该章节前面介绍了Recitation: Snap.py and Google Cloud tutorial,其他Python的图网络包:DGL、Pytorch geometric(PyG)、networkx、阿里开源的Euler等。
这一节的任务:
- Subgraphs:定义、找到Motifs与Graphlets
- 网络中的结构作用:结构角色发现法——RolX
- 发现结构角色及其应用:(1)结构相似性;(2)角色概括和迁移学习;(3)理解角色。
isomorphism 类质同象;同形性;同型
isomorphic 同构;同构的;同型的
topologically 拓扑地
Subgraphs
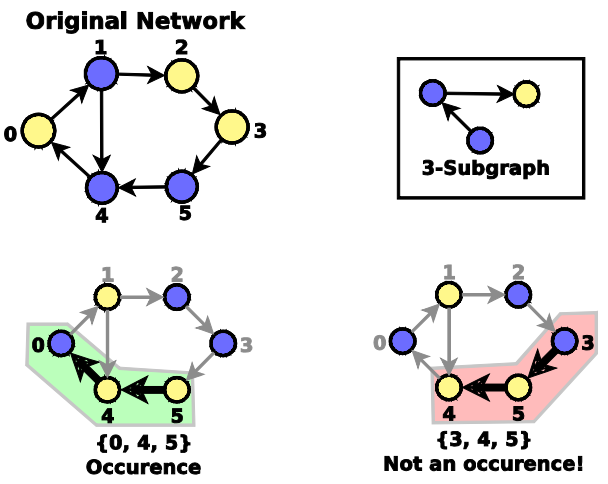
subnetworks或subgraphs:是网络的组成部分,具有描述和区分网络的能力。
考虑所有可能的(非同构)大小为3的有向子图:
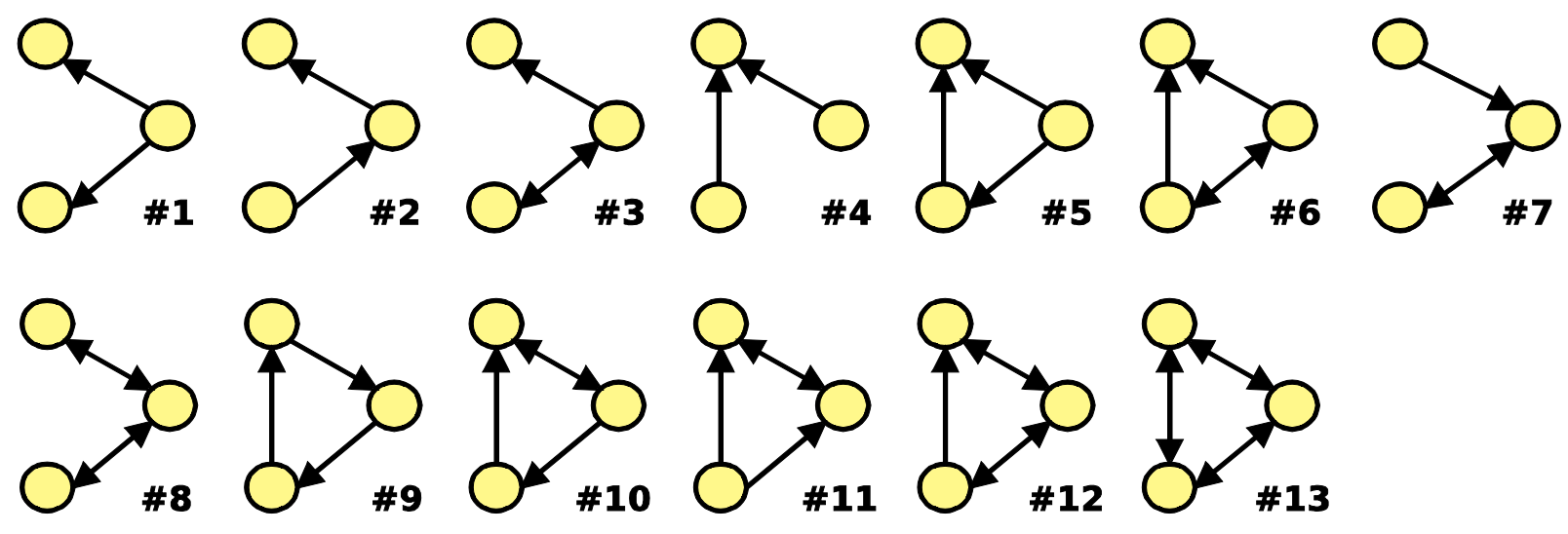
对于每个子图,假设有一个度量标准,能够对子图的“重要性”进行分类,正值表示过度表示,负值表示表示不足。我们创建一个网络重要性字典,该字典包括所有子图类型重要性取值,因此可以比较不同网络中子图的重要性。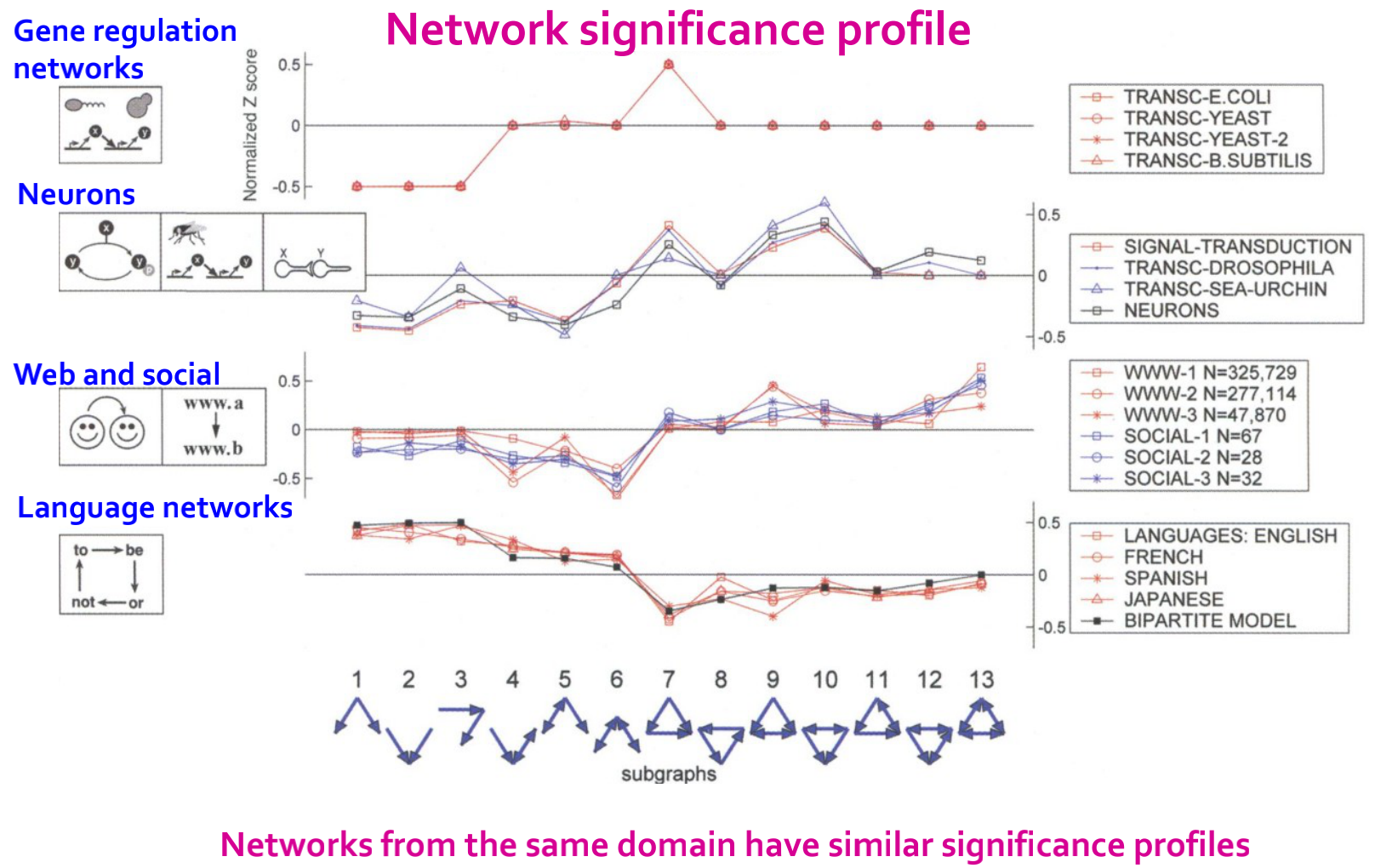

Motifs
Network motifs: “recurring, significant patterns of interconnections”
如何定义一个网络的motif?
- Pattern:小的子图,有某种模式(某种特定的结构);
- Recurring:高频率出现;
Significant:比想象中更为重要(比如说对比随机图来说,出现的频率要更高)。**
为什么需要Motifs?
