JS 引擎

宿主环境:是由外壳程序生成的,比如浏览器就是一个外壳环境(但是浏览器并不是唯一,很多服务器、桌面应用系统都能也能够提供 JavaScript 引擎运行的环境)。
执行期环境:则由嵌入到外壳程序中的 JavaScript 引擎(比如 V8 引擎,不同浏览器可能所用引擎不一样)生成,
初始化:
一套与宿主环境相关联系的规则
JS 引擎内核(基本语法规则、逻辑、命令和算法)
一组 内置对象 和 API
其他约定
不同的 JS 引擎定义初始化环境是不同的,从而形成了浏览器兼容性问题
编译原理
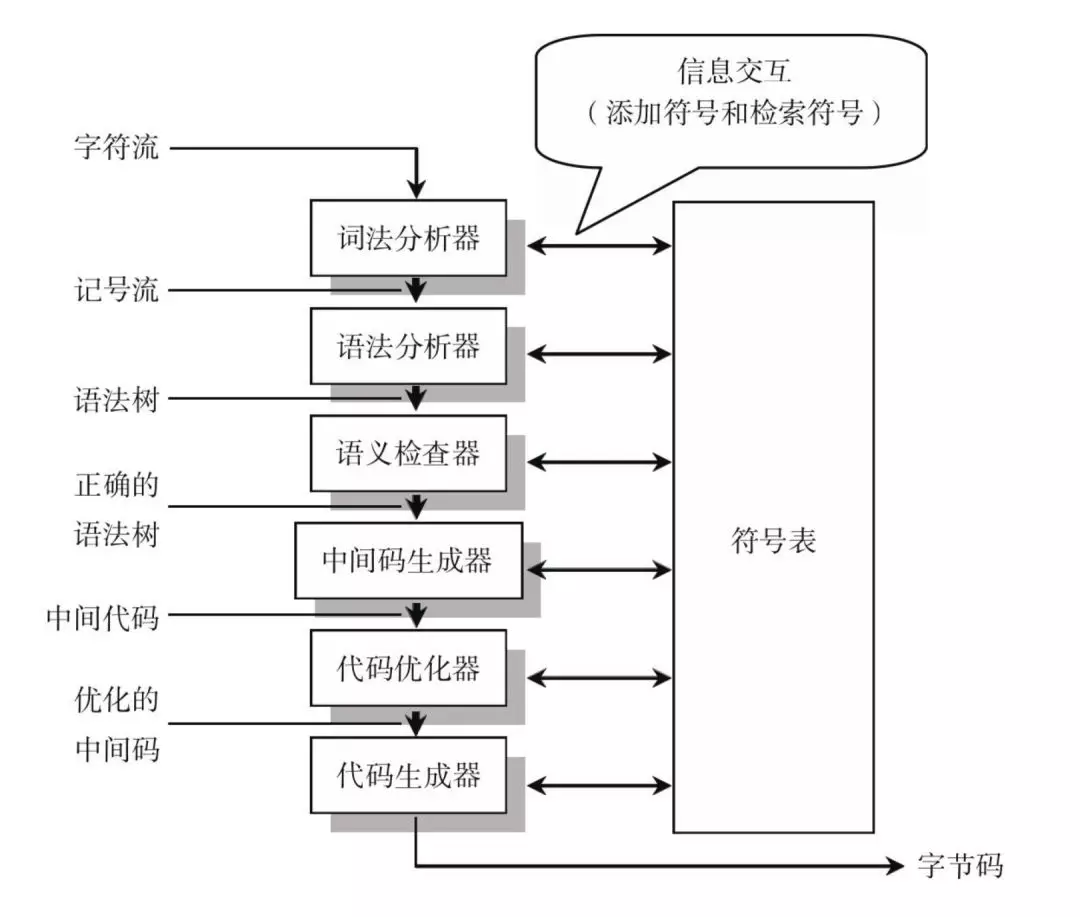
分词/词法分析(Tokenizing/Lexing)
分词:将一句话,按照词语的最小单位进行分割
词法单元(token):将一串串代码拆解成有意义的代码块
例如:var a = 2 分解成 var a = 2 ;空格是否作为词法单位,取决于空格在这门语言中是否具有意义
解析/语法分析(Parsing)
将“词法单元流”转换成一个由元素逐级嵌套所组成的代表了程序语法结构的树,即抽象语法树(AST, Abstract Syntax Tree)
词法分析和语法分析不是完全独立的,而是交错进行的,也就是说,词法分析器不会在读取所有的词法记号后再使用语法分析器来处理。在通常情况下,每取得一个词法记号,就将其送入语法分析器进行分析。
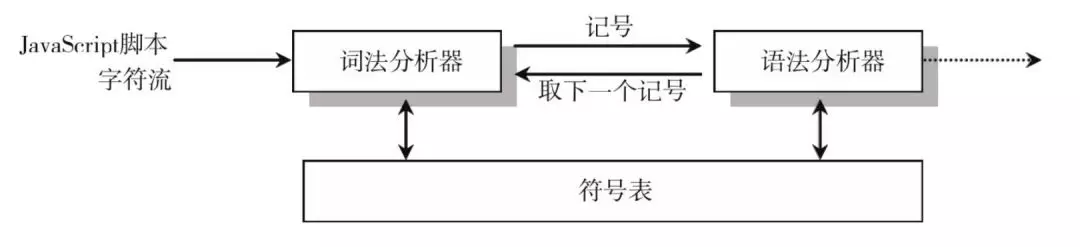
语法分析的过程就是把词法分析所产生的记号生成语法树,通俗地说,就是把从程序中收集的信息存储到数据结构中。注意,在编译中用到的数据结构有两种:符号表和语法树。
符号表:就是在程序中用来存储所有符号的一个表,包括所有的字符串变量、直接量字符串,以及函数和类。
语法树:就是程序结构的一个树形表示,用来生成中间代码。下面是一个简单的条件结构和输出信息代码段,被语法分析器转换为语法树之后,如:
