说明:此方案不是针对与split,而是包含split在内的所有对字符串对大数据量处理的的函数。
问题现象:
做如下查询时:
set tez.queue.name=test_hive;create table itd_dr_wzdc.tmp_test_0729_1asselecturi,protocal,host,path,vid,concat(host_fields[size(host_fields) - 2],'.',host_fields[size(host_fields) - 2]) key_wordfrom (selectconcat(protocal,'://',host,path) path,protocal,host,vid,split(host,'\\.') host_fields,urifrom (select parse_url(uri,'HOST') host,parse_url(uri,'PROTOCOL') protocal,parse_url(uri,'PATH') path,parse_url(uri,'QUERY','vid') vid,urifrom dwd.dwd_nlog_dpi_234g_http_info_hs where hour_id = '2020072520') a) aa;
此表(dwd.dwd_nlog_dpi_234g_http_info_hs)有大概40亿条数据左右,map端会特别慢,最终导致任务失败
问题分析:
一、分别测试这里面用到的函数对整个sql的影响
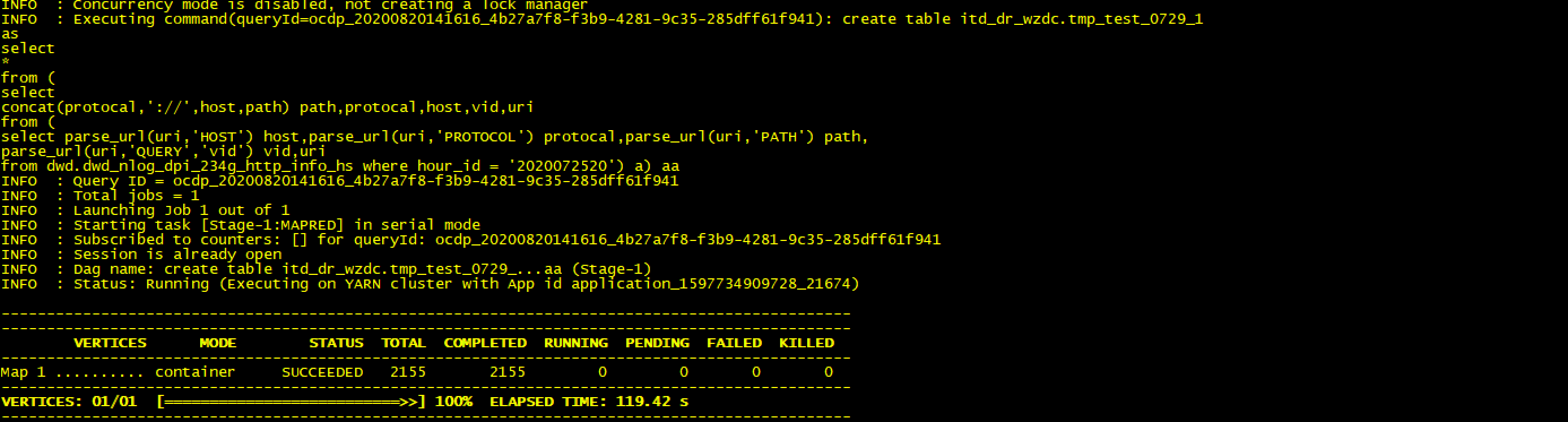
1.不用split函数测试结果如下
set tez.queue.name=test_hive;create table itd_dr_wzdc.tmp_test_0729_1asselect*from (selectconcat(protocal,'://',host,path) path,protocal,host,vid,urifrom (select parse_url(uri,'HOST') host,parse_url(uri,'PROTOCOL') protocal,parse_url(uri,'PATH') path,parse_url(uri,'QUERY','vid') vid,urifrom dwd.dwd_nlog_dpi_234g_http_info_hs where hour_id = '2020072520') a) aa;
2.用到split函数测试结果如下
