一.巡检日期
二.产品说明
大数据产品为橘云产品dpv5.0 ,hdp 版本为3.1.0.0-78
各组件详细版本检查如下表格所示:
| 序号 | 产品组件 | 具体版本 |
|---|---|---|
| 1 | hadoop | 3.1.1 |
| 2 | yarn | 3.1.1 |
| 3 | mapreduce | 3.1.1 |
| 4 | zookeeper | 3.4.6 |
| 5 | hive | 3.1.0 |
| 6 | Spark2 | 2.3.2 |
| 7 | hbase | 2.0.2 |
| 8 | ranger | 1.2.0 |
| 9 | Kafka | 2.0.0 |
三. 节点健康检查
| 项目 | 检查点 | 检查方法 | 当前值 | 建议 |
|---|---|---|---|---|
主机 网络 |
cpu | 通过ambari查看主机是否有长时间超过90% (ambari上配置cpu告警) | 正常 | |
| 内存 | 通过ambari查看主机是否有长时间超过90% (ambari上配置memory告警) | 正常 | ||
| 数据目录 | 是否有足够空间 1、du -h /hdfs* 2、通过namenode ui—>datanodes—>capacity |
需定期清理或扩容 或需数据均衡Hdfs balancer |
||
| 日志目录 | /var文件系统使用量 | 需监控var的使用率 超过60%需要清除日志 |
||
| 域名解析 | /etc/hosts是否已经同步到集群以及客户端机器 | |||
| Transparent Huge Page | 查看系统是否禁用Transparent Huge Page cat /sys/kernel/mm/transparent_hugepage/enabled cat /sys/kernel/mm/transparent_hugepage/defrag grep Huge /proc/meminfo 关闭: echo never > /sys/kernel/mm/transparent_hugepage/enabled echo never > /sys/kernel/mm/transparent_hugepage/defrag |
never | ||
| Swap | cat /proc/sys/vm/swappiness sudo sysctl vm.swappiness=0 cat /proc/sys/vm/min_free_kbytes sudo sysctl -w vm.min_free_kbytes=1024 |
/proc/sys/vm/swappiness :0 /proc/sys/vm/min_free_kbytes: 90112 |
vm.swappiness < 10 vm.min_free_kbytes to at least 1GB (8GB on larger memory systems) |
| | 关闭Swap分区 | 如果没有关闭
1、执行以下命令,查询当前系统中 Swap 的分区。
swapon -s
或者 cat /proc/swaps
2、关闭查询到的 swap 分区。
swapoff swap 分区
例如:
swapoff /dev/dm-1
3、打开配置文件“/etc/fstab”,找到对应的信息,并把相关信息注释掉, 如下:
#dev/mapper/vg_r160-lv_swap swap swap nosuid 0 0 | | 系统swap使用率,计算方法:已用 swap大小/总共 swap 大小。当前阈值设置为 75%,如果 swap 处于打开状态,并且使用率大于75%,会影响集群性能,建议关闭 swap。 |
| | 时钟同步
NTP 偏移量 | Ntpdate systemctl is-enabled ntpd
/usr/sbin/ntpq -np 查看信息,其中offset列表示时间偏差。查看时间偏差是否大于10s | | 是否开启时钟同步
时间偏差10s以内 |
| | 平均负载
| 执行uptime 命令,命令输出的最后三列分别表示 1分钟负载、5分钟负载和15分钟负载。根据系统平均负载的计算方法,如果负载超过阈值,则认为不健康,也可以通过ambari metrics进行查看 | | 系统平均负载,表示特定时间段内运行队列中的平均进程数。这里系统平均负载是通过 uptime 命令中得到的负载值计算得到。计算方法:(1 分钟负载 + 5 分钟负载 +15分钟负载)/(3*CPU个数)。如果超过2,则负载较高。也可通过ambari metrics进行查看 |
| | umask | 登录主机,su ocdp执行umask | | umask设置为077 |
| | 设置磁盘文件预读值 | echo 16384 > /sys/block/sda/queue/read_ahead_kb | | |
| | D 状态进程 | 执行如下命令查看ocdp用户D状态进程号:
ps -elf | grep -v “\[thread_checkio\]” | awk ‘NR!=1 {print $2, $3, $4}’ | grep ocdp | awk -F’ ‘ ‘{print $1, $3}’ | grep D | awk ‘{print $2}’ | | 不可中断的睡眠进程个数,即D状态进程数。D状态通常是进程在等待IO,比如磁盘IO,网络IO等,但是此时IO出现异常。如果系统中出现D状态进程,则需要关注 |
| | 最大打开文件数以及最大线程数,文件句柄使用率 | 1、查看roo及ocdp用户ulimit情况
ulimit –a
2、查看全局最大线程数
cat /proc/sys/kernel/pid_max
3、查看namenode、regionserver、datanode、hmaster进程的ulimit
cat /proc/$pid/limits
确认文件句柄使用率:
执行 cat /proc/sys/fs/file-nr,输出结果的第一列和第三列分别表 示系统已使用的句柄数和总句柄数,如果使用率超过阈值则进行处理 | | open files>65535
max user processes>65535
pid_max>65535
系统中文件句柄的使用率:
计算方法:已用句柄数/总共句柄数。如果使用率超过80%,则需要处理。 |
四.平台组件检查
4.1.HDFS 检查
| 检查点 | 任务子项 | 当前值 | 建议 |
|---|---|---|---|
Namemode |
进程状态、 | 进程正常 | |
| GC情况 | 1、 [ocdp@ocadfnn01:/var/log/hadoop/ocdp]$ cat hadoop-ocdp-namenode-*.log|grep “Detected pause in JVM or host machine’”  无长时间引起STW 的gc 2、 查看gc日志 |
||
| Namenode堆内存 | 按每一百万个对象占用1G内存算,计算配置的namenode内存值是否足够 | ||
| NameNode Safe Mode |
 |
||
| DFSZKFailoverController Status | 正常 |
||
| namenode jvm详情,jcmd pid VM.flags |  |
||
| JornalNode | 进程状态 |  |
|
| 去掉50070和8088 web ui的kerberos认证 | hadoop.http.authentication.simple.anonymous.allowed=true hadoop.http.authentication.type=simple |
开启kerberos之后,访问50070和8080需要配置windows的kerberos认证,如不需要,可取消 | |
| Trash | 1、配置HDFS垃圾回收站机制,增加数据恢复几率,配置 fs.trash.interval=1440 2、配置回收站检查点间隔时长,使数据分批删除,防止nn切换 fs.trash.checkpoint.interval=120 |
fs.trash.interval= 1440—回收站数据保留一天 fs.trash.checkpoint.interval=120—每两个小时执行数据删除,防止一次删除大批量数据导致nn切换 |
|
| Snapshot | HDFS的Snapshot功能,增强HDFS数据安全性 | hdfs lsSnapshottableDir | 对重要数据可以设置 |
| 慢数据节点及慢磁盘检测 | dfs.datanode.peer.stats.enabled=true dfs.datanode.fileio.profiling.sampling.percentage = 20;dfs.datanode.outliers.report.interval = 30m; |
如果需要可通过配置慢数据节点及慢磁盘检测可通过namenode JMX信息查看慢datanode及慢磁盘 | |
| 副本数 | HDFS Block副本数机制,增强数据安全性 dfs.replication |
