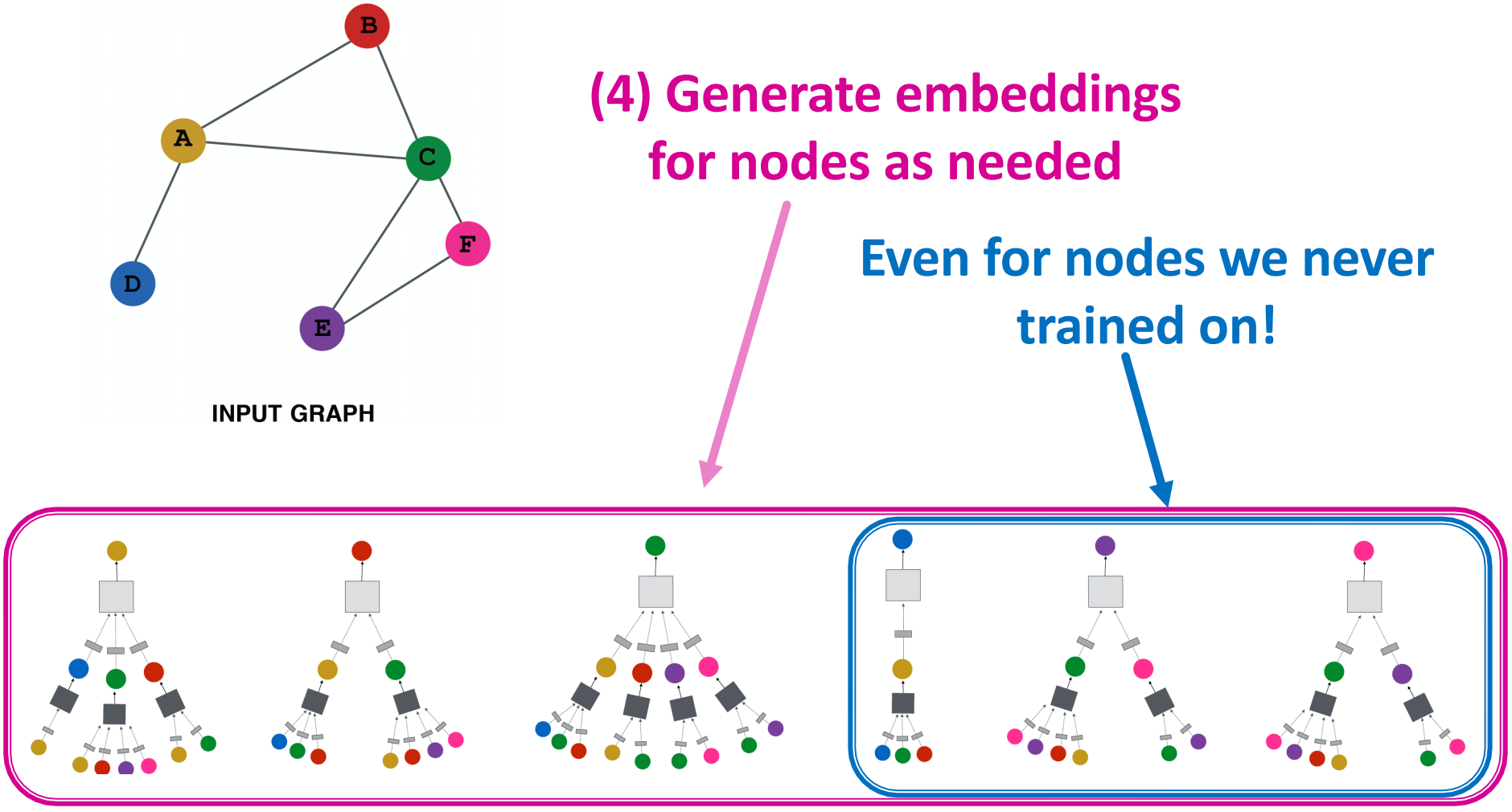
所有节点共享相同的聚合参数,模型参数的数量在 中是次线性的,我们可以将其泛化到看不见的节点上。
中是次线性的,我们可以将其泛化到看不见的节点上。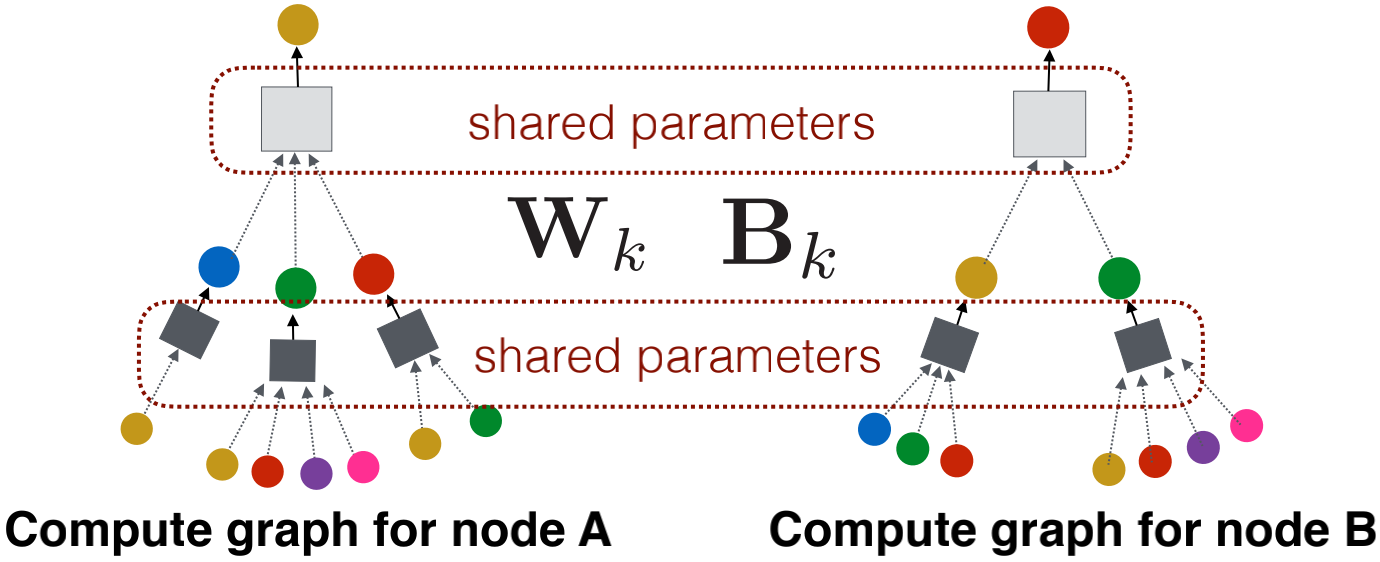
Inductive Capability:New Graphs、New Nodes
New Graphs:如,在模型生物体A的蛋白质相互作用图上进行训练,并在新收集的生物体B的数据上生成嵌入。
New Nodes:很多应用设置不断遇到以前没有的节点,如Reddit、YouTube、GoogleScholar等,需要动态地生成新的嵌入。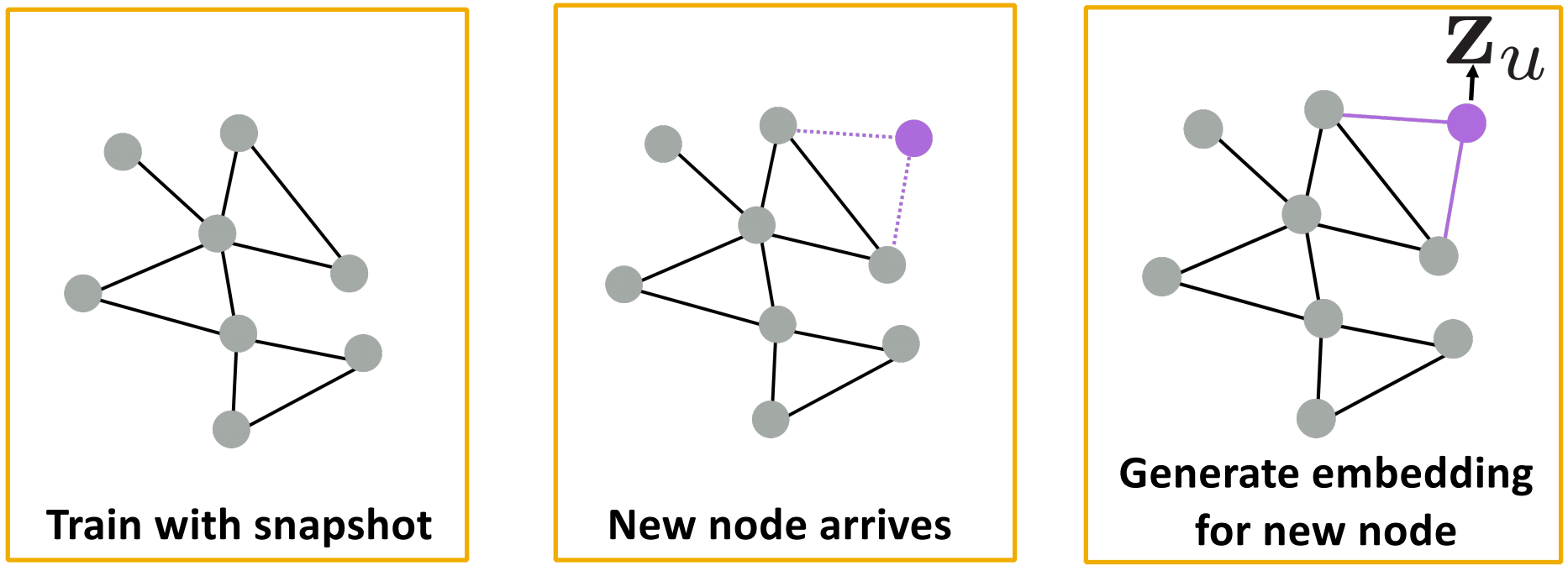
Graph Convolutional Networks and GraphSAGE
Inductive Representation Learning on Large Graphs. W.L. Hamilton, R. Ying, and J. Leskovec arXiv:1706.02216 [cs.SI], 2017.
目前为止,我们知道可以通过权重均值来聚合邻居信息,如何做得更好呢?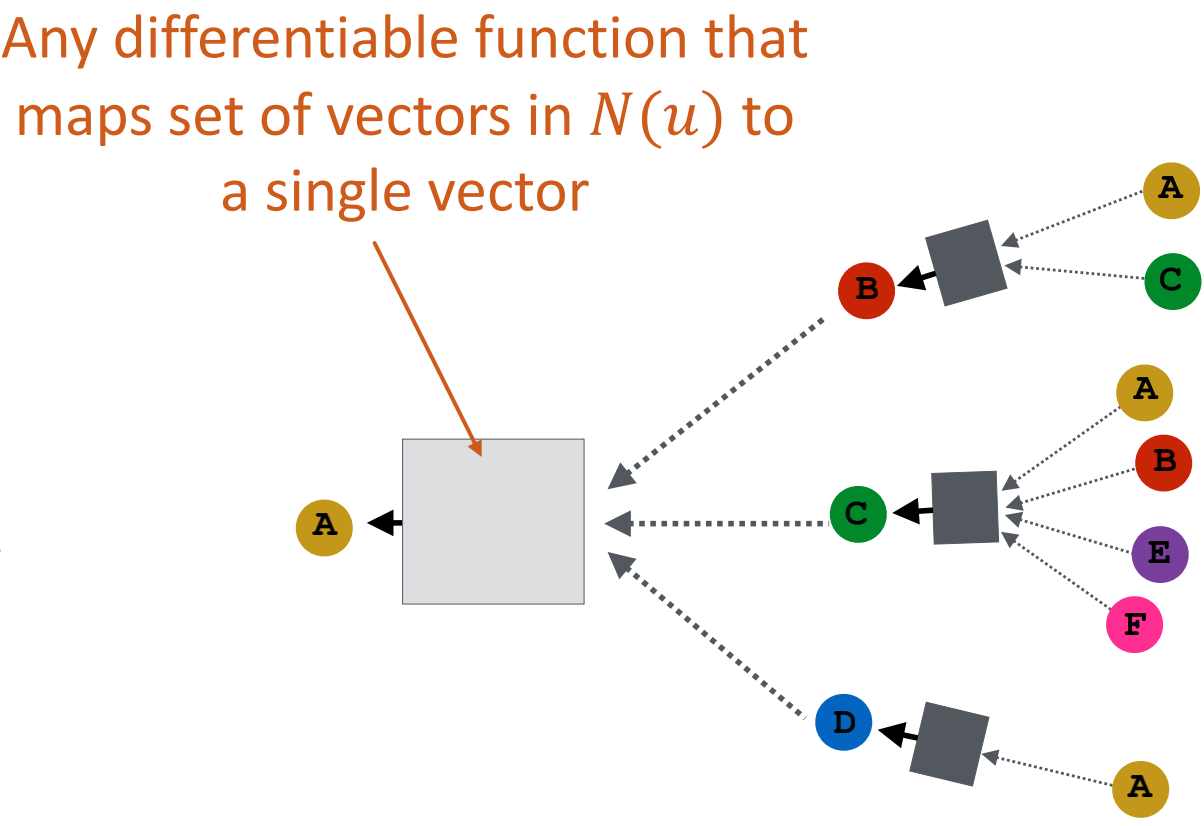