set tez.queue.name=test_hive;create table itd_dr_wzdc.tmp_test_0729_1asselect*from (selectconcat(protocal,'://',host,path) path,protocal,host,vid,split(host,'\\.') host_fields,urifrom (select parse_url(uri,'HOST') host,parse_url(uri,'PROTOCOL') protocal,parse_url(uri,'PATH') path,parse_url(uri,'QUERY','vid') vid,urifrom dwd.dwd_nlog_dpi_234g_http_info_hs where hour_id = '2020072520') a) aa;
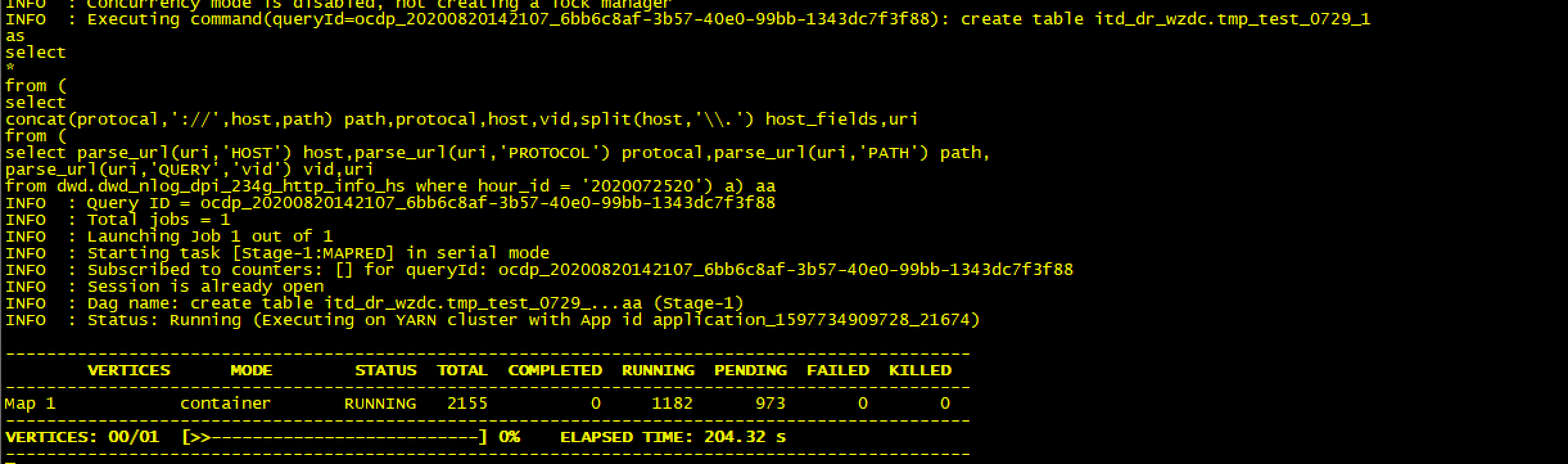
map竟然这么慢,在等等看结果
3.split中的转译符\的影响测试
无影响
二、测试数据量多少对此sql的影响
1.测试1亿条数据结果如下
set tez.queue.name=test_hive;create table itd_dr_wzdc.tmp_test_0729_1asselecturi,protocal,host,path,vid,concat(host_fields[size(host_fields) - 2],'.',host_fields[size(host_fields) - 2]) key_wordfrom (selectconcat(protocal,'://',host,path) path,protocal,host,vid,split(host,'\\.') host_fields,urifrom (select parse_url(uri,'HOST') host,parse_url(uri,'PROTOCOL') protocal,parse_url(uri,'PATH') path,parse_url(uri,'QUERY','vid') vid,urifrom dwd.dwd_nlog_dpi_234g_http_info_hs where hour_id = '2020072520' limit 100000000) a) aa;
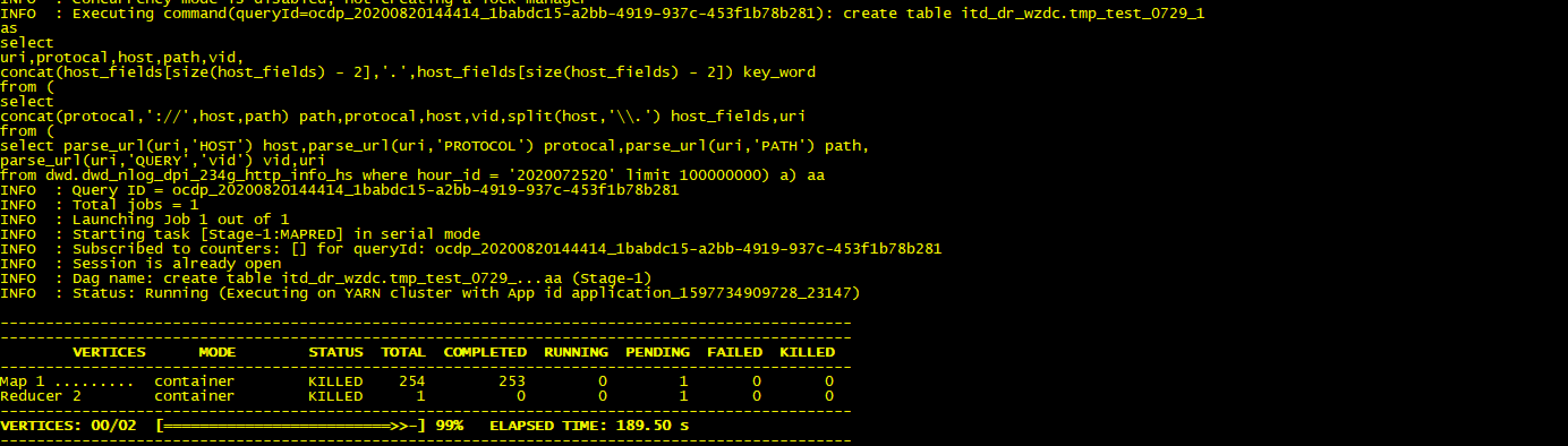
2.测试20亿条数据结果如下
set tez.queue.name=test_hive;create table itd_dr_wzdc.tmp_test_0729_1asselecturi,protocal,host,path,vid,concat(host_fields[size(host_fields) - 2],'.',host_fields[size(host_fields) - 2]) key_wordfrom (selectconcat(protocal,'://',host,path) path,protocal,host,vid,split(host,'\\.') host_fields,urifrom (select parse_url(uri,'HOST') host,parse_url(uri,'PROTOCOL') protocal,parse_url(uri,'PATH') path,parse_url(uri,'QUERY','vid') vid,urifrom dwd.dwd_nlog_dpi_234g_http_info_hs where hour_id = '2020072520' limit 1999999999) a) aa;
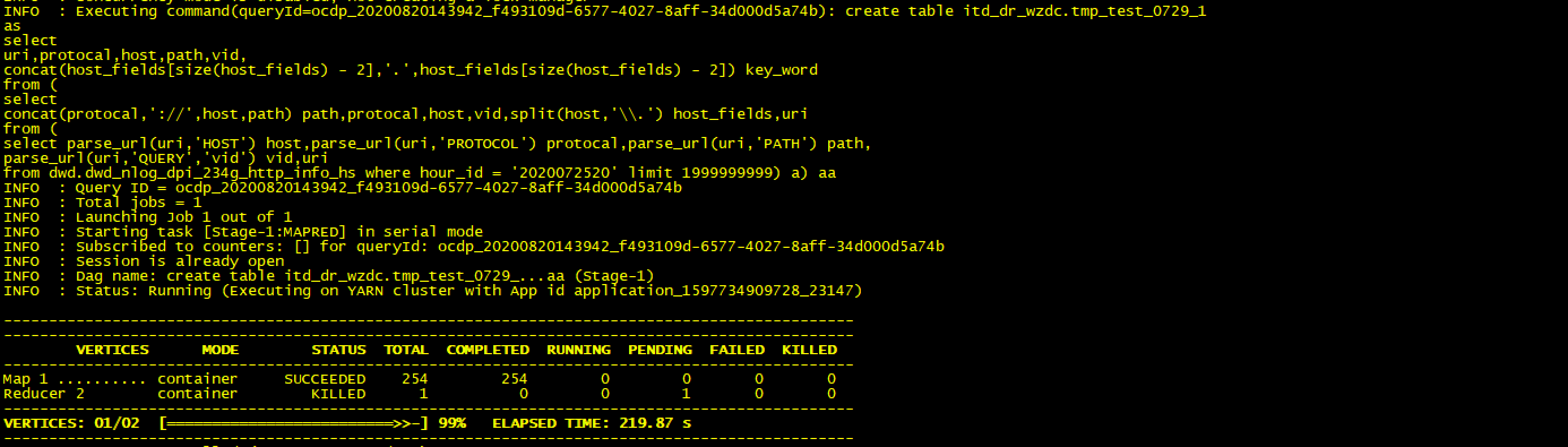
map正常
3.测试40亿条数据结果如下
set tez.queue.name=test_hive;create table itd_dr_wzdc.tmp_test_0729_1asselecturi,protocal,host,path,vid,concat(host_fields[size(host_fields) - 2],'.',host_fields[size(host_fields) - 2]) key_wordfrom (selectconcat(protocal,'://',host,path) path,protocal,host,vid,split(host,'\\.') host_fields,urifrom (select parse_url(uri,'HOST') host,parse_url(uri,'PROTOCOL') protocal,parse_url(uri,'PATH') path,parse_url(uri,'QUERY','vid') vid,urifrom dwd.dwd_nlog_dpi_234g_http_info_hs where hour_id = '2020072520') a) aa;
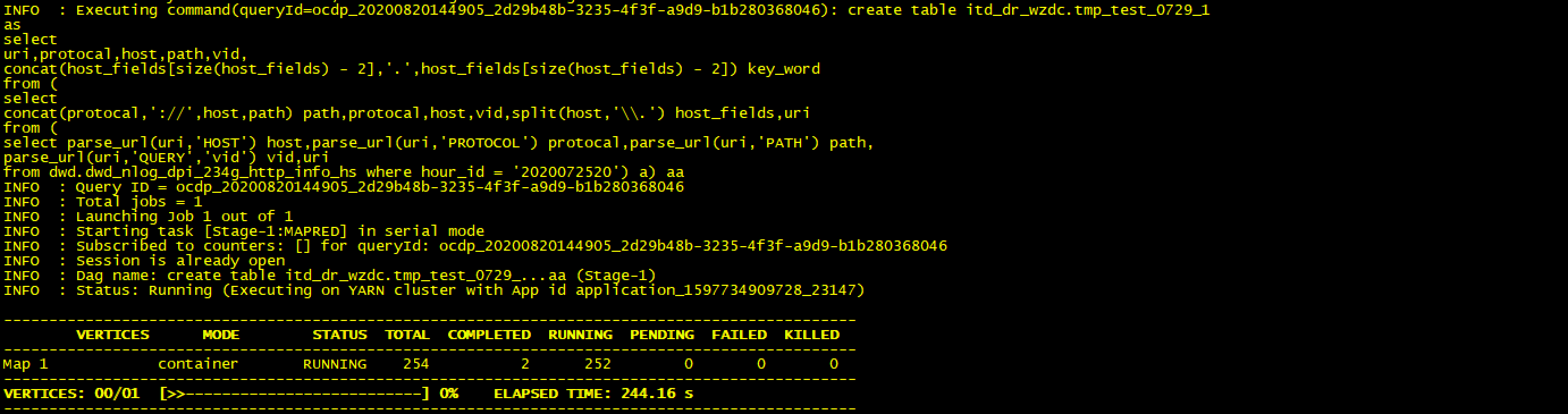
显而易见,map端特别慢,在等等看结果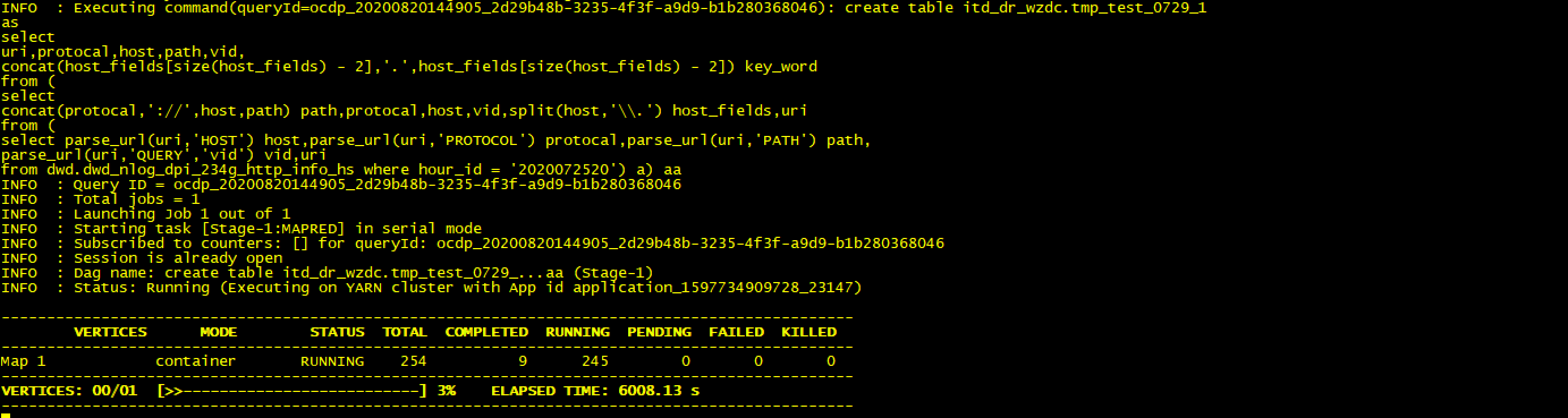
卡死在这儿不动了,看一下job日志
yarn logs -applicationId application_159*_23147 > hivetest.log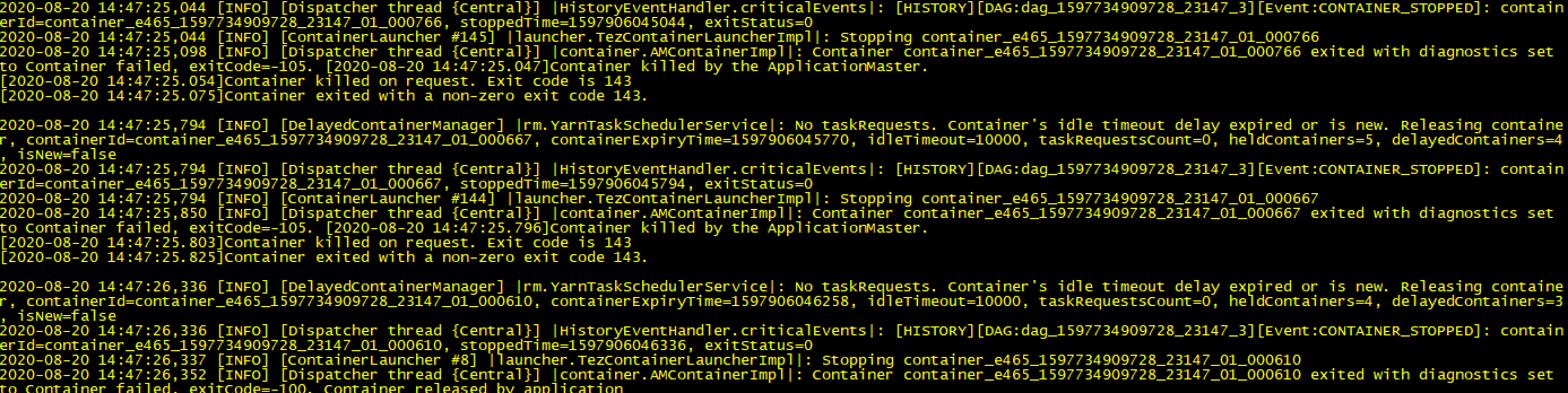 根据日志发现如下报错:
根据日志发现如下报错:
Container killed on request. Exit code is 143
表面现象:
内存分配不足,需要修改内存配置
三、hive优化测试
1.调节container内存大小进行测试
set mapreduce.map.memory.mb=30720
set mapreduce.reduce.memory.mb=30720
2.调节map,reduce数量
3.其他hive,yarn参数优化
