OCDP5.0 hive操作手册
前言:
由于OCDP5.0hive改造较大,之前OCDP版本的使用方式会有所变动。为了便于现场进行改造,本文档将对OCDP5.0使用进行详细测试。
1. Hive的连接访问
(1)访问方式:
OCDP5.0hive版本为3.1.0
Hive3.1.0禁止了hive client访问方式,只提供jdbc连接方式(beeline或代码)。
现场之前所有使用hive client执行SQL的应用都需要改造。
Beeline访问方式如下:
beeline -u jdbc:hive2://10.1.236.84:10000 -n ocdc -p ocdc

注:-n后面为用户,-p后面为用户密码。
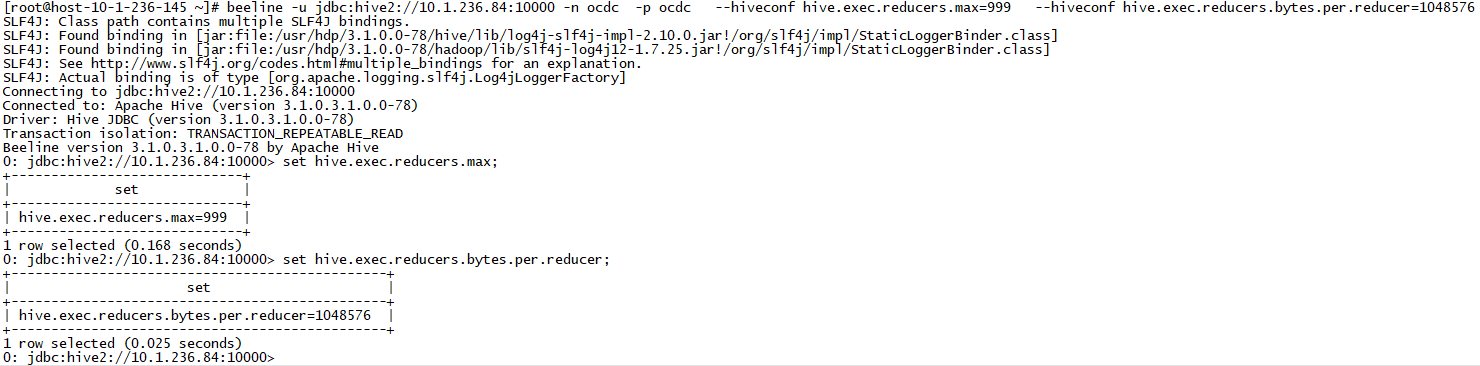
(2)beeline带参数启动启动
beeline -u jdbc:hive2://10.1.236.84:10000 -n ocdc -p ocdc —hiveconf hive.exec.reducers.max=999 —hiveconf hive.exec.reducers.bytes.per.reducer=1048576