GraphSAGE想法: ,在每一层对每个节点嵌入进行L2归一化处理
,在每一层对每个节点嵌入进行L2归一化处理
简单的邻居聚合:
GraphSAGE方法:并联邻居嵌入和自嵌入,generalized aggregation。
邻居聚合的变体:
- 均值:取邻居的加权均值,

- 池化:变换邻居向量,并应用对称向量函数,,其中
 是element-wise mean/max
是element-wise mean/max - LSTM:使用LSTM来重新组合邻居,

GCN、GraphSAGE的总结:
关键点:基于局部邻居生成节点嵌入,使用神经网络将节点从邻居处得到的信息聚合。
- Graph Convolutional networks,基础变体,平均邻居信息,叠加神经网络;
- GraphSAGE,泛化对邻居的聚合。
有效的实现:
许多聚合通过(稀疏)矩阵操作能够有效实现。设 ,
,
另一个GCN例子(Kipf et al. 2017):
更多关于Graph Neural Networks的材料
教程与概述:
- Relational inductive biases and graph networks (Battaglia et al., 2018)
- Representation learning on graphs: Methods and applications (Hamilton et al., 2017)
Attention-based neighborhood aggregation:
- Graph attention networks (Hoshen, 2017; Velickovic et al., 2018; Liu et al., 2018)
Embedding entire graphs:
- Graph neural nets with edge embeddings (Battaglia et al., 2016; Gilmer et. al., 2017)
- Embedding entire graphs (Duvenaud et al., 2015; Dai et al., 2016; Li et al., 2018) and graph pooling
(Ying et al., 2018, Zhang et al., 2018)
- Graph generation and relational inference (You et al., 2018; Kipf et al., 2018)
- How powerful are graph neural networks(Xu et al., 2017)
Embedding nodes:
- Varying neighborhood: Jumping knowledge networks (Xu et al., 2018), GeniePath (Liu et al., 2018)
- Position-aware GNN (You et al. 2019)
Spectral approaches to graph neural networks:
- Spectral graph CNN & ChebNet (Bruna et al., 2015; Defferrard et al., 2016)
- Geometric deep learning (Bronstein et al., 2017; Monti et al., 2017)
Other GNN techniques:
- Pre-training Graph Neural Networks (Hu et al., 2019)
GNNExplainer: Generating Explanations for Graph Neural Networks (Ying et al., 2019)
Graph Attention Networks
回顾简单的邻居聚合:
图卷积的操作是:通过邻居
 聚合信息
聚合信息 是节点传给节点的信息的权重因子(重要性)
是节点传给节点的信息的权重因子(重要性)- 则
 是根据图的机构性质明确定义的
是根据图的机构性质明确定义的 - 则所有邻居
 对于节点来说都是等价重要的
对于节点来说都是等价重要的
我们能比简单的邻居聚合做得更好吗?能让权重因子的定义不那么明确吗?