测试结果:无效
四、自定义udf函数测试
1.对自定义udf函数进行一系列优化多次测试
上传jar包到hdfshadoop fs -put SplitUDF-0.0.1-SNAPSHOT.jar /lxl/创建函数CREATE TEMPORARY FUNCTION split_asiainfo AS 'Asiainfo.SplitUDF.GenericUDFSplitAsiainfo' using jar 'hdfs:///lxl/SplitUDF-0.0.1-SNAPSHOT.jar';执行测试sqlcreate table itd_dr_wzdc.tmp_test_0729_13asselecturi,protocal,host,path,vid,concat(host_fields[size(host_fields) - 2],'.',host_fields[size(host_fields) - 2]) key_wordfrom (selectconcat(protocal,'://',host,path) path,protocal,host,vid,split_asiainfo(host,'\\.') host_fields,urifrom (select parse_url(uri,'HOST') host,parse_url(uri,'PROTOCOL') protocal,parse_url(uri,'PATH') path,parse_url(uri,'QUERY','vid') vid,urifrom dwd.dwd_nlog_dpi_234g_http_info_hs where hour_id = '2020080221') a) aa;
测试结果:无效,证明split函数本身是没问题的。
五、split执行时java线程分析
jstack -l 14954 | grep 0x3af0 -A20
"TezChild" #15 daemon prio=5 os_prio=0 tid=0x00007f157538d800 nid=0x3af0 runnable [0x00007f1547581000]java.lang.Thread.State: RUNNABLEat org.apache.hadoop.hive.ql.exec.vector.VectorAssignRow.assignRowColumn(VectorAssignRow.java:573)at org.apache.hadoop.hive.ql.exec.vector.VectorAssignRow.assignRowColumn(VectorAssignRow.java:350)at org.apache.hadoop.hive.ql.exec.vector.udf.VectorUDFAdaptor.setResult(VectorUDFAdaptor.java:205)at