(3)beeline直接执行SQL返回
beeline -u jdbc:hive2://10.1.236.84:10000 -n ocdc -p ocdc -e “select * from audit limit 5;”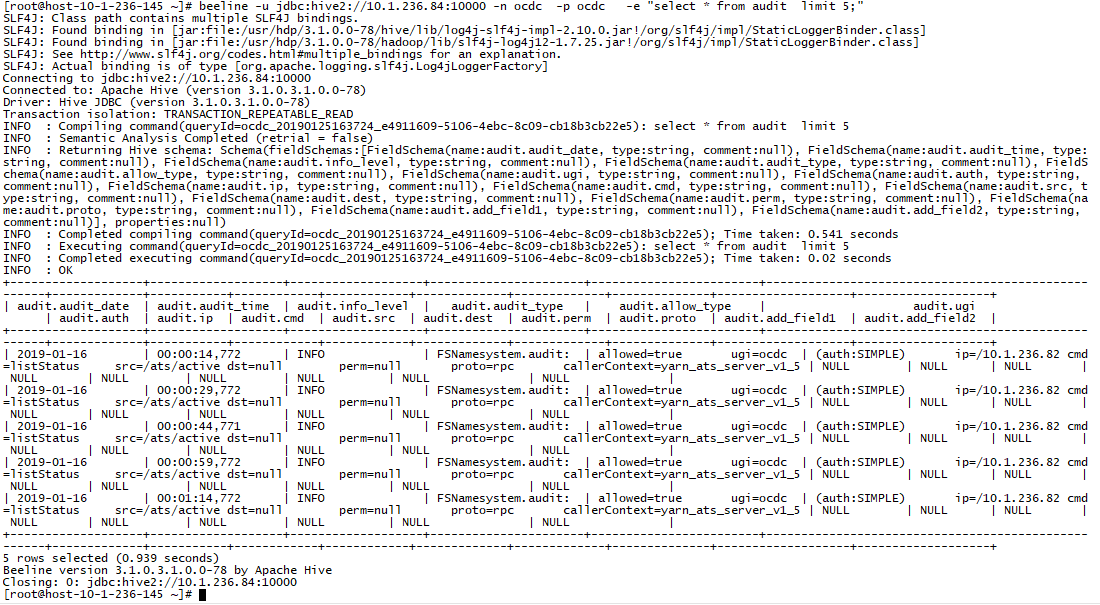
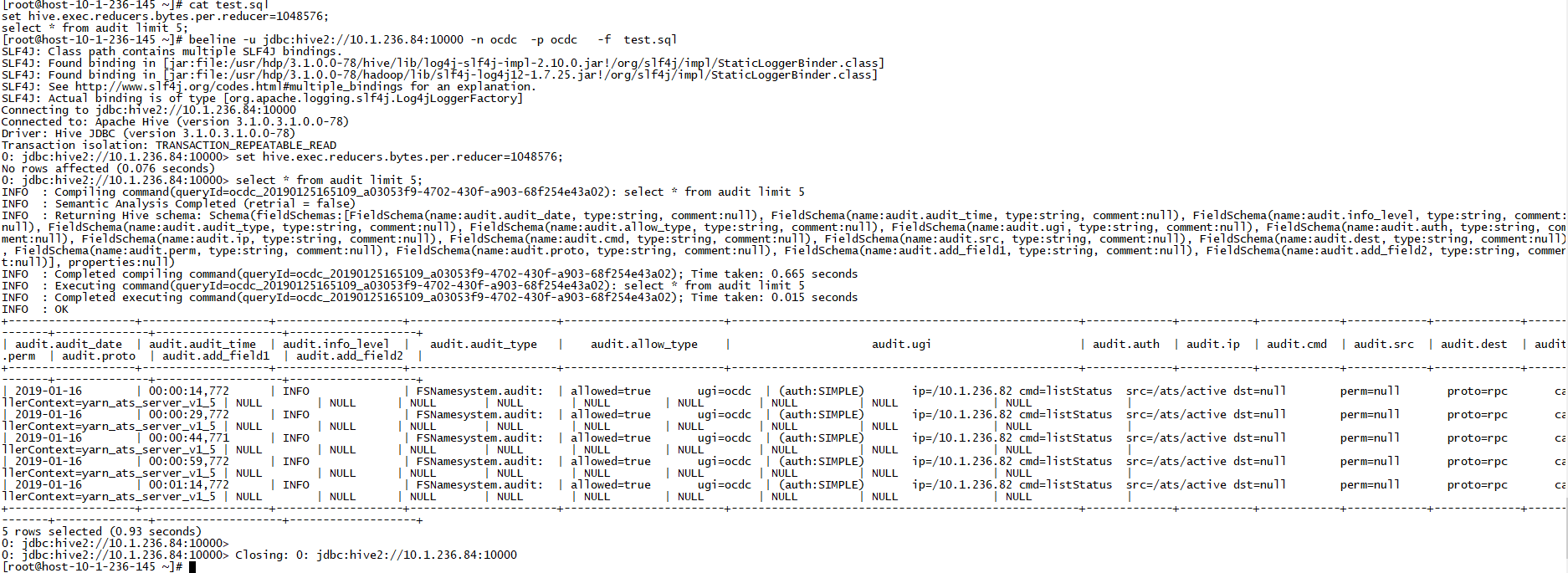
(4)beeline执行SQL文件
beeline -u jdbc:hive2://10.1.236.84:10000 -n ocdc -p ocdc -f test.sql
2. 数据加载
(1)从hdfs目录load数据到hive表:
load data inpath “/yinkp/data” into table audit;
(2)从linux目录load数据到hive表
注:由于无法使用hive client方式访问hive,所以从linux上load数据到hive表时,只能从hiveserver2所在linux主机目录进行load,如果现场有从其它主机load的,建议将数据put到hdfs,然后再从hdfs load到hive表中。
