1. ORC的结构化流支持
功能描述:
https://docs.hortonworks.com/HDPDocuments/HDP3/HDP-3.0.1/developing-spark-applications/content/accessing_orc_data_in_hive_tables.html
功能实现:
访问Hive表中的ORC数据
HDP上的Apache Spark支持优化行列式(ORC)文件格式。
ORC通过仅访问当前查询所需的列来减少I/O开销。它需要的搜索操作要少得多,因为单个行数据组中的所有列都存储在磁盘上。
Spark ORC数据源支持ACID事务,快照隔离,内置索引和复杂数据类型(如数组,映射和结构),并提供对ORC文件的读写访问。
它利用Spark SQL Catalyst引擎进行常规优化,例如列修剪,谓词下推和分区修剪。
spark ORC集成示例:
从Spark访问ORC文件,使用以下步骤从Apache Spark访问ORC文件。
——————————————————————
要开始使用ORC,您可以定义SparkSession实例:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder().getOrCreate()
import spark.implicits._
以下示例使用数据结构来演示使用复杂类型。Person结构数据类型具有名称,年龄和一系列联系人,这些联系人本身由姓名和电话号码定义。
步骤:
1、定义Contact和Person数据结构:
case class Contact(name:String,phone:String)
case class Person(name:String,age:Int,contacts:Seq [Contact])
2、创建100条Person记录:
val records = (1 to 100).map { i =>;