帮助我们了解网络是如何运作的;
-
Motifs举例
(1)Feed-forward loops:
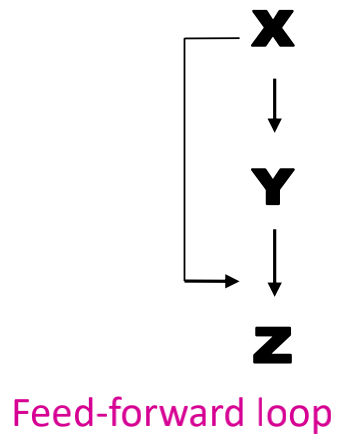
(2)Parallel loops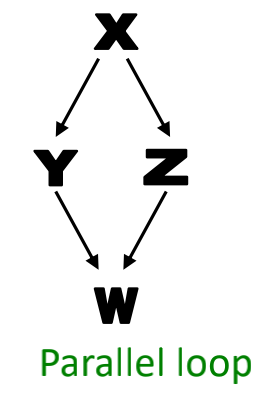
(3)Single-input modules
发现Motifs
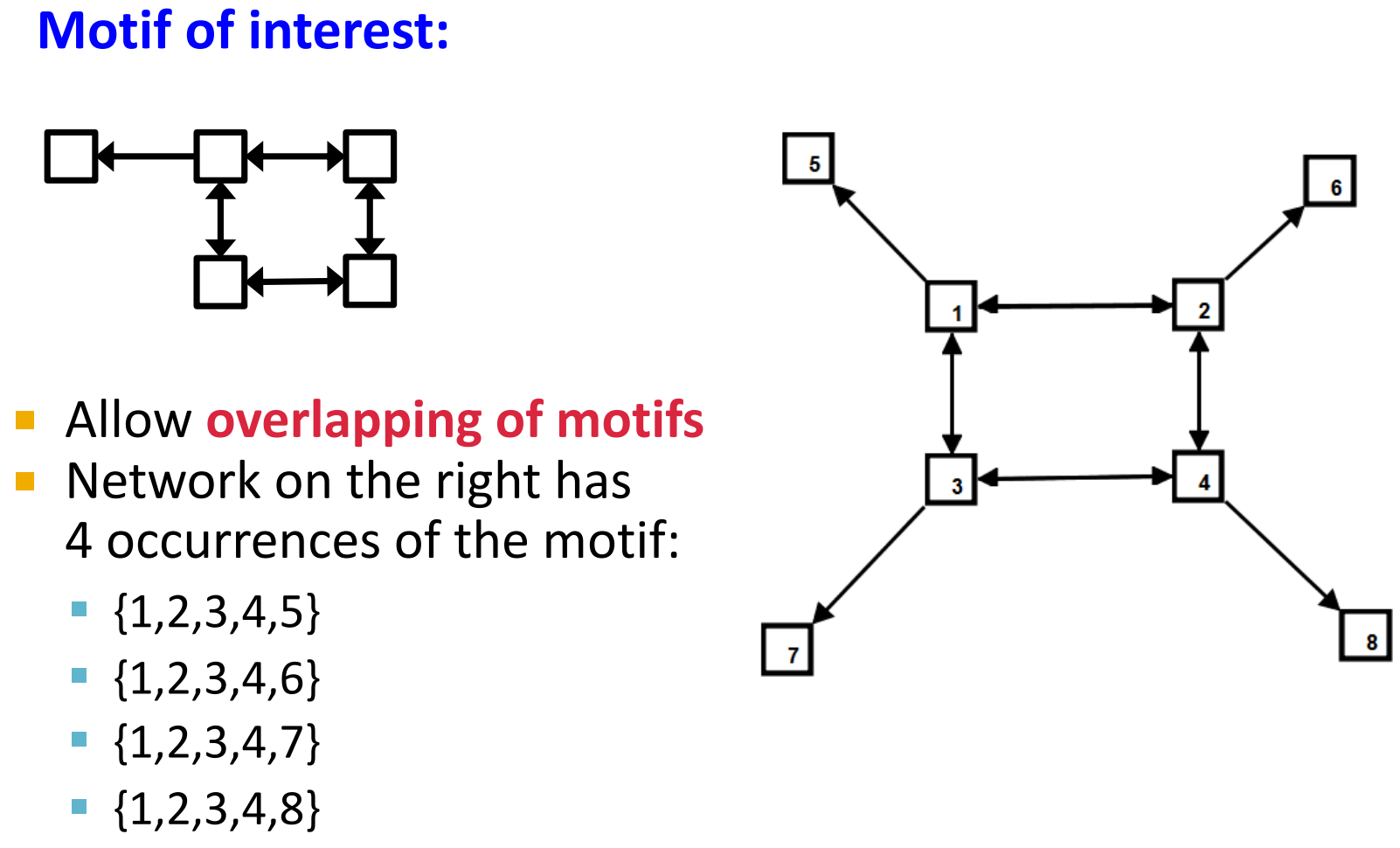
Motifs: Recurrence
Motifs的重要性
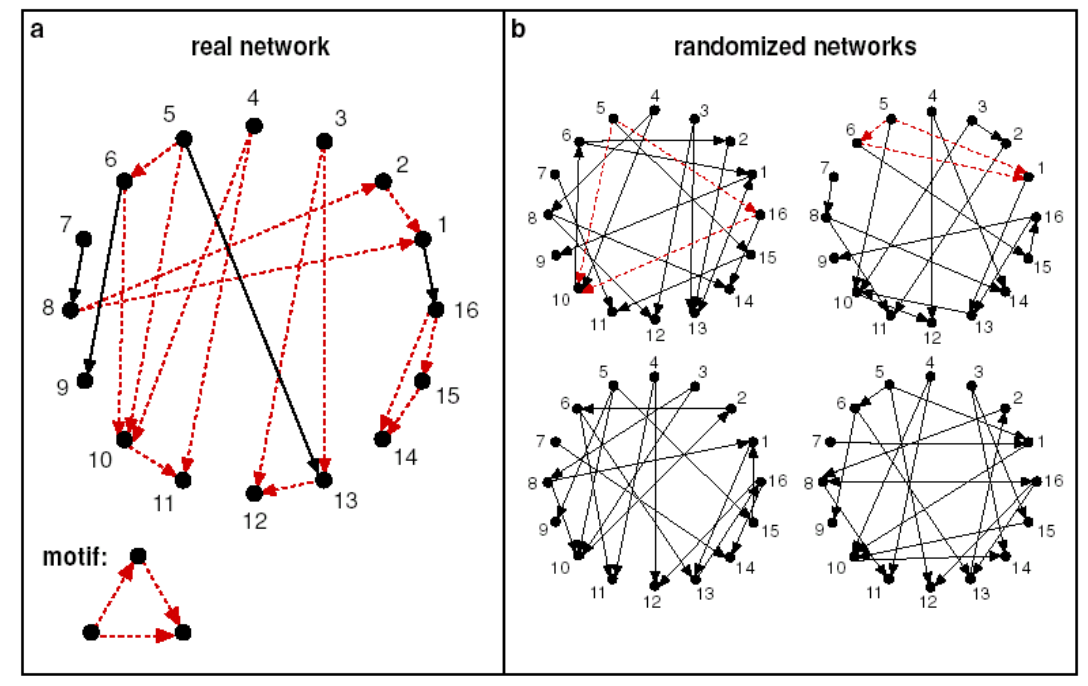
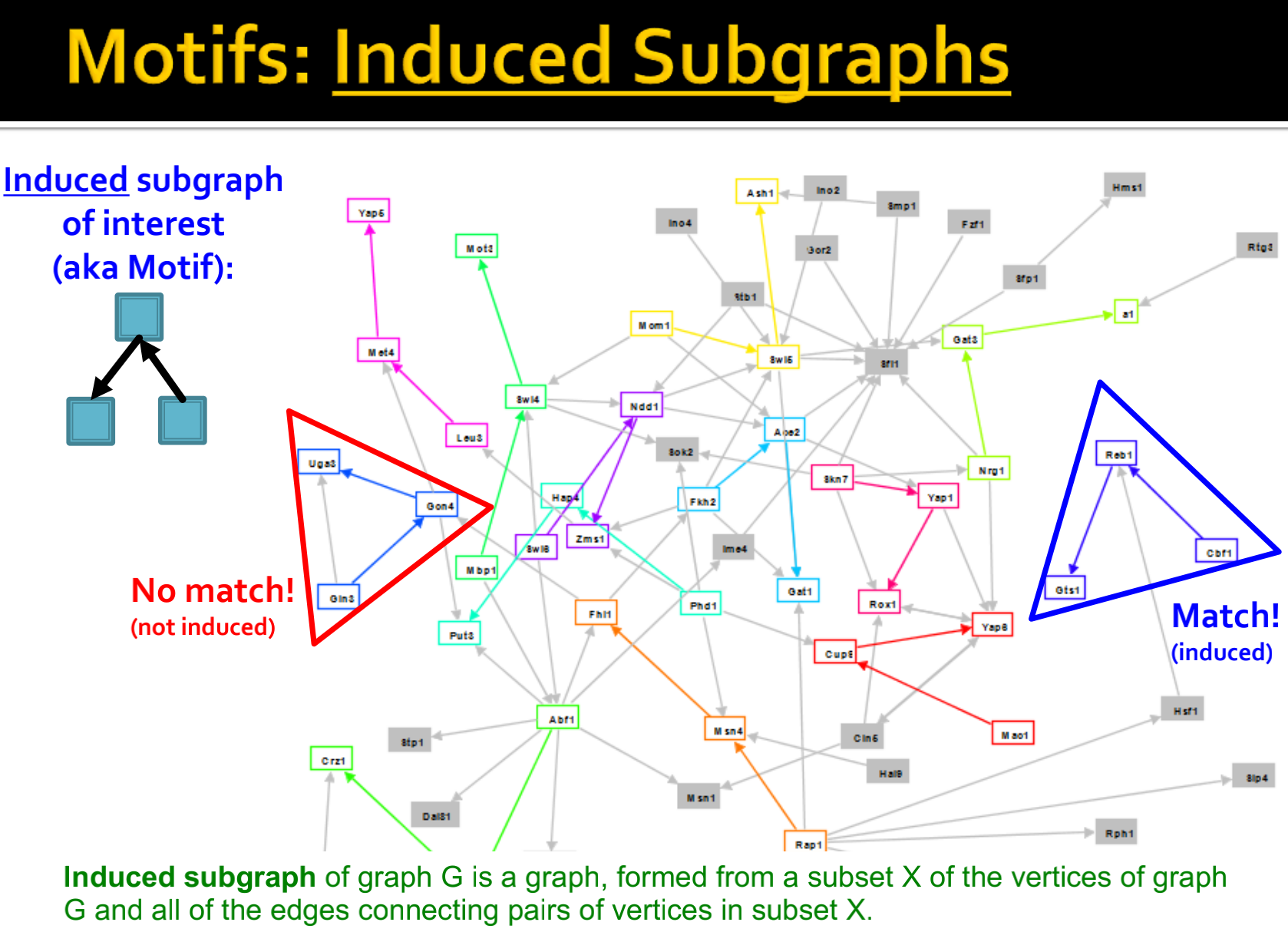
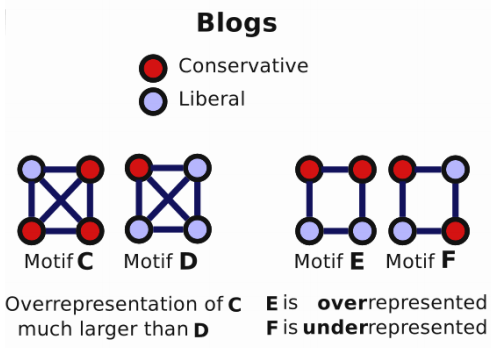
在motif定义中有提到,一个motif要比想象中更重要,“重要性”可以来对比随机网络,就是说,这个Motif在真实网络中出现的次数要远远大于随机网络中出现的次数。如下图所示,a图中的左下角定义了一个motif,这个motif在左图的真实网络中出现的频率要远远大于右图中的随机网络,因此这个motif定义的就是合理的。
从数学角度定义Motif i的重要程度: ,其中
,其中 表示网络
表示网络 中类型
中类型 的子图数量,
的子图数量, 表示随机网络
表示随机网络 中类型的子图数量。
中类型的子图数量。
Network significance profile(SP): ,SP是一个归一化的向量,强调子图的相对重要性。
,SP是一个归一化的向量,强调子图的相对重要性。
例子: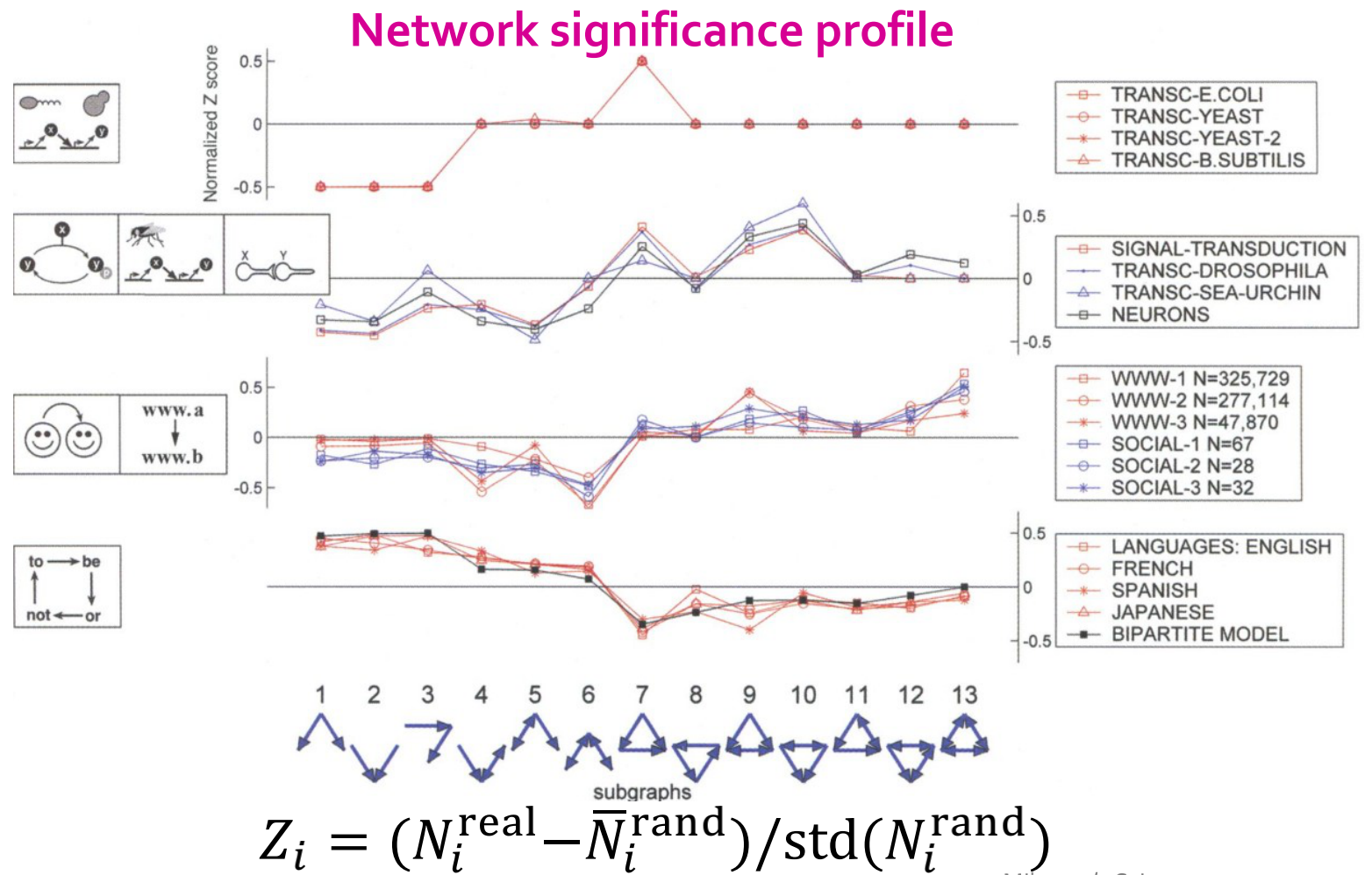
如何产生一个用来与真实图比较的随机图?