load data local inpath “file:///var/log/hadoop/ocdc/data” into table audit;
遇到的问题:
ERROR [HiveServer2-Background-Pool: Thread-412]: ql.Driver (:()) - FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.MoveTask. org.apache.hadoop.hive.ql.metadata.HiveException: Load Data failed for hdfs://ocdp/yinkp/data/data as the file is not owned by hive and load data is also not ran as hive
解决方法:(修改为hdfs服务启动用户)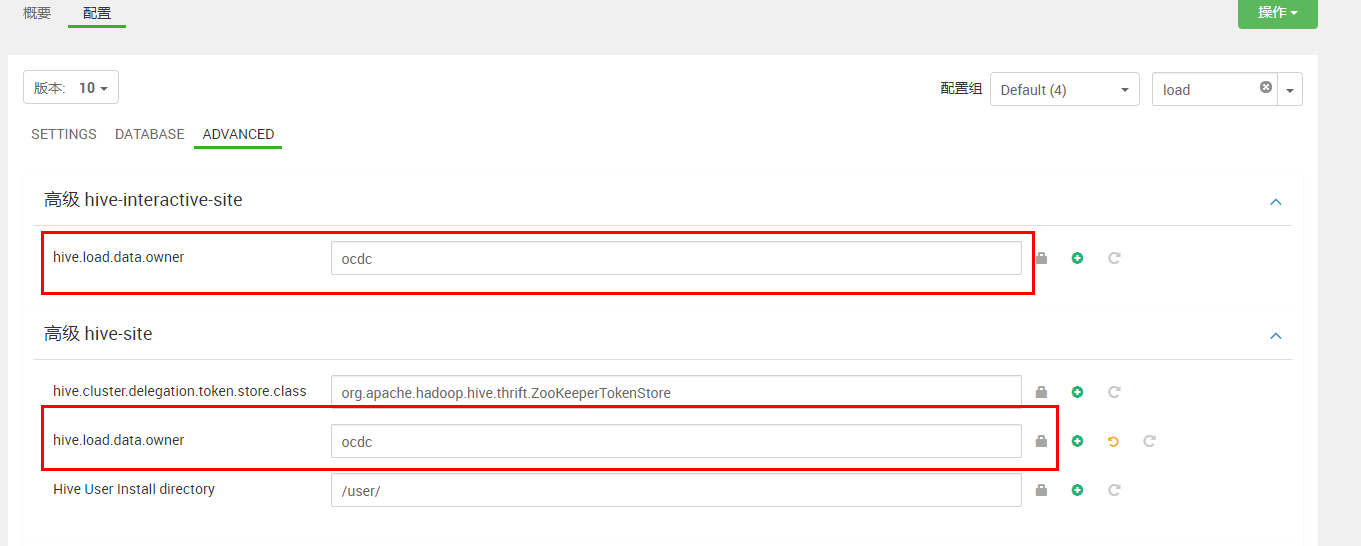
重启hive服务即可。
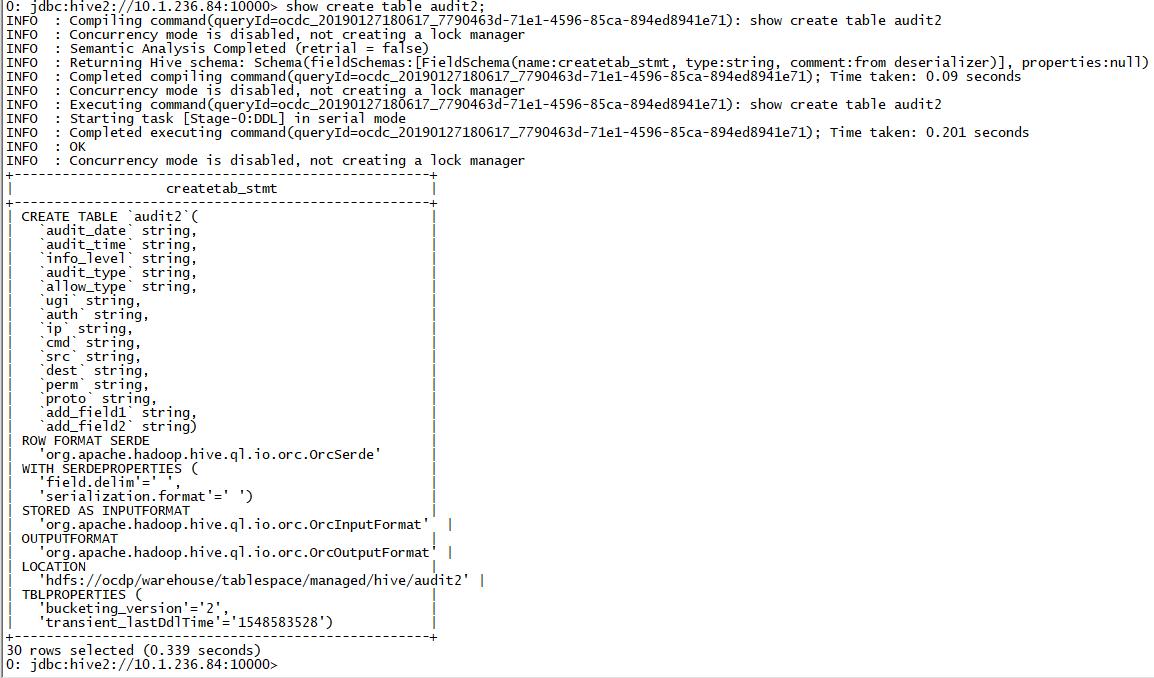
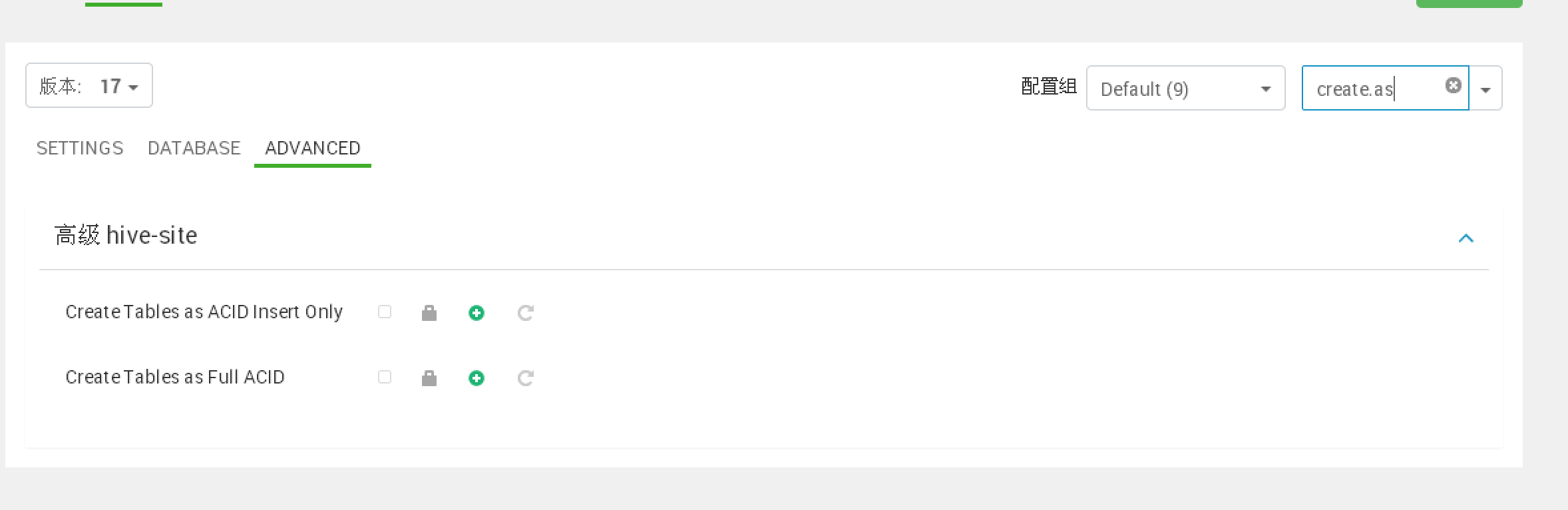
