注:如果只是简单的功能改进测试项,只需要进行一下详细的功能描述即可。
如果需要进行测试的,功能实现部分需要有详细的测试步骤和截图。
1. 查询日志
功能描述:
新添加了系统表“SYSTEM.LOG”,存储有关针对集群运行的查询的信息(客户端驱动)。
功能实现:
通过新增系统表SYSTEM.LOG,保存了通过客户端驱动进行的查询信息。
之前版本: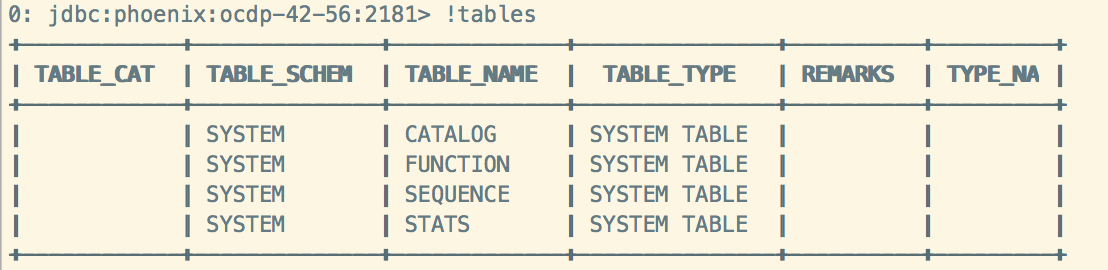
现在版本: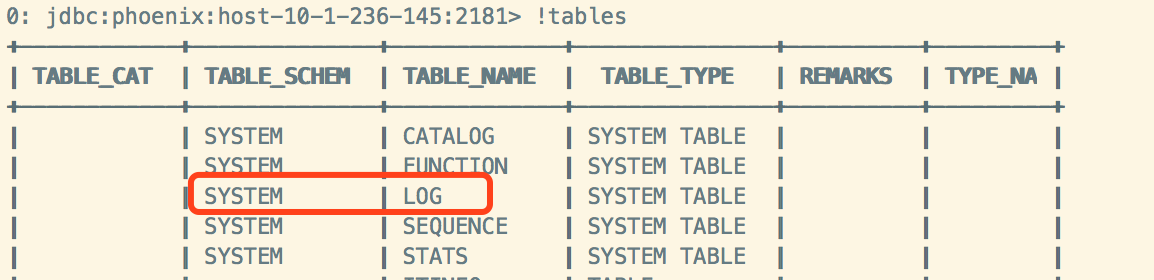
遇到问题:
2.列编码
功能描述:
对immutable 类型的表,storage scheme有ONE_CELL_PER_COLUMN和SINGLE_CELL_ARRAY_WITH_OFFSETS,使用SINGLE_CELL_ARRAY_WITH_OFFSETS的不可变存储方案将属于列族的列打包在单个单元中。从而大大减少了不可变数据的大小,数据变小了,从而性能也得到了提升。
重要的是要注意,只有在使用其中一个编号列映射方案时才能使用此编码。这是因为内部编码依赖于这些基于数字的列限定符来查找列的值,即SINGLE_CELL_ARRAY_WITH_OFFSETS与COLUMN_ENCODED_BYTES一起使用,
使用SINGLE_CELL_ARRAY_WITH_OFFSETS与COLUMN_ENCODED_BYTES = NONE时会引发错误
使用ONE_CELL_PER_COLUMN和SINGLE_CELL_ARRAY_WITH_OFFSETS怎么选择呢,如下情况需使用ONE_CELL_PER_COLUMN,其它情况可使用SINGLE_CELL_ARRAY_WITH_OFFSETS
1、数据稀疏,即少于50%的列具有值
2、列族中的数据大小太大。我们的一般指导是,默认HBase块大小为64K,如果列族中的数据增长超过50K,那么我们不应该使用SINGLE_CELL_ARRAY_WITH_OFFSETS。
3、For immutable tables that are going to have views on them
附:列映射配置属性及对应的值(默认为2,可在hbase-site.xml中通过phoenix.default.column.encoded.bytes.attrib设置):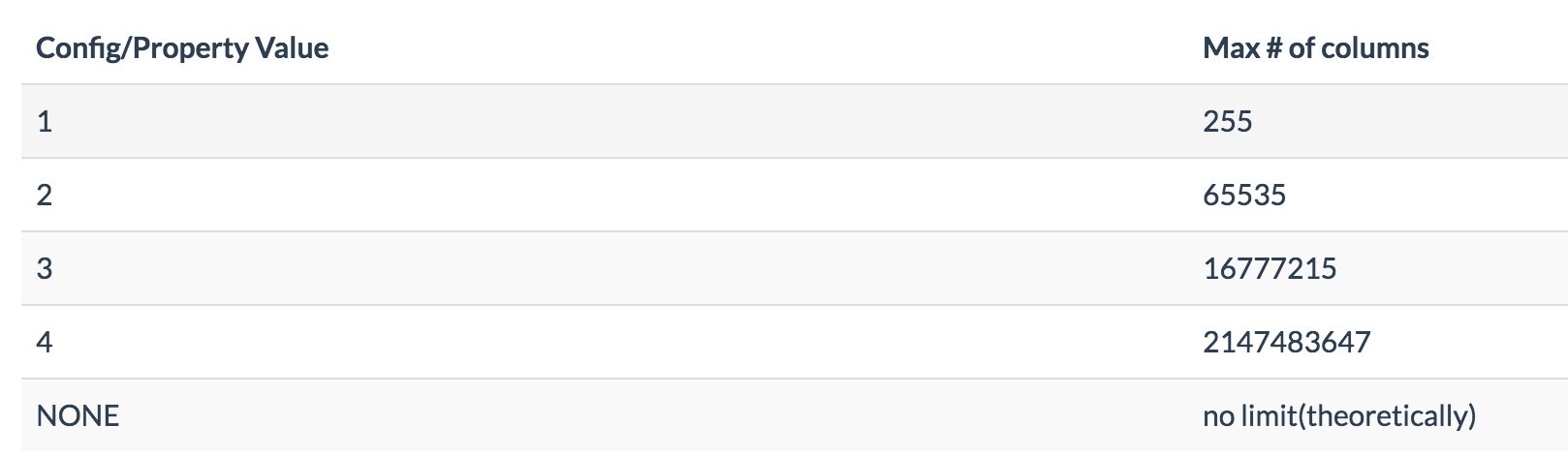
功能实现:
在创建表的时候通过关键字IMMUTABLE_STORAGE_SCHEME指定:
CREATE IMMUTABLE TABLE T
(
a_string varchar not null,
col1 integer
CONSTRAINT pk PRIMARY KEY (a_string)
)