**
随机图要求:与真实图有相同的节点数、边数、度分布
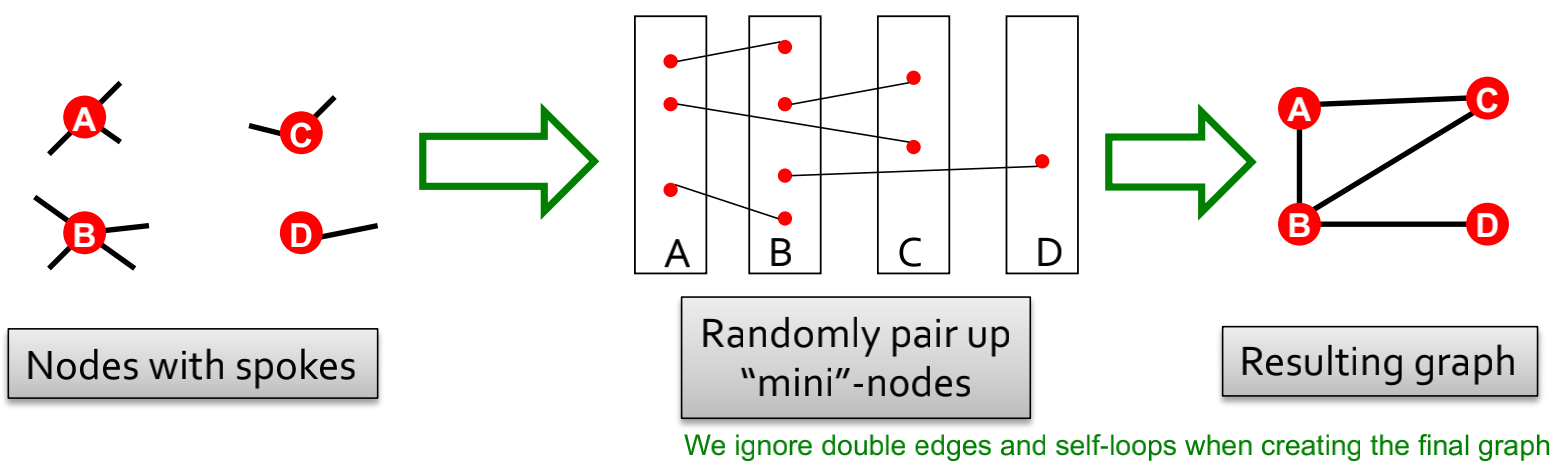
目标:给定一个度序列,产生随机图方法1 Configuration Model
如下图所示,假设要生成有4个节点的随机图,度分别为4、3、2、1,则利用ABCD四种度序列,随机选择其他连边,最终生成右图,图中忽略了自环,多重边只保留一个。
方法2 Switching
如下图所示,给定一个初始图
 ,重复交换
,重复交换 次,Q为超参数(足够大使迭代聚合,比如取100),交换准则:(1)每次随机选择两组边,比如AB、CD;(2)交换endpoints,边变成了AD、CB(同时要确保交换时不产生多重边和自环),基于上述方法,就可产生相同度分布的随机图。
次,Q为超参数(足够大使迭代聚合,比如取100),交换准则:(1)每次随机选择两组边,比如AB、CD;(2)交换endpoints,边变成了AD、CB(同时要确保交换时不产生多重边和自环),基于上述方法,就可产生相同度分布的随机图。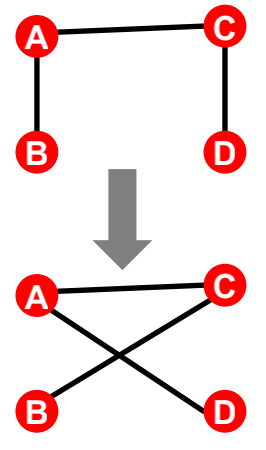
检测Motifs
产生随机图后,检测Motifs的方法:
在真实图
中,统计子图的个数;- 在随机图中,统计子图的个数;
- 计算Z-score:

high Z-socre表示子图是真实图的motif。
例子: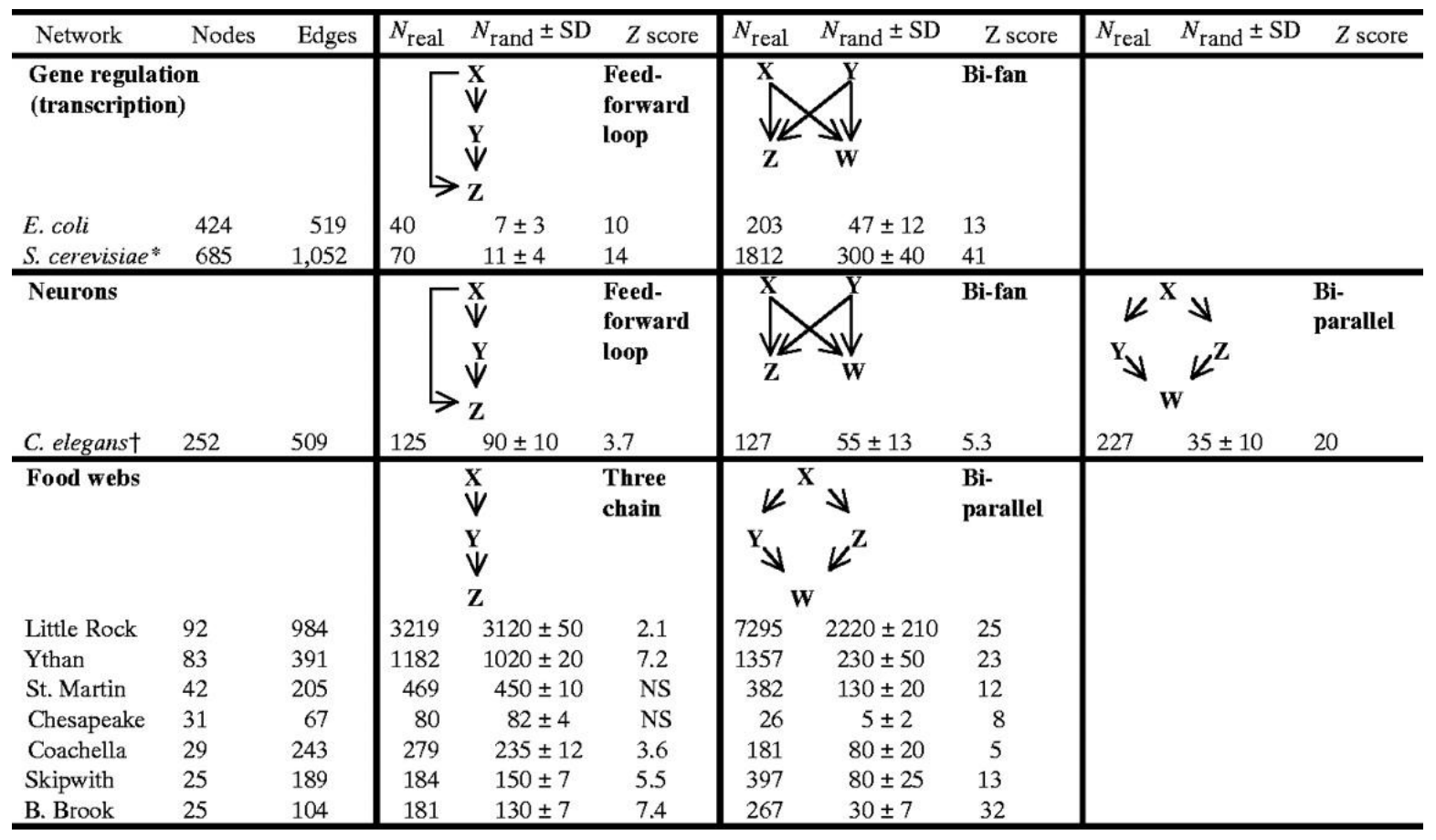
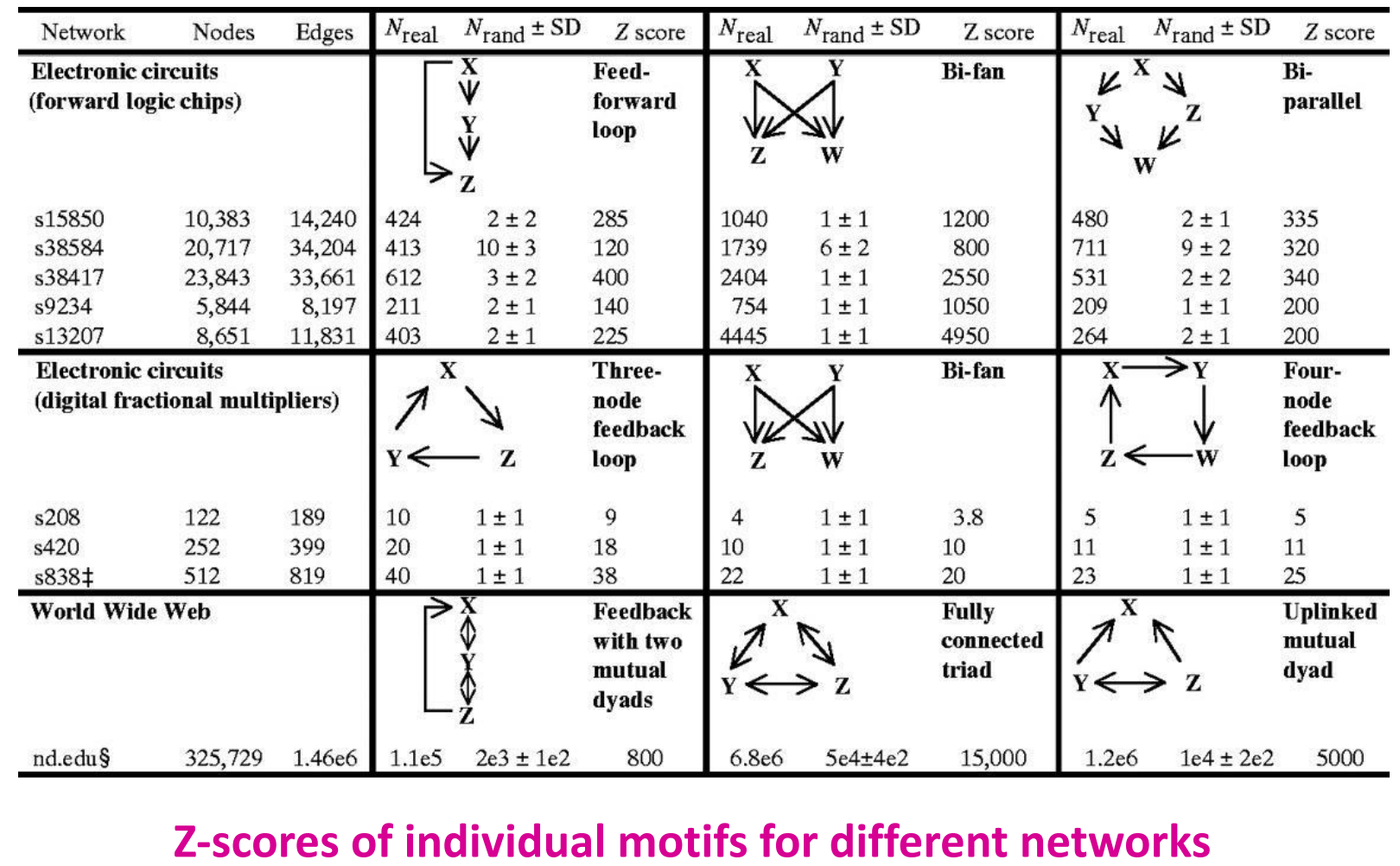
从上述的两张表格可知:
- Neurons与Gene两个网络含有相似的motifs:feed-forward loops和bi-fan structures,两者都是具有感觉和作用成分的信息处理网络;
- Food webs有parallel loops:特定捕食者的猎物共享猎物;
-
Motif概念的变体
规范的定义:
Directed and undirected
- Colored and uncolored
- Temporal and static motifs
其他定义:
- Different frequency concepts
- Different significance metrics
- Under-Representation (anti-motifs)
- Different constraints for null model
Graphlets: Node feature vectors
Graphlets定义
Graphlets: connected non-isomorphic subgraphs
isomorphic 同构;同构的;同型的