3 | dfs.replication = 3 |
| FsImage同步 | 检查NameNode主备节点FsImage文件同步情况,降低服务出现异常的风险 | 主nn最新fsimage: 备nn最新fsimage: |
主备fsimage 是否超过2hour |
| FsImage 备份数 | dfs.namenode.num.checkpoints.retained | 2 |
5 |
| Checkpoints时间间隔 | dfs.namenode.checkpoint.period | Hdfs默认checkpoint时间长为:6小时。建议为1小时3600 | |
| 数据均衡 | datanode节点磁盘使用率均 | 与datanode平均使用率相差10%的节点超过集群的总数的20% | |
| WebHDFS | 禁止使用WebHDFS dfs.webhdfs.enabled |
false | |
| namenode ha超时时间 | ha.health-monitor.rpc-timeout.ms | 推荐90000-120000 | |
| namenode 线程数 | dfs.namenode.handler.count | python -c ‘import math ;print int(math.log(datanode_num) * 20)’,小于100节点的集群设置64就可以,小于1000节点配置128就能满足要求 | |
| dn 是否有磁盘问题 | |||
| dn 线程数 | dfs.datanode.handler.count |  修改为32 |
<100 可配置为机器core数 |
| 数据传入和传出DN的最大线程数 | dfs.datanode.max.transfer.threads
| | 指定用于将数据传入和传出DN的最大线程数。如果运行HBase的话建议为16384,老版本为dfs.datanode.max.xcievers |
| 配置HDFS短路读特性 | dfs.client.read.shortcircuit=true
dfs.client.hedged.read.threadpool.size=20
dfs.client.hedged.read.threshold.millis=10 | true | 开启该参数后,Client读操作会通过unix domian socket与DN建立IPC连接,而不走TCP协议,可以提升读性能 |
| 日志异步写 | dfs.namenode.audit.log.async=true
dfs.namenode.edits.asynclogging=true | | 开启异步日志可以提升NameNode的性能 |
| HDFS读写的缓存区大小 | io.file.buffer.size | 131072 | HDFS读写的缓存区大小,该缓冲区的大小可能应该是硬件页面大小的倍数(在Intel x86上为4096),建议配置131072。 |
| 避免读写stale DataNodes
| dfs.namenode.avoid.read.stale.datanode=true
dfs.namenode.avoid.write.stale.datanode=true | | 脏DN指在一个指定的时间间隔内没有收到心跳信息 |
| 数据包大小 | dfs.client-write-packet-size | | 客户端写入的数据包大小,在万兆网部署下,增加数据包的大小可以减少磁盘寻道时间,从而提升IO性能,建议:262144 |
| 文件完成判断控制
| dfs.namenode.file.close.num-committed-allowed
| | 通常一个文件只有在虽有的Block是Complete状态下才可以关闭。如果给这个配 置项配置一个正整数N时,允许文件剩余N个Block时committed状态下,关闭文件,在文件写入最后的一个block还未从DataNode上报状态时,允许客户端关闭文件,从而缩短文件关闭耗时
建议值1 |
| 块上报策略控制
| dfs.blockreport.incremental.intervalMsec | | 当前DataNode增量上报处理,每次操作后都会上报。设置一个正整数以后, DataNode上的incremental blockreport会把上报的时间延迟相应的毫秒数,等待集中上报,建议合并增量块上报操作,1000毫秒合并一次,以减少NameNode上因为增量块上报操作导致的频繁锁切换
建议 1000 |
| 服务端socket的监听队列长度
| ipc.server.listen.queue.size | | 这个参数表示ipc call queue的队列长度,会受到linux内核参数net.core.somaxconn的制约
查看
sysctl -a| grep net.core.somaxconn
设置:
sysctl -w net.core.somaxconn=32768
永久生效:
vi在/etc/sysctl.conf中增加一行net.core.somaxconn=4000然后执行命令sysctl -p建议配置:
100dfs.namenode.handler.count |
| Image传输超时 | dfs.image.transfer.timeout | 480000 | Fsimage/ dfs.image.transfer.bandwidthPerSec 2 二倍就确保不会超时了 |
| 带宽设置 | dfs.image.transfer.bandwidthPerSec | | 52428800 = 50M |
| 小文件 | DFS Used/(blocks*3) | 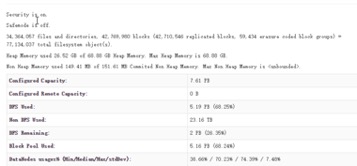
经计算平均block大小为43.43 | >30Mb |
| 机架感知 | 是否配置机架感知 | 已配置net.topology.script.file.na | hadoop dfsadmin –printTopology
为多机架 |
| hdfs Summary
| hdfs 概况信息 | 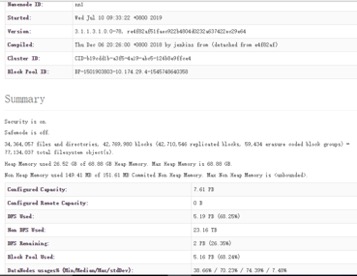 | |
| Fsimage 大小 | 查看fsimage大小 |
| |
| Fsimage 大小 | 查看fsimage大小 | 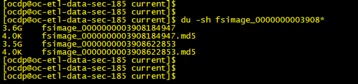 | |
| namenode是否切换 | | namenoe 未搜到下面日志
| |
| namenode是否切换 | | namenoe 未搜到下面日志
IPC’s epoch xx is less than the last promised epoch | 如果发生切换,则分析原因,是否异常切换 |
| Namenode rpc响应时间 | | 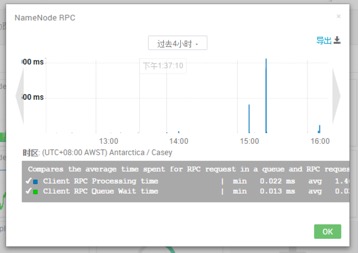 | Avg 10-100ms属于正常 |
| Hdfs垃圾回收时间 | fs.trash.interval | core-site.xml 360 | 1440 |
| Hdfs数据均衡带宽 | dfs.datanode.balance.bandwidthPerSec | Hdfs-site.xml 1048576 | 10485760 |
| Datanode磁盘预留空间 | dfs.datanode.du.reserved | 0 | 157286400 |
| Avg 10-100ms属于正常 |
| Hdfs垃圾回收时间 | fs.trash.interval | core-site.xml 360 | 1440 |
| Hdfs数据均衡带宽 | dfs.datanode.balance.bandwidthPerSec | Hdfs-site.xml 1048576 | 10485760 |
| Datanode磁盘预留空间 | dfs.datanode.du.reserved | 0 | 157286400 |
4.2 yarn 检查
| 检查点 | 检查项 | 当前值 | 建议 |
|---|---|---|---|
| Jobhistory App Timeline Server |
JobHistory Server运行状态 | 正常 | |
| App Timeline Server运行状态 | 正常 | ||
| Yarn ui 界面kill application 是否屏蔽 | 屏蔽 | ||
| ResourceManager Nodemanager |
Yarn 运行状态 |
正常 | |
| Standby ResourceManager运行状态 | 正常 | ||
| ResourceManager java heap size Jcmd pid VM.flags |
10240 | 10240M | |
| Resource manager 是否切换 /var/log/hadoop-yarn/ocdp cat yarn-ocdp-resourcemanager-ocdp-ocadfnn01.log |grep “ Transitioning RM to Standby mode” |