3. hive acid表使用
默认开启: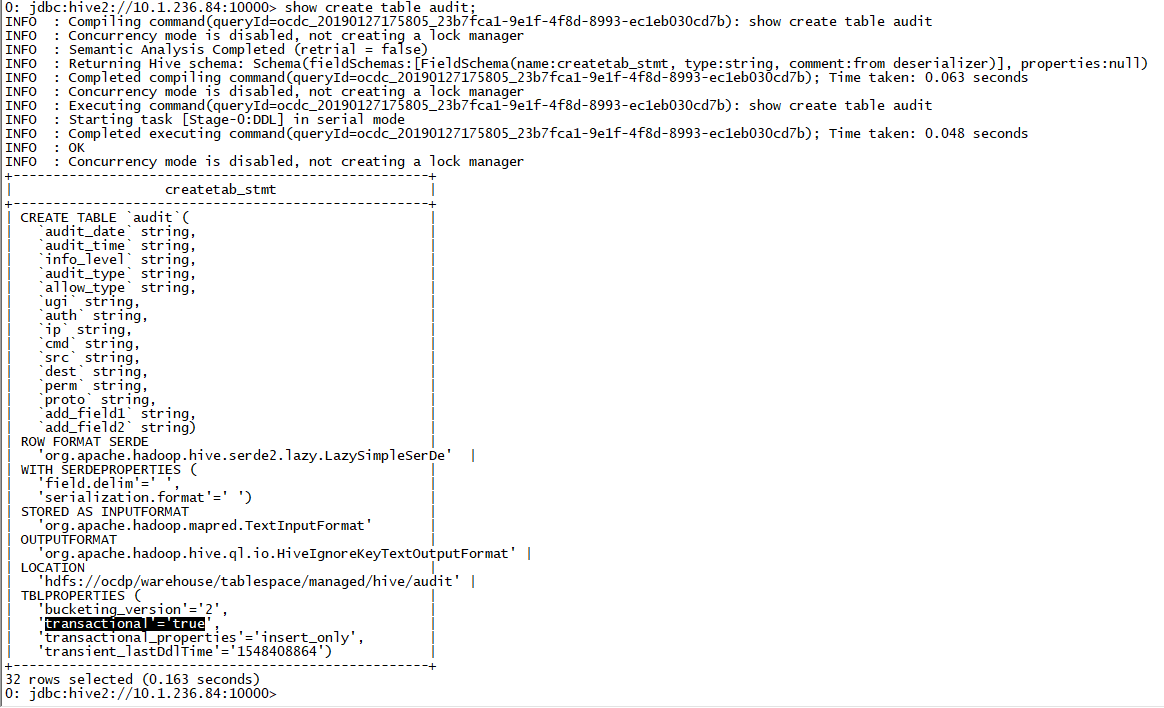
建议关闭。
hive.support.concurrency=false;
hive.exec.dynamic.partition.mode = strict;
hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DummyTxnManager;
hive.strict.managed.tables=false
hive.create.as.insert.only=false
metastore.create.as.acid=false
hive.compactor.initiator.on=false;
hive.compactor.worker.threads=0;
4. spark访问hive表
hive与spark 集成配置:
spark修改
spark.sql.warehouse.dir=/apps/hive/warehouse
关闭http kerberos 认证