Graphlets是对motifs的扩展,motif是从全局的角度来描述图的,全局的图有哪些motifs,而Graphlets是从局部(节点)的角度出发来描述,关注这个节点和它邻居的情况,利用局部信息来对每个节点表示。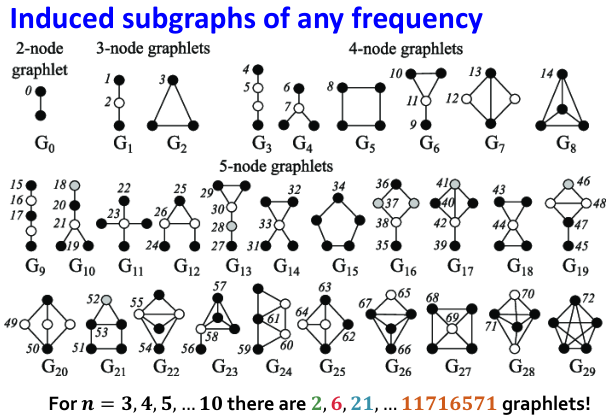
如上图所示,为 时的Graphlets,其中编号代表第几类节点。
时的Graphlets,其中编号代表第几类节点。
当 时,有1个Graphlets,只有一类节点0,两个节点是同构的。
时,有1个Graphlets,只有一类节点0,两个节点是同构的。
当 时,有2个Graphlets,对应三种节点,
时,有2个Graphlets,对应三种节点, 中有节点1、2,最下面的节点等价于节点1,在图
中有节点1、2,最下面的节点等价于节点1,在图 中3个节点都是等价的。
中3个节点都是等价的。
当 时,有6个Graphlets,11种节点,比如在
时,有6个Graphlets,11种节点,比如在 中有2类节点,节点7有三个邻居,而剩余三个节点同构,都可认为是节点6。
中有2类节点,节点7有三个邻居,而剩余三个节点同构,都可认为是节点6。
可以看出Graphlet也是一种子图,但是更关注局部节点的性质。
如何表示Graphlets中的节点?
使用graphlets得到一个节点级别的子图度量
Graphlet degree vector(GDV):度表示一个节点所连接的边数,将Graphlet看作边,则GDV表示一个节点所连接的Graphlets数量。
Automorphism Orbits 自同构的轨道
isomorphism同形性; 同态性
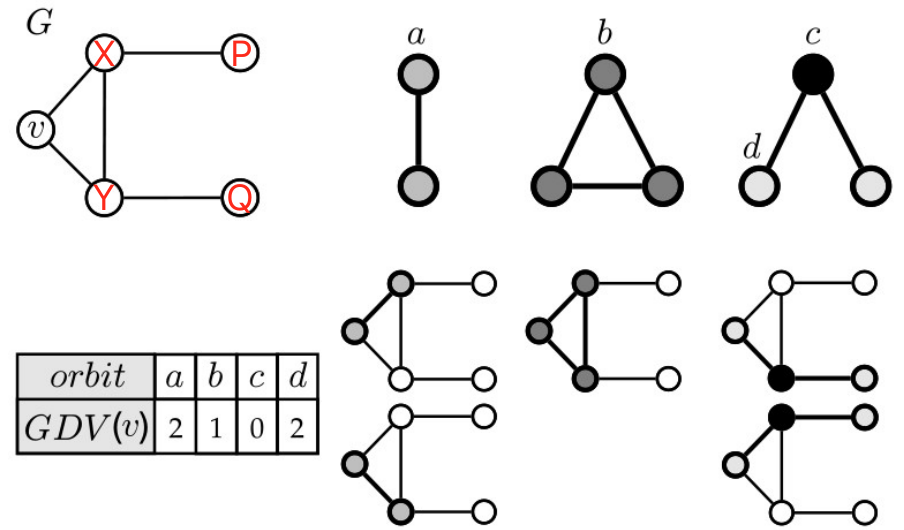
如下图所示,对于图中的节点 ,的自同构轨迹是
,的自同构轨迹是 ,其中
,其中 表示图的自同构组,如G的同形是其自身。
表示图的自同构组,如G的同形是其自身。
- 对于下图中的,假设用节点个数为2、3的graphlet表示(即上图中的
 ),有abcd共4类节点(对应上图的0321节点);
),有abcd共4类节点(对应上图的0321节点); - 对节点
 进行表示:
进行表示: - (1)a类型出现2次,即vX、vY;
- (2)b类型出现1次,即vXY;
- (3)c类型没有出现,vXY不能算是c类型,因为c类型最下面的边没有相连,即vXY不可以算是的子图;
- (4)d类型出现2次,即vXP、vYQ;
- 综上,所以节点v的表示为

Graphlet degree vector对节点在特定轨迹上触及到的graphlets计数。
考虑节点数为2~5的graphlets,73个元素组成的向量是一个节点的特征,它描述了节点的邻居的拓扑结构;捕获其4跳距离内的互连性。
Graphlet degree vector提供了一个度量节点局部网络拓扑结构的方法,即通过比较两个节点的向量,提供了对它们之间局部拓扑相似性的高度约束性测量。