 |
||
| Mapreduce | yarn.app.mapreduce.am.resource.mb | Mapred-site.xml MRAPPmaster进程内存 7168 | 2048 |
| yarn.app.mapreduce.am.resource.cpu-vcores | Mapred-site.xml MRAPPmaster配置的vcore数 1 | 1 | |
| yarn.app.mapreduce.am.co mmand -opts | Mapred-site.xml传递到AM的Java命令行参数-Xmx1024m | -Xmx3072m | |
| mapred.map.child.java.opts mapred.reduce.child.java.opts |
5734m 11468m |
1638 3276 |
|
| mapreduce.map.java.opts mapreduce.reduce.java.opts |
Mapred-site.xml每个map/reduce任务实际jvm启动参数设置最大堆内存-Xmx200m | -Xmx3072m | |
| mapreduce.map.memory.mb | Mapred-site.xml Map进程堆内存 7168-2048 | 2048 判断Map分配的内存是否足够,一个简单的办法是查看运行完成的job的Counters中,对应的task是否发生过多次GC,以及GC时间占总task运行时间之比。通常,GC时间不应超过task运行时间的10%,即GC time elapsed (ms)/CPU time spent (ms)<10%。 |
|
| mapreduce.map.cpu.vcores | Mapred-site.xml Map配置的vcore数 1 | 1 | |
| mapreduce.reduce.memory.mb | Mapred-site.xml Reduce进程内存 14336—4096 | 4096 | |
| mapreduce.task.io.sort.mb | 2047M—1146 | ||
| mapreduce.reduce.cpu.vcores | Mapred-site.xml Reduce配置的vcore数 1 | ||
| mapreduce.map.speculative | FALSE | 对于小集群,可以将这个功能关闭,避免抢占资源 | |
| mapreduce.reduce.speculative | FALSE | 对于小集群,可以将这个功能关闭,避免抢占资源 | |
| mapred.map.tasks.speculative.execution | 推测执行,就是当所有task都开始运行之后,Job Tracker会统计所有任务的平均进度,如果某个task所在的task node机器配置比较低或者CPU load很高(原因很多),导致任务执行比总体任务的平均执行要慢,此时Job Tracker会启动一个新的任务(duplicate task),然后原有任务和新任务哪个先执行完就把另外一个kill掉,建议关闭 | ||
| mapred.reduce.tasks.speculative.execution | 推测执行,就是当所有task都开始运行之后,Job Tracker会统计所有任务的平均进度,如果某个task所在的task node机器配置比较低或者CPU load很高(原因很多),导致任务执行比总体任务的平均执行要慢,此时Job Tracker会启动一个新的任务(duplicate task),然后原有任务和新任务哪个先执行完就把另外一个kill掉,建议关闭 | ||
| mapreduce.job.reduce.slowstart.completedmaps | map作业完成百分之多少后启动reduce作业,建议配置0.8 | ||
| mapreduce.client.submit.file.replication | 可以配置submit阶段的副本数为10 ,尽量实现Task节点的数据本地计算同是也避免大量节点的并发获取产生热点数据 |
||
| mapreduce.map.output.compress | True | True | |
| mapreduce.map.output.compress.codec | org.apache.hadoop.io.compress.SnappyCodec | 一般采用snappy压缩 | |
| mapreduce.output.fileoutputformat.compress | FALSE | True | |
| mapreduce.output.fileoutputformat.compress.codec | |||
| mapreduce.output.fileoutputformat.compress.type | 默认值是RECORD,即针对每条记录进行压缩。如果将其改为BLOCK,将针对一组记录进行压缩 |
||
| mapreduce.map.sort.spill.percent | |||
| mapreduce.reduce.input.buffer.percent | 如果这个参数大于0,那么就会有一定量的数据被缓存在内存并输送给reduce,当reduce计算逻辑消耗内存很小时,可以分一部分内存用来缓存数据,可以提升计算的速度。所以默认情况下都是从磁盘读取数据,如果内存足够大的话,可以设置该参数让reduce直接从缓存读数据 |
||
| mapreduce.reduce.shuffle.input.buffer.percent | 允许map中间结果占用reduce堆大小的百分比,0.7 | ||
| mapreduce.reduce.shuffle.merge.percent | 当reduce中存放map中间结果的buffer使用达到多少百分比时,会触发merge操作,0.66 | ||
| mapreduce.reduce.shuffle.parallelcopies | 在copy(shuffle)阶段,reduce默认的并行传输数,默认5可根据集群大小增大 | ||
| mapreduce.task.io.sort.factor | merge的时候最多能同时merge多少spill,调大可减少merge的次数,从而减少磁盘的操作,默认100 | ||
| mapreduce.task.io.sort.mb | 调大的话,会减少磁盘spill的次数此时如果内存足够的话,一般都会显著提升性能,默认2047 | ||
| mapreduce.reduce.shuffle.read.timeout | reduce下载线程的超时时间,数据比较大,可增大此值,默认180000 |
||
| Yarn | yarn.scheduler.minimum-allocation-mb | 1024M | 一个container分配的最小内存 |
| yarn.scheduler.minimum-allocation-vcores | 1 | 一个container分配最小vcore数 | |
| yarn.scheduler.maximum-allocation-vcores | 32 | 一个container分配最大vcore数 | |
| yarn.resourcemanager.ha.rm-ids | rm1,rm2 | ||
| yarn.nodemanager.resource.memory-mb | Nodemanager节点分配最大内存数 245760M | 80%~90%的节点总内存 | |
| yarn.nodemanager.resource.cpu-vcores | Nodemanager节点分配最大并发数(vcore) 32 | 建议将此配置设定在物理核数的1.5~2倍之间。如果上层计算应用对cpu的计算能力要求不高,可以配置为2倍的物理cpu。 | |
| yarn.nodemanager.local-dirs |  少了磁盘6 |
每个磁盘配置一个路径 | |
| yarn.nodemanager.log-dirs |  少了磁盘6 |
每个磁盘配置一个路径 | |
| yarn.resourcemanager.zk-addres |  |
||
| yarn.nodemanager.pmem-check-enabled | True | ||
| Yarn 服务注册是否打开 hadoop.registry.rm.enabled |
False | ||
| Nodemanager进程堆内存 | Yarn-env.sh 1024 | 4096 | |
| Timelineserver进程堆内存 | Yarn-env.sh 1024 | 4096 | |
| 队列历史变化,pending job 历史变化 脚本实现 |
4.3 zookeeper 检查
| 检查项 | 当前值 | 步骤 |
|---|---|---|
| 服务状态检查 | 1、执行命令echo ruok | nc host-10-1-236-83 2181 返回imok表示服务正常 | |