IMMUTABLE_STORAGE_SCHEME = SINGLE_CELL_ARRAY_WITH_OFFSETS,
COLUMN_ENCODED_BYTES = 1;
CREATE IMMUTABLE TABLE T
(
a_string varchar not null,
col1 integer
CONSTRAINT pk PRIMARY KEY (a_string)
)
IMMUTABLE_STORAGE_SCHEME = ONE_CELL_PER_COLUMN,
COLUMN_ENCODED_BYTES = 1;
创建两个表:
create table TEST(id varchar primary key);
CREATE IMMUTABLE TABLE TEST1
(
id varchar CONSTRAINT pk PRIMARY KEY (id)
)
IMMUTABLE_STORAGE_SCHEME = SINGLE_CELL_ARRAY_WITH_OFFSETS,
COLUMN_ENCODED_BYTES = 1;
导入数据:
python psql.py -t TEST1 localhost /home/1.csv
python psql.py -t TEST localhost /home/1.csv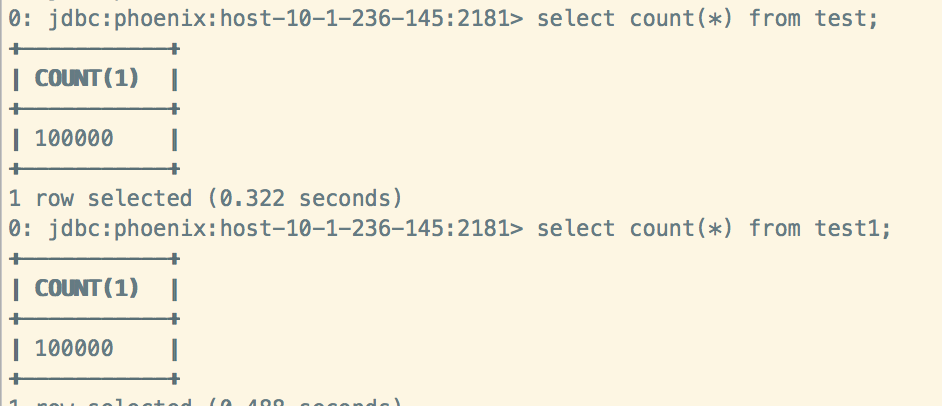
查询磁盘占用:
遇到问题:
3.支持GRANT和REVOKE命令
功能描述:
功能实现:
在表,schema或用户级别授予/撤销权限。权限由HBasehbase:acl表管理,因此需要启用HBASE访问控制。此功能将从Phoenix 4.14版本开始提供。
可能的权限是R - 读取,W - 写入,X - 执行,C - 创建和A - 管理员。要启用/禁用访问控制,请参阅https://hbase.apache.org/book.html#hbase.accesscontrol.configuration
在基表上授予权限将会传播到其所有索引和视图。组权限适用于组中的所有用户,schema权限适用于具有该schema的所有表。没有指定表/schema的授权语句在GLOBAL级别分配。
注意:
每个用户都需要RX所有Phoenix SYSTEM表的权限才能正常工作。用户还需要表RWX上的权限SYSTEM.SEQUENCE才能使用SEQUENCES。
如下测试是在HBASE开启ACL的条件下,HBASE开启ACL:
例1创建表权限:
从hbase中查看用户raoyi权限:
user_permission
用户raoyi登陆phoenix创建表:
create table TEST1(id varchar primary key,name varchar,age integer);
使用管理员用户ocdc登陆phoenix给raoyi用户赋权,并在hbase中查看raoyi的权限:
GRANT ‘RWXC’ TO ‘raoyi’;

然后用户raoyi登陆phoenix创建表成功:
Phoenix ocdc回收用户raoyi的权限:
REVOKE FROM ‘raoyi’;


例2读取表权限:
Phoenix ocdc创建表:
create table TEST_OCDC(id varchar primary key,name varchar,age integer);
查看用户raoyi没有权限
Raoyi phoenix查看ocdc创建的表失败:
select from TEST_OCDC;
Ocdc phoenix给raoyi查看表的赋权:
GRANT ‘R’ ON TEST_OCDC to ‘raoyi’;
user_permission ‘TEST_OCDC’
Raoyi phoenix 查询:
select from TEST_OCDC;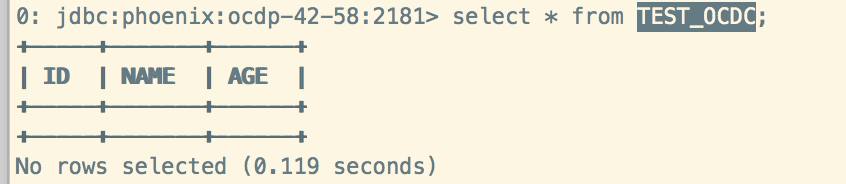
例3删除表权限:
在例2的场景下,删除表失败
虽然报错,但是在phoenix查看表已经被删除,在hbase查看表还在: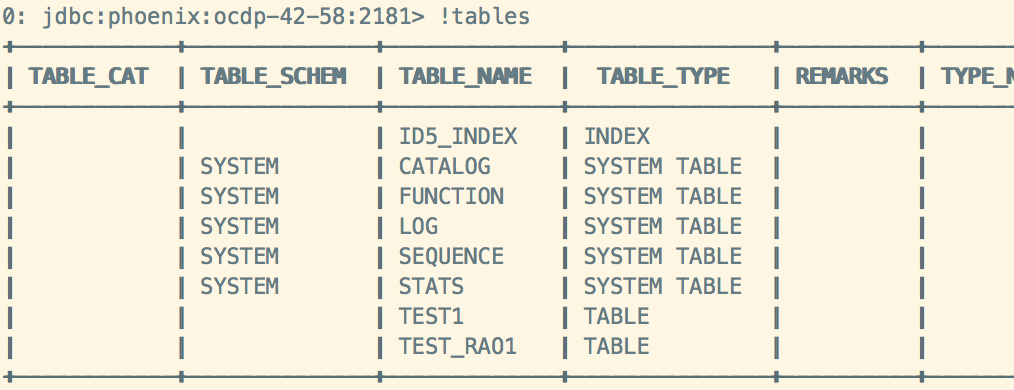
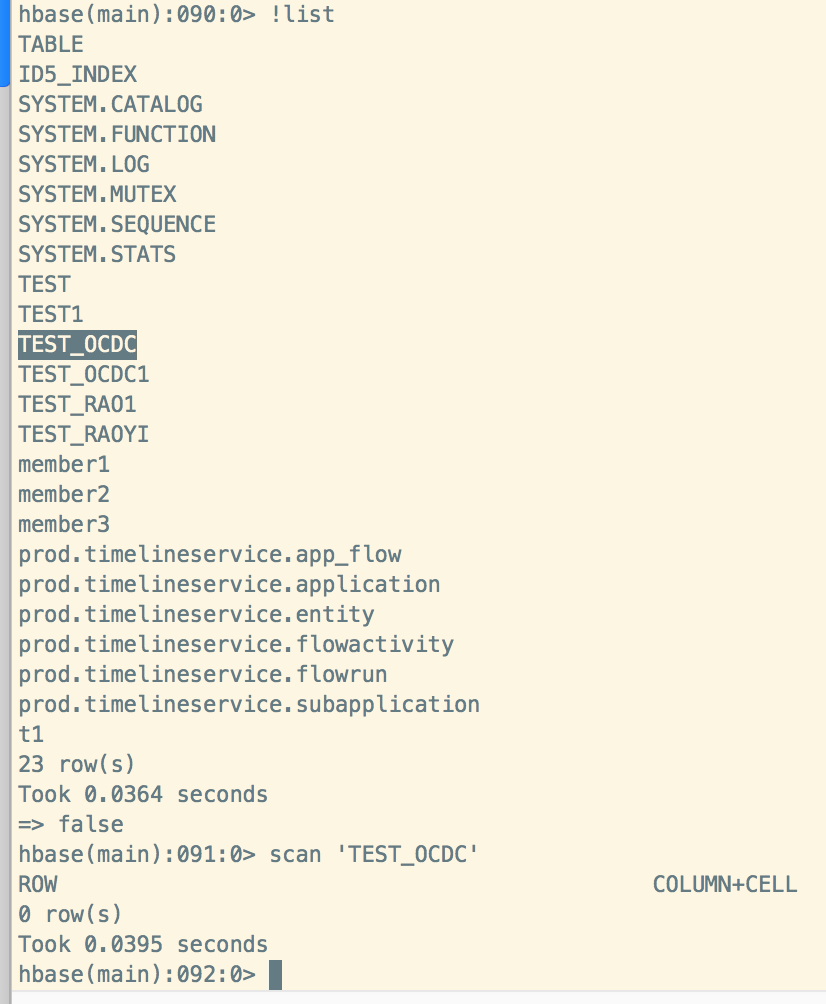
之前版本:
现在版本:
遇到问题:
4.支持抽样表
功能描述:
功能实现:
为了支持表采样,从Phoenix 4.12开始,TABLESAMPLE子句已被加载到 table aliases ref中。
在执行时,给定采样率,它利用Phoenix的统计数据以及HBase的region分布来执行表采样。
例如,要对表进行表格采样,您将执行以下命令。请注意,采样率是介于0和100之间的数值。
表记录数为:10000000,给定采样率12.08,将会从中抽取1113189条记录。
select count(*) from TEST_RAO TABLESAMPLE(12.08);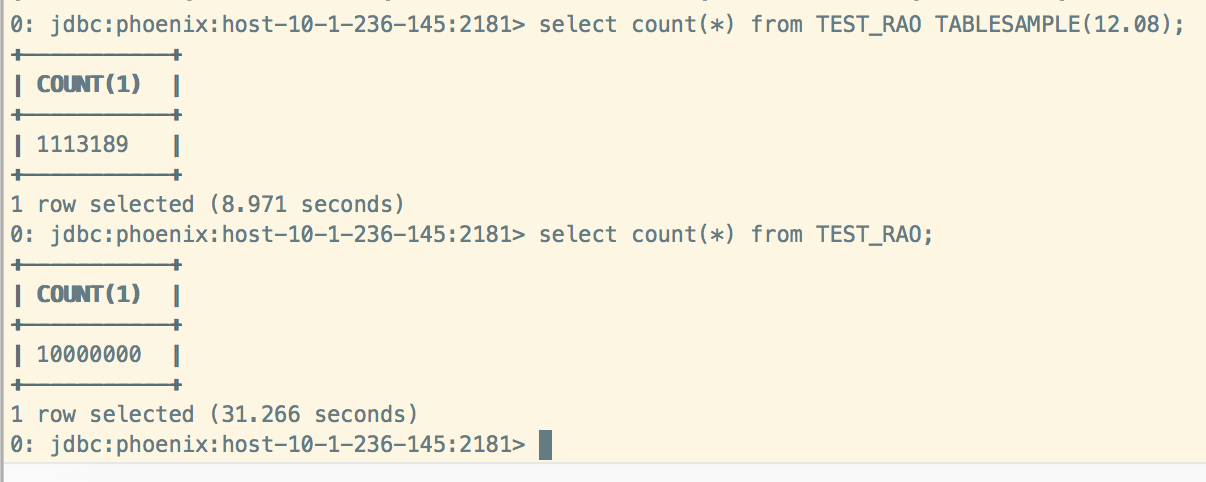
老版本不支持: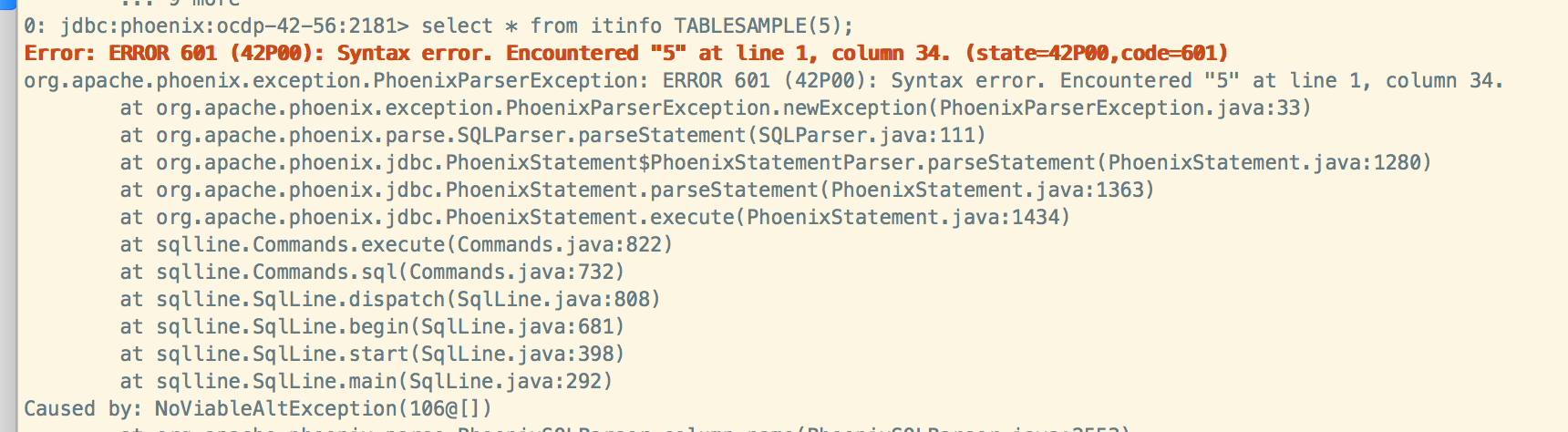
遇到问题:
5.支持原子更新(ON DUPLICATE KEY)
功能描述:
在更新数据时,当存在某个记录时,执行这条语句会更新它,而不存在这条记录时,会插入它
功能实现:
通过使用ON DUPLICATE KEY命令实现,在使用ON DUPLICATE KEY子句时正在更新的行将被锁定,同时读取当前列值并执行ON DUPLICATE KEY子句,将会有性能损失,在存在ON DUPLICATE KEY子句的情况下,如果该行已存在,则将忽略指定的VALUES,而是进行下面的处理逻辑,如果该行不存在,则插入数据:
1、如果指定了ON DUPLICATE KEY IGNORE,则不会更新该行
2、通过执行ON DUPLICATE KEY UPDATE子句后面的表达式,将更新行(处于锁定状态)
举例:
1、更新389的行,将age值加一(由于存在389的行,所以执行ON DUPLICATE KEY UPDATE子句后面的表达式,将age值加一,忽略了values的值”rao”,”0”)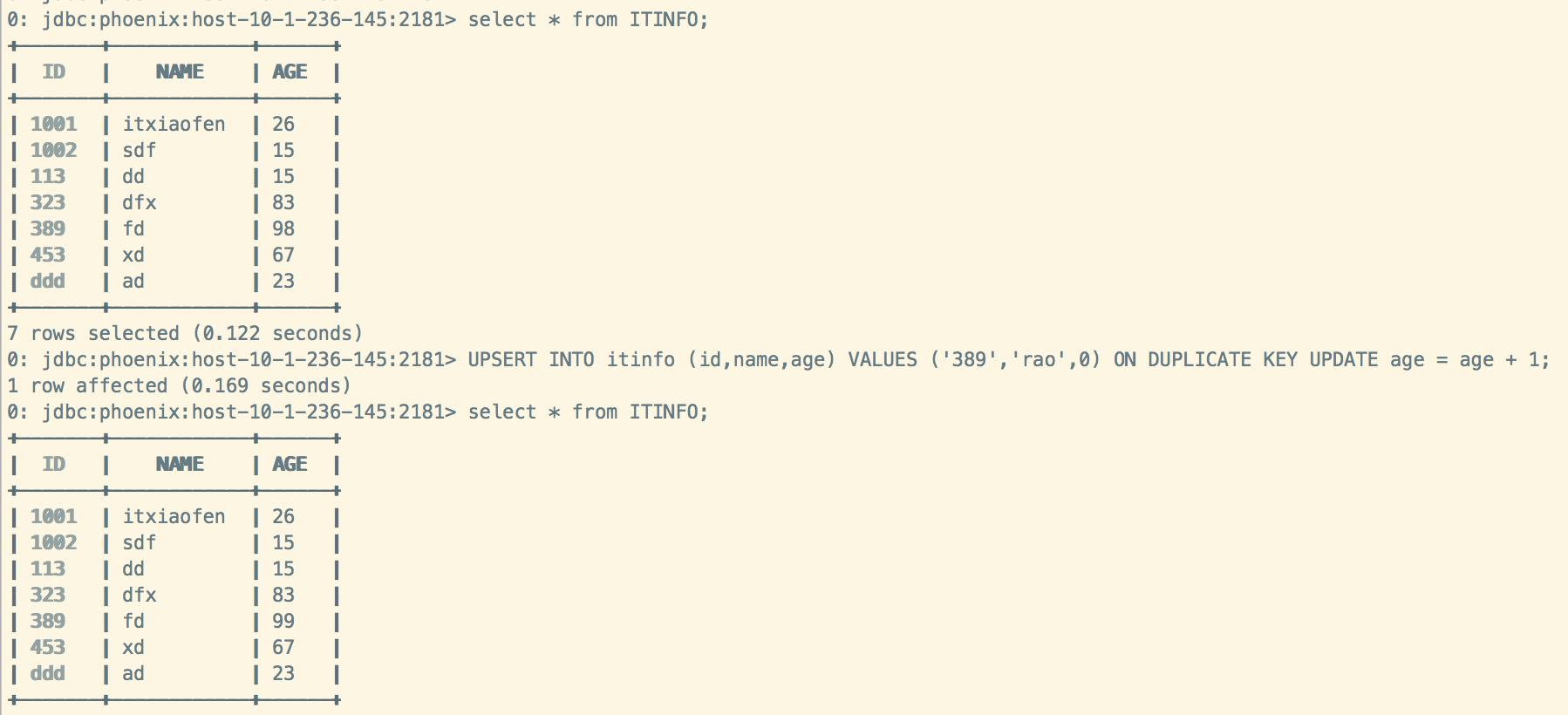
2、插入不存在的值,则直接插入value的值,忽略ON DUPLICATE KEY UPDATE子句后面的表达式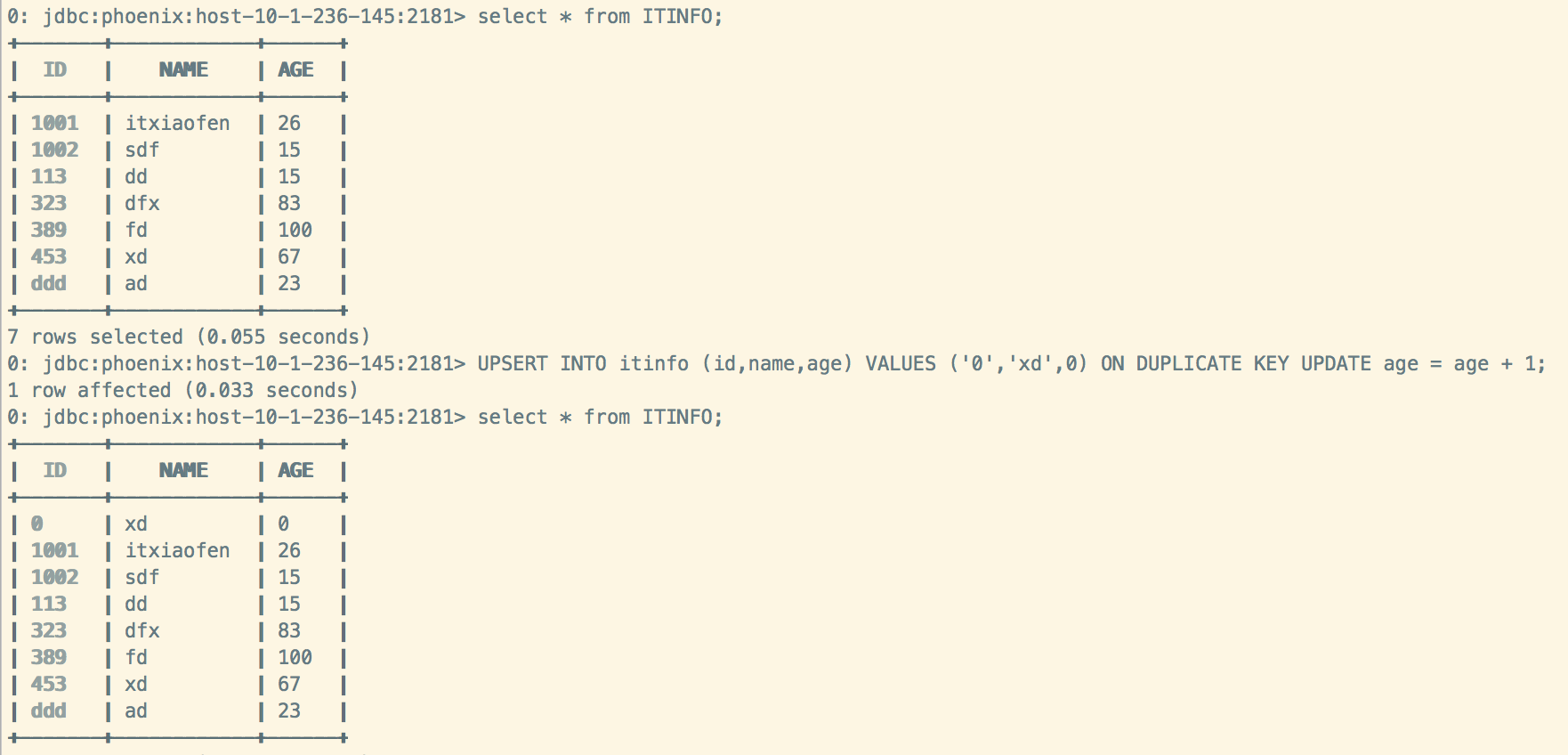
3、指定ON DUPLICATE KEY IGNORE,则不会更新该行
遇到问题:
6.支持基于MR的查询的快照扫描程序
功能描述:
https://issues.apache.org/jira/browse/PHOENIX-3744
https://www.jianshu.com/p/5411bfb4abd6
功能实现:
遇到问题:
7.Hive 3.0支持Phoenix
功能描述:
支持从Hive访问Phoenix数据, 此集成更适合执行在线分析查询处理(OLAP)操作。
功能实现:
添加jar包/usr/hdp/current/phoenix-client/phoenix-5.0.0.3.0.0.0-1634-hive.jar
cp /usr/hdp/current/phoenix-client/phoenix-5.0.0.3.0.0.0-1634-hive.jar /usr/hdp/current/hive-server2/lib
hive-site.xml里配置hive.aux.jars.path属性
然后hive创建表的时候指定一些属性即可将表同时创建到phoenix中。
如:
create external table phoenix_table (
s1 string,
i1 int,
f1 float,
d1 double
)
STORED BY ‘org.apache.phoenix.hive.PhoenixStorageHandler’
TBLPROPERTIES (
“phoenix.table.name” = “phoenix_table”,
“phoenix.zookeeper.quorum” = “host-10-1-236-145”,
“phoenix.zookeeper.znode.parent” = “/hbase-unsecure”,
“phoenix.zookeeper.client.port” = “2181”,
“phoenix.rowkeys” = “s1, i1”,
“phoenix.column.mapping” = “s1:s1, i1:i1, f1:f1, d1:d1”,