例子: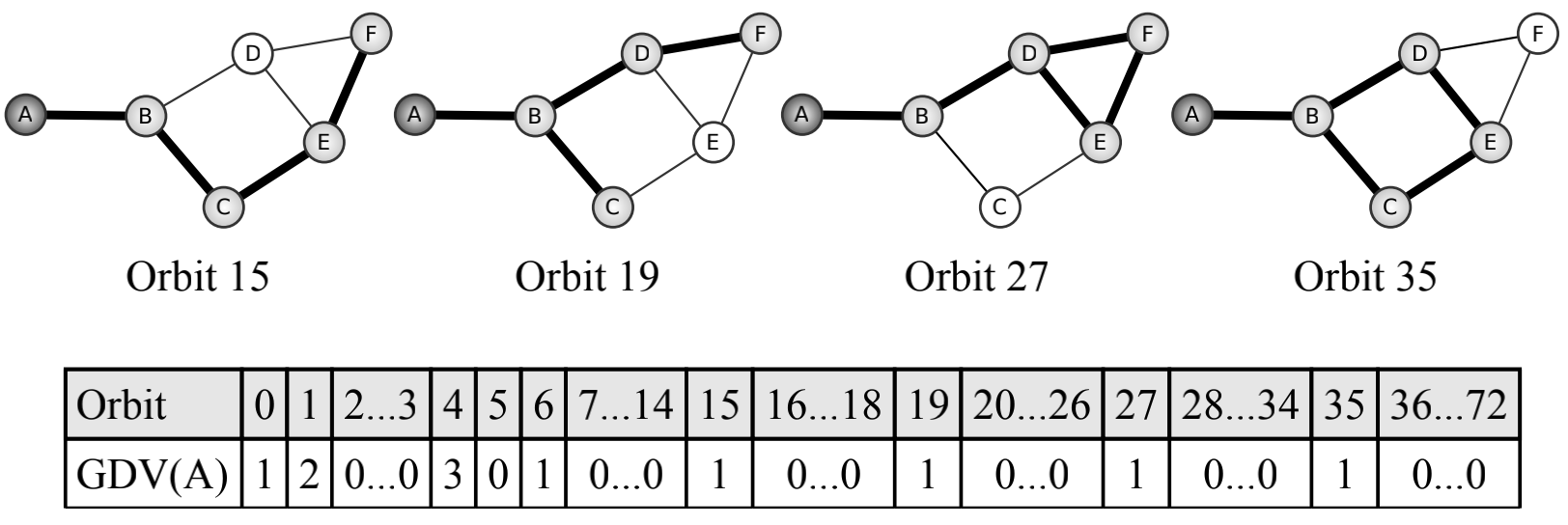
节点A的GDV:
- GDV(A)的第个元素:在轨迹上触及A的graphlets数量;
突出显示的是从左到右在轨迹15、19、27和35处接触节点A的graphlets。
找到Motifs与Graphlets
找到大小为k的motifs或graphlets需要解决以下两个问题:
枚举所有大小为k的连通subgraphs;
- 统计每类subgraph出现的的数量。
然而,子图同构是一个NP-complete问题。随着motif或graphlet大小的增加,计算时间呈指数增大。可行的motif大小通常很小,一般为3~8左右。
实现算法:
- Exact subgraph enumeration (ESU) [Wernicke 2006]
- Kavosh [Kashani et al. 2009]
- Subgraph sampling [Kashtan et al. 2004]
下面具体介绍ESU算法:
- 两个集合:
 :当前的subgraph(motif);
:当前的subgraph(motif); :要添加到motif中的候选节点集合。
:要添加到motif中的候选节点集合。
- 思想:从节点开始,属于集合中的节点有两个性质:
- 的node_id必须大于的node_id;
- 可能只是一些新增节点
 的邻居,但不是中已经存在的节点。
的邻居,但不是中已经存在的节点。
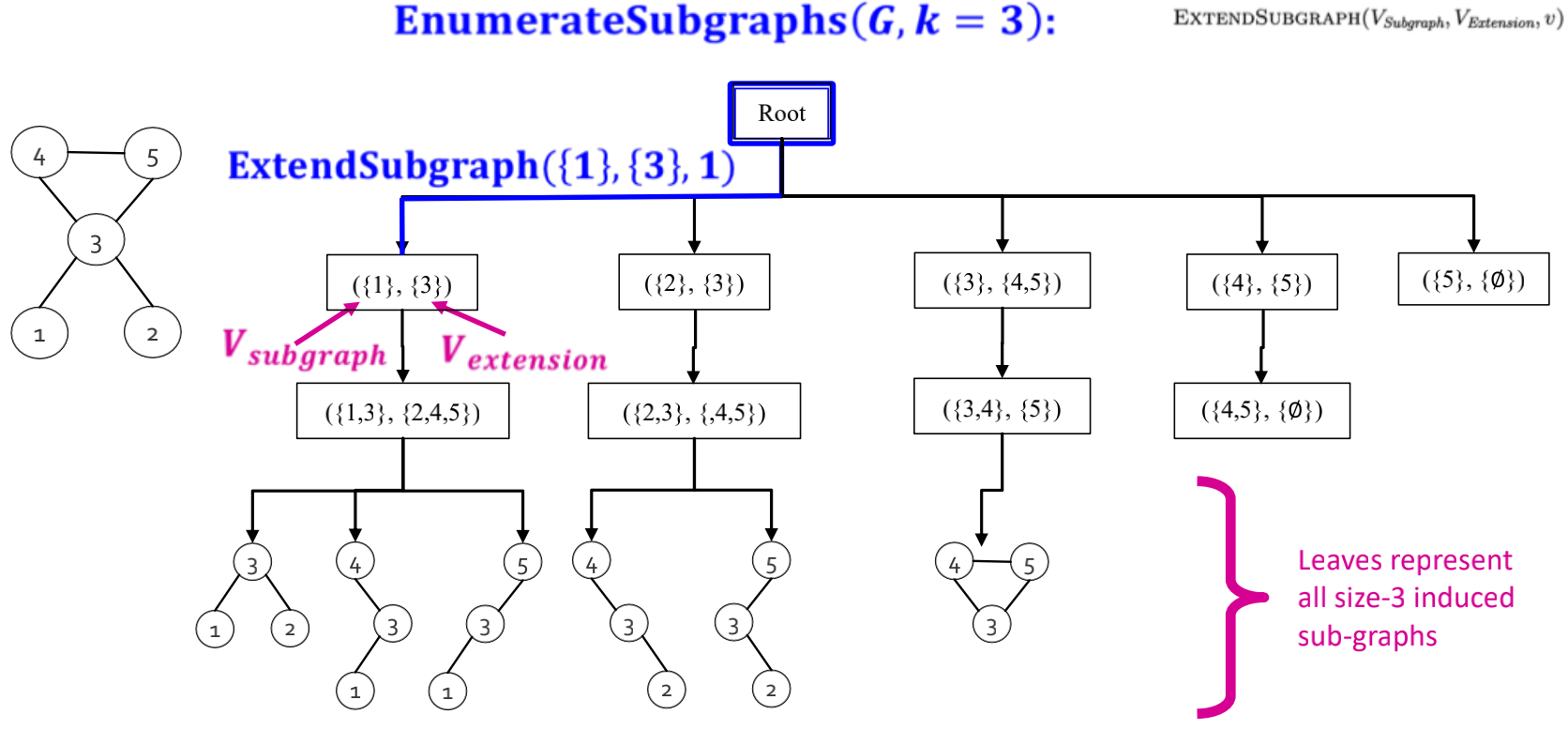
- ESU以递归函数方式实现,使用深度为k的树状结构,称为ESU-Tree。

 是排除的邻居,即是所有节点邻居而不是或
是排除的邻居,即是所有节点邻居而不是或 。
。
举例来说,如下图的ESU-Tree示例图,在ESU-Tree中的节点包括两种邻接集合:
- :当前的subgraph(相邻节点集合);
- :与相邻的节点,且这些节点的node_id比开始节点大。
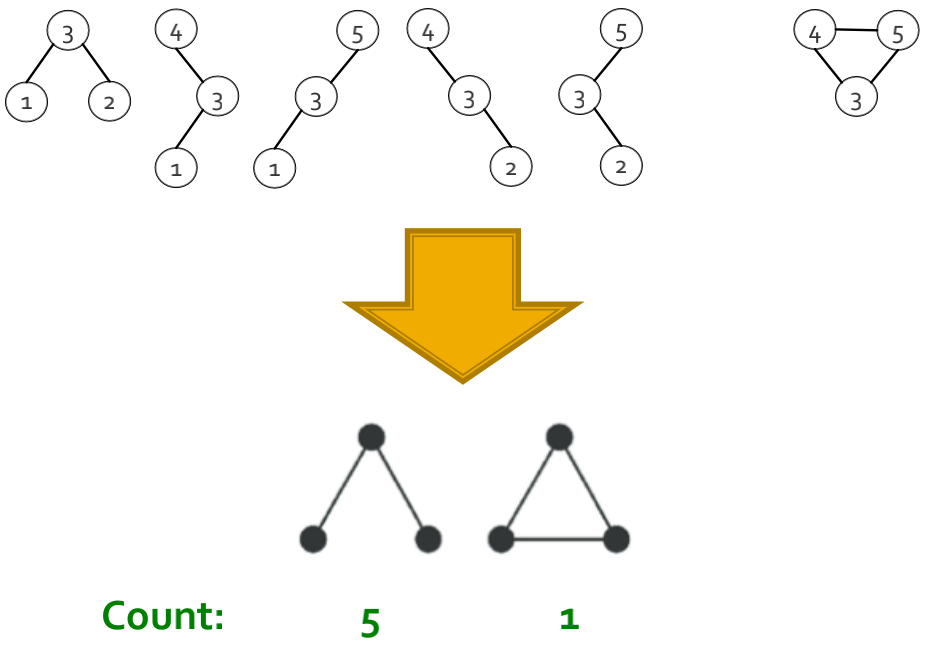
确定ESU-Tree叶子中哪些子图在拓扑学上是等价的(同构),并将它们相应地归入子图类。如上图中所示,将放置在ESU-Tree叶子中的子图分类为非同构、大小为k=3的两个类别,并分别统计这两个类别的数量(上图中第一个类型子图的数量为5,第二个类型子图的数量为1)。
如何判断两个图是否是同构的(isomorphism)?
若存在bijection  ,则图和图
,则图和图 是同构的,也就是说如果
是同构的,也就是说如果 和
和 在中是adjacent的,则任意两个节点和在G中是adjacent的。
在中是adjacent的,则任意两个节点和在G中是adjacent的。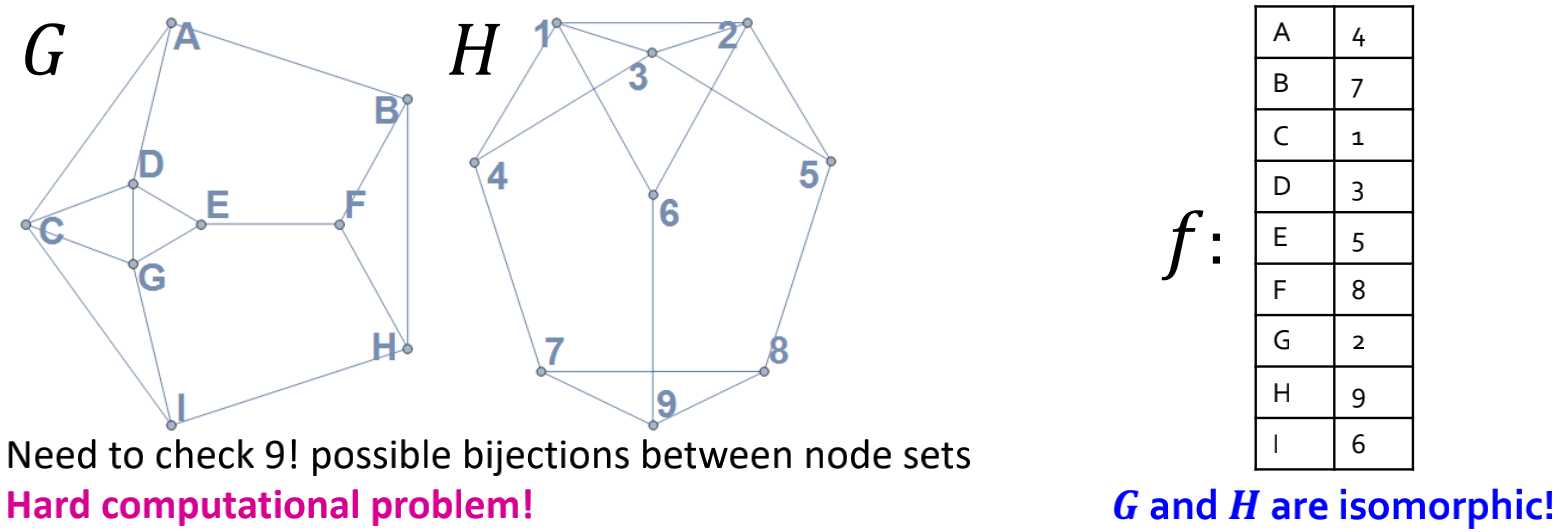
Structural Roles in Networks
什么是角色?