if (typeof a == "undefined") {a = 0;} else {a = a;}alert(a);
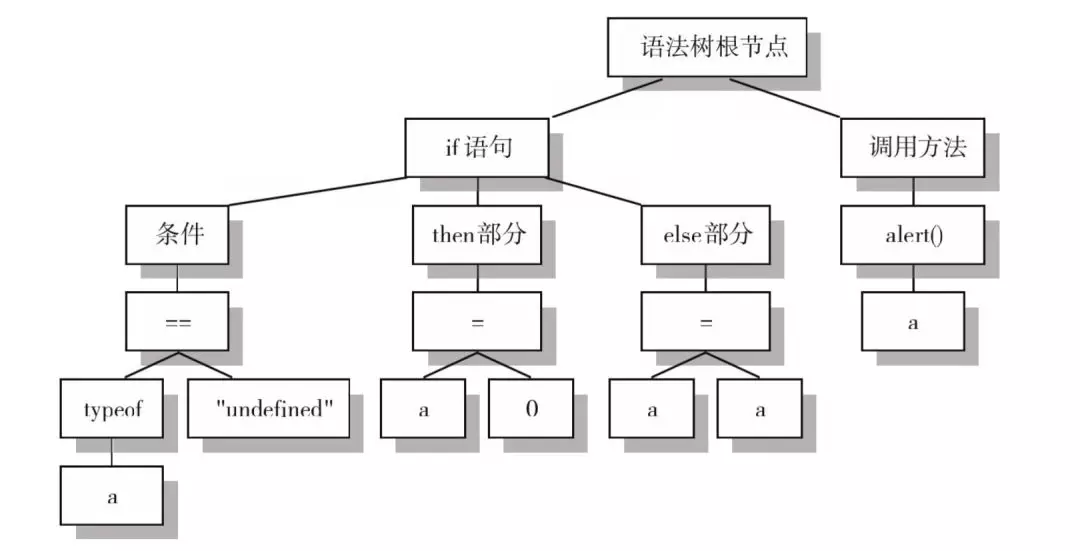
如果 JavaScript 解释器在构造语法树的时候发现无法构造,就会报语法错误,并结束整个代码块的解析。对于传统强类型语言来说,在通过语法分析构造出语法树后,翻译出来的句子可能还会有模糊不清的地方,需要进一步的语义检查。
语义检查的主要部分是类型检查。例如,函数的实参和形参类型是否匹配。但是,对于弱类型语言来说,就没有这一步。
经过编译阶段的准备, JavaScript 代码在内存中已经被构建为语法树,然后 JavaScript 引擎就会根据这个语法树结构边解释边执行。
代码生成
将 AST 转换成可执行代码的过程被称为代码生成。这个过程与语言、目标平台相关。
了解完编译原理后,其实 JavaScript 引擎要复杂的许多,因为大部分情况,JavaScript 的编译过程不是发生在构建之前,而是发生在代码执行前的几微妙,甚至时间更短。为了保证性能最佳,JavaScipt 使用了各种办法。
V8 引擎
当 V8 编译 JavaScript 代码时,解析器(parser)将生成一个抽象语法树(上一小节已介绍过)。语法树是 JavaScript 代码的句法结构的树形表示形式。解释器 Ignition 根据语法树生成字节码。TurboFan 是 V8 的优化编译器,TurboFan 将字节码(Bytecode)生成优化的机器代码(Machine Code)。
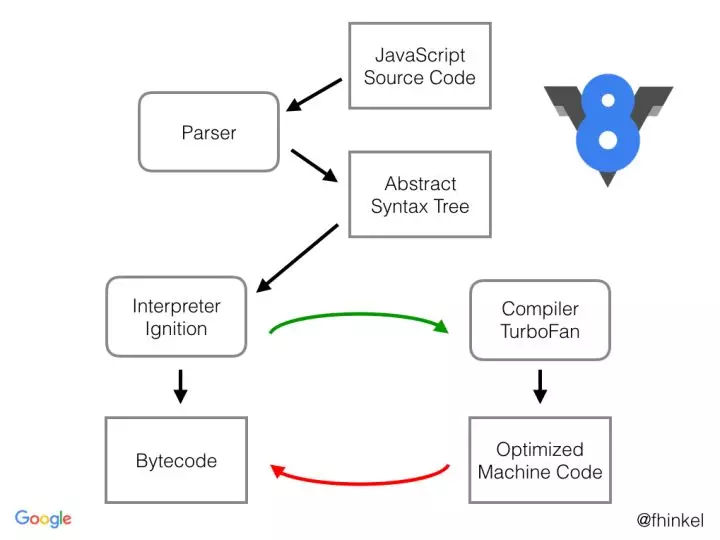
两个编译器
full-codegen - 一个简单而快速的编译器,可以生成简单且相对较慢的机器代码。
Crankshaft - 一种更复杂的(即时)优化编译器,可生成高度优化的代码。
多线程
主线程:获取代码,编译代码然后执行它
