1. 平衡DataNode(HDFS-1312)内磁盘的使用(不同容量)
功能描述:
https://blog.csdn.net/D55dffdh/article/details/82467770
在单一DataNode管理多个磁盘的情况下,执行普通写操作时的每个磁盘用量比较平均。但是,添加或者更换磁盘将会导致DataNode磁盘用量严重不均衡,传统的HDFS均衡器关注点是DataNode之间(inter-)而不是intra-,但是Hadoop 3.0及以上版本中,新的HDFS Intra-DataNode磁盘平衡器可以很好得解决上述问题。
功能实现:
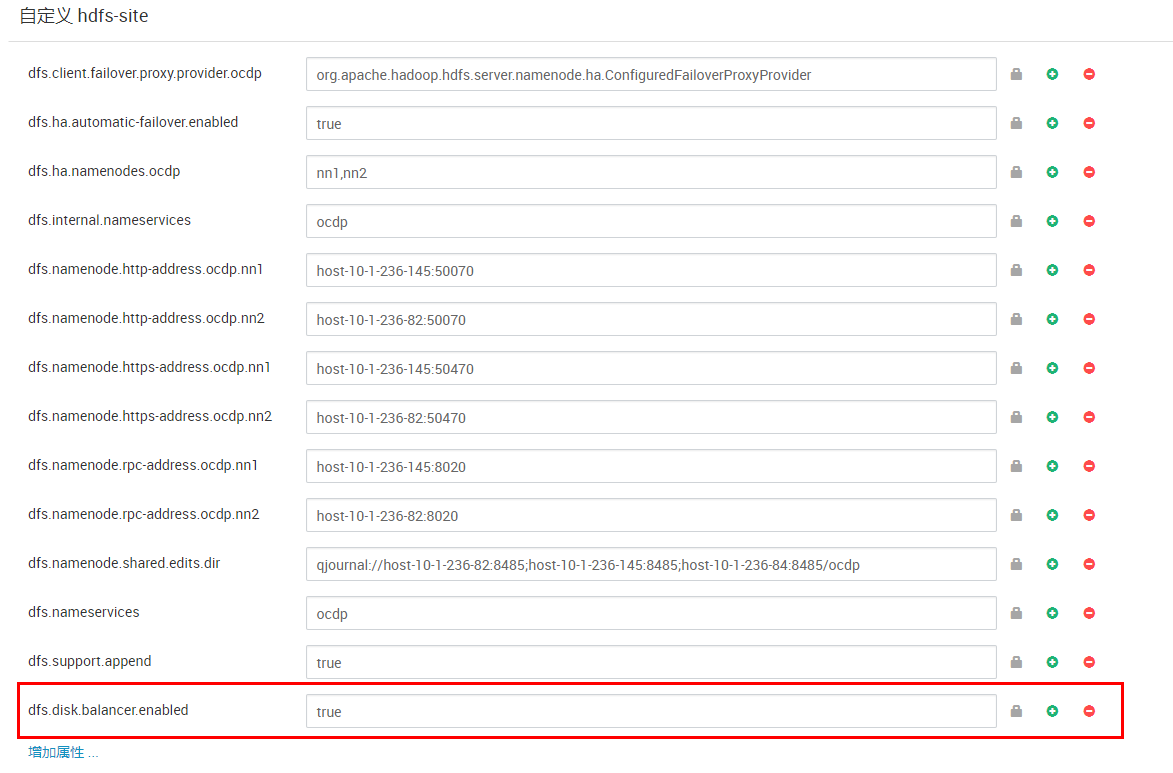
- 通过ambari界面修改hdfs-site.xml,添加如下参数:
| 参数 | 说明 | 默认值 | 建议值 |
|---|---|---|---|
| dfs.disk.balancer.enabled | 开启hdfs datanode diskbalancer | False | True |
重启hdfs使配置生效。
2.后台执行命令进行datanode各磁盘数据均衡
(1)磁盘平衡器任务涉及三个步骤(通过HDFS diskbalancer命令实现):计划,执行和查询。在第一步中,HDFS客户端从NameNode读取有关指定DataNode的必要信息,以生成执行计划:
hdfs diskbalancer -plan host-10-1-236-145 (datanode hostname)
日志中会输出一个执行计划文件路径:
INFO command.Command: Writing plan to : /system/diskbalancer/2018-Oct-9-13-15-01
目录中会生成执行计划文件:
hadoop fs -ls /system/diskbalancer/2018-Oct-9-13-15-01
/system/diskbalancer/2018-Oct-9-13-15-01/host-10-1-236-145.json
执行计划文件:
hdfs diskbalancer -execute /system/diskbalancer/2018-Oct-9-13-15-01/host-10-1-236-145.json
均衡过程需要一段时间,我们可以通过下面命令进行查询:
hdfs diskbalancer -query host-10-1-236-145:20001
如果返回:Result: PLAN_DONE,则说明均衡完成。可以通过命令:df -h 进行查看。
注:上述命令中也可以设置网络带宽,均衡阈值等,防止对生产集群业务产生影响。具体请通过命令查看:hdfs diskbalancer -help plan