下面介绍GAN模型。
GAN模型为图中每个节点的不同邻居指定任意的重要性,
计算图中每个节点的嵌入 遵循下面的一个注意力策略:
遵循下面的一个注意力策略:
 ,
, ,
, ,
,
下面介绍注意力机制 :
:
- 这种方法与的选择无关,如使用一个简单的单层神经网络,可以有需要估计的参数
- 的参数要联合训练,以端到端的方式将参数与权重矩阵(即神经网的其他参数)一起学习。
多头注意力:稳定注意机制的学习过程(Velickovic et al., ICLR 2018),给定层中的注意力操作独立复制R次(每个复制带有不同的参数),通过连接或相加将输出结果汇总。
注意力机制的性质:
- 主要优点是允许(隐式)指定不同邻居有不同的重要性值
- 计算效率高,通过图的所有边并行化计算注意力系数,所有节点的聚合能够并行化
- 存储效率高,稀疏矩阵的操作不需要多于
 存储;不论图多大,参数数量固定
存储;不论图多大,参数数量固定 - 非常局部化,仅考虑局部邻居网络
- Inductive capability,它是一个共享的边缘机制,不依赖于全局图结构。
GAT的例子:Cora Citation Net
上图是基于GAT的节点嵌入的t-SNE图,节点的颜色表示7个出版社类别,边的粗细表示节点 与节点
与节点 之间的标准化注意力系数,通过八个attention heads,
之间的标准化注意力系数,通过八个attention heads,
Example Application

Pin是某人从互联网上保存到他们自己创建的Board上的视觉书签,有图像、文本、链接。
Board是ideas的收藏,pins有共同点。
图:2B pins,1B boards,20B edges
