主要问题:给定一个一些节点带有标签的网络,如何预测网络中其他节点的标?这也是半监督节点分类问题。
- Collective classification:将网络中所有节点一起预测出标签,有以下三种模型
- Relational classification
- Iterative classification
- Belief propagation
网络中存在的关系
三种主要的依赖关系: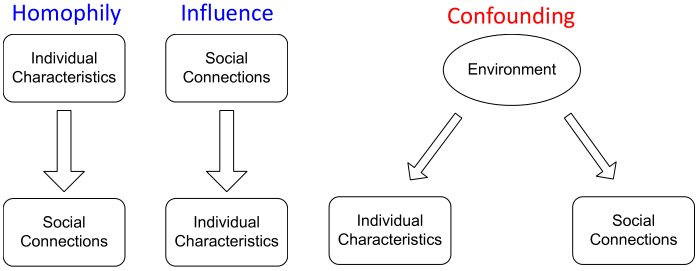
homophily 同质性;同质相吸原则;同质互动
confounding 混杂;交络;混杂设计
Homophily vs. Influence:
- homophily:个人倾向于与相似的人交往和联系。如喜欢音乐的人更可能建立一种社会联系(在音乐会上见面,音乐论坛上互动等)。
- Influence:社会关系会影响一个人的个体特征。如将自己独特的音乐偏好推荐给朋友,使他们中有人能够与自己有相同的爱好。

如何使用在图中发现的上述关系来预测节点的标签呢?
相似的节点一般都是靠近在一起,或者是直接相连的。Guilt-by-association:如果我与标签为X的节点相连,那么我很有可能也为标签X。
网络中对象O的分类标签依赖于:
- O的特征
- O的邻居的标签
- O的邻居的特征
如下图所示,给定一个图,一些带标签的节点,假设网络有同质性,找到余下节点的类别(红色/绿色)。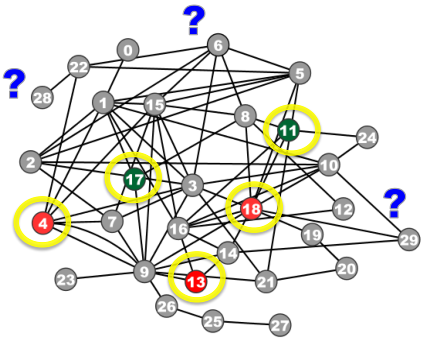
设 个节点的(加权的)邻接矩阵为
个节点的(加权的)邻接矩阵为 ,标签为
,标签为 ,其中1表示positive节点,-1表示negative节点,0表示unlabeled节点。
,其中1表示positive节点,-1表示negative节点,0表示unlabeled节点。
目的:预测unlabeled节点有多大可能为positive。
Collective Classification
直观感受:利用关联性对相互关联的节点进行同步分类。
几个应用:文件分类、词性标注、链接预测、OCR识别、Image/3D数据分割、传感器网络中的实体解析、垃圾邮件和欺诈检测等。
Collective classification overview:
马尔科夫假设:节点 的标签
的标签 依赖于其邻居
依赖于其邻居 的标签,即
的标签,即
Collective classification包括三个步骤:
- Local Classifier:分配初始标签。基于节点的属性或特征预测标签,标准的分类任务,不需要使用网络信息。
- Relational Classifier:捕获节点之间的相关性。基于邻居节点的属性或特征学习一个分类器,用来预测一个节点的标签,这一步骤使用到了网络信息。
- Collective Inference:通过网络传播相关性。迭代地对每个节点使用关系分类,直至邻居标签的不一致性最小化,网络结构很大程度上会影响最终的预测结果。
对任何网络来说,准确推断都是NP-hard问题。近似推断方法有关系分类、迭代分类、置信度传播,这三种都是迭代算法。
如果将每个节点都表示为一个离散随机变量,具有其类成员的联合分布函数为 ,则一个节点的边际分布是所有其他节点的的求和。
,则一个节点的边际分布是所有其他节点的的求和。
准确推断需要花费节点数的指数倍时间,因此我们缩小传播范围(如只传播邻居)和变量数量,通过聚合的方式来近似求解。
如何预测下图中浅色的节点的标签?