| 查看数据存储目录空间使用情况 | ||
| 集群健康状态 | echo mntr | nc host-10-1-236-83 2181 指标名 解释 zk_version 版本 zk_avg_latency 平均响应延迟 zk_max_latency 最大响应延迟 zk_min_latency 最小响应延迟 zk_packets_received 收包数 zk_packets_sent 发包数 zk_num_alive_connections 活跃连接数 zk_outstanding_requests 堆积请求数 zk_server_state 主从状态 zk_znode_count znode 数 zk_watch_count watch 数 zk_ephemerals_count 临时节点数 zk_approximate_data_size 近似数据总和大小 zk_open_file_descriptor_count 打开文件描述符数 zk_max_file_descriptor_count 最大文件描述符数 如下是leader才有的属性 zk_followers Follower数 zk_synced_followers 已同步的Follower数 zk_pending_syncs 阻塞中的sync操作 |
|
| ZooKeeper 连接数使用率 | 检查 ZooKeeper 连接数使用率是否超过 80%。如果超过阈值,则认为不 健康。 cat zookeeper.log|grep “Too many connections” netstat -nap |grep 2181 如果超过80%,通过下面步骤检查处理: 1、获取所有与当前ZooKeeper实例连接的IP及连接数量,取连接数最多的前十个 进行检查: lsof -i|grep pgrep -f zookeeper | awk ‘{print $9}’ | cut -d : -f 2 | cut -d \> -f 2 | awk ‘{a[$1]++} END {for(i in a){print i,a[i] | “sort -r -g -k 2”}}’ | head -102、获取连接进程的端口号: lsof -i|grep pgrep -f zookeeper | awk ‘{print $9}’|cut -d \> -f 2 |grep host-10-1-236-82| cut -d : -f 2 (hostname为上面语句查出来的)3、获取连接进程的进程号。依次登录到各IP,根据获取到的port号,执行命令: lsof -i|grep $port 4、根据获取到的进程号,查看进程是什么进程,为什么会产生大量的zk链接,是否存在连接泄露,然后进行处理,如非重要进程,杀掉 5、如链接没有异常则调整zk最大连接数maxClientCnxns |
|
| ZooKeeper 服务处理请求平均延时 | 检查ZooKeeper服务处理请求的平均延时,如果大于300毫秒,则认为不健康。 如果该指标项异常,则需要检查集群的网络速度是否正常,内存或CPU 使用率是否过高。 |
|
| 配置自动清理 | Zookeeper目录log和snapshot历史文件过多,将影响磁盘空间使用,可配置自动文件清理: autopurge.purgeInterval=24 autopurge.snapRetainCount=30 |
|
| 会话超时时间 |
节点数过多需调整会话超时时间 1、查看 echo conf|nc localhost 2181 2修改 在conf/zoo.conf最后加上: minSessionTimeout=30000 maxSessionTimeout=60000 |
|
| Zookeeper进程堆内存 | Zookeeper-env.sh Zookeeper Server Maximum Memory 1024 | 4096 |
| 单个客户端与单台服务器之间的连接数的限制,ip级别,默认是60,设置为0,不作任何限制。(zoo.cfg配置文件) |
zoo.cfg maxClientCnxns 60 | 300 |
4.4 hive 检查
| 检查项 | 详细检查项 | 当前值 | 检查方法/建议 |
|---|---|---|---|
| Hive服务检查 | Hive服务可用性检查 | 正常 | 通过ambari页面运行服务检查 |
| 进程状态 | HiveServer进程状态 | 正常 | 通过ambari页面查看状态及告警信息 |
| HiveMetastore进程状态 | 正常 | 通过ambari页面查看状态及告警信息 | |
| 内存GC情况 | HiveServer2 gc | cat hiveserver2.log|grep ‘Detected pause in JVM or host machine’ 无此内容 |
引起STW时间是否超过10000ms 建议调整JVM内存大小 |
| HiveServer2 Memory | jcmd pid VM.Flags | ||
| Client Heap Size | Client进程堆内存 | 1024 | 10240 |
| Metastore Heap Size | Metastore进程堆内存 | 1024 | 10240 |
| HiveServer2 Heap Size | Hiveserver2进程堆内存 | 1024 | 10240 |
Hiveserver2 连接数 |
hive.server2.thrift.max.worker.threads | 1、建议大于500 2、Hiveserver主机执行netstat -plan | grep 2181|wc -l 查看hiveserver链接数,如果大于配置的hive.server2.thrift.max.worker.threads值,则需要调大hive.server2.thrift.max.worker.threads |
|
| Hive引擎 | Execution Engine | mr和tez,建议tez | |
启用矢量化 |
hive.vectorized.execution.enabled | True | 启用矢量化,矢量化只适用于 ORC 文件格式 |
| hive.vectorized.execution.reduce.enabled | True | 启用reduce矢量化 | |
| hive.vectorized.execution.reduce.groupby.enabled | True | 启用group by查询的reduce查询矢量化 | |
压缩配置 |
hive.exec.compress.intermediate | 是否压缩Hive在多个map-reduce作业之间生成的中间文件 | |
| mapreduce.map.output.compress | 启用map输出压缩 | ||
| mapreduce.output.fileoutputformat.compress | Map完成后的压缩 | ||
| mapreduce.output.fileoutputformat.compress.codec | 压缩算法,建议Snappy org.apache.hadoop.io.compress.SnappyCodec |
||
| mapreduce.map.output.compress.codec | 压缩算法,建议snappy org.apache.hadoop.io.compress.SnappyCodec |
||
| hive.exec.compress.output | 是否对查询的最终输出(到本地/ hdfs文件或Hive表)进行压缩 | ||
| tez.runtime.compress | Tez压缩 | ||
| tez.runtime.compress.codec | Tez压缩算法,建议Snappy org.apache.hadoop.io.compress.SnappyCodec |
||
动态分区 |
hive.exec.dynamic.partition | True启用动态分区,Hive 允许在表中插入记录时创建动态分区,且无需预定义每个分区 | |
| hive.exec.dynamic.partition.mode | 动态分区模式: strict:必须至少有一个分区是静态的 nonstrict:所有分区都允许是动态的 默认strict |
||
本地模式 |
hive.exec.mode.local.auto | 本地模式可让Hive在一台计算机上(有时是在单个进程中)执行某个作业的所有任务。 如果输入数据较小,并且查询启动任务的开销会消耗总体查询执行资源的绝大部分,则此模式可以提高查询性能 | |
| hive.exec.mode.local.auto.inputbytes.max | 当输入文件大小小于此阈值时可以自动在本地模式运行,默认是134217728(128MB) | ||
| hive.exec.mode.local.auto.input.files.max | 当 Hive Tasks(Hadoop Jobs)小于此阈值时,可以自动在本地模式运行,默认4 | ||
