- 1、背景
- 2、优化方案
- 3、方案测试
- 3.1、添加相关参数
- 3.2、重启StandByNameNode
- 3.3、重启ActiveNameNode
- 3.4、停止StandByNameNodeZKFC
- 3.5、停止ActiveNameNodeZKFC
- 3.6、FormatActiveNameNodeZKFC
- 3.7、FormatStandByNameNodeZKFC
- 3.8、启动ActiveNamenodeZKFC
- 3.9、启动StandByNamenodeZKFC
- 3.10、Rolling Restart The Datanodes
- 3.11、重启其它受影响的
- 3.12、验证生效
- 4.1、删除还原添加的参数
- 4.2、Rolling Restart The Datanodes
- 4.3、停止StandByNameNodeZKFC
- 4.4、停止ActiveNameNodeZKFC
- 4.5、FormatActiveNameNodeZKFC
- 4.6、FormatStandByNameNodeZKFC
- 4.7、启动ActiveNamenodeZKFC
- 4.8、启动StandByNamenodeZKFC
- 4.9、重启StandByNameNode
- 4.10、重启ActiveNameNode
- 4.11、重启其它受影响的
- 4.12、验证生效
1、背景
辽宁移动RPC请求量大,RPC响应时间长,影响NameNode的性能。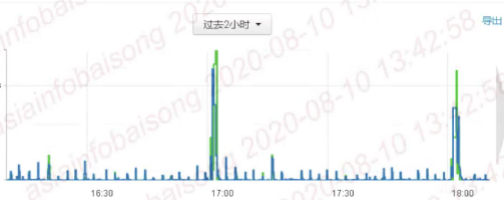
2、优化方案
2.1、启用Service RPC port
服务RPC端口为DataNodes提供了专用端口,以通过块报告和心跳报告其状态。Zookeeper故障转移控制器还使用该端口通过自动故障转移逻辑进行定期运行状况检查。客户端应用程序从不使用该端口,因此可以减少客户端请求和DataNode消息之间的RPC队列争用。
操作步骤:
1、Ambari -> HDFS -> Configs -> Advanced -> Custom hdfs-site -> Add Property
dfs.namenode.servicerpc-address.
dfs.namenode.servicerpc-address.
dfs.namenode.service.handler.count=(dfs.namenode.handler.count / 2)
This RPC port receives all DN and ZKFC requests like block report, heartbeat, liveness report, etc..
Example from hdfs-site.xml,
dfs.nameservices=shva
dfs.internal.nameservices=shva
dfs.ha.namenodes.shva=nn1,nn2
dfs.namenode.rpc-address.shva.nn1=hwxunsecure2641.openstacklocal:8020
dfs.namenode.rpc-address.shva.nn2=hwxunsecure2642.openstacklocal:8020
dfs.namenode.handler.count=200
Service RPC host, port and handler threads:
dfs.namenode.servicerpc-address.shva.nn1=hwxunsecure2641.openstacklocal:8040
dfs.namenode.servicerpc-address.shva.nn2=hwxunsecure2642.openstacklocal:8040
dfs.namenode.service.handler.count=100
2、Restart Standby Namenode. You must wait till Standby Namenode out of safemode.
Note: You can check Safemode status in Standby Namenode UI.
3、Restart Active Namenode.
4、Stop Standby Namenode ZKFC controller.
5、Stop Active Namenode ZKFC controller.
6、Login Active Namenode and reset Namenode HA state.
#su - hdfs
$hdfs zkfc -formatZK (如果不formatzk,则zk启动后报错java.lang.RuntimeException:Mismatched address stored in ZK forNameNode)
7、Login Standby Namenode and reset Namenode HA state.
#su - hdfs
$hdfs zkfc -formatZK (如果不formatzk,则zk启动后报错java.lang.RuntimeException:Mismatched address stored in ZK forNameNode)
8、Start Active Namenode ZKFC controller.
9、Start Standby Namenode ZKFC controller.
10、Rolling restart the Datanodes.
Note: Please check, Nodemanager should not be installed in Namenode box because it uses same port 8040. If installed then you need to change service RPC port from 8040 to different port.
2.2、调整RPC Handler Count
The Hadoop RPC server consists of a single RPC queue per port and multiple handler (worker) threads that dequeue and process requests. If the number of handlers is insufficient, then the RPC queue starts building up and eventually overflows. You may start seeing task failures and eventually job failures and unhappy users.