- 每个节点都有一个特征向量
 ;
; - 一些节点的标签给定(绿色的是+,蓝色的是-);
- 任务:基于所有特征和网络,预测
 。
。
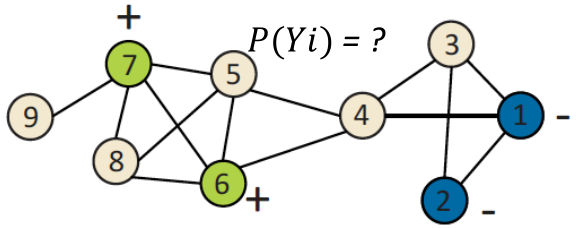
Probabilistic Relational Classifier
基本思想: 的类别概率是其邻居类别概率的加权平均。
的类别概率是其邻居类别概率的加权平均。
主要步骤:
- 对于有标签的节点,用真实标签初始化;
- 对于无标签的节点,随机初始化;
- 用随机顺序更新所有节点,直至聚合或达到最大的迭代次数。
对每个节点和标签 ,计算
,计算 ,其中
,其中 表示从节点到节点
表示从节点到节点 的权重。
的权重。
存在的问题:(1)不能保证聚合;(2)模型不能使用节点特征信息。
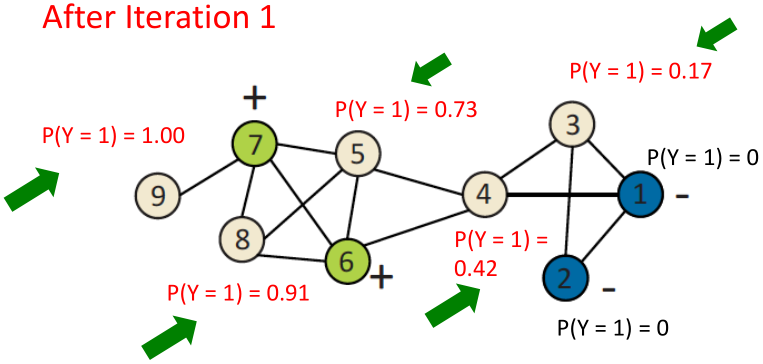
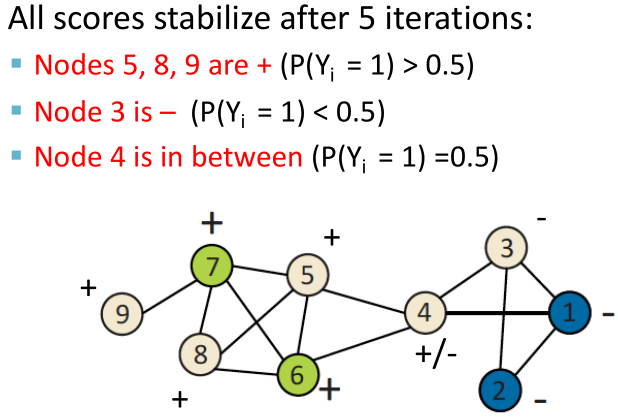
举例:
1、初始化:对所有有标签的节点赋予真实标签,无标签的节点随机分配标签。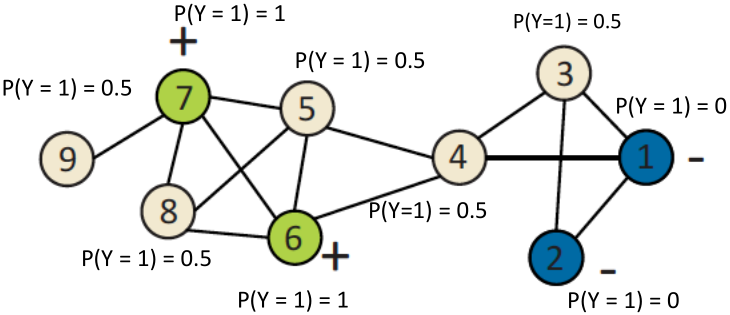
2、第一次迭代更新
对节点3, ,则
,则 ;
;
对节点4, ,则
,则 ;
;
对节点5, ,则
,则 ;
;
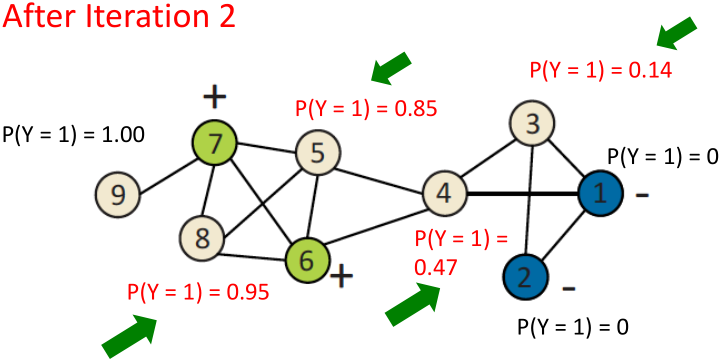
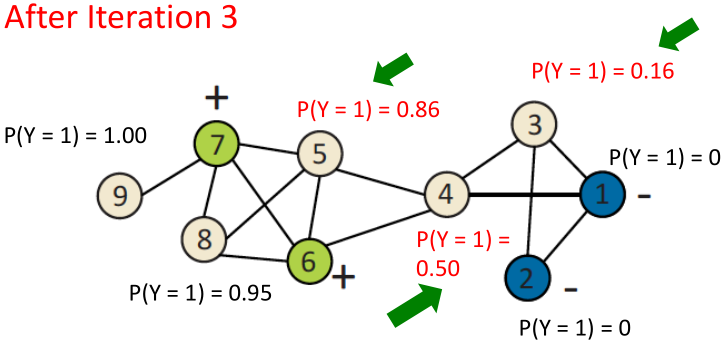
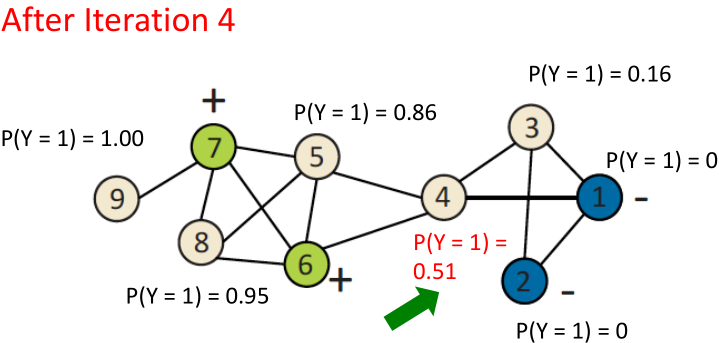
Iterative classification
介绍
主要思想:基于节点的属性与邻居集合的标签,对节点分类。
主要步骤:
- 对每个节点创建一个flat向量