Person(s”name$i”, i, (0 to 1).map { m => Contact(s”contact$m”, s”phone_$m”) })
}
在物理文件中,这些记录以柱状格式保存。通过DataFrame API访问ORC文件时,您会看到行。
3、要将Person记录作为ORC文件写入名为“people”的目录,可以使用以下命令:
records.toDF().write.format(“orc”).save(“people”)
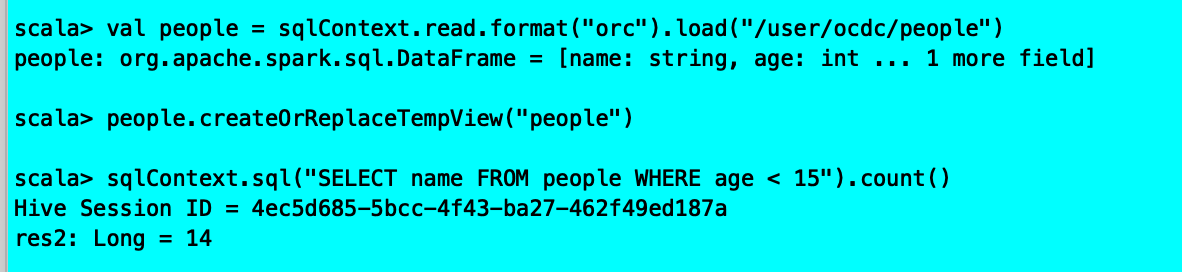
4、读回来的对象:
val people = sqlContext.read.format(“orc”).load(“/user/ocdc/people”)
5、要在将来的操作中重用,将新的“people”目录注册为临时表“people”:
people.createOrReplaceTempView(“people”)
6、注册临时表“people”后,您可以查询表中的列:
sqlContext.sql(“SELECT name FROM people WHERE age <15”).count()
结果:
在此示例中,物理表扫描仅在运行时加载列名称和年龄,而不从文件系统中读取联系人列。这提高了读取性能。
您还可以使用Spark DataFrameReader和 DataFrameWriter方法来访问ORC文件。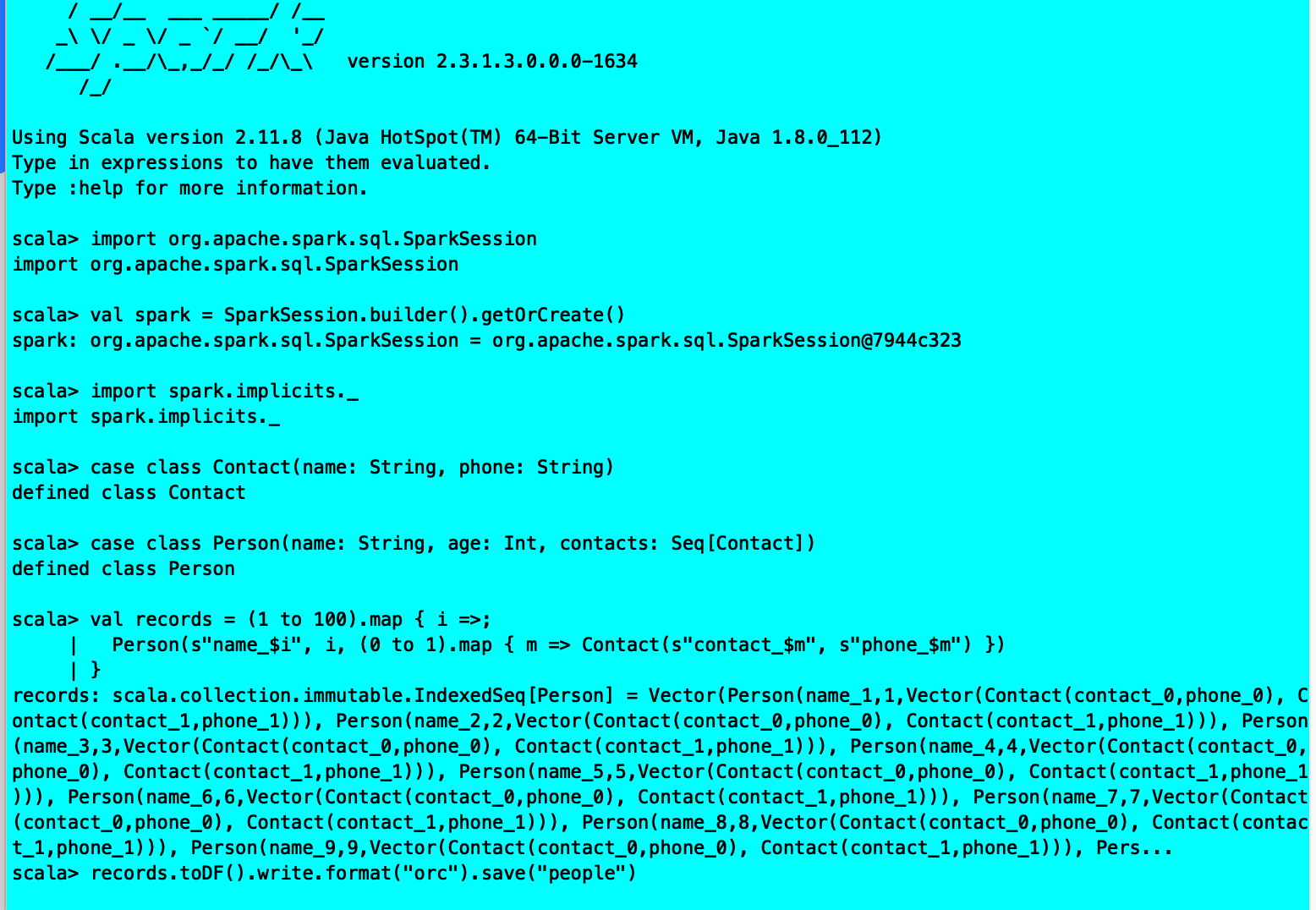

遇到问题:
2. 在History Server中启用安全性和ACL
https://docs.hortonworks.com/HDPDocuments/HDP3/HDP-3.0.1/configuring-spark/content/configuring_the_spark_history_server_kerberos.html
功能描述:
配置Spark history server
在启用Kerberos的群集上,Spark history server后台驻留程序必须具有Kerberos帐户和密钥表。