遇到问题:
2. 使用目录级Reed Solomon擦除编码编码减少HDFS的存储开销(HDFS-7285)
https://blog.csdn.net/runningtortoises/article/details/51589918
https://www.jianshu.com/p/9f99cc9630cd?utm_source=oschina-app
功能描述:
复制是昂贵的 - HDFS中的默认3副本方案在存储空间和其他资源(例如网络带宽)上具有200%的开销。但是,对于I / O活动相对较低的热数据集和冷数据集,在正常操作期间很少访问额外的块副本,但仍占用与第一个副本相同数量的资源。
因此,自然的改进是使用擦除编码(EC)来代替复制,这提供了相同级别的容错性以及更少的存储空间。在典型的擦除编码(EC)设置中,存储开销不超过50%。EC文件的复制因素是没有意义的。它始终为1,不能通过-setrep命令更改。
在存储系统中,EC最显着的用途是廉价磁盘冗余阵列(RAID)。RAID通过条带化来实现EC,将逻辑上连续的数据(如文件)分割成更小的单元(比如位,字节或块),并将连续的单元存储在不同的磁盘上。在本指南的其余部分,这个条带分布单元被称为条带单元(或单元)。对于原始数据单元的每个条带,计算并存储一定数量的奇偶单元 - 其过程被称为编码。任何分条单元上的错误可以通过基于存活数据和奇偶校验单元的解码计算来恢复。
将EC与HDFS集成可以提高存储效率,同时仍能提供与传统的基于复制的HDFS部署类似的数据持久性。举个例子,一个有6个块的3副本文件会占用6 * 3 = 18块磁盘空间。但是随着EC(6数据,3奇偶校验)的部署,它将只消耗9块磁盘空间。
群集和硬件配置
擦除编码在CPU和网络方面对集群提出了额外的要求。
编码和解码工作在HDFS客户端和DataNode上消耗额外的CPU。
擦除编码的文件也分布在机架上以实现机架容错。这意味着在读取和写入条带化文件时,大多数操作都是机架外的。网络二等分带宽非常重要。
对于机架容错,配置至少与配置的EC条带宽度一样多的机架也很重要。对于欧共体政策RS(6,3),这意味着最少9个机架,最好是10或11个,以处理计划内和计划外停机。对于机架数量少于条带宽度的机箱,HDFS无法保持机架的容错性,但仍然会尝试在多个节点间传播条带文件以保持节点级的容错性。
功能实现:
1.默认情况下,除了在默认情况下启用的dfs.namenode.ec.system.default.policy中定义的内容之外,所有内置的擦除编码策略都是禁用的。集群管理员可以通过hdfs ec [-enablePolicy -policy
Erasure Coding Policies:
ErasureCodingPolicy=[Name=RS-10-4-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=10, numParityUnits=4]], CellSize=1048576, Id=5], State=DISABLED
ErasureCodingPolicy=[Name=RS-3-2-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=3, numParityUnits=2]], CellSize=1048576, Id=2], State=DISABLED
ErasureCodingPolicy=[Name=RS-6-3-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=1], State=ENABLED
ErasureCodingPolicy=[Name=RS-LEGACY-6-3-1024k, Schema=[ECSchema=[Codec=rs-legacy, numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=3], State=DISABLED
ErasureCodingPolicy=[Name=XOR-2-1-1024k, Schema=[ECSchema=[Codec=xor, numDataUnits=2, numParityUnits=1]], CellSize=1048576, Id=4], State=DISABLED
默认情况下,“dfs.namenode.ec.system.default.policy”是“RS-6-3-1024k”。
3. HDFS提供了一个ec子命令来执行与删除编码相关的管理命令。
hdfs ec [通用选项]
[-setPolicy -path
[-getPolicy -path
[-unsetPolicy -path
[-listPolicies]
[ - addPolicies -policyFile
[-listCodecs]
[-enablePolicy -policy
[-disablePolicy -policy
[-help [cmd …]]以下是有关每个命令的详细信息。[-setPolicy -path
路径:HDFS中的目录。这是一个强制参数。设置策略只影响新创建的文件,不影响现有的文件。policyName:用于此目录下文件的擦除编码策略。如果设置了“dfs.namenode.ec.system.default.policy”配置,则可以省略此参数。路径的EC策略将在配置中设置为默认值。-replicate在目录上应用特殊的REPLICATION策略,强制目录采用3x复制方案。-replicate和-policy