 ;
; - 使用训练一个分类器;
- 节点可能有很多邻居节点,因此可以使用聚合函数,如计数、取模、比例、均值、是否存在等。
iterative classifiers的基本框架:
- Bootstrap phase:将每个节点转为flat向量,使用局部分类器
 (如SVM、KNN等)来计算最佳的;
(如SVM、KNN等)来计算最佳的; - Iteration phase:迭代至聚合。具体来说,对每个节点重复:(1)更新节点向量
 (2)更新标签到,这是一个艰巨的任务。如此迭代至类别标签稳定或达到最大迭代次数。
(2)更新标签到,这是一个艰巨的任务。如此迭代至类别标签稳定或达到最大迭代次数。 - 注:由于不能保证能达到聚合,因此最好使用最大迭代次数。
例子:网页分类
 表示单词是否出现,Baseline是基于单词训练一个能分类网页的分类器(如KNN)。
表示单词是否出现,Baseline是基于单词训练一个能分类网页的分类器(如KNN)。
同样的单词,但是有不同的链接结构。基于单词的分类器会给出同样单词不同连接结构相同的标签,如何改进呢?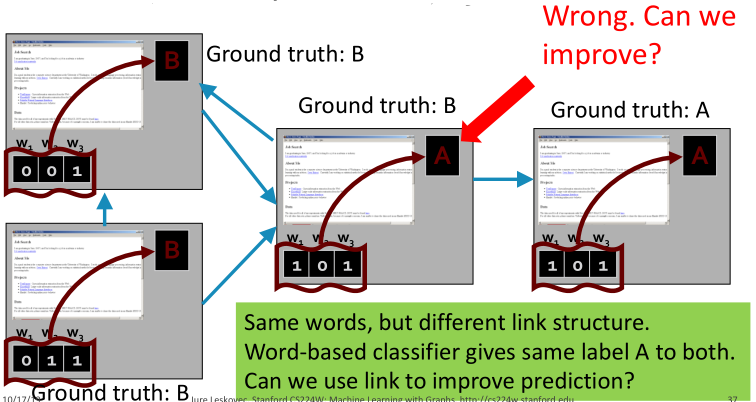
对每个节点都添加一个邻居标签向量 ,其中
,其中 。
。
如果至少有一个进来的网页被标记为A,则 。
。 也有同样的定义。
也有同样的定义。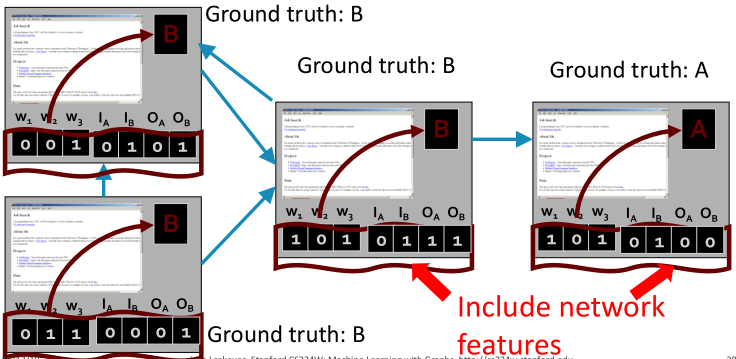
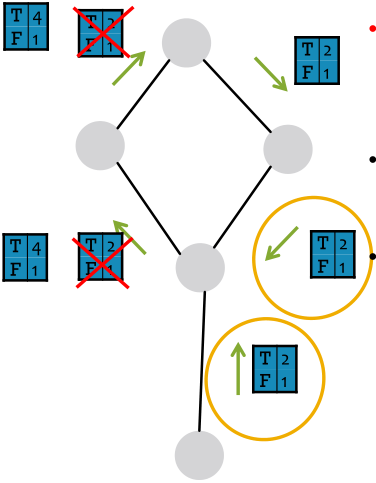
训练集:
对于不同的训练集,训练两个分类器:
- 仅是词向量(绿色圈圈)
- 单词和连接向量(红色圈圈)
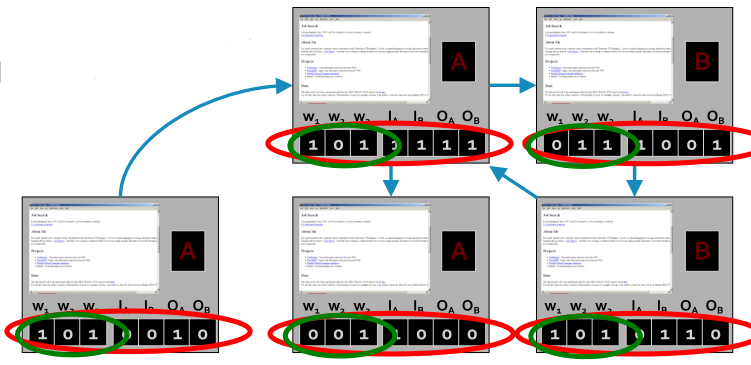
测试集:
使用训练的词向量分类器做测试集上做bootstrap。
迭代:(1)对所有节点,更新邻居向量。(2)对所有节点重新分类。
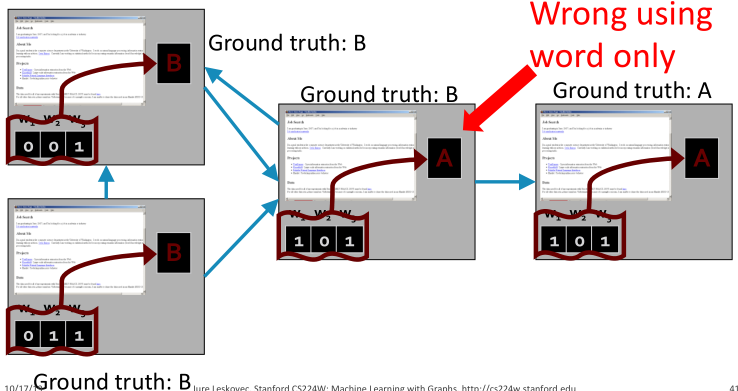
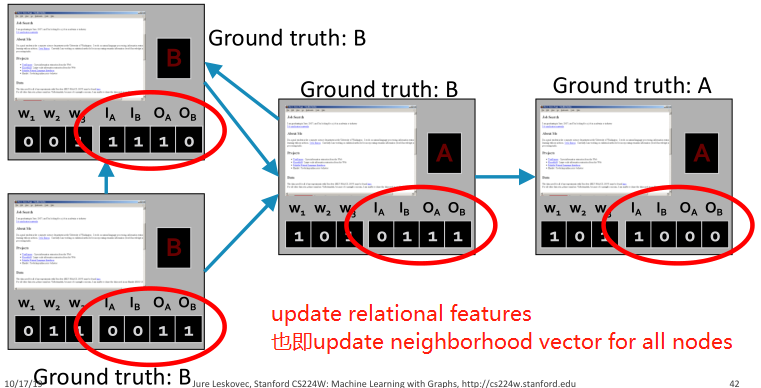
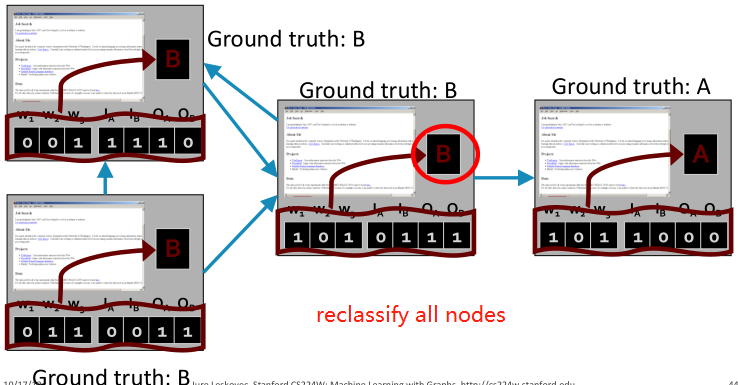
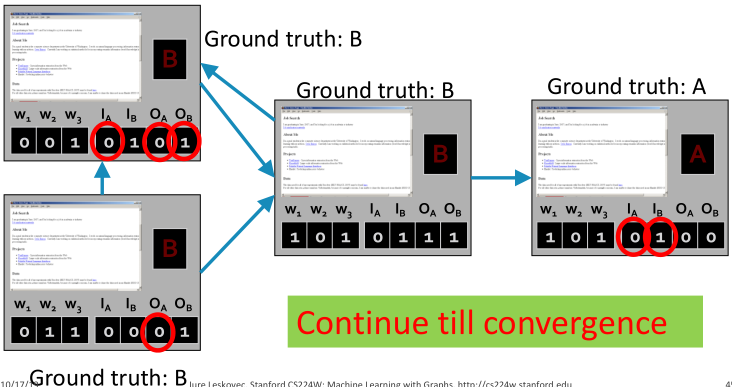
Application of iterative classification framework fake reviewer/review detection
REV2: Fraudulent User Prediction in Rating Platforms
虚假评论垃圾邮件检测
- 行为分析:个体特征、位置、登陆时间、会话历史等。
- 语言分析:叠词的使用,大量的自述,错别字的比率,许多协议词的使用等。
- 个体行为、评论内容,都容易造假
- 难以伪造的是:图结构。图能够捕捉评论者、评论、店铺之间的关系。
问题设定
输入:bipartite rating graph as a weighted signed network,节点是用户、产品,边是-1~1之间的评级。
输出:给出假评级的用户集合。
REV2 Solution Formulation
构建了三种得分fairness、reliabilty、goodness,不断迭代更新这三个得分直至稳定,就可以判断哪些用户是虚假评论的用户。
基本思想:用户、产品、评级有内在的质量得分,用户有公平的得分(fairness),产品有好的得分(goodness),评级有可靠的得分(reliability)。
所有的值都是未知的,如何同时计算所有节点和边的值呢?