使用Ambari为Hadoop集群启用Kerberos时,Ambari会为Spark history server配置Kerberos,并自动为其创建Kerberos帐户和密钥表。
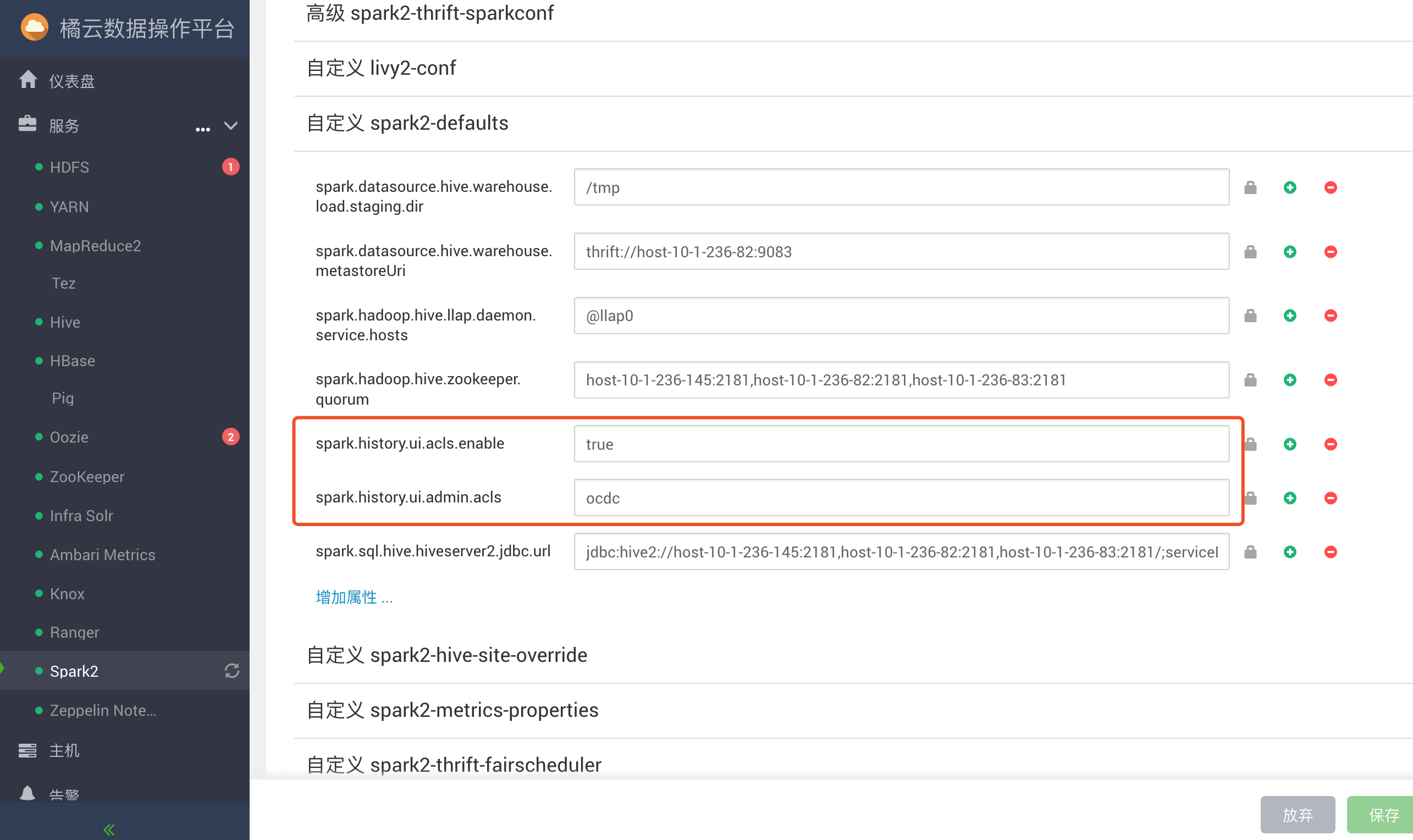
Ambari配置Spark history server权限,以便Admin用户可以查看所有Spark作业的历史记录,而其他用户只能查看他们提交的作业的历史记录。
要自定义这些设置,在Ambari中选择Spark2>configs>custom spark2-defaults
功能实现:
添加管理员用户:
1、在Ambari中选择Spark2>configs>custom spark2-defaults。
2、添加以下属性:
| Table 1. Apache Spark History Server ACL Settings | |
|---|---|
| Property | Value |
| spark.history.ui.acls.enable | true |
| spark.history.ui.admin.acls | Comma-separated list of Admin users. |
3、单击“ 保存”,然后重新启动Spark以及需要重新启动的任何其他服务。
/usr/hdp/3.0.0.0-1634/spark2/bin/spark-submit —class org.apache.spark.examples.SparkPi —executor-memory 500m —total-executor-cores 1 /usr/hdp/3.0.0.0-1634/spark2/examples/jars/spark-examples_2.11-2.3.1.3.0.0.0-1634.jar 100
遇到问题:
3. 直接支持Spark thrift服务器
功能描述:
https://docs.hortonworks.com/HDPDocuments/HDP3/HDP-3.0.1/configuring-spark/content/configuring_the_spark_thrift_server.html
Apache Spark Thrift服务器是一种允许JDBC和ODBC客户端运行Spark SQL查询的服务。Spark Thrift服务器是HiveServer2的变种。
1、为Spark Thrift服务器启用Spark SQL用户模拟
默认情况下,Spark Thrift服务器以运行Spark Thrift服务器的操作系统帐户的标识运行查询。在多用户环境中,查询通常需要在发起查询的最终用户的身份下运行; 此功能称为“用户模仿”。
启用用户模拟后,Spark Thrift服务器将使用提交用户运行Spark SQL查询。通过在与提交者关联的用户帐户下运行查询,Thrift服务器可以加强用户级权限和访问控制列表。Spark中缓存的关联数据仅对提交用户查询可见。
用户模拟可在文件或表级别对Spark SQL查询进行细粒度访问控制。
用户模拟功能由doAs属性控制。当doAs设置为true时,Spark Thrift服务器会启动按需Spark应用程序来处理用户查询。这些查询仅与来自同一用户的连接共享。Spark Thrift服务器将传入的查询转发到相应的Spark应用程序以执行,使Spark Thrift服务器非常轻量级:它仅作为转发请求和响应的代理。当Spark Thrift服务器关闭Spark应用程序的所有用户连接时,相应的Spark应用程序也会终止。
先决条件
Apache Spark支持Spark SQL用户模拟。
如果要启用基于存储的授权,在启用用户模拟之前,完成HD数据访问指南中的“配置基于存储的授权”中的说明。
在Ambari管理的群集上启用用户模拟
要在Ambari管理的群集上为Spark Thrift服务器启用用户模拟,请完成以下步骤:
1. 启用doAs支持。导航到“Advanced spark-hive-site-override”部分并进行设置hive.server2.enable.doAs=true。