建议将RPC handler count设置为20 log2(Cluster Size),上限为200。
例如,对于250个节点的群集,应将其初始化为20 log2(250)=160。RPC处理程序计数可以在hdfs-site.xml中使用以下设置进行配置。
dfs.namenode.handler.count=160
2.3、启用DataNode Lifeline Protocol
https://issues.apache.org/jira/browse/HDFS-9239
https://www.qedev.com/bigdata/57302.html
在HDFS中,我们都知道DataNode是通过定期发送心跳信息到NameNode,以此证明自己还“活着”。当然心跳信息发送的另一项作用是发送自身的块报告信息给NameNode,以此保证集群数据的更新。然后NameNode会反馈给各DataNode一个回复命令。从这里看出,心跳在这里的所执行的操作还是比较“重”的。所以这里会引发出一个问题,一方面DataNode需要及时将自身的块信息报告给NameNode,另一方面,DataNode又要等待NameNode的心跳返回命令,换句话说,如果NameNode当前处理忙碌状态,处理心跳的速度异常地缓慢,那么就有可能造成DataNode下次心跳发送的延时,最糟糕的结果就是被认定为了dead node。所以在这里,我们应该要将心跳的“存活”检查功能从当前逻辑中剥离开来,从而达到一个轻量级的DataNode的生命检查
The Lifeline protocol is a feature recently added by the Apache Hadoop Community (see Apache HDFS Jira HDFS-9239). It introduces a new lightweight RPC message that is used by the DataNodes to report their health to the NameNode. It was developed in response to problems seen in some overloaded clusters where the NameNode was too busy to process heartbeats and spuriously marked DataNodes as dead.
1、hdfs-site.xml 添加:
dfs.namenode.lifeline.rpc-address.mycluster.nn1=mynamenode1.example.com:8050
dfs.namenode.lifeline.rpc-address.mycluster.nn2=mynamenode2.example.com:8050
2、滚动重启HDFS
2.4、启用RPC Congestion Control