解决方法:迭代分类。
固定goodness和reliability,则fairness更新: ;
;
固定fairness和reliability,则goodness更新: ;
;
固定fairness和goodness,则reliability更新:
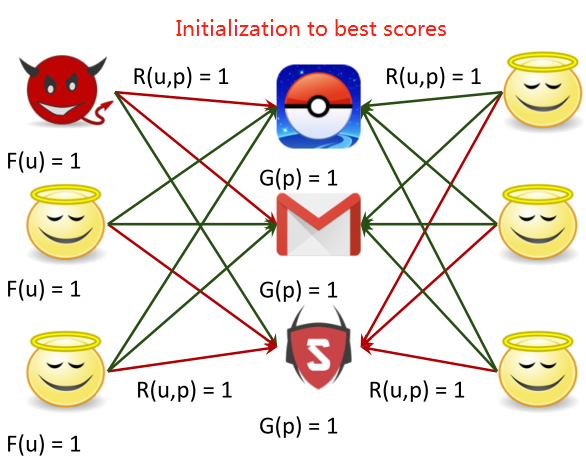
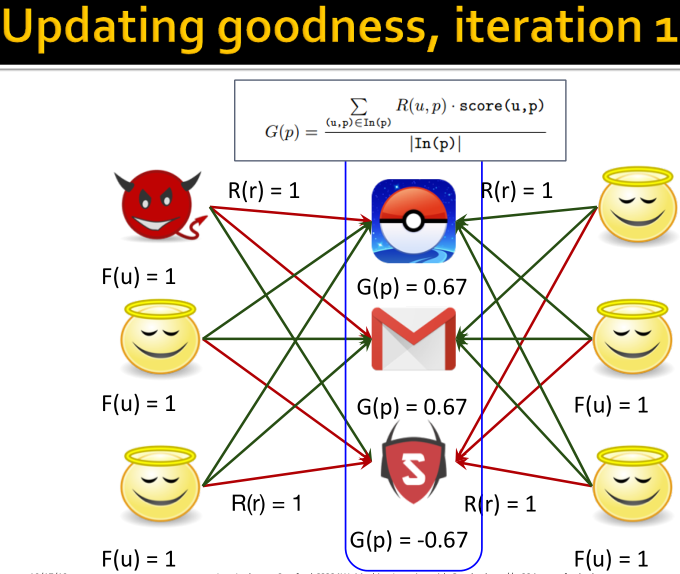
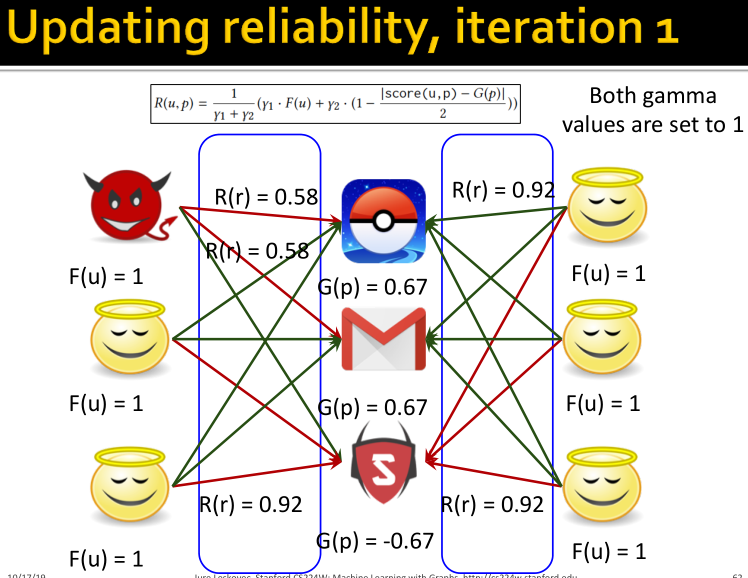
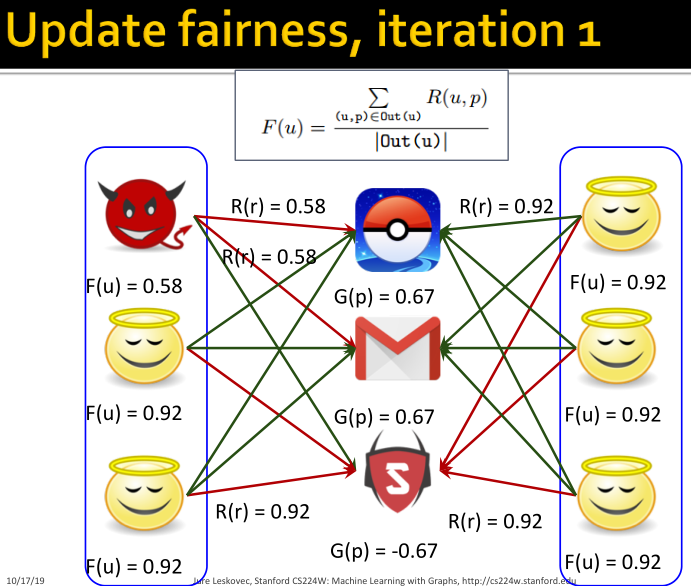
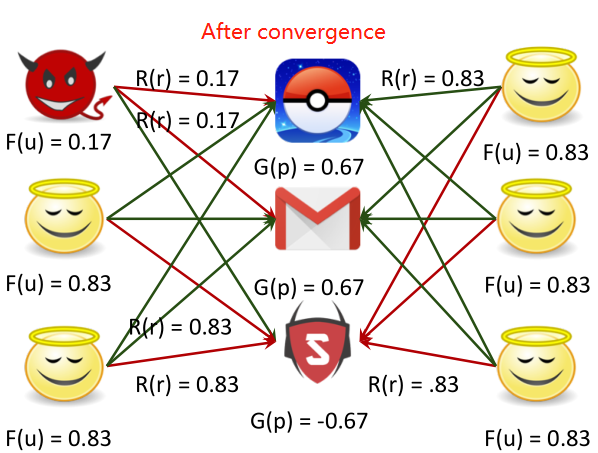
REV2方法的性质:
- 能够保证收敛;
- 直到收敛的迭代次数有上限;
- 时间复杂度:与图中的边数成线性关系。
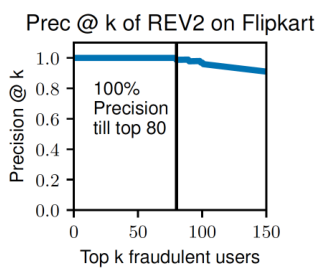
上图所示模型的效果,低fairness的用户等于欺诈者。150最低的fairness用户中,有127个是真是欺诈者。
Collective Classification: Belief propagation