遇到问题:
擦除编码文件不支持某些HDFS文件写入操作,即hflush,hsync和append,因为存在严重的技术挑战。append()在擦除编码文件将抛出IOException。hflush()和HSYNC()上DFSStripedOutputStream是无操作。因此,在擦除编码的文件上调用hflush()或hsync()不能保证数据持久。
客户端可以使用StreamCapabilities API来查询OutputStream是否支持hflush()和hsync()。如果客户希望通过hflush()和hsync()来实现数据持久化,目前的补救措施是在非擦除编码的目录中创建常规3x复制文件等文件,或使用FSDataOutputStreamBuilder#replicate() API创建3x复制文件一个删除编码的目录。
4. 支持NameNode高可用性的2个备用NameNode
功能描述:
在Hdfs3.0以前版本中,一个hdfs只有两个namenode服务,一个是active状态,一个是standby 状态。当active namenode进程挂掉后,standby namenode会变成active状态,保证hdfs服务正常运行。但是这时如果这个standby namenode也挂掉了,则hdfs将无法提供服务。基于这种情况,hdfs3.0可以允许有一个active namenode,多个standby namenode,从而防止这种情况发生。
功能实现:
由于ambari界面没有直接提供该功能实现。需要我们通过ambari rest api来进行实现。
找一个没有安装namenode的节点通过ambari rest api进行安装:
curl -u admin:admin -i -H “X-Requested-By:ambari” -X POST ‘10.1.236.145:8080/api/v1/clusters/ocdp/hosts/host-10-1-236-83/host_components/NAMENODE’
curl -u admin:admin -i -H “X-Requested-By:ambari” -X PUT ‘10.1.236.145:8080/api/v1/clusters/ocdp/hosts/host-10-1-236-83/host_components/NAMENODE’ -d ‘{“HostRoles”: {“state”: “INSTALLED”}}’