角色roles:是网络中节点的“functions”(功能,发挥作用)。
如,生态系统中的物种,公司中扮演的角色(老板、员工)。
角色由图中的结构行为来衡量:
- centers of stars
- members of cliques(cliques 小集团;小团体;派系集结)
- peripheral nodes(peripheral 外围的)
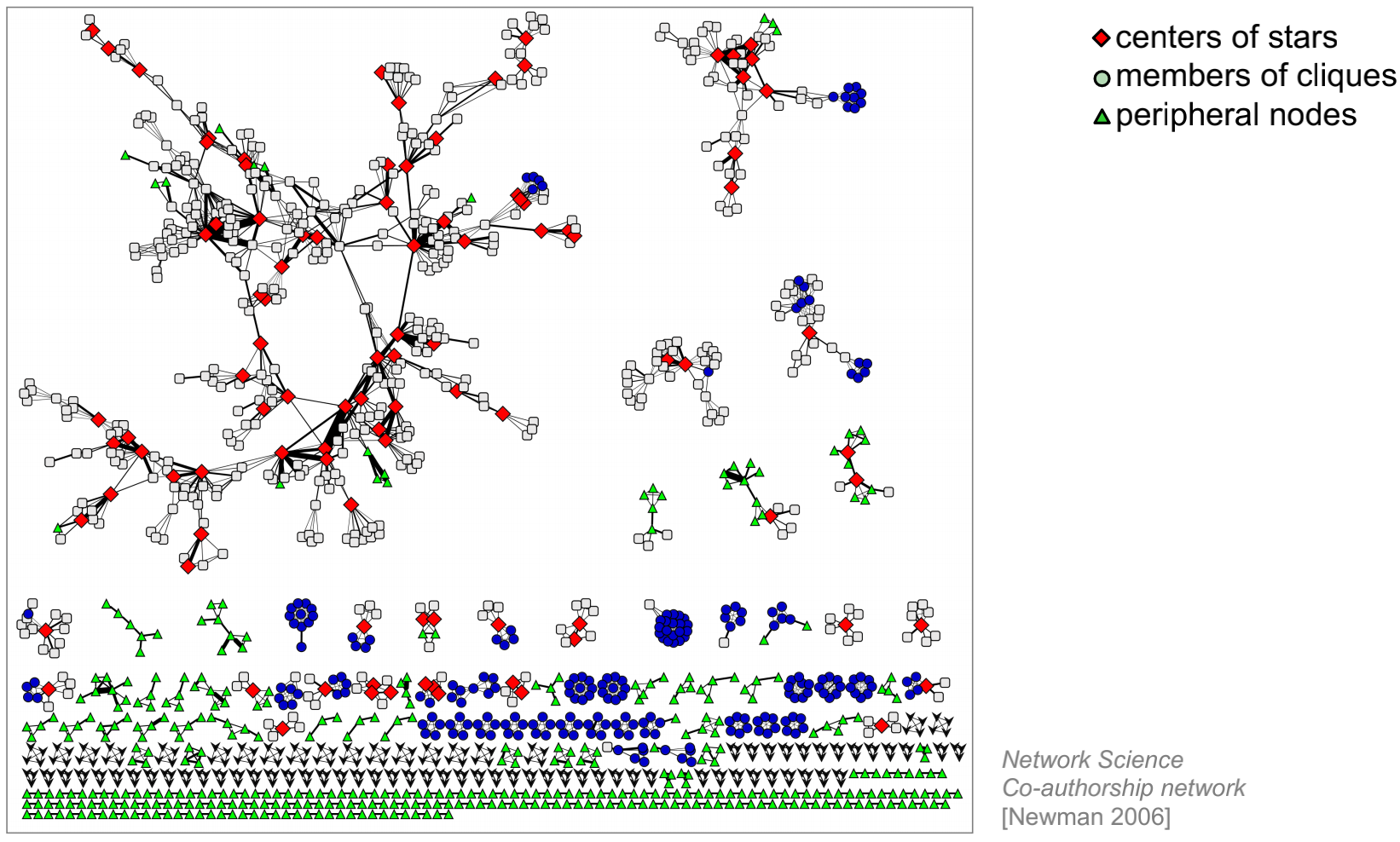
角色是在网络中具有相似位置的节点的集合,具有相同角色的节点之间无需直接或间接交互。
角色 VS 社区/组
- 角色是基于节点子集之间关系的相似性,是一组具有相似结构特性的节点,如教师、职员、学生;
- 组是根据相邻性、邻近性或可到达性组成小组,是一组相互连接的节点,如AI实验室、信息实验室、理论实验室。
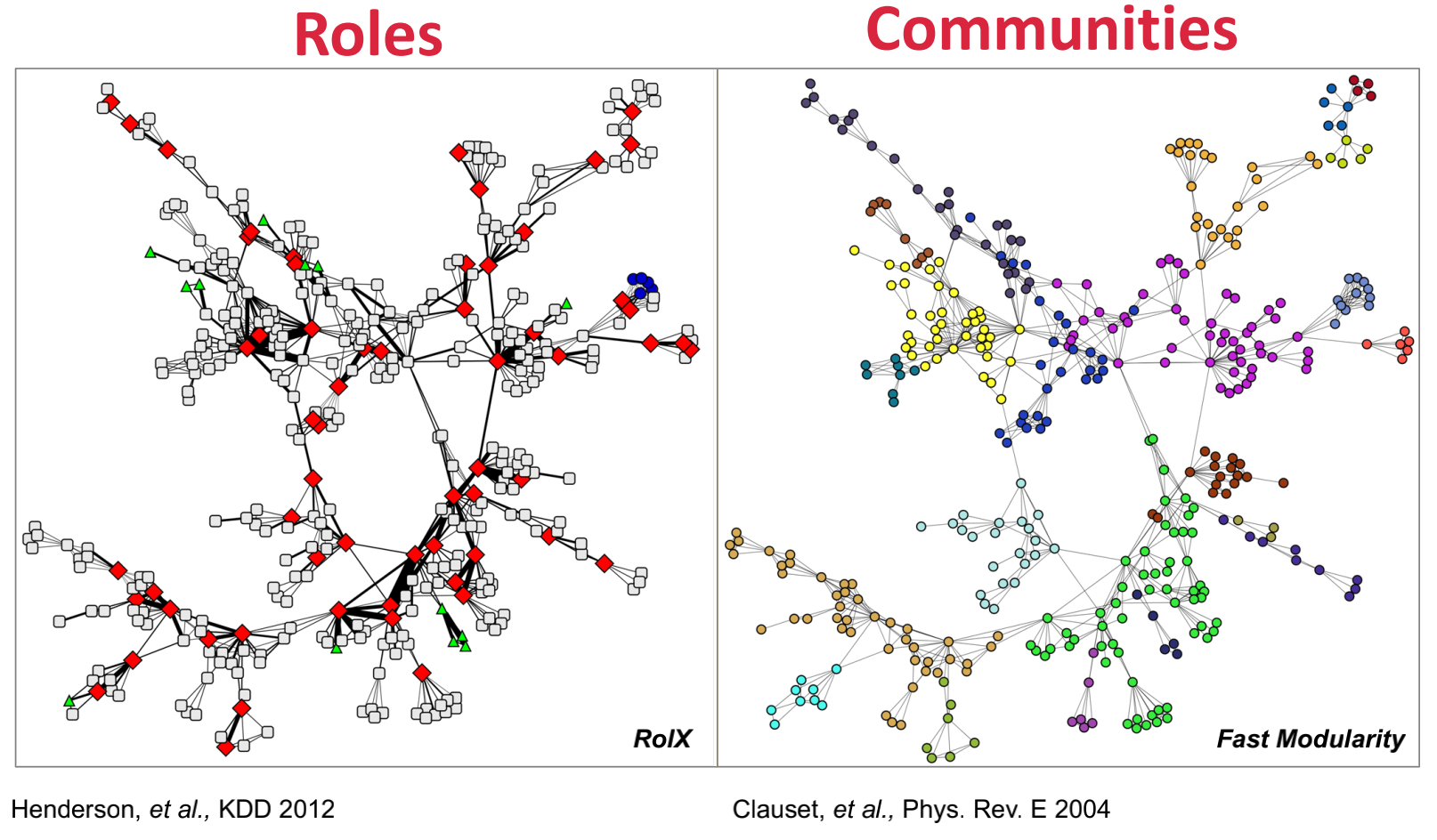
角色更正式的定义
结构结构等同性Structural equivalence:如果节点和对所有其他节点有相同的关系,则它们是结构等同的。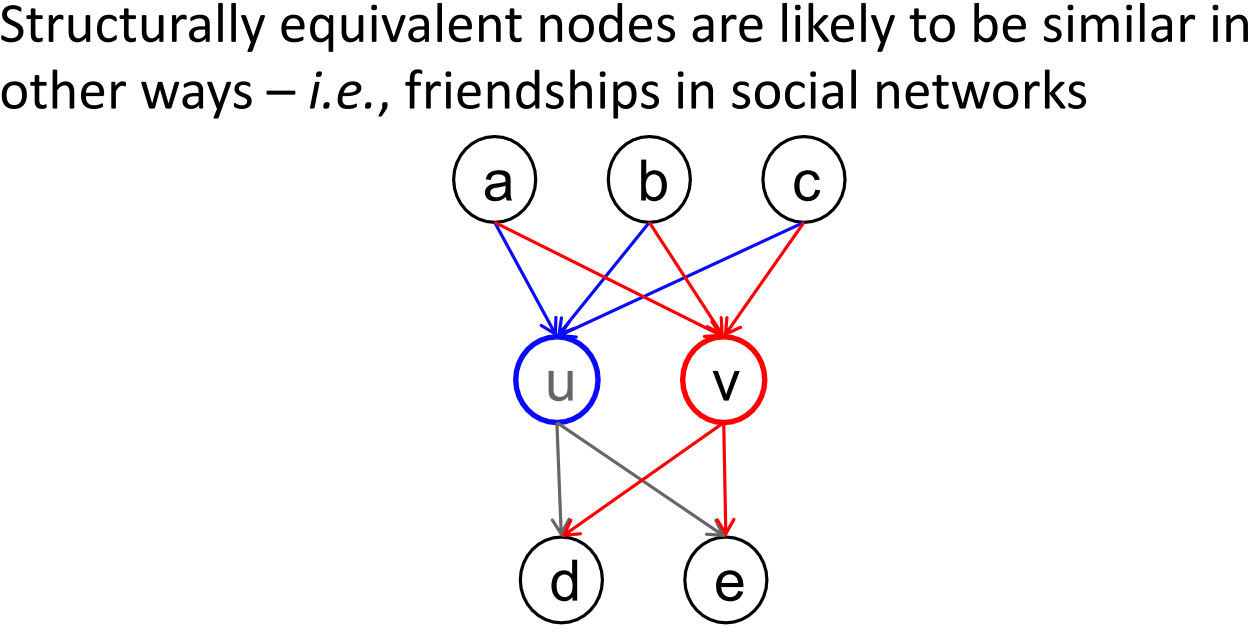
节点和是结构等同的:对所有其他节点 ,若节点与节点相连,则节点也与节点相连。
,若节点与节点相连,则节点也与节点相连。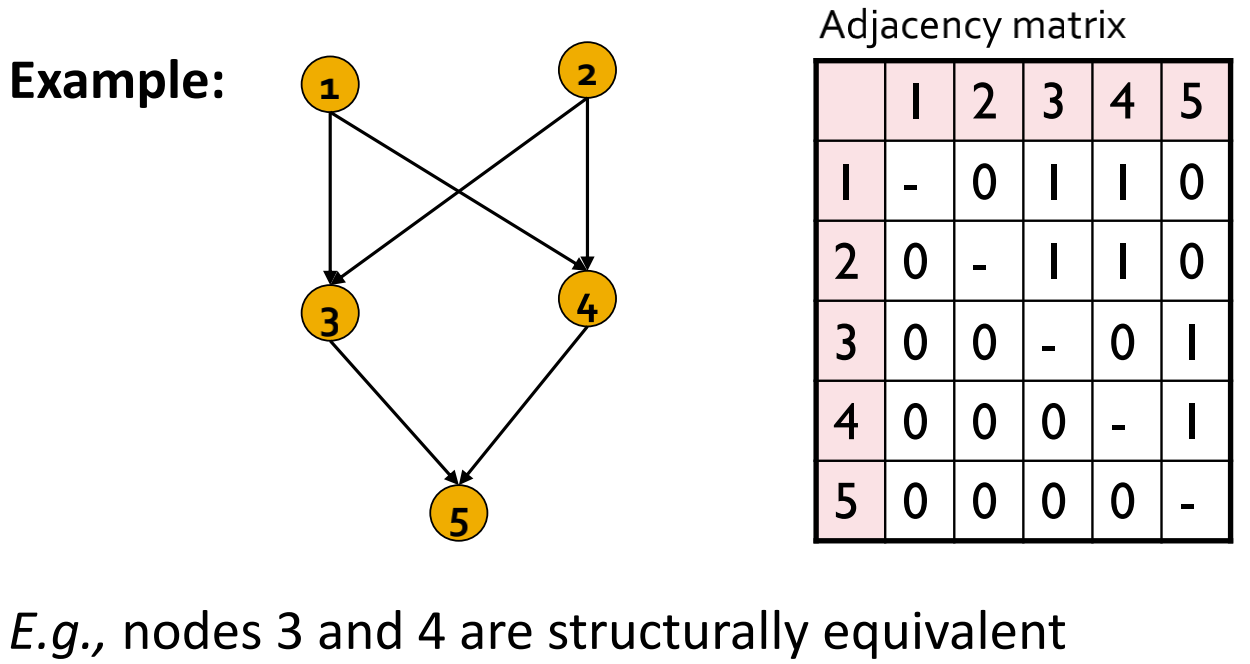
发现角色及角色的应用
角色的重要性