Group分组优化 |
hive.multigroupby.singlereducer | True是否通过多个group by查询优化生成单个M / R作业,若多个groupby使用的是一个公用的字段,则这些groupby可以生成一个MR | |
| hive.map.aggr | True group by查询在map端做聚合 | ||
并行执行 |
hive.exec.parallel | True 启用并行执行job作业 | |
| hive.exec.parallel.thread.number | 最多可以并行执行多少个job作业,默认8 建议16 | ||
| limit调优 | hive.limit.optimize.enable | True优化以首先尝试对简单LIMIT尝试较小的数据子集,避免全表扫描,使用抽样机制 | |
启用Fetch task |
hive.fetch.task.aggr | 没有groupby子句的聚合查询(例如,select count(*) from src)在单个reduce任务中执行最终聚合。如果将此参数设置为true,则Hive将最后的聚合阶段使用fetch任务,从而减少查询时间 | |
| hive.fetch.task.conversion | 1. minimal: SELECT *, FILTER on partition columns (WHERE and HAVING clauses), LIMIT only 2. more: SELECT, FILTER, LIMIT only (including TABLESAMPLE, virtual columns) “more” can take any kind of expressions in the SELECT clause, including UDFs. 建议配置为more |
||
| hive.fetch.task.conversion.threshold | 阈值,默认1073741824 (1G),小于1G才会使用Fatch抓取模式 | ||
小文件合并 |
hive.input.format | org.apache.hadoop.hive.ql.io.CombineHiveInputFormat 执行Map前进行小文件合并 | |
| hive.merge.mapfiles | Map作业结束后合并小文件 | ||
| hive.merge.mapredfiles | 在map-reduce作业结束后合并小文件 | ||
| hive.merge.size.per.task | 作业结束时合并文件的大小,默认256000000 | ||
| hive.merge.smallfiles.avgsize | 当作业的平均输出文件大小小于该值时,Hive将启动另一个map-reduce作业以将输出文件合并为更大的文件。如果hive.merge.mapfiles为true,则仅对map作业执行此操作;如果hive.merge.mapredfiles为true,则仅对map-reduce作业执行此操作。默认16000000 | ||
| hive.mergejob.maponly | 如果支持CombineHiveInputFormat则生成只有Map的任务执行merge | ||
| hive.merge.tezfiles | 在Tez DAG的末尾合并小文件 | ||
join优化 |
hive.auto.convert.join | True,普通join转mapjoin | |
| hive.mapjoin.smalltable.filesize | 默认是25000000,mapjoin的阀值,如果小表小于该值,则会将普通join[reduce join]转为mapjoin,(按照hive.tez.container.size大小做相应调整) | ||
| hive.auto.convert.join.noconditionaltask | True Hive在基于输入文件大小的前提下将普通JOIN转换成MapJoin,并是否将多个MJ合并成一个 | ||
| hive.auto.convert.join.noconditionaltask.size | 默认100000000(按照hive.tez.container.size大小做相应调整),多个MJ合并成一个MJ时,其表的总的大小须小于该值 | ||
skewjoin优化 |
hive.optimize.skewjoin | 是否打开skewjoin优化,如果有join操作,建议设置为true,有数据倾斜时开启负载均衡 | |
| hive.skewjoin.key | 超过多少行的key视为skew key,推荐使用默认值100000 | ||
| hive.groupby.skewindata | True 数据倾斜时负载均衡,Group By查询中防止数据倾斜 | ||
Tez切片配置 |
tez.grouping.min-size | 16777216 | 分组分割大小下限,默认值16777216,Hadoop会将单个文件拆分(对应)为多个文件,并且并行处理产生的文件。对应程序的数目取决于分割的数目,降低这两个参数可以产生更多的map改善延迟扩大吞吐 |
| tez.grouping.max-size | 1073741824 | 分组分割大小上限,默认值1073741824,Hadoop会将单个文件拆分(对应)为多个文件,并且并行处理产生的文件。对应程序的数目取决于分割的数目,降低这两个参数可以产生更多的map改善延迟扩大吞吐 | |
自动并行reduce |
hive.tez.auto.reducer.parallelism | TRUE打开Tez的自动reduce并行功能,启用后,Hive会估计数据大小并设置并行度估算,建议开启 | |
| hive.tez.min.partition.factor | 默认0.25 When auto reducer parallelism is enabled this factor will be used to over-partition data in shuffle edges.,建议0.05 |
||
| hive.tez.max.partition.factor | 默认值2 When auto reducer parallelism is enabled this factor will be used to put a lower limit to the number of reducers that Tez specifies. Hive/ Tez estimates number of reducers Max(1, Min(hive.exec.reducers.max [1099], ReducerStage estimate/hive.exec.reducers.bytes.per.reducer)) x hive.tez.max.partition.factor [2],可以适当调大 |
||
| Tez container prewarm | hive.prewarm.enabled | True 启用container prewarm | |
| hive.prewarm.numcontainers | 每个AM预启动container数 ,eg:3, 一个session打开将启动4个container,建议10 | ||
Hive白名单 |
hive.security.authorization.sqlstd.confwhitelist | mapred.|hive.|mapreduce.|spark. | |
| hive.security.authorization.sqlstd.confwhitelist.append | mapred.|hive.|mapreduce.|spark. | ||
| Tez container内存 | hive.tez.container.size | 默认2048 建议4096 | |
| Tez AM内存 | tez.am.resource.memory.mb | 默认1024,设置不能太小,am container不停full gc,最后报错终止,建议8192 | |
| tez.runtime.io.sort.mb | 输出排序内存大小,建议40% of hive.tez.container.size,一般不超过2G | ||
| tez.runtime.unordered.output.buffer.size-mb | 缓冲区大小,建议10% of hive.tez.container.size | ||
| tez.session.am.dag.submit.timeout.secs | 默认值600,建议配置10 AM等待DAG提交的超时时间,dacp一个流程的多个任务使用不用的session所以这个值应该设置的较小,避免资源浪费 |
||
| hive.exec.reducers.bytes.per.reducer | 默认256000000,指定每个reducer处理的数据大小,降低这个值会增加并行度,影响reduce数量 | ||