org.apache.hadoop.hive.ql.exec.vector.udf.VectorUDFAdaptor.evaluate(VectorUDFAdaptor.java:150)at org.apache.hadoop.hive.ql.exec.vector.expressions.VectorExpression.evaluateChildren(VectorExpression.java:271)at org.apache.hadoop.hive.ql.exec.vector.expressions.ListIndexColScalar.evaluate(ListIndexColScalar.java:59)at org.apache.hadoop.hive.ql.exec.vector.VectorSelectOperator.process(VectorSelectOperator.java:146)at org.apache.hadoop.hive.ql.exec.Operator.vectorForward(Operator.java:965)at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:938)at org.apache.hadoop.hive.ql.exec.TableScanOperator.process(TableScanOperator.java:125)at org.apache.hadoop.hive.ql.exec.vector.VectorMapOperator.process(VectorMapOperator.java:889)at org.apache.hadoop.hive.ql.exec.tez.MapRecordSource.processRow(MapRecordSource.java:92)at org.apache.hadoop.hive.ql.exec.tez.MapRecordSource.pushRecord(MapRecordSource.java:76)at org.apache.hadoop.hive.ql.exec.tez.MapRecordProcessor.run(MapRecordProcessor.java:426)at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:267)at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:250)at org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:374)at org.apache.tez.runtime.task.TaskRunner2Callable$1.run(TaskRunner2Callable.java:73)at