- 角色查询:识别和目标有相似行为的用户
- 角色异常:识别不同寻常行为的用户
- 角色动态变化:识别行为中异常用户的动态改变
- 身份识别:根据扮演角色判断用户身份
-
角色发现算法:RolX
RolX:自动发现网络中节点的结构作用,如图所示。
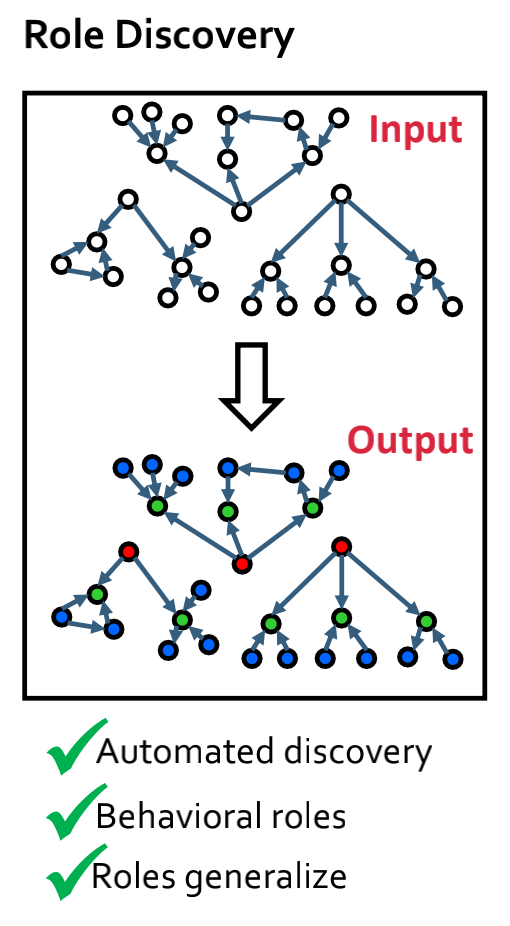
RolX有以下几个特点: 无监督学习
- 无需先验知识
- 每个节点有多个角色
- 线性复杂度
RolX方法的概览: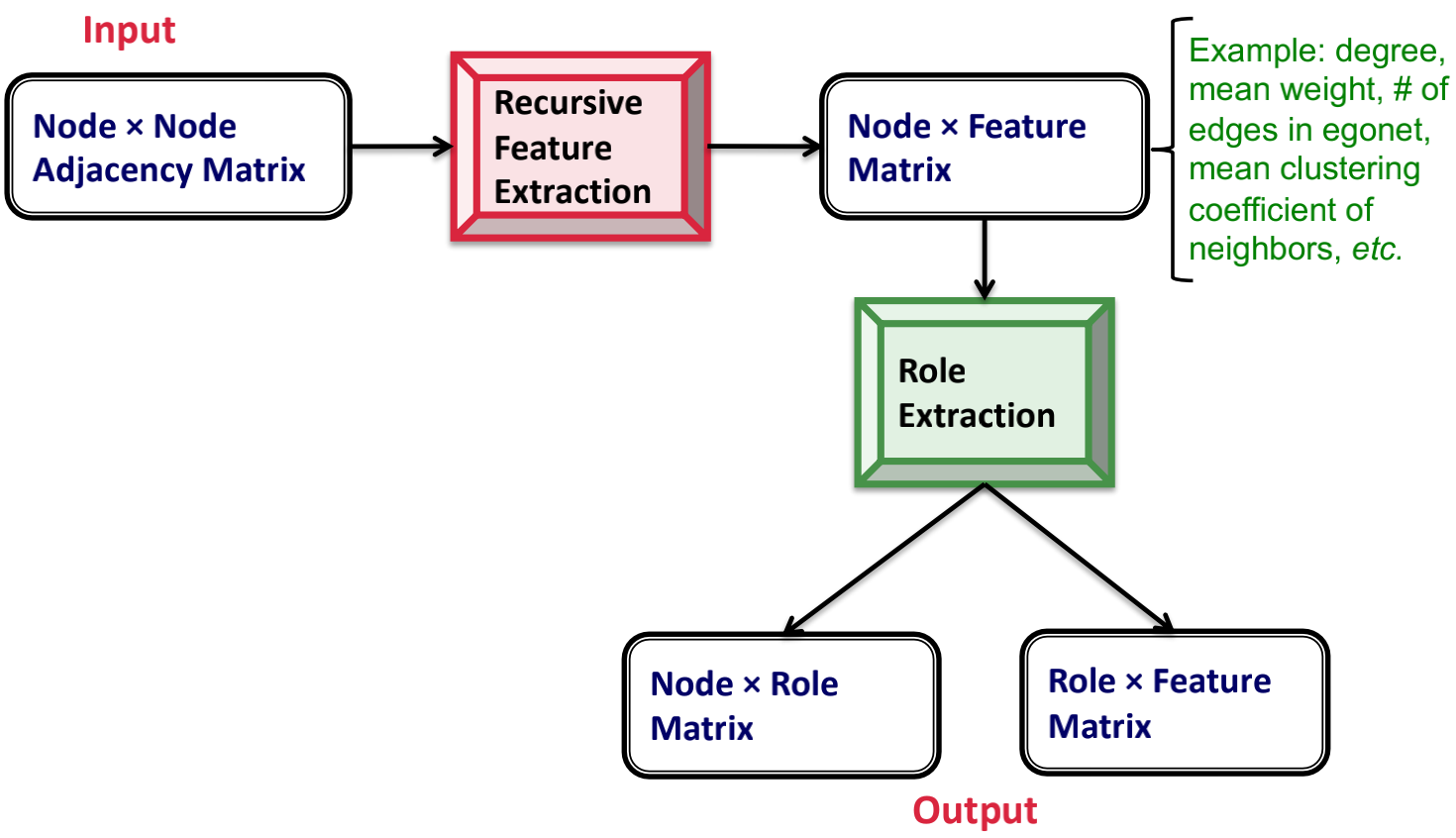
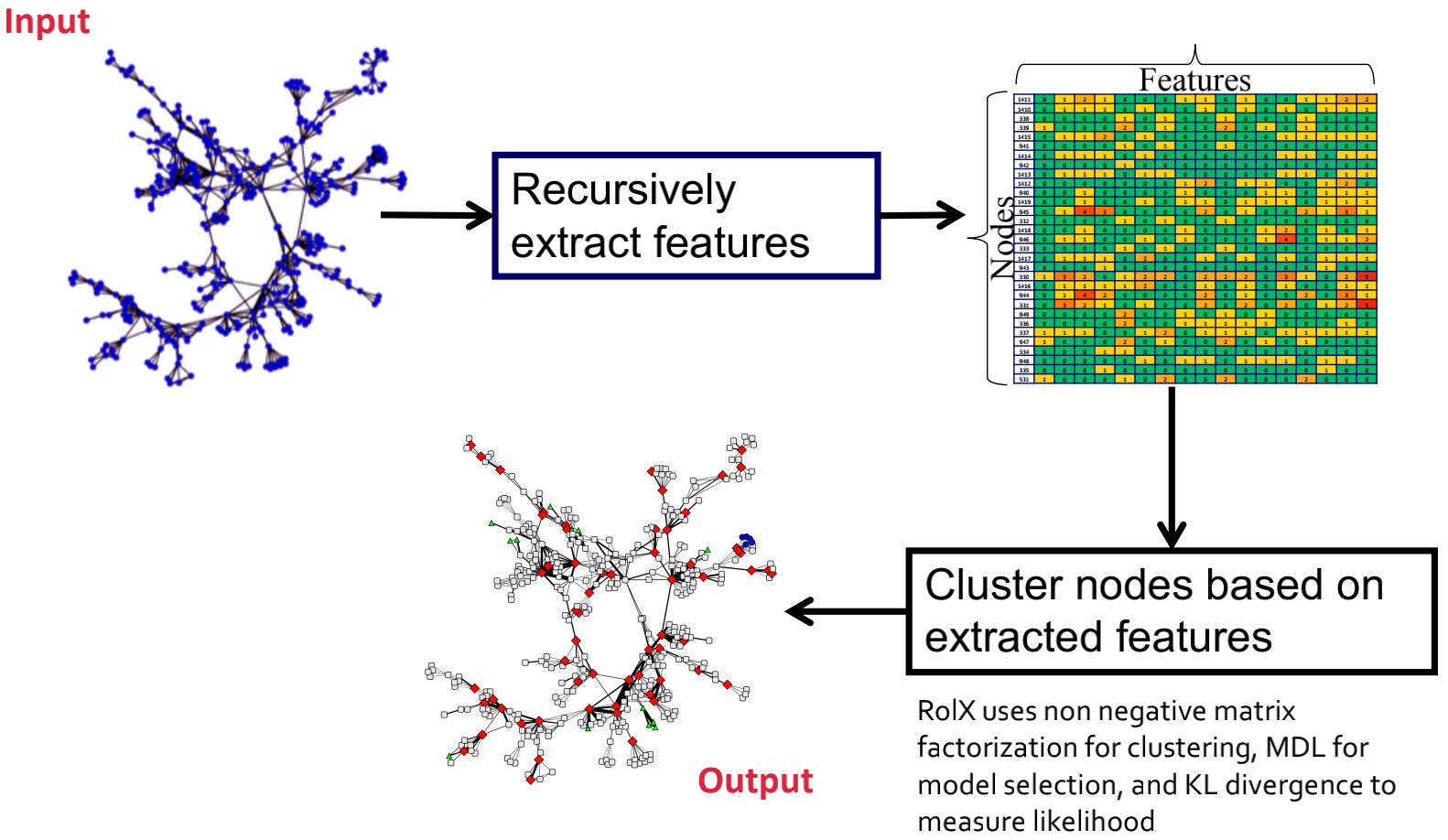
Recursive Feature Extraction 递归特征提取:
将连接的网络转为结构特征,其思想是将一个节点的特征聚合,使用聚合特征生成新的递归特征,如下图所示。
节点邻域特征的基本集:
- 局部特征:节点度的所有测量。若网络是有向的,则包括in和out度、总的度;若网络是加权的,则包括加权特征。
- egonet特征:基于节点的egonet计算,egonet包括节点、节点的邻居、子图的边、在/不在egonet边个数等。
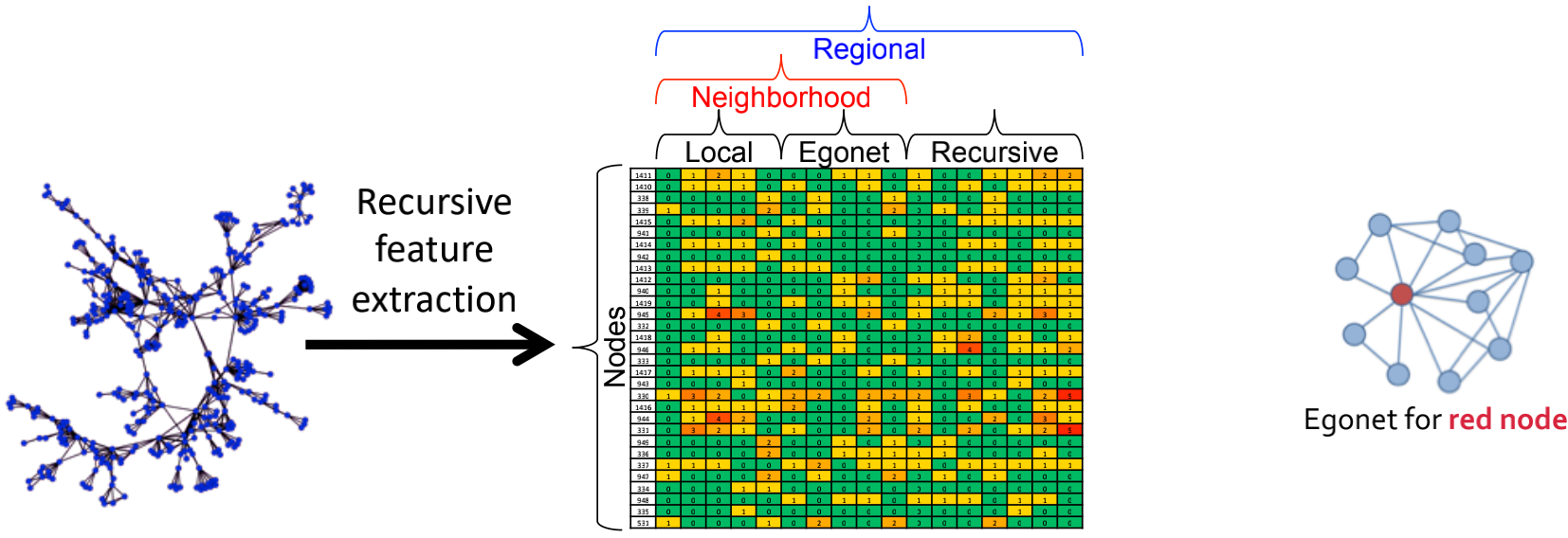
egonet 自我网
egoist n. 自我主义者;利己主义者
- 从基本的节点特征集开始