警告: 必须首先启用服务RPC端口并重新启动服务,以便服务RPC设置有效。否则将中断DataNode-NameNode通信。__
RPC拥塞控制是Apache Hadoop社区添加的一个相对较新的功能,可帮助Hadoop服务在高负载下更可预测地响应(请参阅Apache Hadoop Jira HADOOP-10597)
如果NameNode在其RPC队列已满时向客户端发送显式信号,则可以缓解此问题。客户端没有等待可能永远不会完成的请求,而是通过以指数级增加的延迟重新提交请求来限制自身
core-site.xml添加:
ipc.8020.backoff.enable=true
2.5、启用RPC FairCallQueue
警告: 必须首先启用服务RPC端口并重新启动服务,以便服务RPC设置有效。否则将中断DataNode-NameNode通信。__
RPC FairCallQueue用多个优先级队列替换单个RPC队列(请参阅Apache Hadoop Jira HADOOP-10282)。RPC服务器维护按用户分组的最近请求的历史记录。它将基于用户的历史记录将传入请求放入适当的队列中。RPC处理程序线程将以较高的可能性使优先级较高的队列中的请求出队。
FairCallQueue很好地补充了RPC拥塞控制,并且当您同时启用这两个功能时,效果最佳。
core-site.xml添加:
ipc.8020.callqueue.impl=org.apache.hadoop.ipc.FairCallQueue
3、方案测试
3.1、添加相关参数
hdfs-site.xml :
dfs.namenode.servicerpc-address.cluster84.nn1=host-10-1-236-82:8060
dfs.namenode.servicerpc-address.cluster84.nn2=host-10-1-236-83:8060
dfs.namenode.lifeline.rpc-address.cluster84.nn1=host-10-1-236-82:8050
dfs.namenode.lifeline.rpc-address.cluster84.nn2=host-10-1-236-83:8050
dfs.namenode.handler.count=10
dfs.namenode.service.handler.count=5
core-site.xml添加
ipc.8020.backoff.enable=true
ipc.8020.callqueue.impl=org.apache.hadoop.ipc.FairCallQueue
3.2、重启StandByNameNode
需要等待snn退出安全模式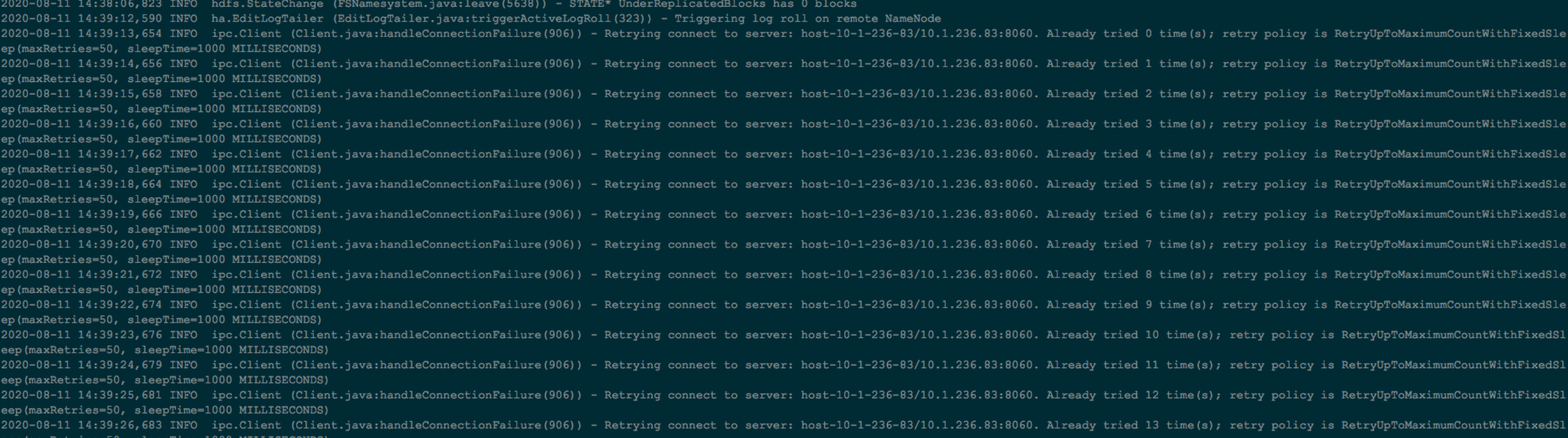


重启后会通过8060端口链接active nn,但是active nn此刻还未重启,报错为正常现象