“phoenix.table.options” = “SALT_BUCKETS=10, DATA_BLOCK_ENCODING=’DIFF’”
);
1. phoenix.table.name
o Specifies the Phoenix table name
o Default: the same as the Hive table
2. phoenix.zookeeper.quorum
o Specifies the ZooKeeper quorum for HBase
o Default: localhost
3. phoenix.zookeeper.znode.parent
o Specifies the ZooKeeper parent node for HBase
o Default: /hbase
4. phoenix.zookeeper.client.port
o Specifies the ZooKeeper port
o Default: 2181
5. phoenix.rowkeys
o The list of columns to be the primary key in a Phoenix table
o Required
6. phoenix.column.mapping
o Mappings between column names for Hive and Phoenix. See Limitations for details.
测试:
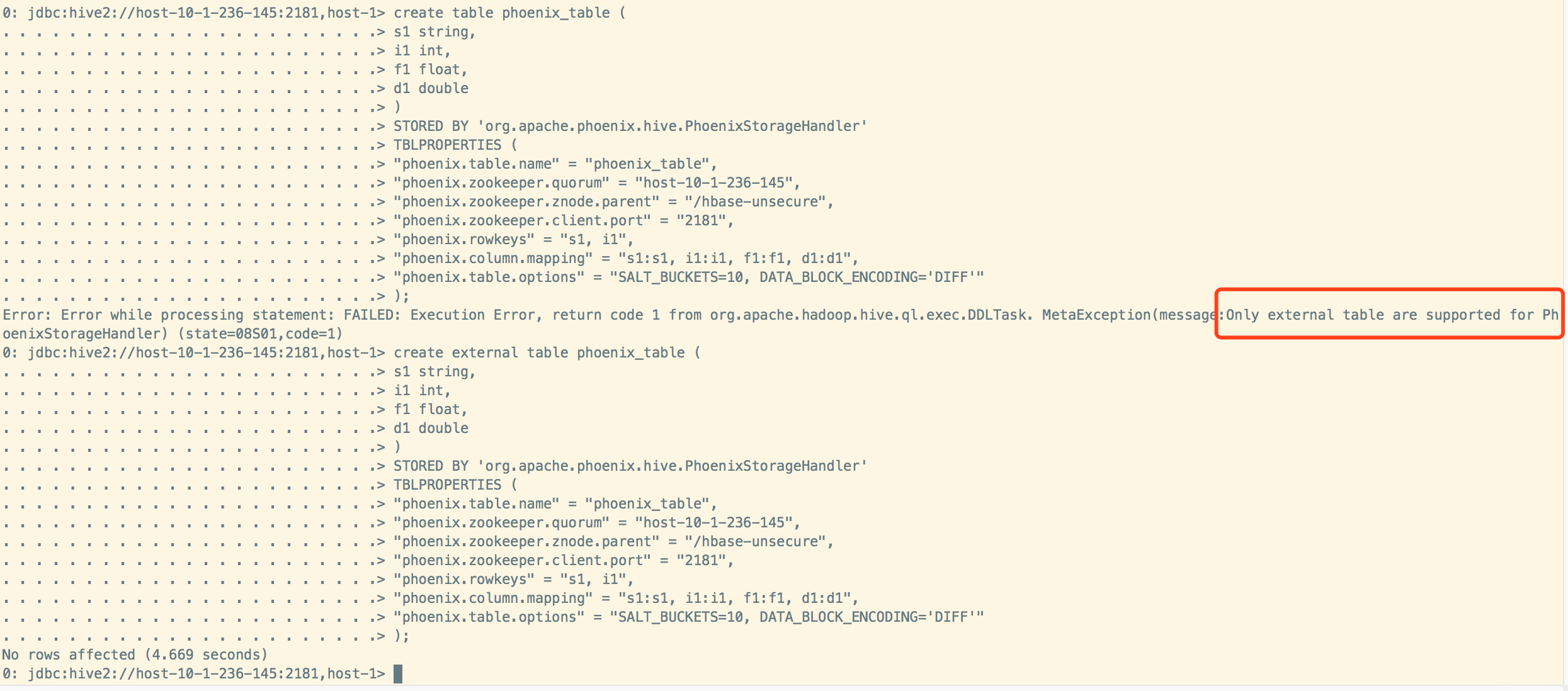
打开hive ,创建表,测试只支持外部表:
create external table phoenix_table (
s1 string,
i1 int,
f1 float,
d1 double
)
STORED BY ‘org.apache.phoenix.hive.PhoenixStorageHandler’
TBLPROPERTIES (
“phoenix.table.name” = “phoenix_table”,
“phoenix.zookeeper.quorum” = “host-10-1-236-145”,
“phoenix.zookeeper.znode.parent” = “/hbase-unsecure”,
“phoenix.zookeeper.client.port” = “2181”,
“phoenix.rowkeys” = “s1, i1”,
“phoenix.column.mapping” = “s1:s1, i1:i1, f1:f1, d1:d1”,
“phoenix.table.options” = “SALT_BUCKETS=10, DATA_BLOCK_ENCODING=’DIFF’”
);