- 使用当前节点特征生成额外的特征:有mean和sum两种聚合函数,如计算一个节点所有邻居之间的无权重度特征的均值。
- 可能的递归特征数量随着每次递归迭代呈指数上升,可使用剪枝方法来减少特征数量:(1)找到高度相关的特征对;(2)基于给定的相关性阈值来删去两个特征中的一个。
角色的应用
基于结构相似性对节点聚类
两个网络:
- Network science co-authorship network:节点是网络科学家,边是合作论文的数量
- Political books co-purchasing network:节点是亚马逊上的政治书籍,边是同一买家经常共同购买书籍。
Setup:对于每个网络:
- 使用RolX为每个节点在已发现的结构性角色集上分配一个分布
- 通过比较节点的角色分布来确定节点之间的相似性
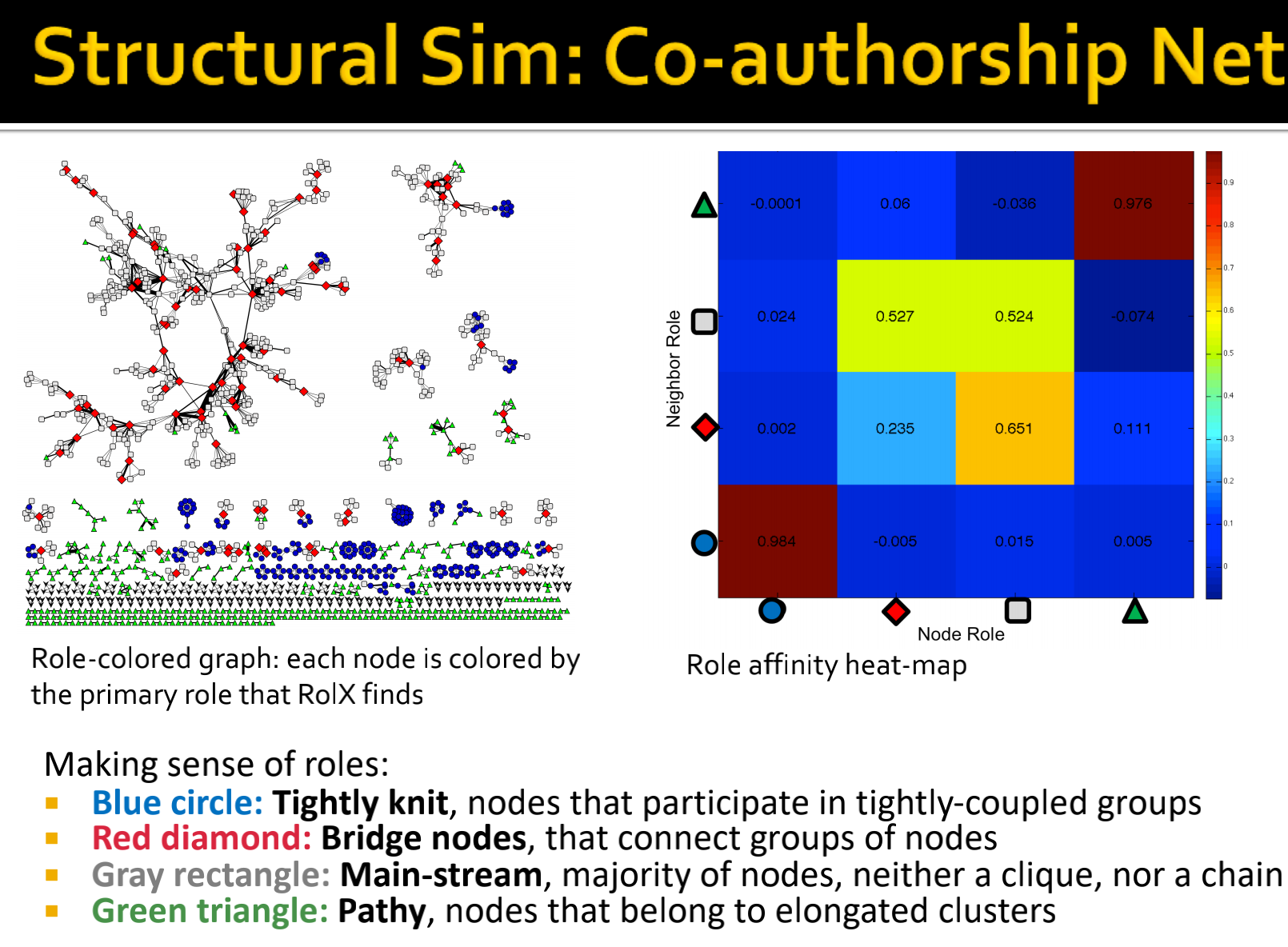
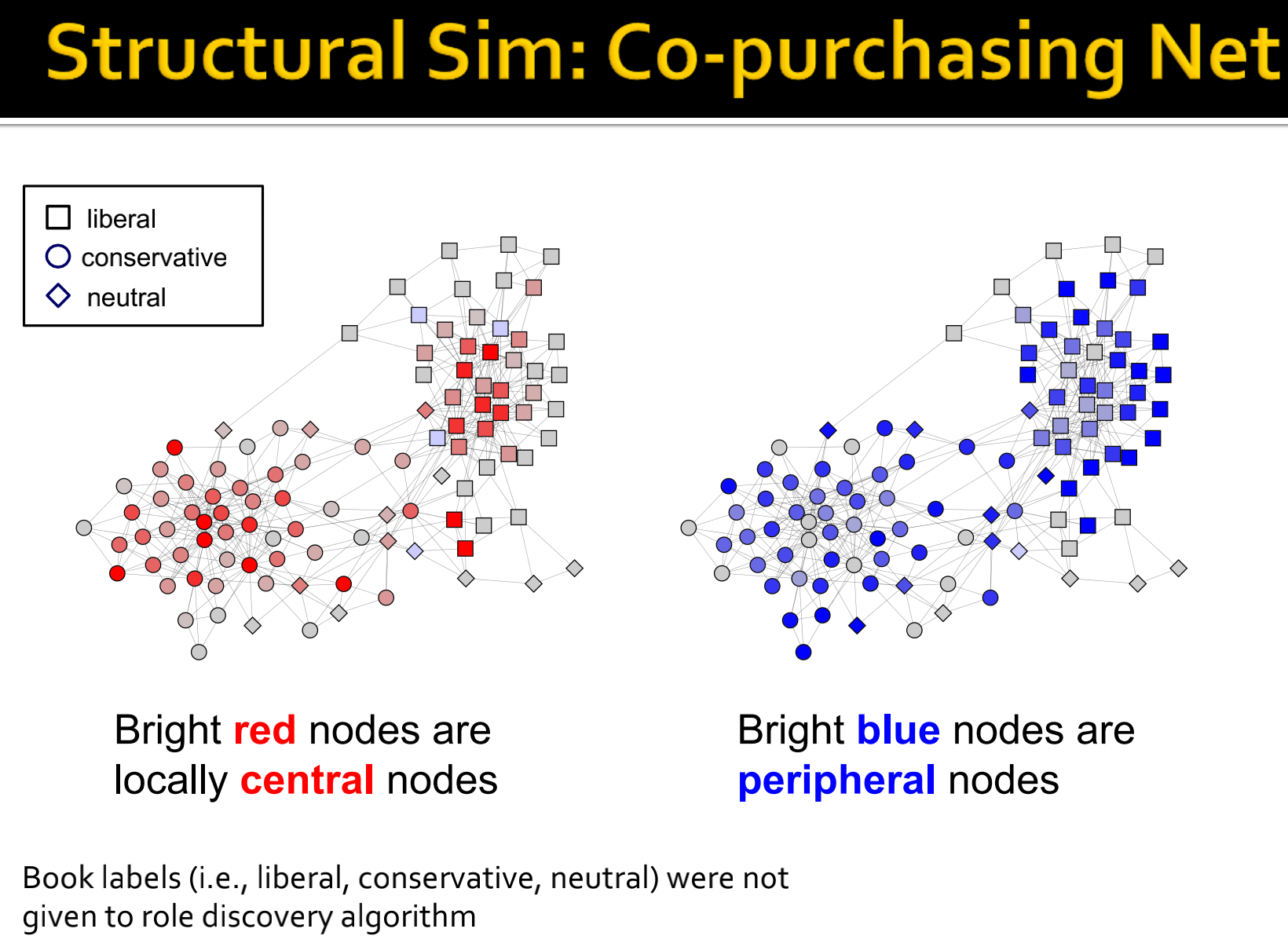
knit 毛衣;结合;编结
elongate 伸长;延伸;变长
peripheral 外围的;周边的;周边设备
conservative 保守的;守旧的;因循守旧的;(式样等) 保守的
参考链接
知乎笔记:https://zhuanlan.zhihu.com/p/138560010
PPT:http://web.stanford.edu/class/cs224w/slides/03-motifs.pdf

若有收获,就点个赞吧
0 人点赞