图是动态的,在不对模型重新训练的情况下,需要适应新的节点。
有丰富的节点特征:内容、图片。
PinSage图卷积网络是为包含数十亿对象网络规模的Pinterest图中的节点(如Pins/图片)生成嵌入。
主要思想:从附近节点借来信息,如床栏图可能看起来像一个花园的栅栏,但大门和床很少相邻的图形。
Pin嵌入对于各种任务都是必不可少的,比如Pins的推荐、分类、聚类、排名等。
任务:推荐相关的pins给用户。学习节点嵌入 ,使得
,使得

挑战:(1)规模巨大,30亿个节点,200亿个边;(2)异质数据,丰富的图像和文本特征。
想要在30亿个pins中区分标签,使用越来越难的负样本,包括每个epoch的越来越难的负样本。
如何将节点嵌入的训练以及推理扩展到有数十亿节点和数百亿边的图中?(比以往任何图形神经网络应用的数据集大10,000倍)
主要创新点:
- 高效GPU批处理的子样本邻域
- 生产者-消费者CPU-GPU训练管道
- 负样本的课程学习
- 高效推理的MapReduce
三个主要创新点:
1、on-the fly(动态/实时)图卷积:(1)对节点周围的邻域进行采样,动态构建计算图。(2)围绕特定节点进行局部图卷积。(3)训练时不需要整个图。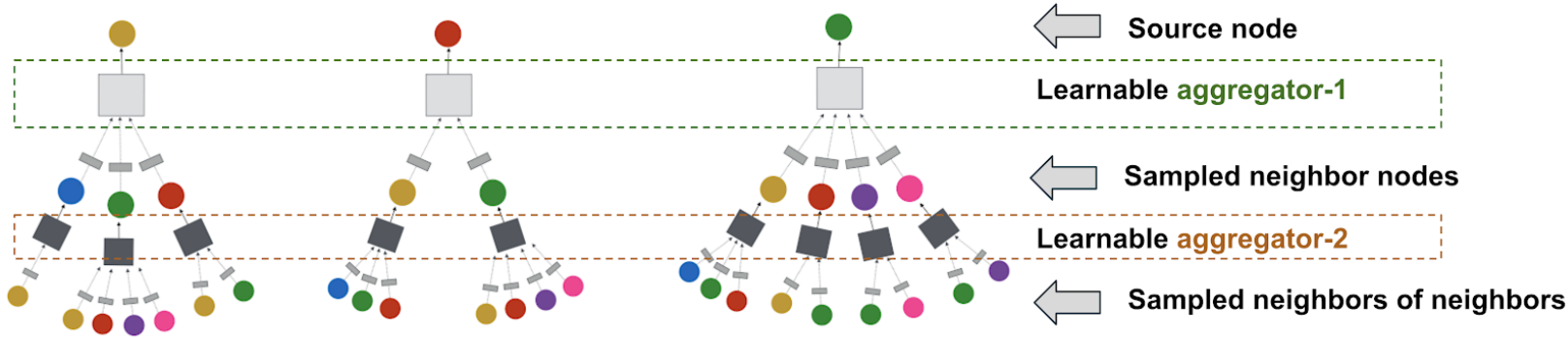
2、通过随机游走构建图卷积:(1)对整个邻域进行卷积是不可行的,如何选择节点的邻域进行卷积呢?(2)池化的重要性,通过模拟随机游走和选择访问次数最多的邻居来定义基于重要性的邻域。
3、高效的MapReduce推理:节点嵌入的自下而上聚合适合MapReduce,在MapReduce中,将所有节点的每个聚合步骤分解为三个操作,即map、join和reduce。