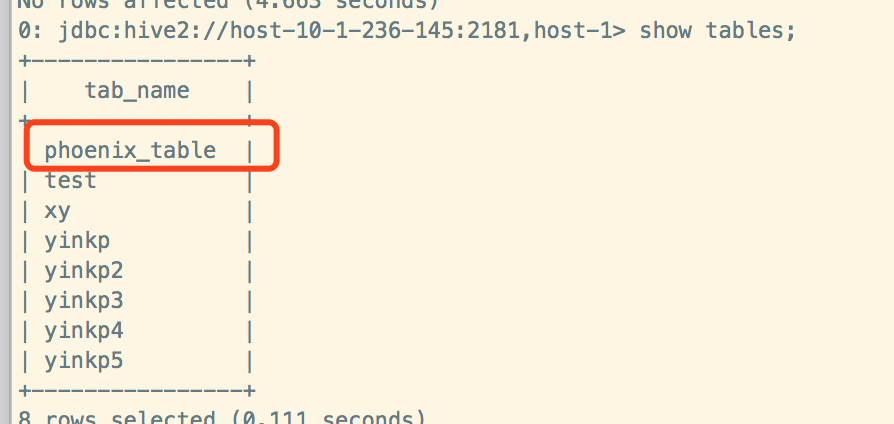
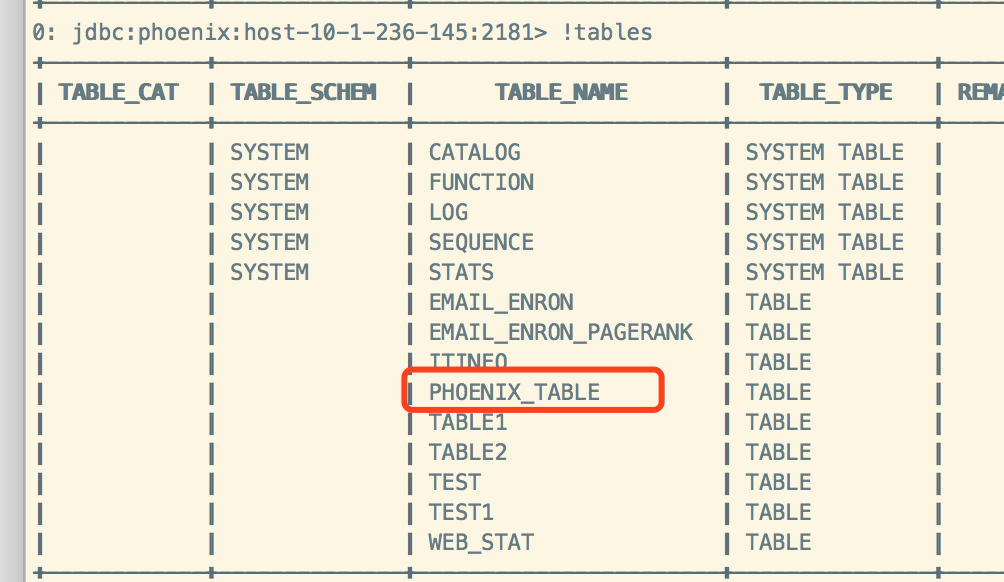
Hive插入数据: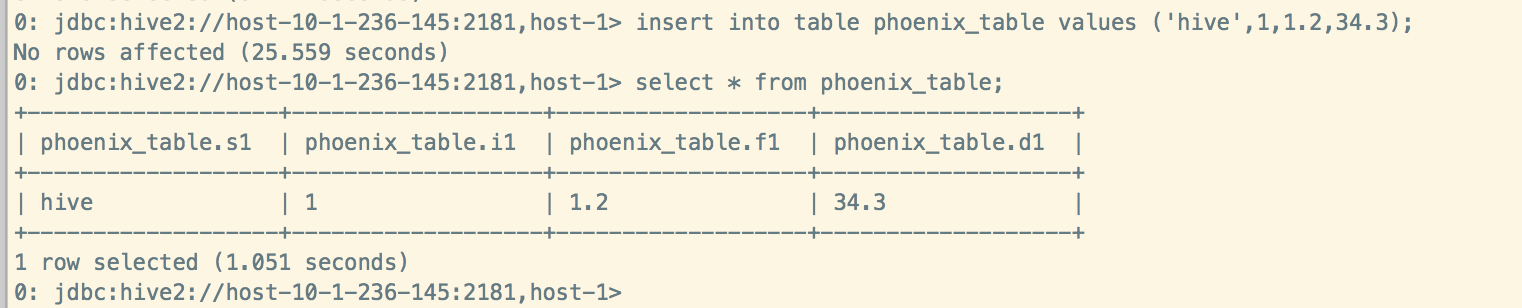
Phoenix查看数据: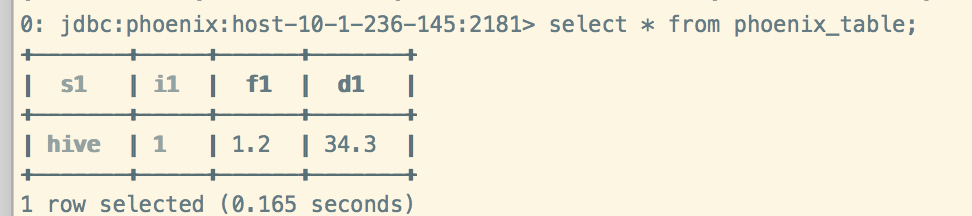
Phoenix插入数据: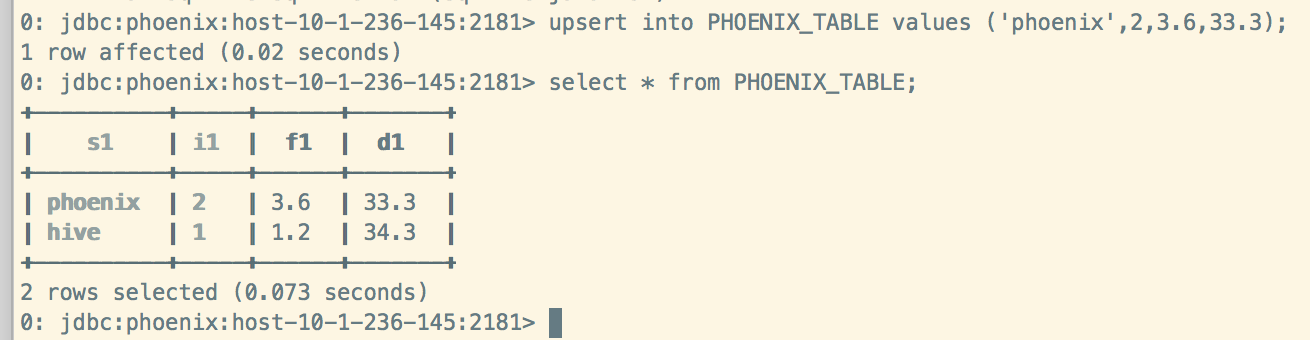
Hive查看数据: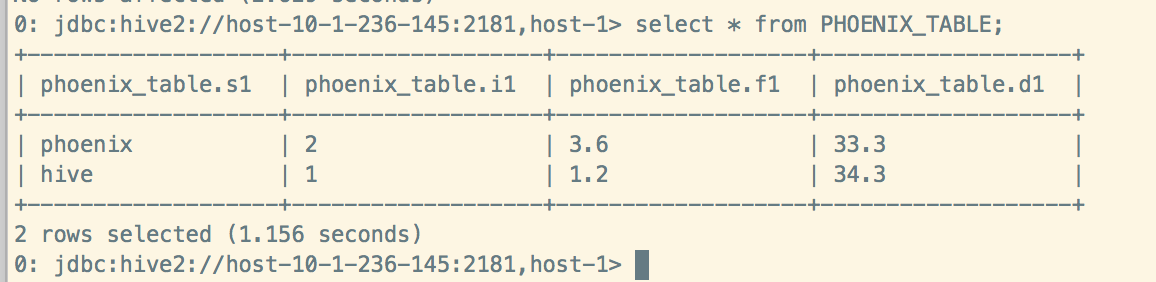
所有删除和更新操作都应在Phoenix端执行,hive端不能执行。
Hive 删除数据:
Phoenix删除数据: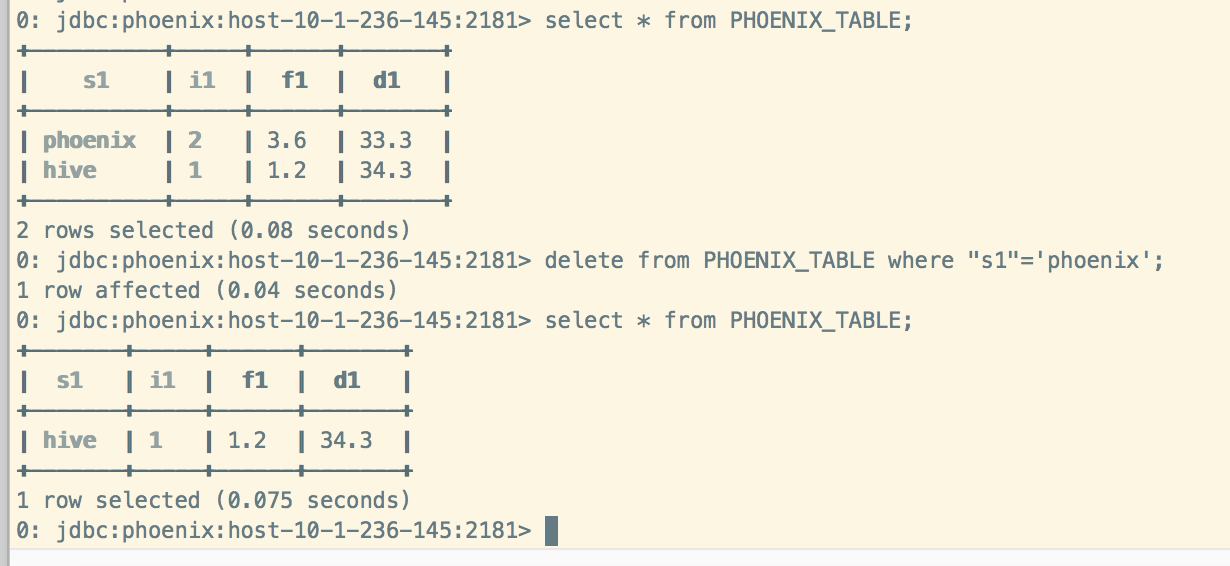
Hive同步删除: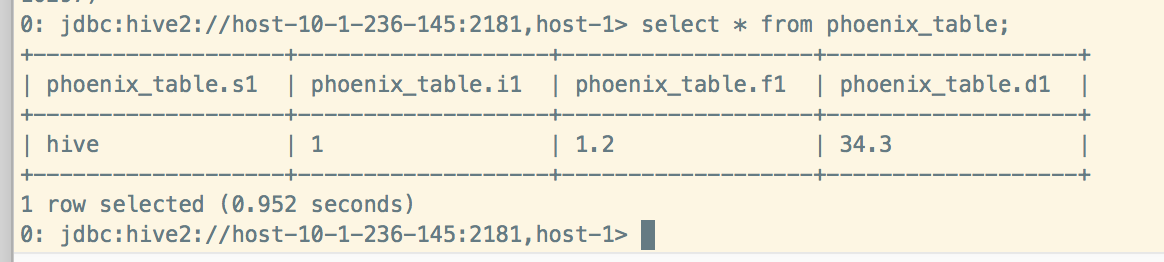
Hive删除表: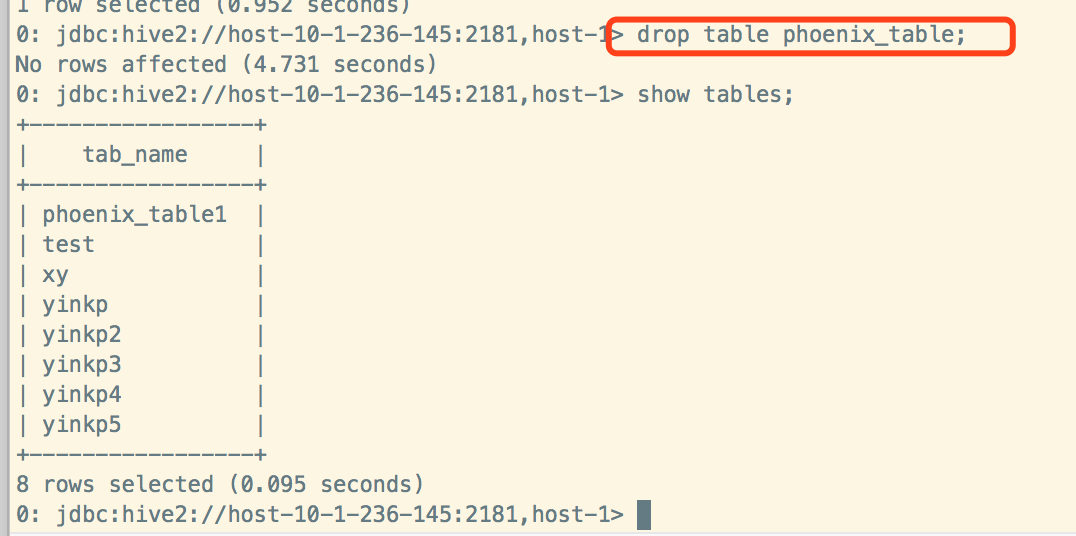
Phoenix同步删除: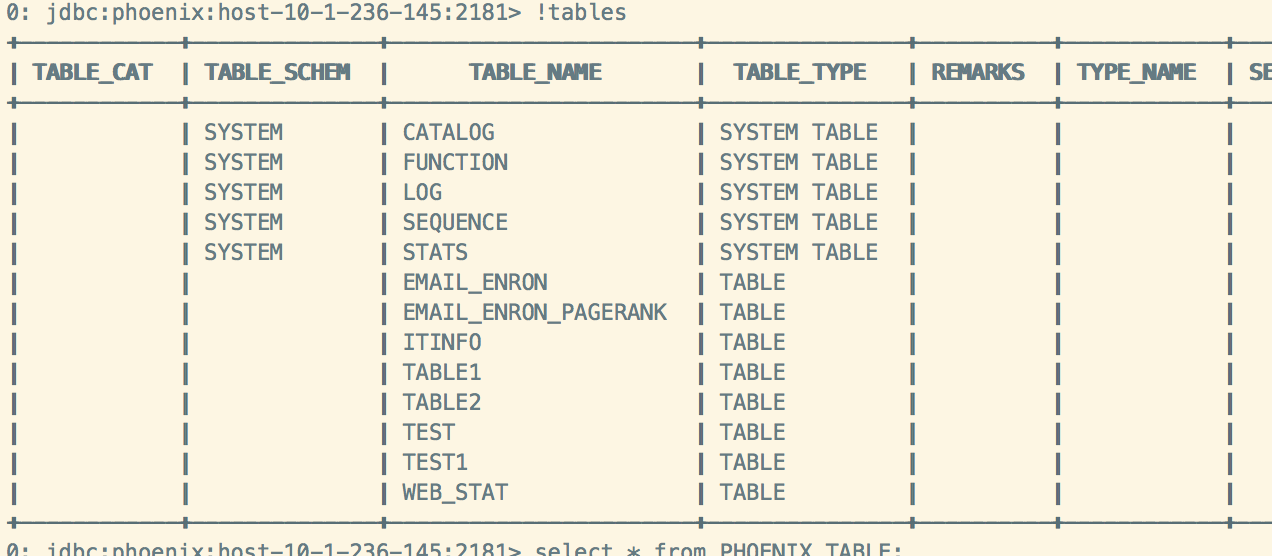
Phoenix删除表:
Hive端查看表存在,但是无法查询,元数据被删掉:
遇到问题:
1、创建表,测试只支持外部表,phoenix说明是能支持内部表的。
2、Phoenix删除表,Hive端查看表存在,但是无法查询表数据。
8.Spark 2.3支持Phoenix
功能描述:
功能实现:
在spark-defaults.conf文件中配置’spark.executor.extraClassPath’和 ‘spark.driver.extraClassPath’以包含 ‘phoenix- 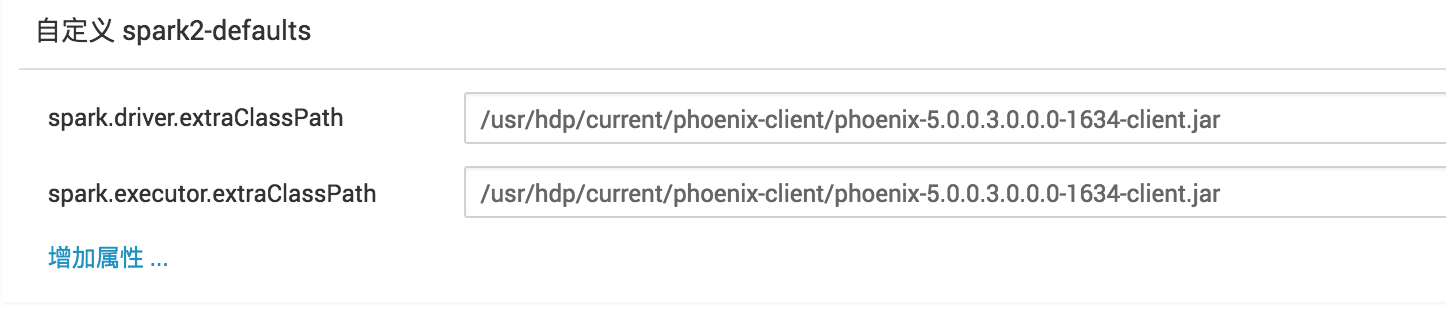
测试:
1、在phoenix中创建Phoenix 表
CREATE TABLE EMAILENRON(MAIL_FROM BIGINT NOT NULL, MAIL_TO BIGINT NOT NULL CONSTRAINT pk PRIMARY KEY(MAIL_FROM, MAIL_TO));
CREATE TABLE EMAIL_ENRON_PAGERANK(ID BIGINT NOT NULL, RANK DOUBLE CONSTRAINT pk PRIMARY KEY(ID));
2、导入数据到EMAIL_ENRON:
./psql.py -t EMAIL_ENRON localhost /tmp/enron.csv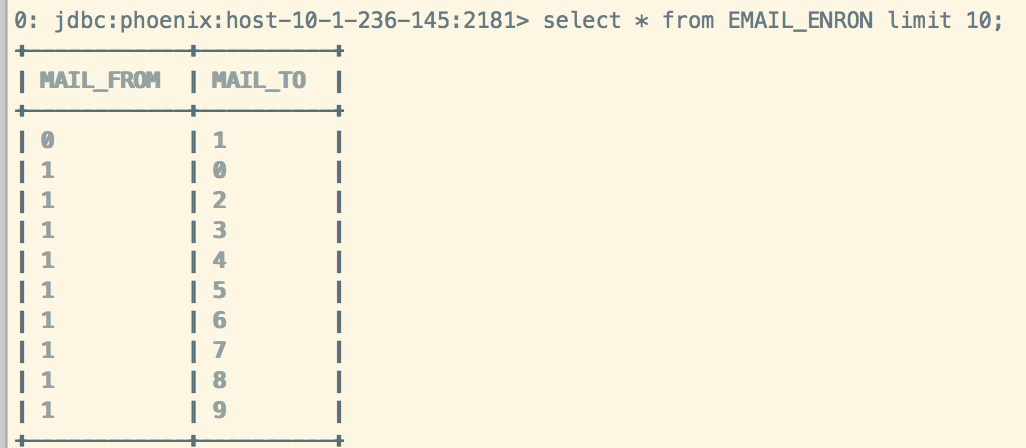
3、打开spark-shell,输入代码:
import org.apache.spark.graphx.