org.apache.tez.runtime.task.TaskRunner2Callable$1.run(TaskRunner2Callable.java:61)[yarn@hdp32b ~]$ jstack -l 14954 | grep 0x3af0 -A20"TezChild" #15 daemon prio=5 os_prio=0 tid=0x00007f157538d800 nid=0x3af0 runnable [0x00007f1547581000]java.lang.Thread.State: RUNNABLEat org.apache.hadoop.hive.ql.exec.vector.BytesColumnVector.ensureSize(BytesColumnVector.java:554)at org.apache.hadoop.hive.ql.exec.vector.VectorAssignRow.assignRowColumn(VectorAssignRow.java:570)at org.apache.hadoop.hive.ql.exec.vector.VectorAssignRow.assignRowColumn(VectorAssignRow.java:350)at org.apache.hadoop.hive.ql.exec.vector.udf.VectorUDFAdaptor.setResult(VectorUDFAdaptor.java:205)at org.apache.hadoop.hive.ql.exec.vector.udf.VectorUDFAdaptor.evaluate(VectorUDFAdaptor.java:150)at org.apache.hadoop.hive.ql.exec.vector.expressions.VectorExpression.evaluateChildren(VectorExpression.java:271)at org.apache.hadoop.hive.ql.exec.vector.expressions.ListIndexColScalar.evaluate(ListIndexColScalar.java:59)at org.apache.hadoop.hive.ql.exec.vector.VectorSelectOperator.process(VectorSelectOperator.java:146)at org.apache.hadoop.hive.ql.exec.Operator.vectorForward(Operator.java:965)at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:938)at