| tez.shuffle-vertex-manager.min-src-fraction | the fraction of source tasks which should complete before tasks for the current vertex are scheduled 默认0.2建议0.25 |
||
| tez.shuffle-vertex-manager.max-src-fraction | once this fraction of source tasks have completed, all tasks on the current vertex can be scheduled. Number of tasks ready for scheduling on the current vertex scales linearly between min-fraction and max-fraction 默认0.4建议0.75 |
||
| tez.am.container.idle.release-timeout-max.millis | 默认10000,保留该容器的最长时间 建议20000 |
||
| tez.am.container.idle.release-timeout-min.millis | 默认5000,保留该容器的最长时间 建议10000 |
||
| tez.am.mode.session | True表示会话模式,跑批量任务,建议关掉(HDP2.4 |
||
| tez.yarn.ats.event.flush.timeout.millis | 建议配置60000 解决tez任务AM不释放 | ||
| hive.metastore.transactional.event.listeners | hive msck修复分区慢,修改此属性为空 | ||
| Hive.load.data.owner | Ocdp dp5.0下会检查load文件的宿主,需修改为ocdp | ||
Hive关闭ACID |
hive.compactor.initiator.on=false; hive.compactor.worker.threads=0; hive.strict.managed.tables=false; hive.create.as.insert.only=false; metastore.create.as.acid=false; |
SparkSql无法读取hive acid表,如果需要使用SparkSql读取hive表,则需要关闭hive acid | |
HIVE LLAP |
tez.am.resource.memory.mb | 8192 AM内存 | |
| hive.server2.tez.sessions.per.default.queue | 2 并行执行任务数 | ||
| hive.llap.daemon.yarn.container.mb | 81920 hive llap daemon内存 | ||
| hive.llap.io.threadpool.size | 16 = hive.llap.daemon.num.executors | ||
| num_llap_nodes_for_llap_daemons | 40 llap总使用内存/hive llap daemon内存 | ||
| hive.tez.container.size | 4096 | ||
| hive.llap.daemon.num.executors | 16 (llap_heap_size/ hive.tez.container.size | ||
| llap_headroom_space | 6144 | ||
| llap_heap_size | 65536 (llap总内存-llap_headroom_space- hive.llap.io.memory.size) | ||
| hive.llap.io.memory.size | 10240 |
4.5 hbase 检查
| 检查项 | 当前值 | 建议 |
|---|---|---|
| HBase Master运行状态 | hmaster 正常 | |
| Hbase RegionServers运行状态 | regionserver正常 | |
| Hbase master进程堆内存 | Hbase-env.sh 1024 | 8192M,Hbase中的主服务器不会做任何繁重的工作,基本上负责元操作,例如表的创建/删除,因此在常规设置中使用的空间不会超过4-8 GB |
| Hbase regionserver进程堆内存 | Hbase-env.sh 1024 | 8192M,大多数数据加载/处理将在分配的regionserver堆中进行。使用G1GC算法时,对堆大小没有限制。可以在Ambari> Hbase>主UI>内存选项卡中检查堆使用情况,如果利用率在高峰时段激增至总堆的60-70%左右,则考虑将进一步增加堆大小。 |
| Master 异常退出 | 查看regionserver FATAL日志 ,无 |
|
| RegionServer 异常退出 | 查看regionserver FATAL日志 | |
| RegionServer gc | 1、 查看gc日志 2、 查看regionserver 日志 cat hbase--regionserver-.log |grep ‘Detected pause in JVM or host machine’ 看了几个节点,都在1000多ms |
引起STW时间是否超过20000ms |
| Snapshot (对重点表进行snapshot) | ||
| Hbase region in transition 是否存在长时间处于RIT状态的region |
无 | |
| Memstore 大小 | Hbase.hregion.memstore.flush.size 128M | 如果regionserver的jvm内存比较充足(16G以上),可以调整为256M |
| HbaseMaster Jvm | Jcmd pid VM.flags |
|
| Number of regions per RS - upper bound | 1 正常 | <1500 |
| Hbase.hregion.max.filesize | 10G | |
| Compactions (合并) | base.regionserver.thread.compaction.small=5 | |
| hbase.hstore.compactionThreshold 3 | 该值不能太大,否则会积累太多文件,一般建议设置为5~8左右 | |
| hbase.hstore.compaction.max 10 | ||
| hbase.hstore.blockingStoreFiles 100 –20 | ||
| hbase.hregion.majorcompaction.jitter 0.5 | ||
| hbase.hstore.blockingWaitTime | 达到hbase.hstore.blockingStoreFiles定义的StoreFile限制后,区域将阻止更新的时间。在此时间过去之后,即使压缩尚未完成,该区域也将停止阻止更新。为了避免影响业务暂停时间过长,可将此参数配小,默认90000,建议30000 | |
| Hbase region是否分裂 | Hbase ui查看 无region分裂 |
不分裂后者分裂次数小于region数的1/100 |
| Pre-splitting the table (是否预分区) | Hbase ui查看 |
Table region 在不分裂的情况下大于1 |
| major compact | hbase.hregion.majorcompaction=0 已经关闭 | 建议关闭,改为手工执行 |
| 重点table rowkey 是否分布均匀 | Hbase ui 查看 | request在region server 上分布均匀 |
| Regionserver jvm详情 | jcmd pid VM.flags |
|
| Regionserver Request Count | ||
| hbase.regionserver.handler.count | 100 | 该值不是越大越好,建议根据CPU的使用情况,可以选择设置为100至300之间的值。 |
| hbase.regionserver.lease.period | 客户端连接regionserver的租约超时时间,客户端必须在这个时间内汇报,否则认为客户端已死掉,默认60000,可配置120000 | |
| hbase.client.scanner.timeout.period | 该参数表示一次Scan中一次RPC请求的超时时间(一次Scan可能有多次RPC请求)需配置小于hbase.regionserver.lease.period,表示scan租约的时间,建议设置为60000ms的整数倍,在读高负载情况下可以适当调大,可配置120000 | |