3.3、重启ActiveNameNode

重启后,上面重启的nn变为active,而且报错消失,正常提供服务: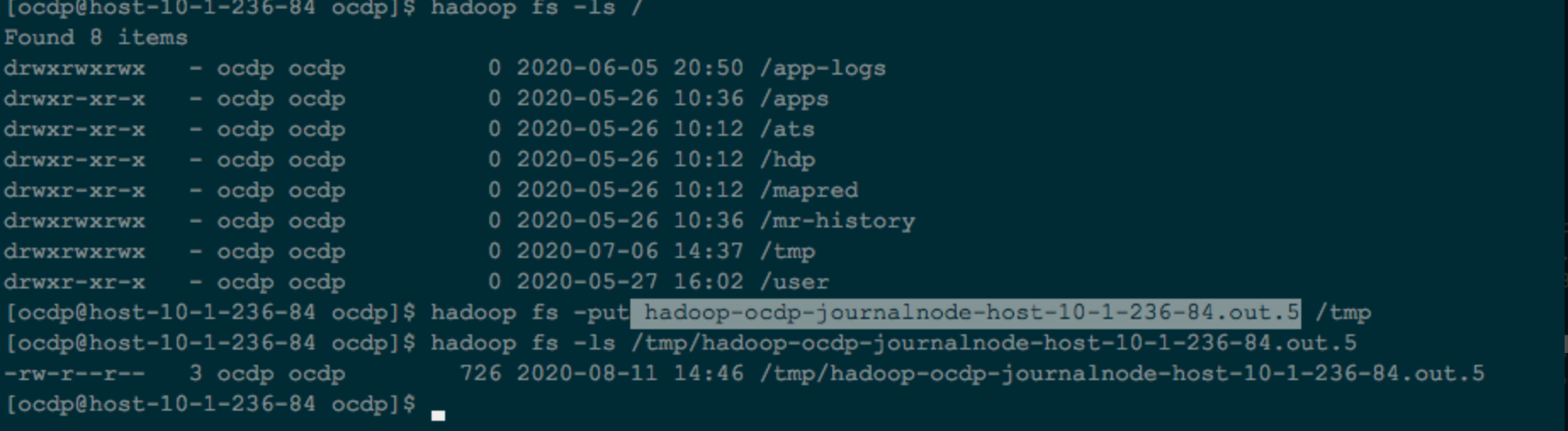


3.4、停止StandByNameNodeZKFC
3.5、停止ActiveNameNodeZKFC
3.6、FormatActiveNameNodeZKFC
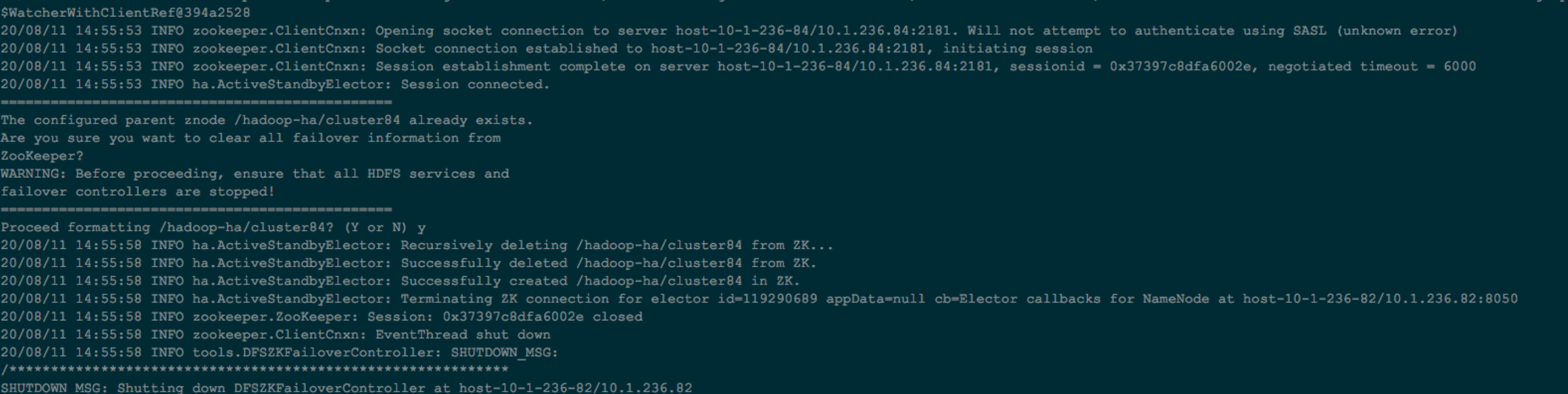
3.7、FormatStandByNameNodeZKFC
3.8、启动ActiveNamenodeZKFC
3.9、启动StandByNamenodeZKFC
3.10、Rolling Restart The Datanodes
3.11、重启其它受影响的
3.12、验证生效
namenode log:
zkfc log:
datanode log:
4、回退测试
关闭zkfc的自动重起
4.1、删除还原添加的参数
删除如下属性:
hdfs-site.xml :
dfs.namenode.servicerpc-address.cluster84.nn1=host-10-1-236-82:8060
dfs.namenode.servicerpc-address.cluster84.nn2=host-10-1-236-83:8060
dfs.namenode.lifeline.rpc-address.cluster84.nn1=host-10-1-236-82:8050
dfs.namenode.lifeline.rpc-address.cluster84.nn2=host-10-1-236-83:8050
dfs.namenode.service.handler.count=5
core-site.xml添加
ipc.8020.backoff.enable=true
ipc.8020.callqueue.impl=org.apache.hadoop.ipc.FairCallQueue
还原如下属性:
dfs.namenode.handler.count=10
4.2、Rolling Restart The Datanodes
rolling重启一下datanode,重启后,此刻业务可以正常使用,跑任务没有问题。datanode通过8020和nn进行通信
4.3、停止StandByNameNodeZKFC
4.4、停止ActiveNameNodeZKFC
4.5、FormatActiveNameNodeZKFC
4.6、FormatStandByNameNodeZKFC
4.7、启动ActiveNamenodeZKFC
4.8、启动StandByNamenodeZKFC
4.9、重启StandByNameNode
4.10、重启ActiveNameNode
4.11、重启其它受影响的
4.12、验证生效

若有收获,就点个赞吧
0 人点赞