curl -u admin:admin -i -H “X-Requested-By:ambari” -X POST ‘10.1.236.145:8080/api/v1/clusters/ocdp/hosts/host-10-1-236-83/host_components/ZKFC’
curl -u admin:admin -i -H “X-Requested-By:ambari” -X PUT ‘10.1.236.145:8080/api/v1/clusters/ocdp/hosts/host-10-1-236-83/host_components/ZKFC’ -d ‘{“HostRoles”: {“state”: “INSTALLED”}}’
修改hdfs配置: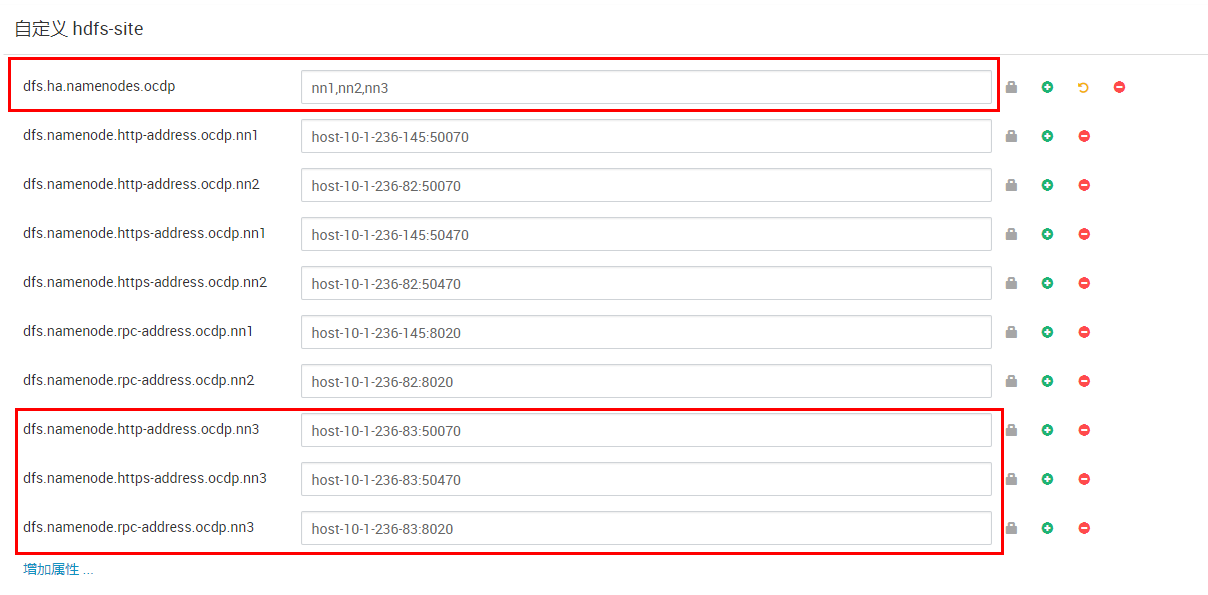
重启zkfc,使配置刷到本地磁盘。然后停止zkfc服务,重新format zkfc:
sudo su ocdc -l -c ‘hdfs zkfc -formatZK’
启动zkfc,在新加namenode节点执行:
sudo su ocdc -l -c ‘hdfs namenode -bootStrapstandby’
重启hdfs服务即可。
如果成功,显示如下: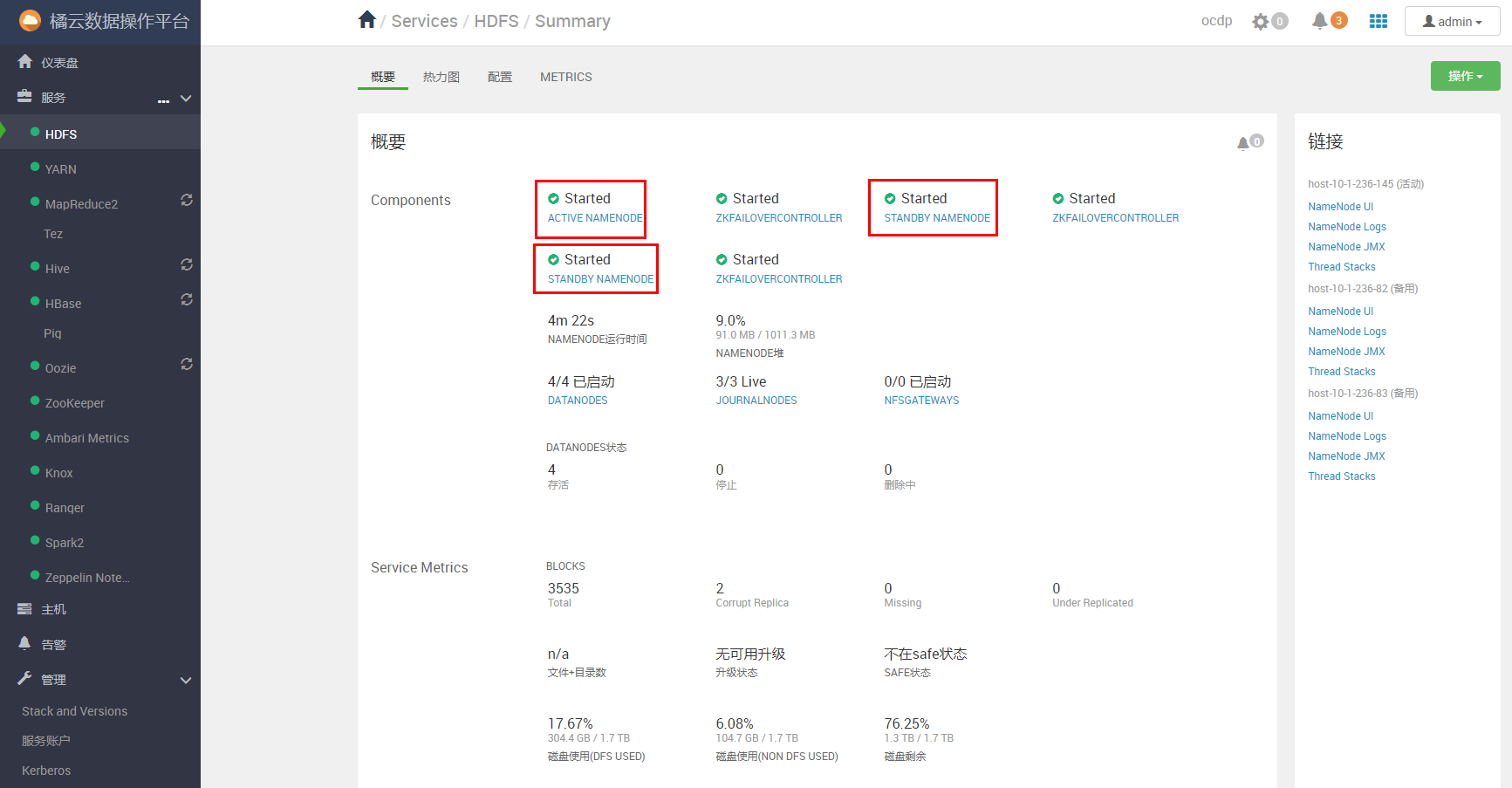
遇到问题:
5. NFS网关需要在ViewFS前工作(对统一命名空间的文件访问)
功能描述:
在之前集群使用过程中,为了使hdfs访问能够像linux一样简单。我们可以把hdfs通过nfs挂载到linux主机的一个目录,我们可以在这个目录下使用linux命令(部分)访问对应hdfs文件。但是当hdfs有多个namespace并且我们配置使用了viewFS后,就无法再使用该功能。
功能实现:
开启viewFS之前:
节点增加NFSGATEWAYS服务,启动。然后在该节点执行:
[root]> service nfs stop
[root]> service rpcbind stop
[root]> $HADOOP_HOME/bin/hdfs —daemon start portmap
[hdfs]$ $HADOOP_HOME/bin/hdfs —daemon start nfs3
[root]> rpcinfo -p $nfs_server_ip
[root]> showmount -e $nfs_server_ip
[root]> mount -t nfs -o vers=3,proto=tcp,nolock 10.1.236.82:/ /tmp/.hdfs-nfs
然后在主机/tmp/.hdfs-nfs目录就可以通过linux命令查看hdfs文件。
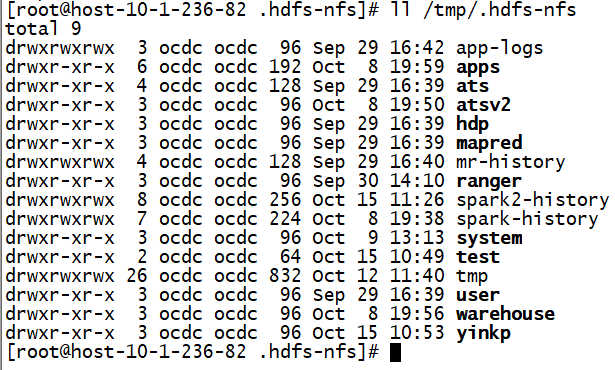