| hbase.client.scanner.caching | 在扫描器上调用next时尝试获取的行数。此配置与hbase.client.scanner.max.result.size一起使用,以尝试有效地使用网络,可设置200 | |
| hbase.client.scanner.max.result.size | 默认:2097152 2M适合1ge网络 | |
| hbase.hregion.memstore.mslab.enabled | 启用MemStore-Local Allocation Buffer,该功能可防止在重写入负载下发生堆碎片。这可以减少大堆上GC暂停的频率 | |
| hbase.rpc.timeout | hbase client进行rpc链接的超时时间,建议增大到90000 | |
| hbase.regionserver.hlog.splitlog.writer.threads | 默认值是3,建议设为10,日志切割所用的线程数。 | |
| base.regionserver.thread.compaction.small | 默认值为1,regionserver做Minor Compaction时线程池里线程数目,可以设置为5 | |
| hbase.regionserver.thread.compaction.large | 默认值为1,regionserver做Major Compaction时线程池里线程数目,可以设置为8 | |
| hbase.regionserver.lease.period | 默认值60000(60s),客户端连接regionserver的租约超时时间,客户端必须在这个时间内汇报,否则认为客户端已死掉,建议配置90000 | |
| Hbase.client.write.buffer | 默认2097152 2M,写缓存大小,推荐设置为5M,测试过设为10M下的入库性能,反而没有5M好 | |
| hbase.hstore.flusher.count | memstore的flush线程数,在put高负载场景下可以适当调大 |
4.6 spark 检查
| 检查点 | 检查项 | 当前值 |
|---|---|---|
| Spark thift server | 进程状态正常 | 正常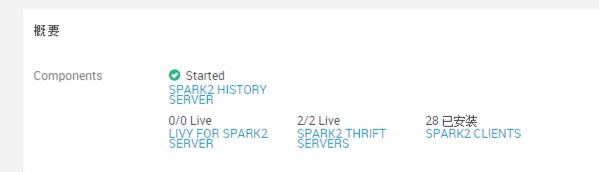 |
| sparkThriftServer进程堆内存 | spark-thrift-sparkconf spark_daemon_memory 1024 | 10240 |
| 每个executor分配的vcore数 | spark-thrift-sparkconf spark.executor.cores 1 | 4 |
| 每个executor分配的内存 | spark-thrift-sparkconf spark.executor.memory 1024 | 1024 |
4.7 Ambari-server 检查
调整ambari-server堆内存,防止集群增大后,内存不足响应缓慢。
vi /var/lib/ambari-server/ambari-env.sh
export AMBARI_JVM_ARGS=$AMBARI_JVM_ARGS’ -Xms1024m -Xmx4096m -XX:MaxPermSize=128m
五.元数据安全检查
| 检查内容 | 当前值 |
|---|---|
| Ambari | 元数据存放mysql 库,主主 |
| hive | 元数据存放mysql 库,主主 |
| hdfs | 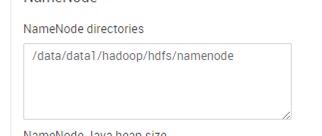 1个目录 |
| ranger | 元数据存放mysql 库,主主 |
| ldap | 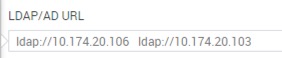 启用主备 启用主备 |
六.高可用检查
| 检查项 | 是否高可用 |
|---|---|
| NameNode | HA高可用 |
| ResouceManager | HA高可用 |
| Hmaster | HA高可用 |
| Hiveserver2 | HA高可用 |
| Hivemetastore | HA高可用 |
| Mysql 高可用 | 主主 |
| Ldap 高可用 | HA高可用 |
| KDC高可用 | 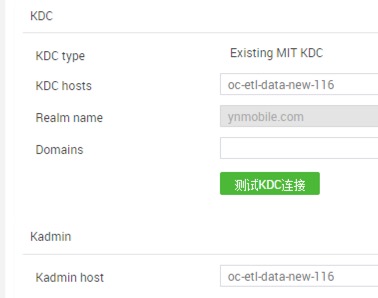 |
七.权限及认证检查
7.1组件权限检查
| 检查项 | Plug enabled |
|---|---|
| Hdfs plug enabled | Enabled |
| yarn plug enabled | Enabled |
| Hive plug enabled | Enabled |
| Hbase plug enabled | Enabled |
| kafka plug enabled | Enabled |
7.2 LDAP 认证检查
| 检查项 | 当前值 |
|---|---|
| Ldap 用户能否通过认证登录客户端 | 正常 |
| Ldap 用户是否同步在namenode、resource manager、hiveserver2 主机 | 正常 |
| Ldap链接数 | |
| ldap添加日志方便后期定位问题 | vi slapd.conf loglevel 4095 vi /etc/rsyslog.conf local4.* /var/log/openldap.log service rsyslog restart service slapd restart |
7.3 Ranger 检查
| 检查项 | 当前值 |
|---|---|
| 操作系统新增一个用户, 检查ranger 是否同步该用户 | |
| Ranger admin 状态 | 正常 |
| Ranger usersync 状态 | 正常 |
7.4 Kerberos 检查
| 参数 | 说明 | 默认值 | 建议值 |
|---|---|---|---|
| hadoop.security.auth_to_local | 指定的规则将Kerberos主体映射到操作系统用户(系统)帐户 | DEFAULT | RULE:2:$1/$2@$0s/(.)@ocdp/./ |
7.5 Mysql 检查
| 参数 | 说明 | 默认值 | 建议值 |
|---|---|---|---|
| 查看授权用户 | SELECT host,user,Grant_priv,Super_priv FROM mysql.user;// | ||
| default-character-set | /etc/my.cnf mysql服务器默认字符集设置 | utf8 | |
| max_connections | /etc/my.cnf最大用户连接数 | 151 | 3000 |
八.集群扩容检查
8.1 HDFS配置
| 说明 | 参数 | 建议值 |
|---|---|---|
| HDFS | ||
| 可适当增加打开文件数目值 | vi /etc/security/limits.conf | * - nofile 65535 |
| 合理设置namenode线程参数 | hdfs-site.xml dfs.namenode.handler.count 10 | 20 * log2(DN节点数) :设置namenode能够同时处理的请求数,一般为集群规模的自然对数lnN 的20倍,小于100节点的集群设置64就可以,小于1000节点配置128就能满足要求。 |
| 合理设置datanode线程参数 | dfs.datanode.handler.count | 设置datanode处理rpc的线程数,大集群可以适当加大。注意提高此参数会占用更多DataNode内存,故需观察DN内存情况,视消耗情况可增加DN内存。<100 可配置为机器core数 |
| ipc.server.listen.queue.size这个参数表示ipc call queue的队列长度, | 会受linux内核参数net.core.somaxconn的制约。 所以如果要增大该参数,同时也要调整内核参数net.core.somaxconn,否则配置是不会生效的。core-site.xml ipc.server.listen.queue.size 128 |
100*dfs.namenode.handler.count |
| 设置合理datanode传输数据的最大线程数 | dfs.datanode.max.transfer.threads | datanode用于传输数据的最大线程数,默认4096,对于高并发场景调整为8192。 |
| HBase | ||
| 设置合理rpc请求的线程数量 | hbase.regionserver.handler.count | rpc请求的线程数量,默认值是10,生产环境建议使用100,也不是越大越好,特别是当请求内容很大的时候,比如scan/put几M的数据,会占用过多的内存,有可能导致频繁的GC,甚至出现内存溢出 |