2. 将DataNucleus jar添加到Spark Thrift服务器类路径。导航到“Custom spark-thrift-sparkconf”部分并按spark.jars如下方式设置属性:
spark.jars=/usr/hdp/current/spark-thriftserver/lib/datanucleus-api-jdo-3.2.6.jar,/usr/hdp/current/spark-thriftserver/lib/datanucleus-core-3.2.10.jar,/usr/hdp/current/spark-thriftserver/lib/datanucleus-rdbms-3.2.9.jar
3. (可选)禁用Spark Thrift服务器主服务器的Spark Yarn应用程序。导航到“Advanced spark-thrift-sparkconf”部分并进行设置 spark.master=local。当doAs=true时,查询是被Spark AM执行的,这可以防止启动spark-client HiveThriftServer2应用程序主机。当spark.master设置为local``时,SparkContext只使用本地计算机的驱动程序和执行任务。
(当Thrift服务器运行时doAs设置为false,您应该设置spark.master为yarn-client,以便查询执行利用群集资源。)
4. 重新启动Spark Thrift服务器。
自定义Spark Thrift服务器端口
默认的Spark Thrift服务器端口为10016.要指定其他端口,请在Ambari仪表板上选择 Spark> Config,然后选择Advanced spark-hive-site-override。将hive.server2.thrift.port属性设置为新端口号。单击“ 保存”,然后重新启动Spark以及需要重新启动的任何其他组件。
功能实现:
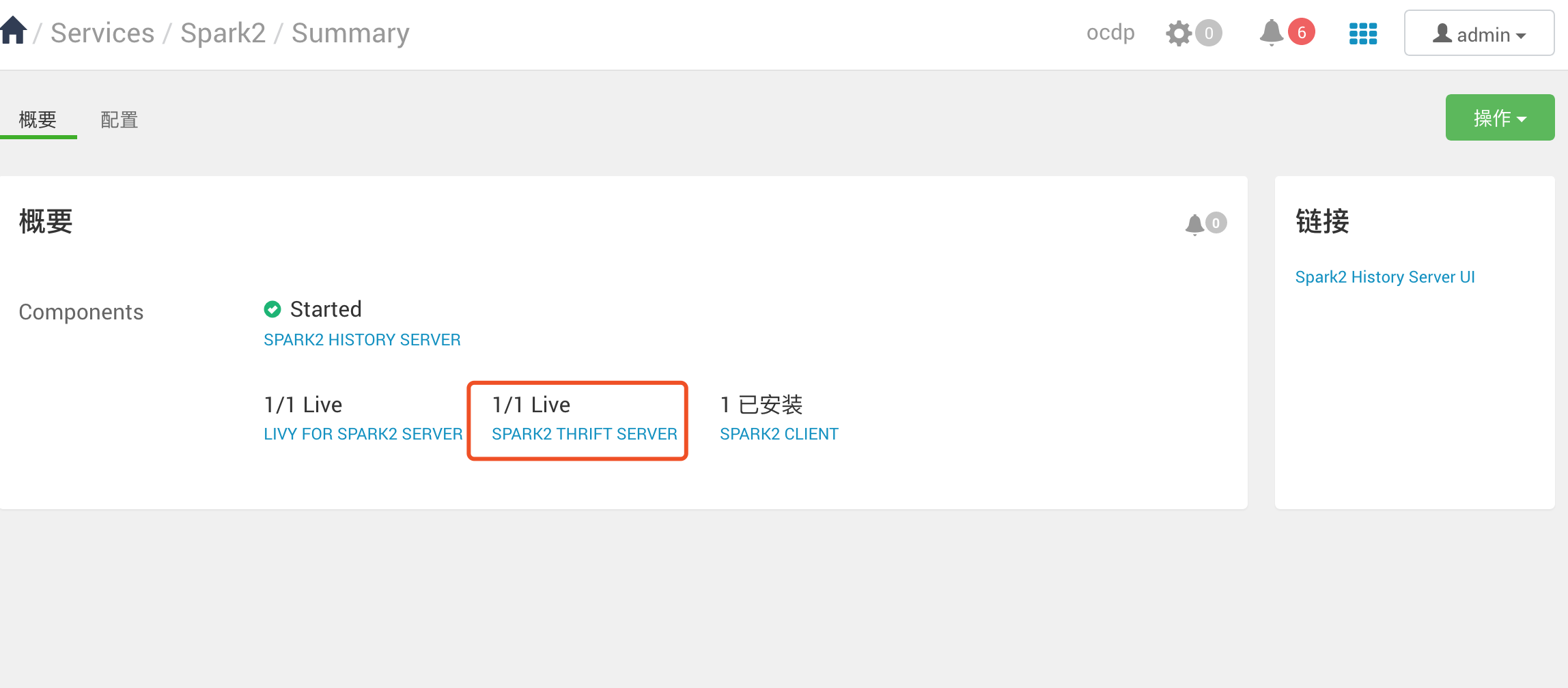
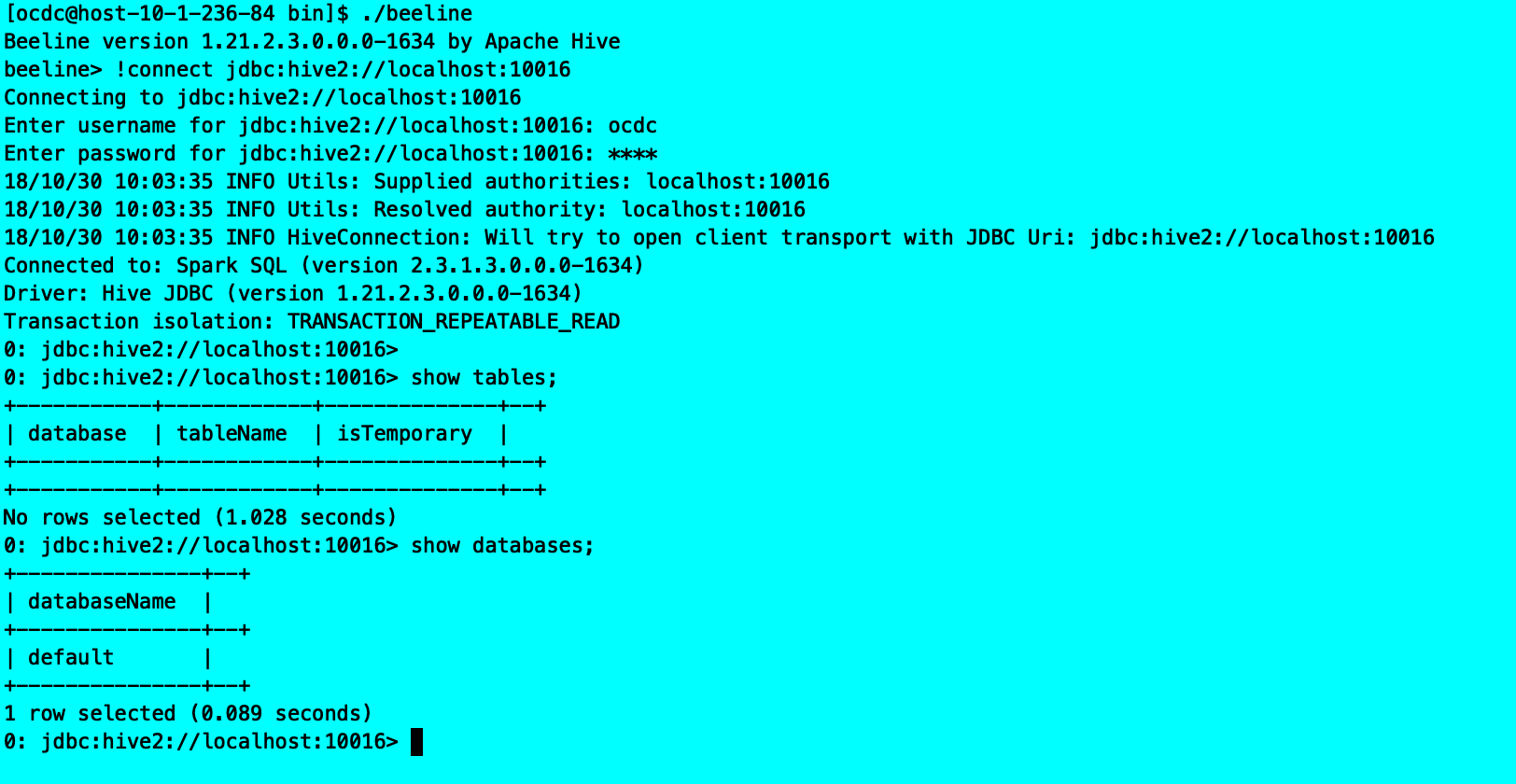
遇到问题:
4. Livy支持ACL
功能描述:
https://docs.hortonworks.com/HDPDocuments/HDP3/HDP-3.0.1/configuring-zeppelin/content/configuring_livy_on_an_ambari-managed_cluster.html
在Ambari管理的群集上配置Livy
本节介绍如何在Ambari管理的群集上配置Livy。
Livy是Apache Spark的代理服务; 它提供以下功能:
· Zeppelin用户可以通过安全连接在群集上启动Spark会话,提交代码并检索作业结果。
· 当Zeppelin在启用身份验证的情况下运行时,Livy会在创建会话时传播用户信息。Livy用户模拟提供了扩展的多租户体验,允许用户共享RDD和群集资源。多个用户可以访问自己的私人数据和会话,并在笔记本上进行协作。
注意:Livy支持Kerberos,但不需要它。
下图显示了Zeppelin,Livy和Spark之间的进程通信: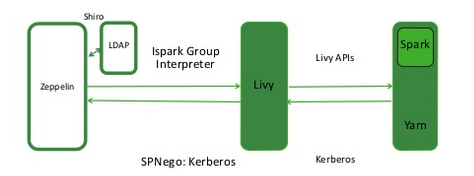
在Ambari管理的集群上,Livy与Spark一起安装。
以下部分介绍了几个可选的配置步骤。
启用Kerberos的群集
确保仅对Livy运行的组和主机启用访问。
检查Livy主机URL
1. 导航到Zeppelin Web UI中的Interpreter配置页面。
2. 在livy解释器部分中,确保该 zeppelin.livy.url属性包含完整的Livy主机名 - localhost必要时替换。
3. 向下滚动并单击“ 保存”。
| 注意 | |
|---|---|
| 在Ambari管理的群集上,您可以通过为Spark2 Server选择Spark2 > Summary > Livy for Spark2 Server. |