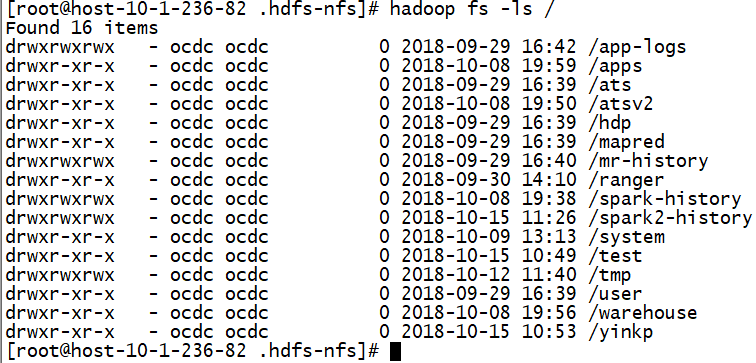
开启viewFS之后:

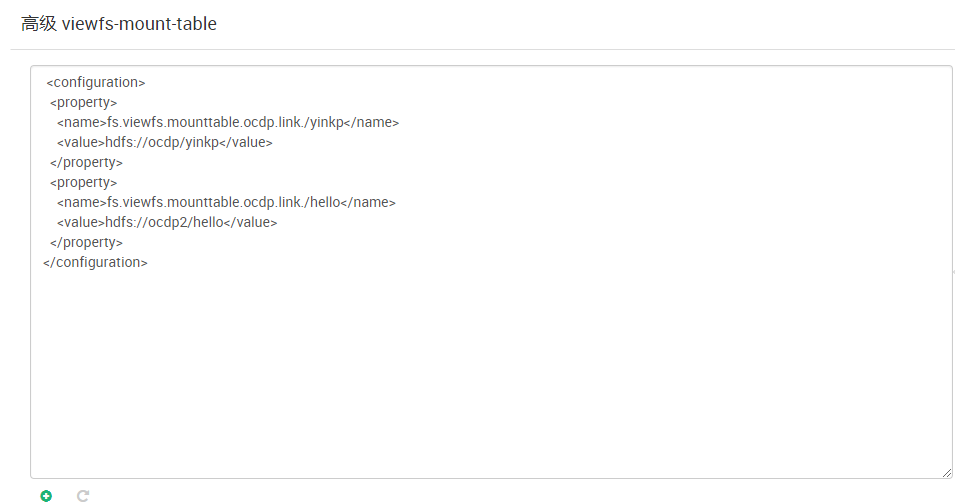

节点增加NFSGATEWAYS服务,启动。然后在该节点执行:
mount -t nfs -o vers=3,proto=tcp,nolock 10.1.236.82:/ /tmp/.hdfs-nfs

无法mount查看。
所以在未使用viewFS前可以正常使用hdfs的NFS网关,开启viewfs将不能使用hdfs的NFS网关。
遇到问题:
6. 通过WebHDFS API(HDFS-11394,HDFS-13512)公开加密区域和擦除编码区域
功能描述:
Webhdfs api可以查看文件&目录是否为公开加密区域和擦除编码区域。
功能实现:
curl http://10.1.236.82:50070/webhdfs/v1/tmp/data4?op=GETFILESTATUS


{“FileStatus”:{“accessTime”:0,”blockSize”:0,”childrenNum”:1,”ecBit”:true,”ecPolicy”:”RS-3-2-1024k”,”ecPolicyObj”:{“name”:”RS-3-2-1024k”,”cellSize”:1048576,”numDataUnits”:3,”numParityUnits”:2,”codecName”:”rs”,”id”:2,”extraOptions”:{}},”fileId”:230073,”group”:”ocdc”,”length”:0,”modificationTime”:1539070350398,”owner”:”ocdc”,”pathSuffix”:””,”permission”:”755”,”replication”:0,”storagePolicy”:0,”type”:”DIRECTORY”}}
遇到问题:
7. 擦除编码目录上的Hive支持(HDFS-7285)
功能描述:
由于hive的数据文件是存储在hdfs上的,所以hive文件也可以通过擦除编码方式存储,提高存储利用率。
功能实现:
hdfs ec -setPolicy -path /warehouse
如果hive中有表的话会有这个警告,对有文件不进行擦除编码。

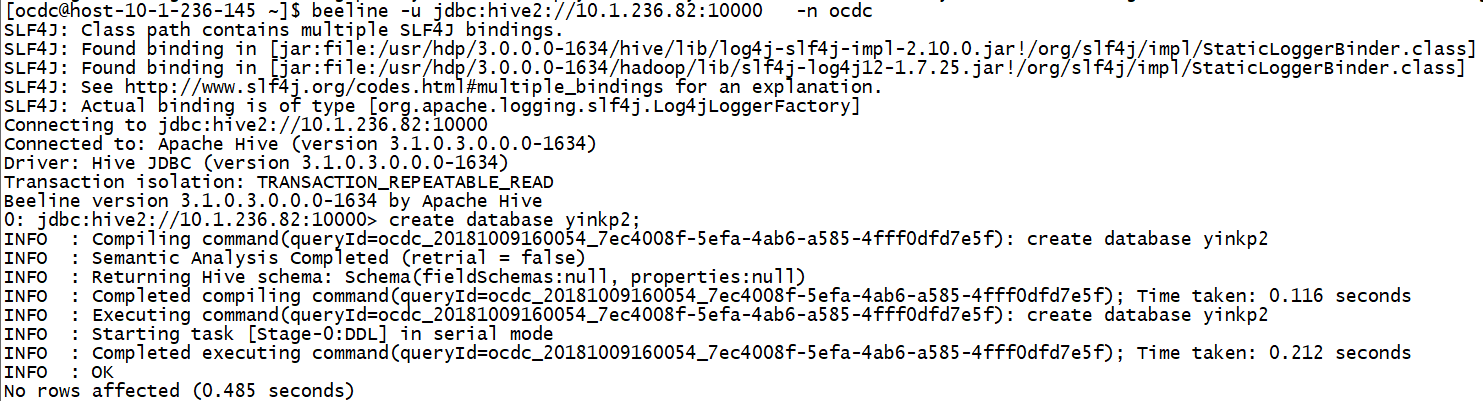
curl http://10.1.236.82:50070/webhdfs/v1//warehouse/tablespace/external/hive/yinkp2.db?op=GETFILESTATUS

遇到问题:

若有收获,就点个赞吧
0 人点赞