hadoop.http.authentication.simple.anonymous.allowed=true
hadoop.http.authentication.type=simple
Spark与hive数据共享:
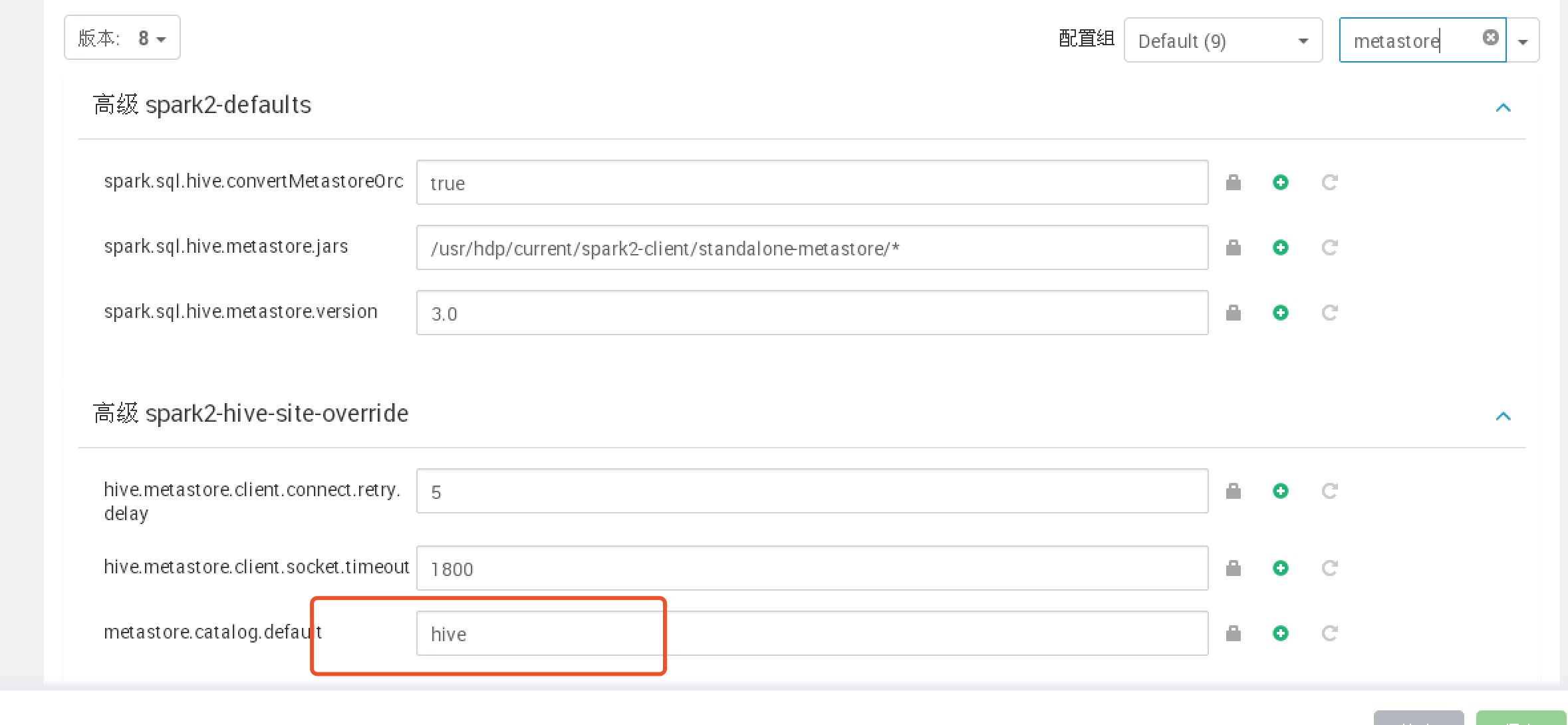
beeline -u “jdbc:hive2://oc-data-cs-09:10016/default;principal=spark/oc-data-cs-09@dragon” —verbose —spark2.x测试升级后!!!(使用spark principal)
hive修改
hive.compactor.initiator.on=false;
hive.compactor.worker.threads=0;
hive.strict.managed.tables=false;
hive.create.as.insert.only=false;
metastore.create.as.acid=false;
hive.metastore.warehouse.dir=/apps/hive/warehouse