Baselines:
- Visual:CNN视觉嵌入的最近邻居推荐
- Annotation:Word2vec嵌入的最近邻居
- Combined:拼接嵌入,使用与PinSage完全相同的数据和损失函数
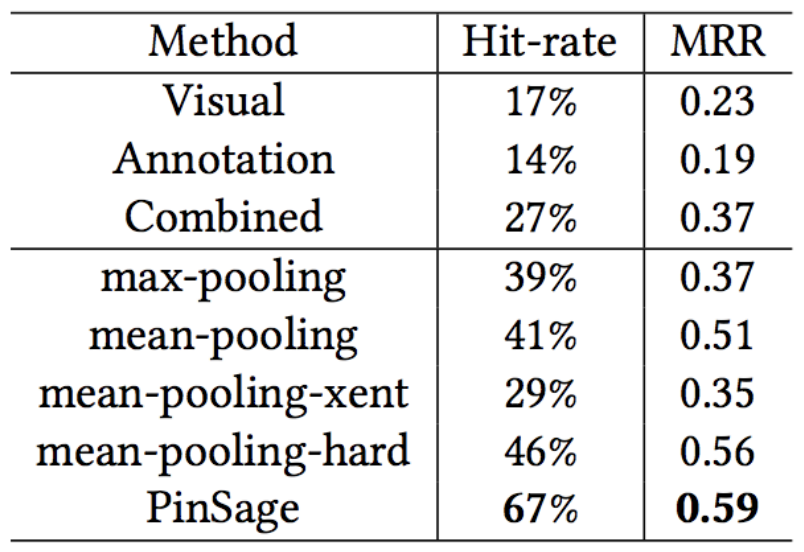
与最佳baseline相比,PinSage的命中率提升150%,MRR提升60%。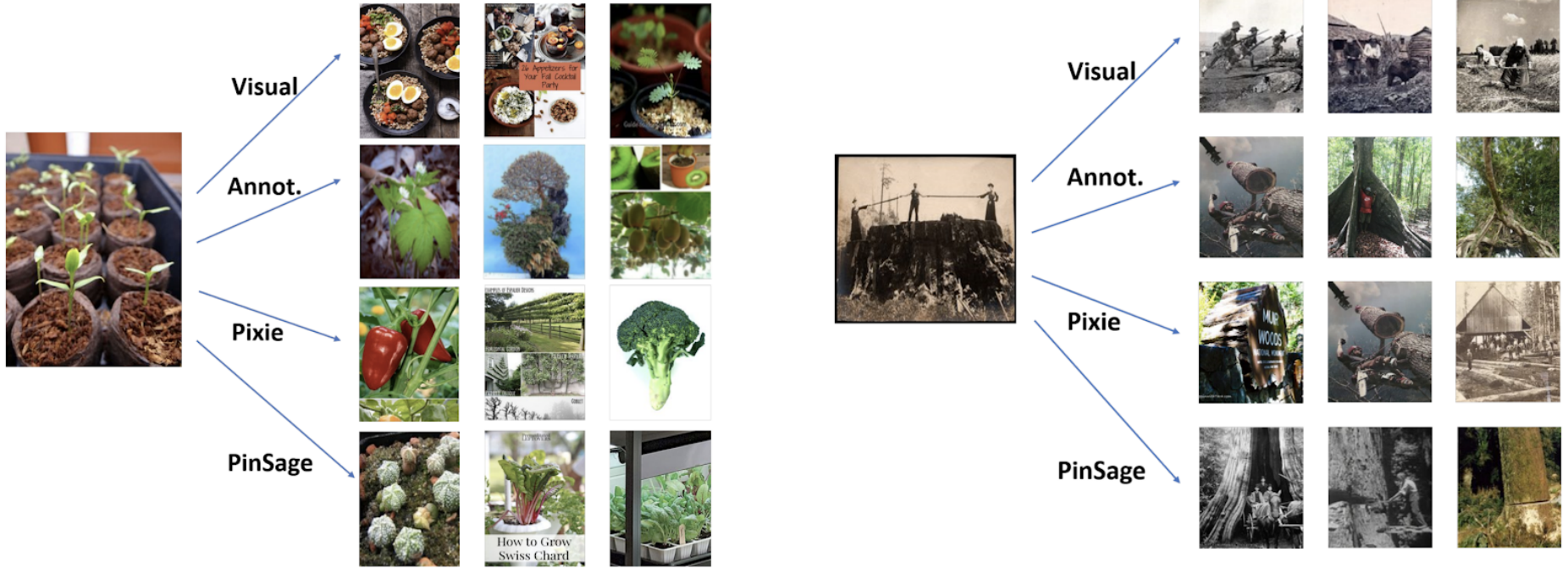
Pixie是一种纯粹基于图的方法,通过模拟从查询Pin开始的随机行走,使用偏向的随机行走来生成排名分数。得分最高的项目会被检索为推荐。
General Tips and Practical Demos
一般建议:
- 数据预处理很重要,使用重新标准化技巧,方差比例初始化,网络数据美白化。
- ADAM优化,ADAM很自然地处理了学习率衰减问题。
- ReLU激活函数效果不错
- 在输出层不用激活函数,如果用共享函数构建层,很容易犯错。
- 每层包括bias项。
- 64或128大小的GCN层已经足够了。
Debugging Deep Networks:
- Debug?!当训练过程中Loss或Accuracy不收敛时
- 对模型开发很重要:
- 训练数据过拟合,精度基本达到了100%或误差接近0,如果神经网络不能过度拟合一个数据点,那就有问题了
- 仔细检查损失函数
- 仔细检查可视化图
参考链接
知乎笔记:https://zhuanlan.zhihu.com/p/141232377
PPT:http://web.stanford.edu/class/cs224w/slides/08-GNN.pdf

若有收获,就点个赞吧
0 人点赞