优化线程:与主线程并行,用于优化代码的生成
Profiler 线程:它将告诉运行时我们花费大量时间的方法,以便 Crankshaft 可以优化它们
其他一些线程来处理垃圾收集器扫描
字节码
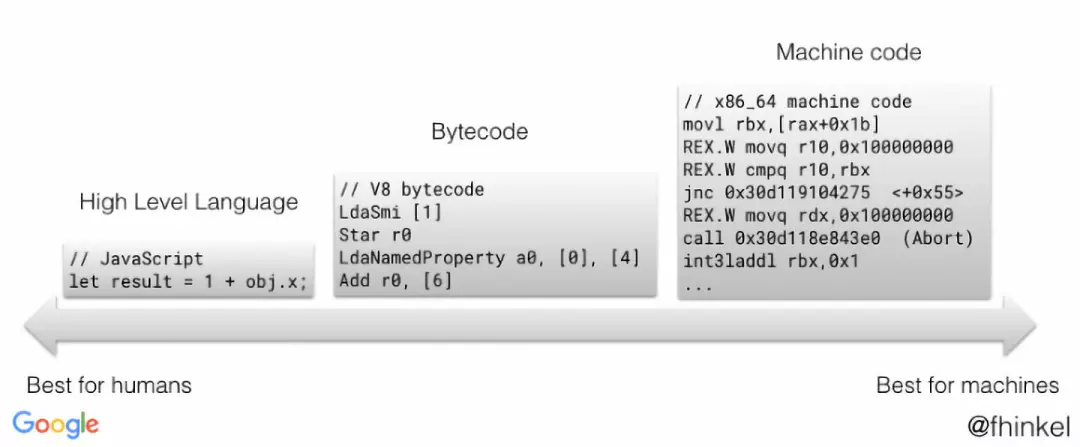
字节码是机器代码的抽象。如果字节码采用和物理 CPU 相同的计算模型进行设计,则将字节码编译为机器代码更容易。这就是为什么解释器(interpreter)常常是寄存器或堆栈。 Ignition 是具有累加器的寄存器。
头文件 bytecodes.h(https://github.com/v8/v8/blob/master/src/interpreter/bytecodes.h) 定义了 V8 字节码的完整列表。
在早期的 V8 引擎里,在多数浏览器都是基于字节码的,V8 引擎偏偏跳过这一步,直接将 jS 编译成机器码,之所以这么做,就是节省了时间提高效率,但是后来发现,太占用内存了。最终又退回字节码了,之所以这么做的动机是什么呢?
减轻机器码占用的内存空间,即牺牲时间换空间。(主要动机)
提高代码的启动速度 对 v8 的代码进行重构。
降低 v8 的代码复杂度。
V8 引擎为什么那么快
内联(Inlining)
内联特性是一切优化的基础,对于良好的性能至关重要,所谓的内联就是如果某一个函数内部调用其它的函数,编译器直接会将函数中的执行内容,替换函数方法。
function add(a, b) {return a + b;}function calculateTwoPlusFive() {var sum;for (var i = 0; i <= 1000000000; i++) {sum = add(2 + 5);}}var start = new Date();calculateTwoPlusFive();var end = new Date();var timeTaken = end.valueOf() - start.valueOf();console.log("Took " + timeTaken + "ms");