org.apache.hadoop.hive.ql.exec.TableScanOperator.process(TableScanOperator.java:125)at org.apache.hadoop.hive.ql.exec.vector.VectorMapOperator.process(VectorMapOperator.java:889)at org.apache.hadoop.hive.ql.exec.tez.MapRecordSource.processRow(MapRecordSource.java:92)at org.apache.hadoop.hive.ql.exec.tez.MapRecordSource.pushRecord(MapRecordSource.java:76)at org.apache.hadoop.hive.ql.exec.tez.MapRecordProcessor.run(MapRecordProcessor.java:426)at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:267)at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:250)at org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:374)at org.apache.tez.runtime.task.TaskRunner2Callable$1.run(TaskRunner2Callable.java:73)
观察jstacks任务发现,似乎它正在运行矢量化UDF并陷入某些循环的代码。
参考:https://issues.apache.org/jira/browse/HIVE-21935
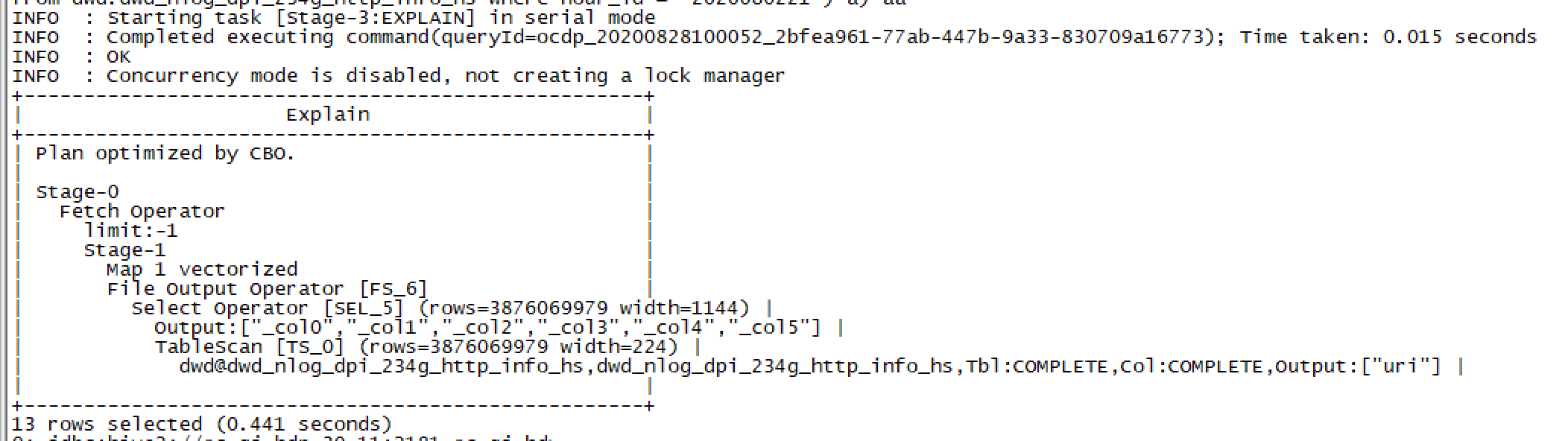
查看任务是否有矢量化执行:
EXPLAIN VECTORIZATION selecturi,protocal,host,path,vid,concat(host_fields[size(host_fields) - 2],'.',host_fields[size(host_fields) - 2]) key_wordfrom (selectconcat(protocal,'://',host,path) path,protocal,host,vid,split(host,'\\.') host_fields,urifrom (select parse_url(uri,'HOST') host,parse_url(uri,'PROTOCOL') protocal,parse_url(uri,'PATH') path,parse_url(uri,'QUERY','vid') vid,urifrom dwd.dwd_nlog_dpi_234g_http_info_hs where hour_id = '2020073021') a) aa