Loopy Belief Propagation
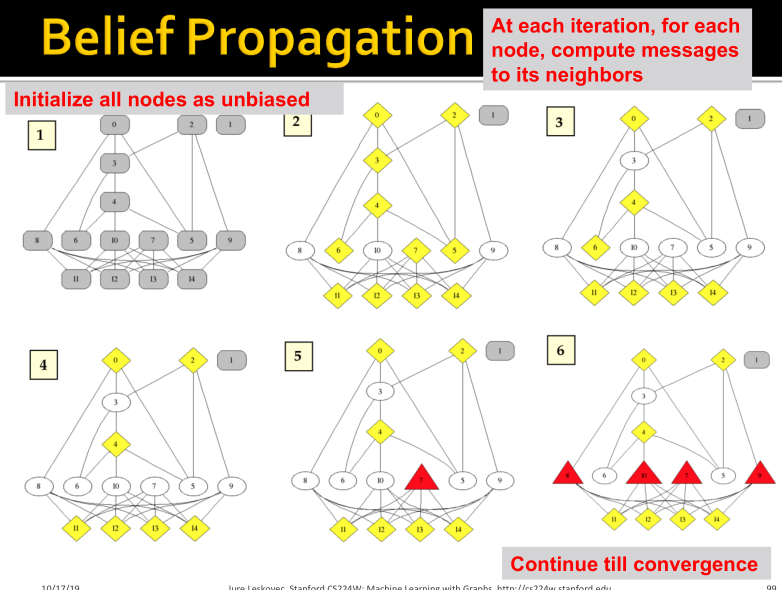
Belief Propagation是一种动态规划方法,用于回答图模型中的条件概率查询。在这个迭代过程中,相邻变量之间相互 “对话”,传递信息。当达成共识后,计算最终belief。
任务:计算图中节点的个数。
条件:每个节点只能与其邻居相互作用。
如,直线图:
解决方法:每个节点都会监听来自邻居的消息,更新消息,并将其转发。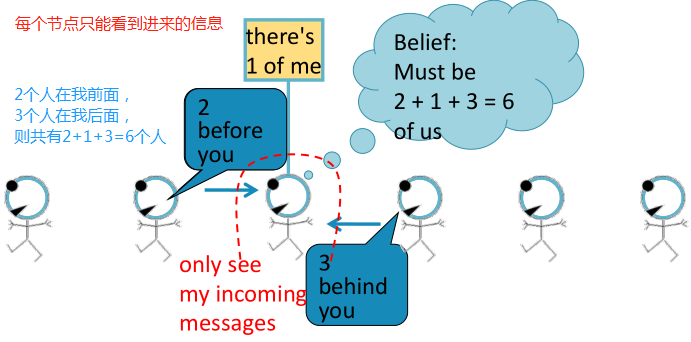
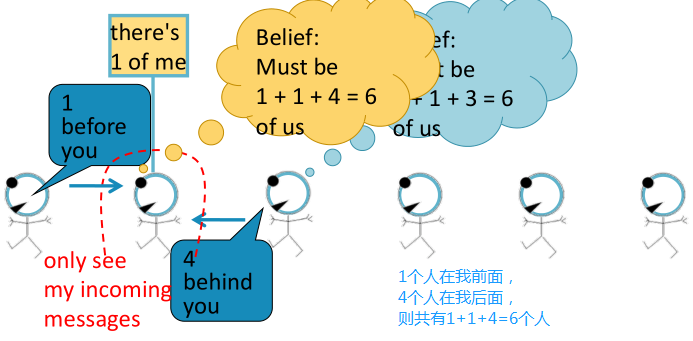
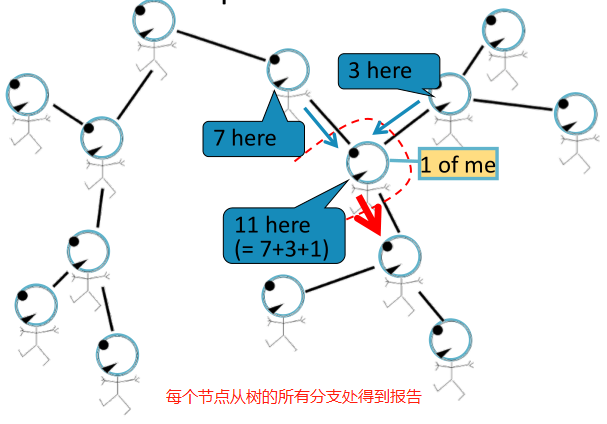
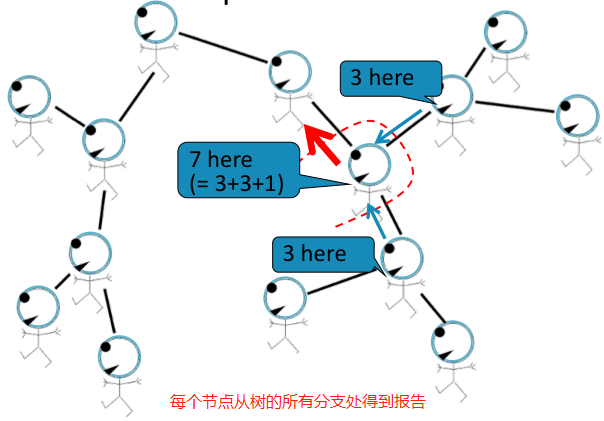
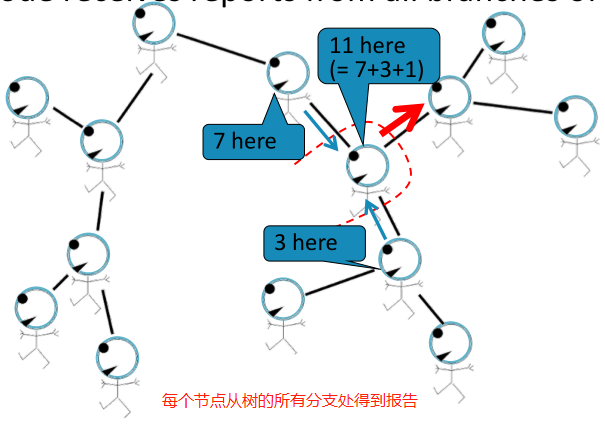
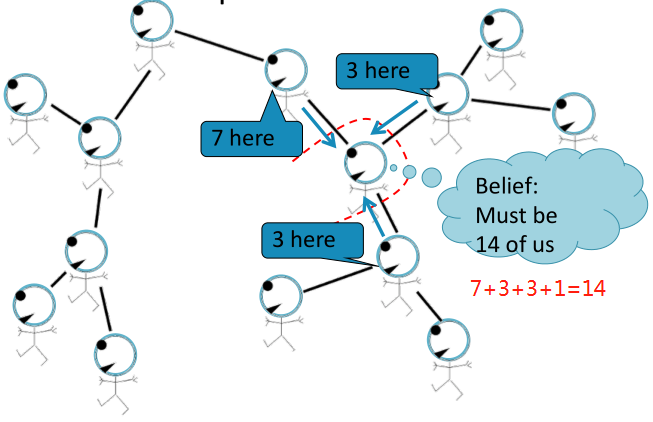
Loopy BP algorithm
如下图所示,会给传送什么信息呢?
- 取决于从其邻居
 处听到了什么信息;