import org.apache.phoenix.spark._
val rdd = sc.phoenixTableAsRDD(“EMAIL_ENRON”, Seq(“MAIL_FROM”, “MAIL_TO”), zkUrl=Some(“localhost”)) // load from phoenix
val rawEdges = rdd.map{ e => (e(“MAIL_FROM”).asInstanceOf[VertexId], e(“MAIL_TO”).asInstanceOf[VertexId]) } // map to vertexids
val graph = Graph.fromEdgeTuples(rawEdges, 1.0) // create a graph
val pr = graph.pageRank(0.001) // run pagerank
pr.vertices.saveToPhoenix(“EMAIL_ENRON_PAGERANK”, Seq(“ID”, “RANK”), zkUrl = Some(“localhost”)) // save to phoenix
4、在phoenix中查看EMAIL_ENRON_PAGERANK表,已经填充上数据。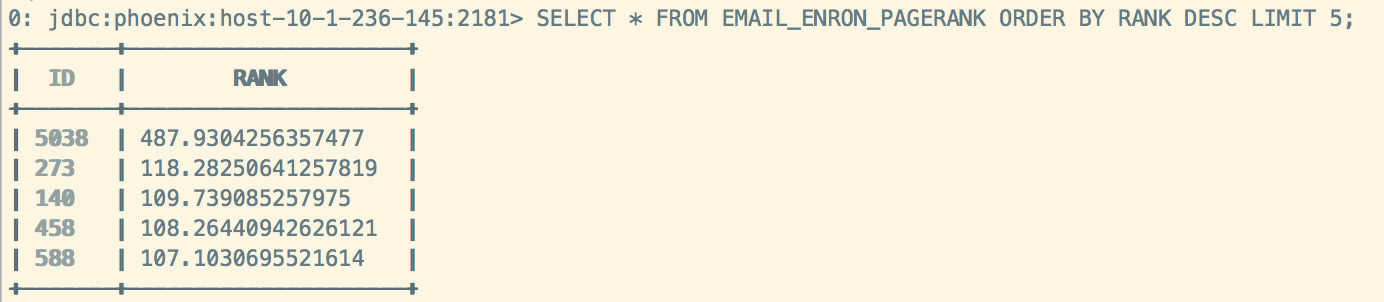
遇到问题:
9.加强包括Local和Global的二级索引
功能描述:
对于HBase而言,如果想精确地定位到某行记录,唯一的办法是通过rowkey来查询。如果不通过rowkey来查找数据,就必须逐行地比较每一列的值,即全表扫瞄。对于较大的表,全表扫瞄的代价是比较大的。
HBase只提供了一个基于字典排序的主键索引,在查询中你只能通过行键查询或扫描全表来获取数据,使用Phoenix提供的二级索引,可以避免在查询数据时全表扫描,提高查过性能,提升查询效率
功能实现:
通过ambari界面设置参数
hbase.regionserver.wal.codec:
org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
hbase.region.server.rpc.scheduler.factory.class:
org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory
hbase.rpc.controllerfactory.class:
org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory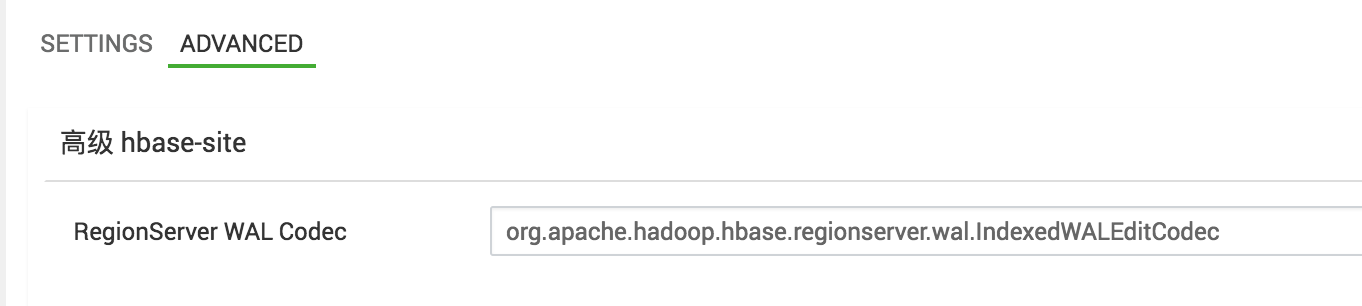

Covered Indexes:
在某次查询中,查询项或者查询条件中包含索引列之外的列(主键除外),该查询会触发全表扫描,使用covered index则可以避免全表扫描。 
使用Covered Indexes后: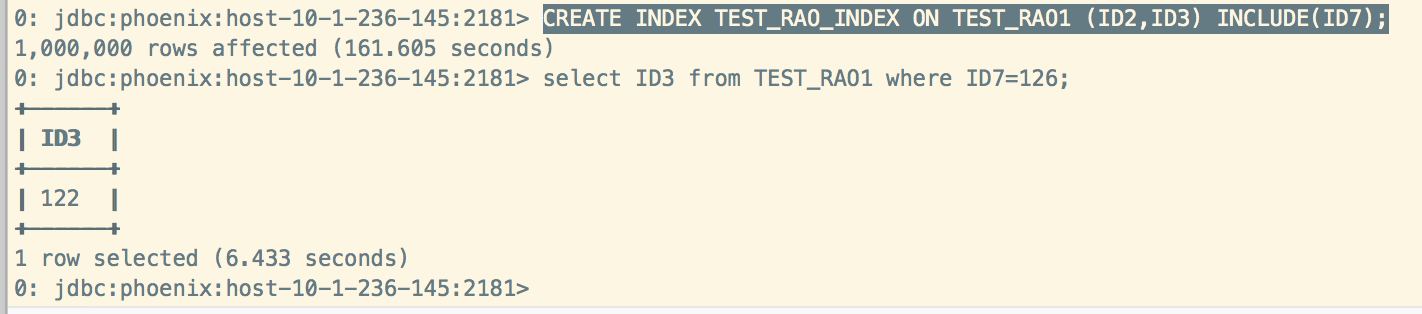
Functional Indexes:
不仅可在列上创建索引,而且可在任意表达式上创建索引.
create index index_upper1 on TEST_RAO2 (UPPER(ID8));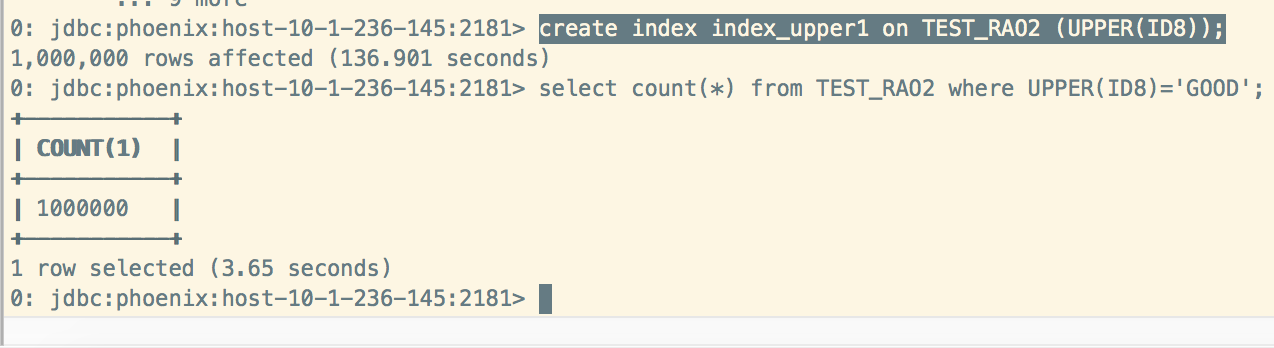
Global Indexes:
全局索引适用于多读写少的场景,在写操作上会给性能带来极大的开销,因为所有的更新和写操作(DELETE,UPSERT VALUES和UPSERT SELECT)都会引起索引的更新,在读数据时,Phoenix将通过索引表来达到快速查询的目的。如果想查询的字段不是索引字段的话索引表不会被使用。
创建全局索引:CREATE INDEX TEST_RAO_INDEX ON TEST_RAO1 (ID2);
Local Indexes:
本地索引适用于写多读少,空间有限的场景,使用本地索引,索引数据和表数据都存放在相同的服务器中,可避免进行写操作所带来的网络开销,当查询的字段不完全是索引字段时本地索引也会被使用,这点与全局索引不同。4.8.0版本之前,所有的本地索引都单独存储在同一张共享表中,从4.8.0之后,所有本地索引数据存储在同一数据表中的单独阴影列族中(storing all local index data in the separate shadow column families in the same data table),由于无法预先确定region的位置,所以在读取数据时会检查每个region上的数据因而带来一定性能开销。
Index Population:
默认情况下,创建索引时,会在CREATE INDEX调用期间完成索引表的填充。
从4.5开始,通过在索引创建DDL语句中包含ASYNC关键字,可以异步完成索引表的填充:
CREATE INDEX async_index ON my_schema.my_table(v)ASYNC
必须通过HBase命令行单独启动填充索引表的map reduce作业:
hbase org.apache.phoenix.mapreduce.index.IndexTool
—schema MY_SCHEMA —data-table MY_TABLE —index-table ASYNC_IDX
—output-path ASYNC_IDX_HFILES
只有当map reduce作业完成时,才能在查询中使用索引。output-path选项用于指定用于写入HFile的HDFS目录。