由于内联属性特性,在编译前,代码将会被优化成
function add(a, b) {return a + b;}function calculateTwoPlusFive() {var sum;for (var i = 0; i <= 1000000000; i++) {sum = 2 + 5;}}var start = new Date();calculateTwoPlusFive();var end = new Date();var timeTaken = end.valueOf() - start.valueOf();console.log("Took " + timeTaken + "ms");
隐藏类(Hidden class)
例如 C++/Java 这种静态类型语言的每一个变量,都有一个唯一确定的类型。因为有类型信息,一个对象包含哪些成员和这些成员在对象中的偏移量等信息,编译阶段就可确定,执行时 CPU 只需要用对象首地址 —— 在 C++中是 this 指针,加上成员在对象内部的偏移量即可访问内部成员。这些访问指令在编译阶段就生成了。
但对于 JavaScript 这种动态语言,变量在运行时可以随时由不同类型的对象赋值,并且对象本身可以随时添加删除成员。访问对象属性需要的信息完全由运行时决定。为了实现按照索引的方式访问成员,V8“悄悄地”给运行中的对象分了类,在这个过程中产生了一种 V8 内部的数据结构,即隐藏类。隐藏类本身是一个对象
内联缓存(Inline caching)
正常访问对象属性的过程:首先获取隐藏类的地址,然后根据属性名查找偏移值,然后计算该属性的地址。虽然相比以往在整个执行环境中查找减小了很大的工作量,但依然比较耗时。能不能将之前查询的结果缓存起来,供再次访问呢?