处听到了什么信息; - 每个邻居给传送其认为的信息。
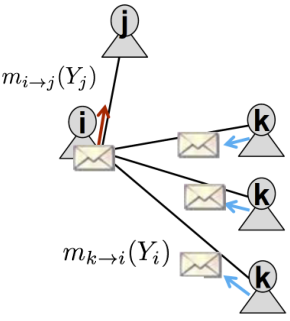
记号:
- Label-label potential matrix
 :一个节点与其邻居之间的依赖关系。
:一个节点与其邻居之间的依赖关系。 =在给定邻居节点处于状态下,节点处于状态
=在给定邻居节点处于状态下,节点处于状态 下的概率。
下的概率。 - Prior belief
 :节点处于状态下的概率为
:节点处于状态下的概率为 。
。  表示从节点来估计节点处于状态
表示从节点来估计节点处于状态 的概率。
的概率。 表示所有状态的集合。
表示所有状态的集合。
Loopy BP算法步骤:**
- 初始化所有的messages为1;
- 对每个节点迭代计算:

- 迭代收敛后,
 节点处于状态下的belief,
节点处于状态下的belief,
Loopy Belief Propagation:
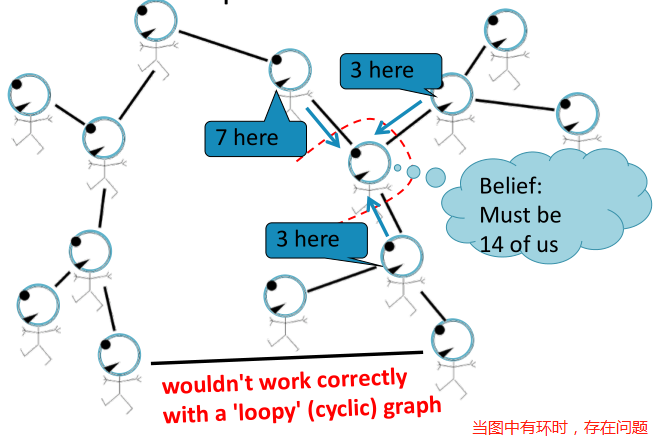
如果我们的图有圈圈怎么办?
从不同子图得到的信息不再独立,我们可以运行BP,因为它是局部算法,无法处理遇到的圈圈问题。
会出现什么样的问题?