六、可行方案
方案一:
禁用向量化,以标准模式运行
set hive.vectorized.execution.enabled = false
方案二:
开启矢量化查询(默认是开启的)
set hive.vectorized.execution.enabled=true;
指定仅对使用本机矢量化UDF的查询进行矢量化(默认是all,对所有不使用矢量化查询)
set hive.vectorized.adaptor.usage.mode=chosen;
七、建议方案
基准测试表明启用Parquet矢量化后可以显著提升典型的ETL工作负载的性能。使用TPC-DS,启用Parquet矢量化可以使平均性能提升26.5%(所有查询运行时间的几何平均值)。Vectorization通过减少虚函数调用的数量,并利用CPU的SIMD指令来获得这些性能提升。当满足某些条件(如受支持的字段类型或表达式),使用Hive查询就会使用矢量化执行。如果查询不能使用矢量化,则会回退到非矢量化执行。所以不建议使用方案一。
根据测试结果,数据量大小以20亿为界限,根据现场情况,基本都是大于20亿数据量的,所以建议如下设置:
开启矢量化查询(默认是开启的)
set hive.vectorized.execution.enabled=true;
指定仅对使用本机矢量化UDF的查询进行矢量化(默认是all,对所有不使用矢量化查询)
set hive.vectorized.adaptor.usage.mode=chosen;
说明:指定矢量化引擎尝试对没有可用本机矢量化版本的UDF进行矢量化的程度。选择该none选项可指定仅对使用本机矢量化UDF的查询进行矢量化。选择该chosen选项将指定Hive选择使用Vectorized Adaptor基于性能优势对UDF的子集进行矢量化。选择该all选项可指定即使所有本机矢量化版本都不可用,也可将矢量化适配器用于所有UDF。
建议:为了获得最佳的稳定性和查询输出的正确性,请将此选项设置为chosen。
默认设置: chosen
39亿数据split测试结果如下: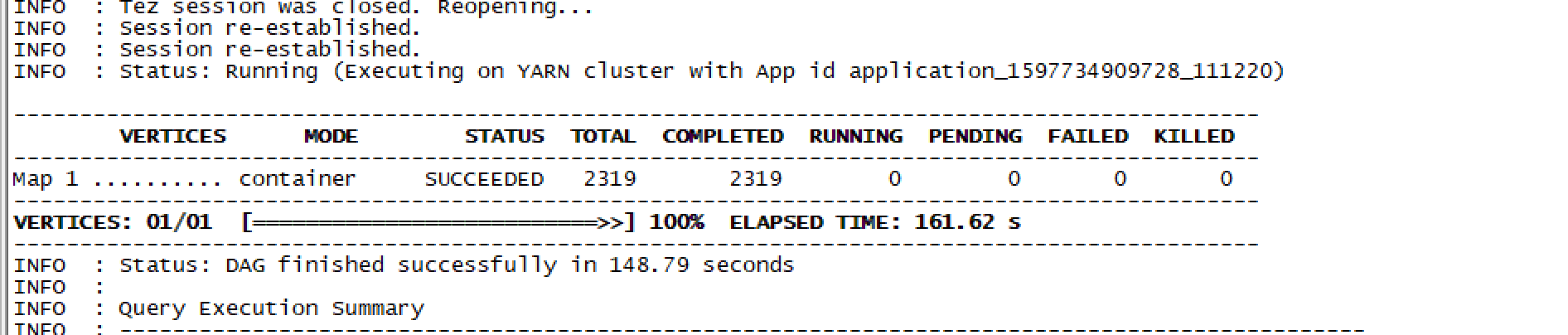
八、参考资料
https://issues.apache.org/jira/browse/HIVE-21935
https://www.docs4dev.com/docs/zh/apache-hive/3.1.1/reference/Vectorized_Query_Execution.html
https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/hive_query_vectorization.html

若有收获,就点个赞吧
0 人点赞