配置Livy模拟
1. 在Ambari仪表板上,选择Spark2> Configs。
2. 单击custom livy2-conf。
3. 确保livy.superusers列出 - 如果没有,请添加属性。
4. 设置livy.superusers为与Zeppelin关联的用户帐户zeppelin.livy.principal。
例如,如果 zeppelin.livy.principal是 zeppelin-sr1@example.com,则设置 livy.superusers为同一帐户, zeppelin-sr1@example.com。
配置Livy用户访问控制
您可以使用该livy.server.access-control.enabled属性配置Livy用户访问权限。
当此属性设置为时false,只有会话所有者和超级用户可以访问(查看和修改)给定会话。用户无法访问属于其他用户的会话。ACL被禁用,任何用户都可以向Livy发送任何请求。
如果将此属性设置为true,则启用ACL,并使用以下属性来控制用户访问:
· livy.server.access-control.allowed-users - 以逗号分隔的允许访问Livy的用户列表。
· livy.server.access-control.view-users - 以逗号分隔的用户列表,可以查看其他用户的信息,例如提交的会话状态和语句结果。
· livy.server.access-control.modify-users - 以逗号分隔的用户列表,具有修改其他用户会话的权限,例如提交语句和删除会话。
为Livy会话指定超时值。
默认情况下,Livy在会话不活动一小时后通过回收会话来保留群集资源。当Livy会话超时时,必须重新启动Livy解释器。
要使用Ambari指定更大或更小的值,请选择Spark2> Configs> Advanced livy2-conf,然后使用该livy.server.session.timeout属性指定超时(以毫秒为单位)(默认值为3600000或一小时)。