| 设置合理的regionserver参数 | Regionserver Jvm | 对于共享HDFS集群的Hbase集群,regionServer内存不建议过高,单个regionServer负载region数也建议在1500个以内,故内存可设置在10GB以内 |
| Number of regions per RS - upper bound | 对于共享HDFS集群的Hbase集群,由于服务器资源有限,单个RegionServer负载Region数建议保持在1500个以内,且根据表存储数据量及RegionSize评估预设Region数,尽量避免Region分裂;对于高频率更新value值的非累积表,需合理设置major compact频率,保证数据清除效率 | |
| Maximum region size | 对于大规模集群,该值对Region分裂以及major compact影响较大,既要尽量减少分裂,还要考虑major compact效率 | |
| Compactions | compaction很大程度上影响write的吞吐量,对于写比较密集的作业,应该减少的compaction的频率,可以通过调高hbase.hstore.compaction.min 、hbase.hstore.blockingStoreFiles,降低compaction频率 |
8.2 YARN内存配置
集节点的适当YARN和MapReduce内存配置:
YARN和MapReduce内存=总RAM – 预留内存(堆栈内存预留+ HBase内存预留)
保留内存建议
| 每个节点的总内存 | 建议的预留系统内存 | 建议的保留HBase内存 |
|---|---|---|
| 4 GB | 1 GB | 1 GB |
| 8 GB | 2 GB | 1 GB |
| 16 GB | 2 GB | 2 GB |
| 24 GB | 4 GB | 4 GB |
| 48 GB | 6 GB | 8 GB |
| 64 GB | 8 GB | 8 GB |
| 72 GB | 8 GB | 8 GB |
| 96 GB | 12 GB | 16 GB |
| 128 GB | 24 GB | 24 GB |
| 256 GB | 32 GB | 32 GB |
| 512 GB | 64 GB | 64 GB |
每个节点允许的最大容器数,可以使用以下公式:
容器数量=最小值(2 CORES,1.8 DISKS,(总可用RAM)/ MIN_CONTAINER_SIZE)
| 每个节点的总RAM | 建议的最小容器尺寸 |
|---|---|
| Less than 4 GB | 256 MB |
| Between 4 GB and 8 GB | 512 MB |
| Between 8 GB and 24 GB | 1024 MB |
| Above 24 GB | 2048 MB |
每个容器的RAM数量,可以使用以下公式:
每个容器的RAM =最大值(MIN_CONTAINER_SIZE,(总可用RAM)/容器))
设置YARN和MapReduce配置:
| 配置文件 | 配置设定 | 价值计算 |
|---|---|---|
| yarn-site.xml | yarn.nodemanager.resource.memory-mb | =容器*每个容器的RAM |
| yarn-site.xml | yarn.scheduler.minimum-allocation-mb | =每个容器RAM |
| yarn-site.xml | yarn.scheduler.maximum-allocation-mb | =容器*每个容器的RAM |
| mapred-site.xml | mapreduce.map.memory.mb | =每个容器RAM |
| mapred-site.xml | mapreduce.reduce.memory.mb | = 2 *每个容器的RAM |
| mapred-site.xml | mapreduce.map.java.opts | = 0.8 *每个容器的RAM |
| mapred-site.xml | mapreduce.reduce.java.opts | = 0.8 2 每个容器的RAM |
| yarn-site.xml(检查) | yarn.app.mapreduce.am.resource.mb | = 2 *每个容器的RAM |
| yarn-site.xml(检查) | yarn.app.mapreduce.am.command-opts | = 0.8 2 每个容器的RAM |
8.3 HBase配置
| 说明 | 参数 | 建议值 |
|---|---|---|
| Hbase master进程堆内存 | Hbase-env.sh 1024 | 8192M,Hbase中的主服务器不会做任何繁重的工作,基本上负责元操作,例如表的创建/删除,因此在常规设置中使用的空间不会超过4-8 GB |
| Hbase regionserver进程堆内存 | Hbase-env.sh 1024 | 8192M,大多数数据加载/处理将在分配的regionserver堆中进行。使用G1GC算法时,对堆大小没有限制。可以在Ambari> Hbase>主UI>内存选项卡中检查堆使用情况,如果利用率在高峰时段激增至总堆的60-70%左右,则考虑将进一步增加堆大小。 |
| regionserver堆的年轻代大小的上限 | hbase_regionserver_xmn_max |
经验是保留总堆的1/8-1/10,且不得超过4000 Mb。 |
| 每个regionserver的region数量 | 决不建议每个区域服务器超过200-400个区域。根据公式找出集群中的现有数量是否为优化数:(regionserver_memory_size)(memstore_fraction)/((memstore_size)(num_column_families)) | |
| 块缓存用来使读取速度更快 | file.block.cache.size | 建议20-40%之间,需要使用反复试验的方法进行调整,什么最适合。 |
| 每个表每个区域的每个列族打开的所有内存存储所使用的总堆的一部分 | hbase.regionserver.global.memstore.size | 对于大量写入的用例,介于20-40%之间。注意块缓存的总和与全局内存大小之和不应大于总堆的70-75% |
| 设置合理rpc请求的线程数量 | hbase.regionserver.handler.count | rpc请求的线程数量,默认值是10,生产环境建议使用100,也不是越大越好,特别是当请求内容很大的时候,比如scan/put几M的数据,会占用过多的内存,有可能导致频繁的GC,甚至出现内存溢出 |
| 设置合理的regionserver参数 | Regionserver Jvm | 对于共享HDFS集群的Hbase集群,regionServer内存不建议过高,单个regionServer负载region数也建议在1500个以内,故内存可设置在10GB以内 |
| Number of regions per RS - upper bound | 对于共享HDFS集群的Hbase集群,由于服务器资源有限,单个RegionServer负载Region数建议保持在1500个以内,且根据表存储数据量及RegionSize评估预设Region数,尽量避免Region分裂;对于高频率更新value值的非累积表,需合理设置major compact频率,保证数据清除效率 | |
| Maximum region size | 对于大规模集群,该值对Region分裂以及major compact影响较大,既要尽量减少分裂,还要考虑major compact效率 | |
| Compactions | compaction很大程度上影响write的吞吐量,对于写比较密集的作业,应该减少的compaction的频率,可以通过调高hbase.hstore.compaction.min 、hbase.hstore.blockingStoreFiles,降低compaction频率 |
8.4 zookeeper配置
| 会话超时时间zookeeper.session.timeout | zookeeper服务器本身具有为其客户端(如hbase)定义的最小和最大会话超时,其计算公式如下: 最小会话超时:2 X tick time 最大会话超时:20 x tick time |
节点数过多需调整会话超时时间 1、查看 echo conf|nc localhost 2181 2修改 在conf/zoo.conf最后加上: minSessionTimeout=30000 maxSessionTimeout=60000 |
|---|---|---|
| 单个客户端与单台服务器之间的连接数的限制,ip级别,默认是60,设置为0,不作任何限制。(zoo.cfg配置文件) |
zoo.cfg maxClientCnxns 60 | 300 |

若有收获,就点个赞吧
0 人点赞