内嵌缓存:将初次查找的隐藏类和偏移值保存起来,当下次查找的时候,先比较当前对象是否是之前的隐藏类,如果是的话,直接使用之前的缓存结果,减少再次查找表的时间。当然,如果一个对象有多个属性,那么缓存失误的概率就会提高,因为某个属性的类型变化之后,对象的隐藏类也会变化,就与之前的缓存不一致,需要重新使用以前的方式查找哈希表
内存管理
内存的管理主要由分配和回收两个部分构成:
Zone: 管理小块内存。先自己申请一块内存,然后管理和分配一些小内存,当一块小内存被分配后,不能被 Zone 回收,只能一次性回收 Zone 分配的所有小内存。当一个过程需要很多内存,Zone 将需要分配大量的内存,却又不能及时回收,会导致内存不足的情况
堆: 管理 JS 使用的数据、生成的代码、哈希表等。为方便实现垃圾回收,堆被分为三个部分
年轻分代:为新创建的对象分配内存空间,经常需要进行垃圾回收。为方便年轻分代中的内容回收,可再将年轻分代分为两半,一半用来分配,另一半在回收时负责将之前还需要保留的对象复制过来
年老分代:根据需要将年老的对象、指针、代码等数据保存起来,较少地进行垃圾回收
大对象:为那些需要使用较多内存对象分配内存,当然同样可能包含数据和代码等分配的内存,一个页面只分配一个对象
垃圾回收
V8 使用了分代和大数据的内存分配,在回收内存时使用精简整理的算法标记未引用的对象,然后消除没有标记的对象, 整理和压缩那些还未保存的对象,即可完成垃圾回收
为了控制GC 成本并使执行更加稳定,V8 使用增量标记,而不是遍历整个堆,它试图标记每个可能的对象,只遍历一部分堆,然后恢复正常的代码执行。下一次 GC 将继续从之前的遍历停止的位置开始。这允许在正常执行期间非常短的暂停。 如前所述,扫描阶段由单独的线程处理。
优化回退
V8 为了进一步提升 JS 代码的执行效率,编译器直接生成更高效的机器码。程序在运行时,V8 会采集 JS 代码运行数据。当 V8 发现某函数执行频繁(内联函数机制),就将其标记为热点函数。针对热点函数,V8 的策略较为乐观,倾向于认为此函数比较稳定,类型已经确定,于是编译器,生成更高效的机器码。后面的运行中,万一遇到类型变化,V8 采取将 JS 函数回退到优化前的编译成机器字节码。
// 片段 1var person = {add: function(a, b) {return a + b;}};obj.name = "li";// 片段 2var person = {add: function(a, b) {return a + b;},name: "li"};
以上代码实现的功能相同,都是定义了一个对象,这个对象具有一个属性 name 和一个方法 add()。但使用片段 2 的方式效率更高。片段 1 给对象 obj 添加了一个属性 name,这会造成隐藏类的派生。给对象动态地添加和删除属性都会派生新的隐藏类。假如对象的 add 函数已经被优化,生成了更高效的代码,则因为添加或删除属性,这个改变后的对象无法使用优化后的代码。
从例子中我们可以看出:函数内部的参数类型越确定,V8 越能够生成优化后的代码。
写更优化的代码
- 对象属性的顺序:始终以相同的顺序实例化对象属性,以便可以共享隐藏类和随后优化的代码
- 动态属性:在实例化后向对象添加属性将强制隐藏类更改,并任何为先前隐藏类优化的方法变慢,所以,使用在构造函数中分配对象的所有属性来代替
- 方法:重复执行相同方法的代码将比只执行一次的代码(由于内联缓存)运行的快
- 数组:避免键不是增量数字的稀疏数组,稀疏数组是一个哈希表,这种阵列中的元素访问消耗较高,另外,尽量避免预分配大型数组,最好按需分配,自动增加。最后,不要删除数组中的元素,它使键稀疏。

若有收获,就点个赞吧
0 人点赞