hive.metastore.warehouse.external.dir=/apps/hive/warehouse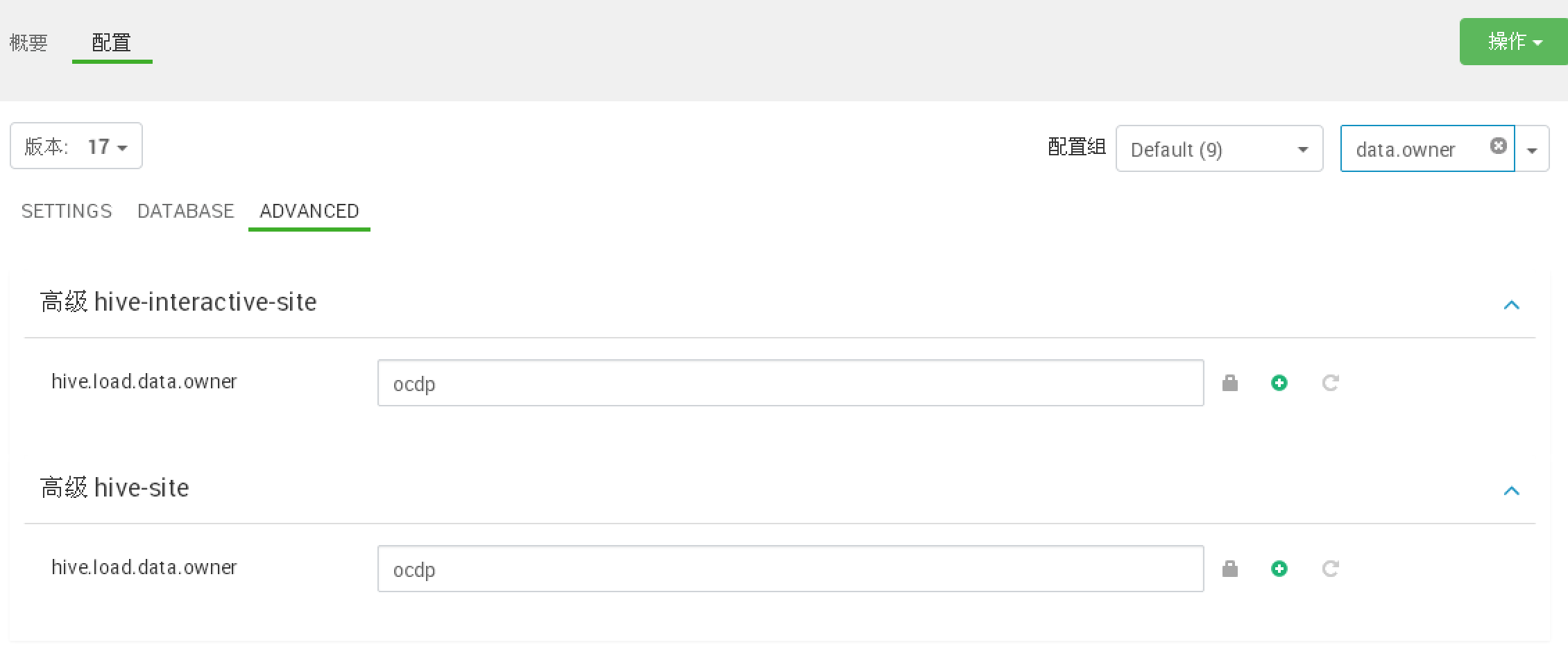
5. 启用LLAP功能
启用LLAP (“Hive interactive”),hive会单独再启动一个HiveServer2 interactive服务。不影响其他的**HivserServer2。
新的HiveServer2 interactive服务有单独的访问端口、单独的连接URL、单独的配置和日志。
一、修改yarn Preemption配置
配置资源抢占,Capacity Scheduler会把Hive LLAP队列定位为在cluster节点资源之间运行的最高优先级工作负载。
l Ambari中,服务->YARN->config->settings,点击“Pre-emption”滑块,设置为“Enabled”: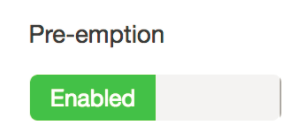
l Ambari中,服务->YARN->config->Advanced,在“Customer Yarn-site”中,找到并修改以下两个属性,推荐值如下:
ü yarn.resourcemanager.monitor.capacity.preemption.natural_termination_factor=1
ü yarn.resourcemanager.monitor.capacity.preemption.total_preemption_per_round=${1/集群中nodemanager节点数}。输入小数值,1除以集群中nodemanager节点数。如集群中有20个nodemanager节点,则1除以20=0.05,输入0.05。用于计算**llap队列的百分比。
二、启用HIVE2 LLAP(典型安装)
Ambari中,服务->HIVE->CONFIG->settings,找到“Interactive Query”,并将“Enable Interactive Query”设置为YES。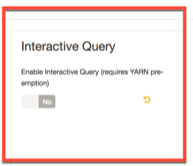
此时,会c
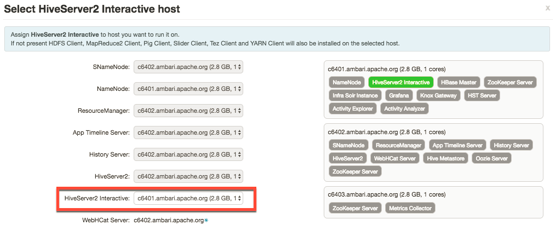
然后点击“选择”。
当“settings”选项卡再次打开时,查看出现在页面中的“交互式查询”部分中的其他配置字段:

若有收获,就点个赞吧
0 人点赞