- 消息循环往复:2,4,8,16,32,…越来越相信这些变量是T;
- BP错误地将此消息视为变量为T;
- 认为这两个信息是独立的,因此将这两个信息相乘。但是这两个信息并不是来自图中独立的部分,它们之间通过闭环是相互影响的。
- 下图所示是一个极端的例子,在实际图中,闭环的影响是微弱的。因为闭环是很长的或者包括至少一个较弱的相关性。
Belief Propagation的优缺点:**
优点:
- 容易编程与并行化计算;
- 一般来说,能够应用到任何图模型上。
缺点:
- 不能保证收敛,尤其是存在许多闭环的时候。
potential functions(parameters):
- 需要训练去估计;
- 基于梯度优化学习:在训练过程中发生收敛问题。
Application of Belief Propagation: Online Auction Fraud
Netprobe: A Fast and Scalable System for Fraud Detection in Online Auction Networks
Pandit et al., World Wide Web conference 2007
在线拍卖欺诈:
拍卖网站上有有吸引力的拍卖目标,2006年占美国联邦互联网犯罪投诉中心投诉的63%,每个事件的平均损失为385美元,通常为未交付欺诈。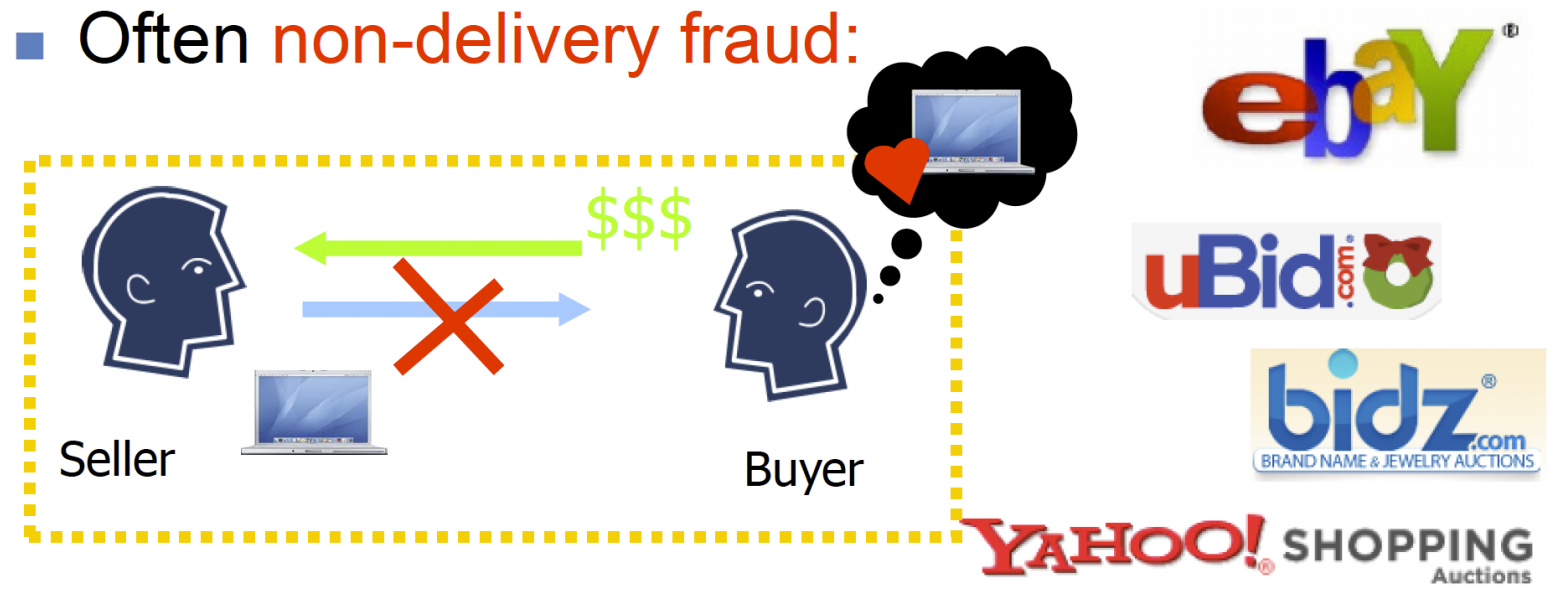
没有足够的解决方案来查看个人特性:用户属性、地理位置、登录时间、会话历史记录等。
每个用户都有一个信誉评分,用户通过反馈对彼此进行评价。问题是诈骗者会如何玩弄反馈系统?
用户的拍卖角色:
- 他们会提升对方的声誉吗?答:不会,因为如果一个欺诈者被捕捉,其他人也会被捕捉到的。
- 他们形成near-bipartite cores(两种角色):(1)帮凶,真实交易,看起来合法;(2)诈骗者,与同伙交易,诚实欺诈。
如何找到near-bipartite cores?如何发现honest、accomplice、fraudster这三个角色?(accomplice 共犯;帮凶;同谋)答:使用belief propagation。
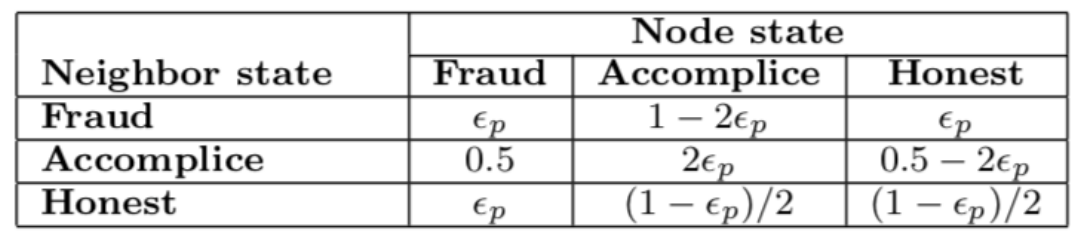
如何设置BP参数?
- 先验beliefs:先验知识,unbiased if none
- compatibility potential兼容潜力:通过观察
总结
三种collective分类算法:
- Relational models:邻居属性的加权平均,无法使用节点的属性。
- Iterative classification:使用自己的与邻居的标签更新每个节点的标签,考虑了节点的属性。
- Belief propagation:基于自身邻居节点的belief,通过信息传递来更新每个节点的belief。
参考链接
知乎笔记:https://zhuanlan.zhihu.com/p/140305723
PPT:http://web.stanford.edu/class/cs224w/slides/06-collective.pdf

若有收获,就点个赞吧
0 人点赞