更改设置后重新启动Livy解释器。
如果您更改任何Livy解释器设置,请重新启动Livy解释器。导航到Zeppelin Web UI中的Interpreter配置页面。找到Livy解释器,然后单击restart。
验证Livy服务器是否正在运行
要验证Livy服务器是否正在运行,请在浏览器窗口中访问Livy Web UI。默认端口是8998:
http://
功能实现:

测试:
curl -X POST —data ‘{“kind”: “scala”,”proxyUser”: “ocdc”}’ -H “Content-Type: application/json” -H “X-XSRF-HEADER: valid” 10.1.236.84:8999/sessions
curl -X POST —data ‘{“kind”: “scala”,”proxyUser”: “ocdc”}’ -H “Content-Type: application/json” -H “X-Requested-By: ocdc” -H “X-XSRF-HEADER: valid” 10.1.236.84:8999/sessions
curl http://10.1.236.84:8999/sessions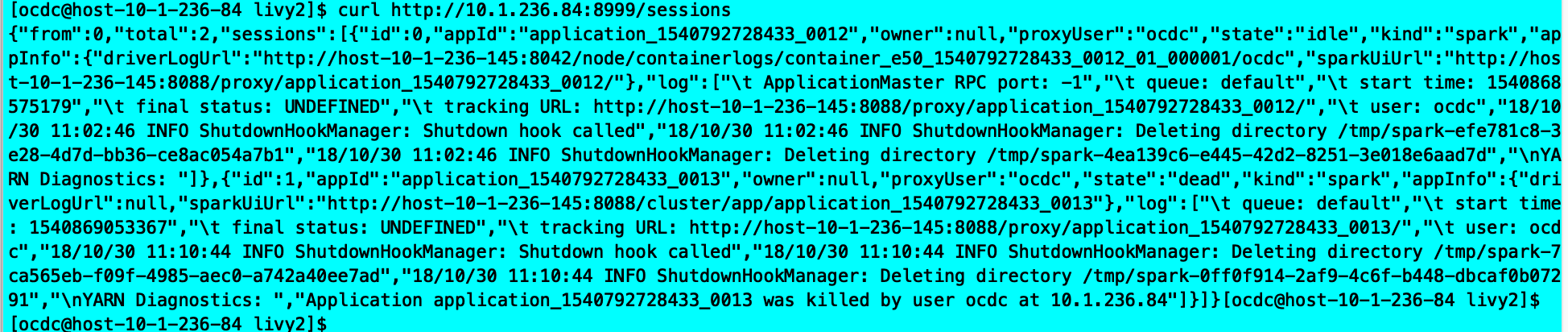
Livy页面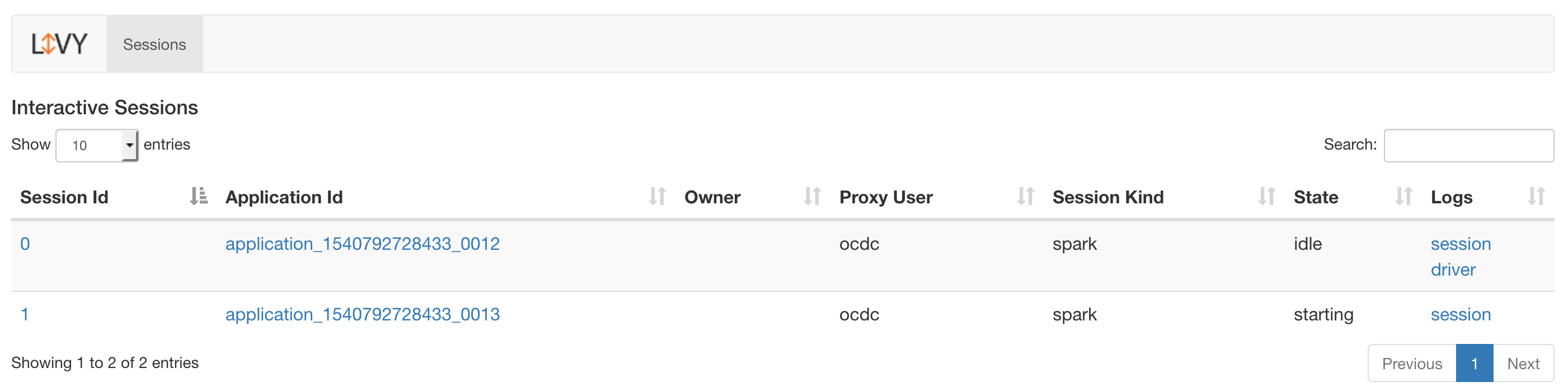
curl 10.1.236.84:8999/sessions/0/statements -X POST -H “X-Requested-By: ocdc” -H ‘Content-Type: application/json’ -d ‘{“code”:”var a = 1;var b=a+1”}’
curl localhost:8999/sessions/0/statements/2
遇到问题:

若有收获,就点个赞吧
0 人点赞