使用索引:
除非查询中引用的所有列都包含在索引中,否则不会使用索引。
SELECT ID3 FROM TEST_RAO1 WHERE ID7 = 126
如果ID7不再索引列中,不会索引
要想使用索引,则可做如下处理:
1、使用Covered Indexes
CREATE INDEX TEST_RAO_INDEX ON TEST_RAO1 (ID2,ID3) INCLUDE(ID7);
使用Covered Indexes后:
2、强制查询使用索引
select /+ INDEX(TEST_RAO1 my_index) / ID3 from TEST_RAO1 where ID7=126;
只有当用户明确知道符合检索条件的数据较少的时候才适合使用,否则会造成全表扫描,对性能影响较大。
3、使用本地索引
CREATE LOCAL INDEX LOCAL_INDEX ON TEST_RAO1 (ID6);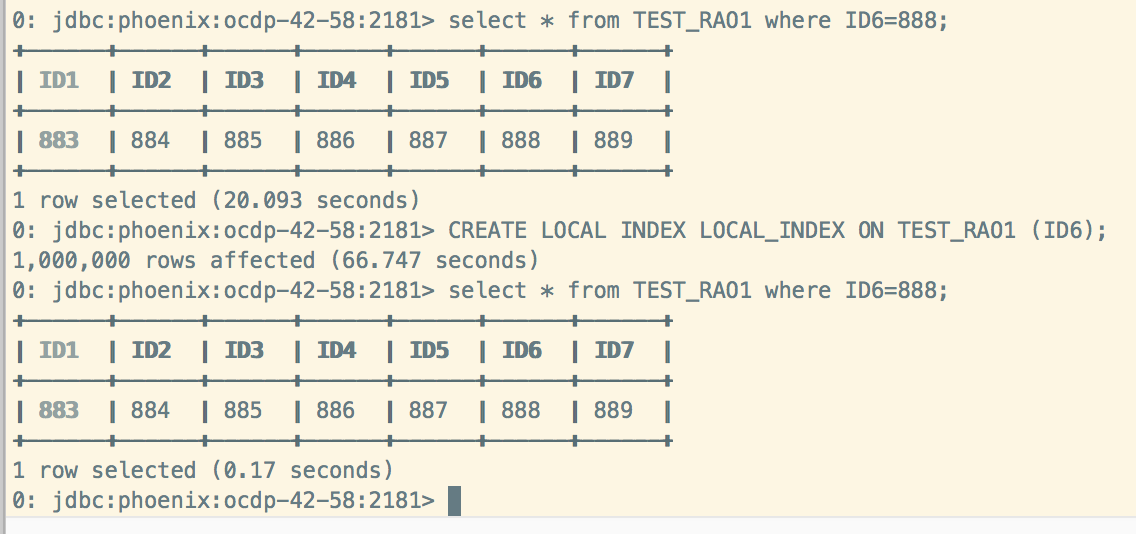
删除索引:
DROP INDEX TEST_RAO_INDEX ON TEST_RAO1;
如果在数据表中删除了索引列,则会自动删除索引。此外,如果在数据表中删除了一个覆盖索引列,它也将自动从索引中删除。
一致性保证
由于索引存储在与数据表不同的表中,因此根据表的属性和索引的类型,如果由于服务器端崩溃而导致提交失败,则表和索引之间的一致性会有所不同。通过如下方案保障数据的一致性:
Transactional Tables 事务表,目前属于beta
通过将表声明为事务性,您可以在表和索引之间实现最高级别的一致性保证,如果提交失败,则不会更新任何数据(表或索引),从而确保表和索引始终保持同步。如果表被声明为不可(immutable),这种情况下事务开销非常小。如果数据是可变的,需确保与事务表发生的冲突检测相关的开销和运行事务管理器的操作开销是可接受的,具有二级索引的事务表可能会降低能够写入数据表的可用性,因为数据表及其二级索引表必须可用,否则写入将失败。
Immutable Tables
适用于对其中数据仅写入一次且不需更新的表,
CREATE TABLE my_table(k VARCHAR PRIMARY KEY,v VARCHAR)IMMUTABLE_ROWS = true
使用IMMUTABLE_ROWS = true声明的表上的所有索引都被视为不可变,对于全局不可变索引,索引完全在客户端维护,索引表在数据表发生更改时生成,本地不可变索引在服务器端维护
从不可变索引表切换到可变索引表,使用ALTER TABLE命令:
ALTER TABLE my_table SET IMMUTABLE_ROWS = false
非事务性,不可变表的索引没有适当的机制来自动处理提交失败。保持表和索引之间的一致性留给客户端来处理。最简单的解决方案是让客户端继续重试一批突变数据,直到它们成功为止。
Mutable Tables
对于非事务性可变表,我们通过将索引更新添加到主表行的Write-Ahead-Log(WAL)条目来维护索引更新持久性。只有在WAL条目成功同步到磁盘后,我们才会尝试使索引/主表更新。我们默认并行处理索引更新,从而实现非常高的吞吐量。如果在索引更新时服务器崩溃,将通过WAL恢复索引表的所有索引更新来确保正确性。因此,非事务性可变表上的索引只能在主表后面进行编辑。
索引更新失败时保持一致性的方法:
1、禁止表写入,直到可变索引一致
更新索引失败时暂时禁止对数据表的写入,直到索引重新online并与数据表同步
phoenix.index.failure.block.write 设置为true,以便在发生提交失败时使对数据表的写入失败,直到索引可以被数据表捕获。
phoenix.index.failure.handling.rebuild设置为true(默认值),以便在发生提交失败时在后台重建可变索引。
2、在写入失败时禁用可变索引,直到恢复一致性
对可变索引的写入在提交时失败,则将索引标记为已禁用,在后台部分重建它们,直到恢复一致性后将它们标记为活动。在此一致性模式下,在重建二级索引时,不会阻止对数据表的写入。但是,重建完成之前查询将不会使用二级索引。
phoenix.index.failure.handling.rebuild设置为true(默认值),以便在发生提交失败时在后台重建可变索引。
phoenix.index.failure.handling.rebuild.interval控制服务器检查是否需要部分重建可变索引以赶上数据表更新的毫秒频率。默认值为10000或10秒。
phoenix.index.failure.handling.rebuild.overlap.time控制从发生故障的时间戳返回多少毫秒,以便在执行部分重建时返回。默认值为1。
3、在写入失败时禁用可变索引,使用手动重建
这是可变二级索引的最低一致性级别。在这种情况下,当对二级索引的写入失败时,索引将被标记为禁用,并且需要手动重建索引后才能再次被查询使用。
phoenix.index.failure.handling.rebuild设置为false才能在发生提交失败时禁用可变索引在后台重建。
遇到问题:
测试异步索引ASYNC的时候报错: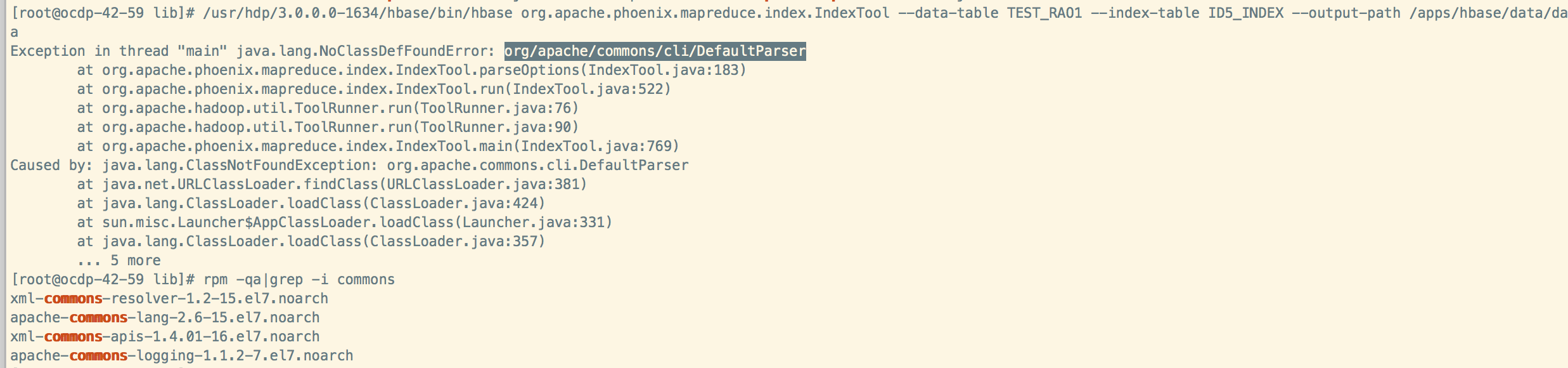
安装apache-commons-cli后还是没解决。
yum install apache-commons-cli -y

若有收获,就点个赞吧
0 人点赞
