1. LLAP 负载管理,LLAP支持多租户
功能描述:
LLAP的工作负载管理。您现在可以在多租户环境中运行LLAP,而无需担心资源竞争。官网链接:https://docs.hortonworks.com/HDPDocuments/HDP3/HDP-3.0.1/performance-tuning/content/hive_optimizing_data_warehouse.html
功能实现:
一、启用YARN抢占:
- Ambari中选择Services > YARN > Configs> Settings.
- 在YARN Features中设置Pre-emption为Enabled:
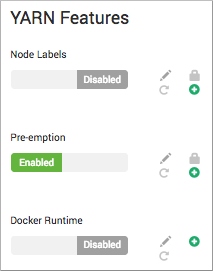
点击Save.
二、启动交互式查询:Ambari中选择Hive>Configs
- 选择Settings>Interactive Query 设置为 Enable

- 在Select HiveServer Interactive Host中,选择要托管HiveServer Interactive的服务器。

三、配置llap队列
通过将Hive服务指向YARN队列来设置名为llap的交互式查询队列,设置启用Hive LLAP所需的yarn-site.xml属性。
1.在Ambari中,从**“视图”中选择“ 服务” >“ YARN” >“ YARN**队列管理器”。
2.添加名为llap的队列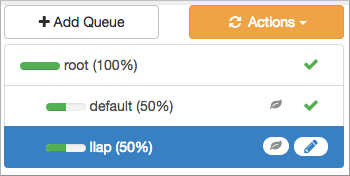
如果llap队列已停止,将状态更改为running。设置llap队列容量和最大容量。
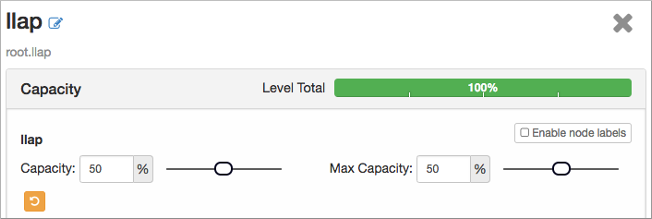
在Add Queue下的队列列表中选择llap queue(50%),在Resources中,将priority设置为大于0。
3.在Ambari中,选择服务> YARN > 配置> 高级
在Custom yarn-site中,添加以下属性yarn.resourcemanager.monitor.capacity.preemption.natural_termination_factor(value = 1)和yarn.resourcemanager.monitor.capacity.preemption.total_preemption_per_round(如下所述)。
通过将1除以节点数来计算每轮总抢占的值,输入小数值。
例如,群集有20个节点,则将1除以20并输入0.05作为此属性设置的值。
4.在Ambari中,选择Hive > Configs。在Interactive Query Queue中,llap如果队列显示为选择,选择该队列: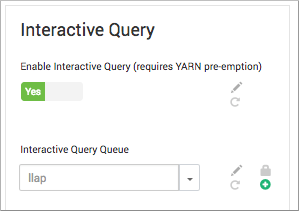
四、配置LLAP属性: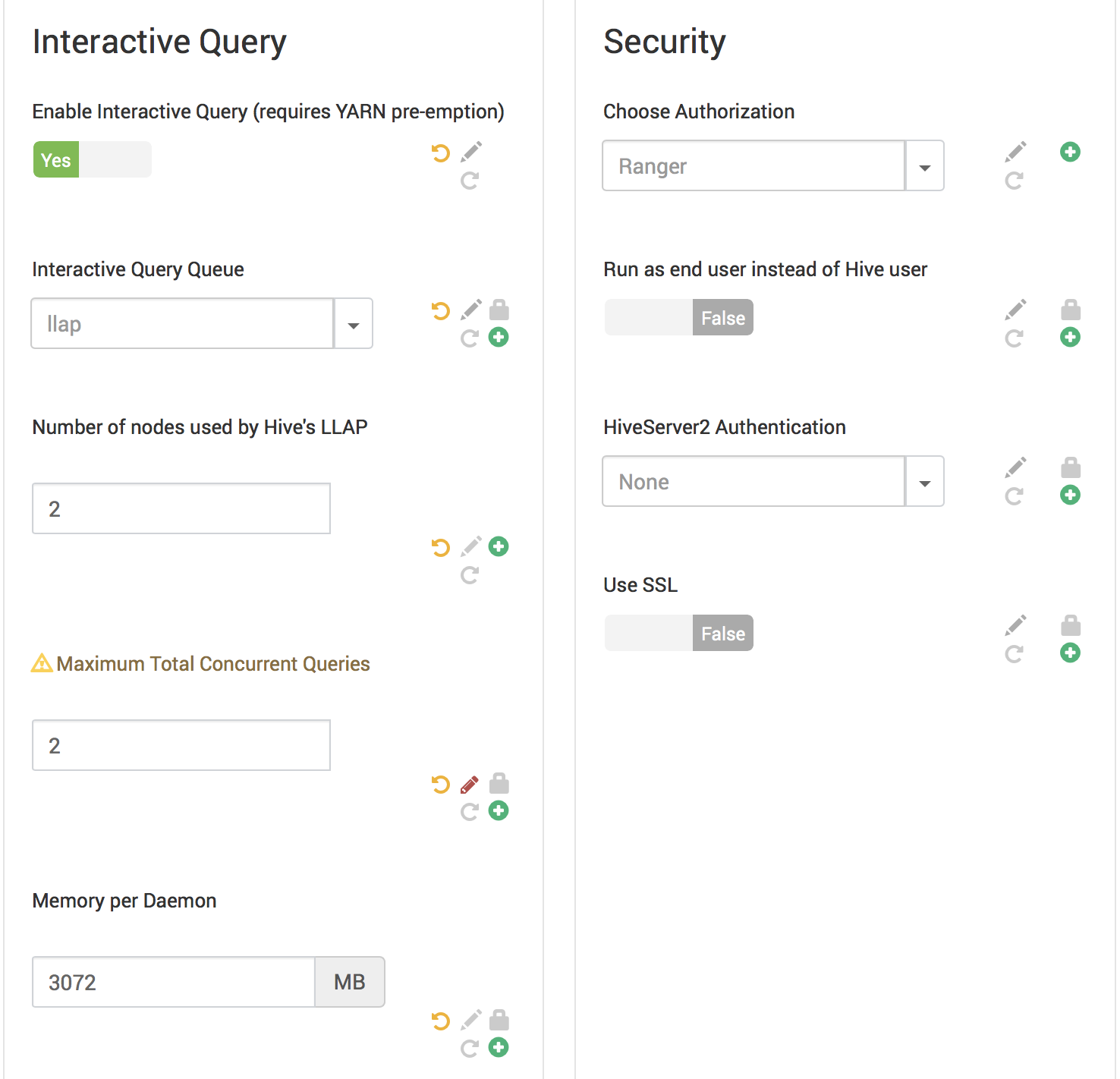
1.将Hive LLAP使用的节点数设置为2.
2.接受最大总并发查询数。
3.更改其他设置以适合您的环境,或接受默认值(一般情况默认值是比较好的选择)。
五、保存LLAP设置并重新启动服务
1.单击向导底部的“保存”。
2.如果显示“从属配置”窗口,请查看建议并接受或拒绝建议。
3.导航到每个服务,从Ambari服务下列出的第一个服务开始,然后根据需要重新启动任何服务。
4.选择“ 服务” >“ Hive” >“ 摘要”,验证是否已设置并启动HiveServer Interactive。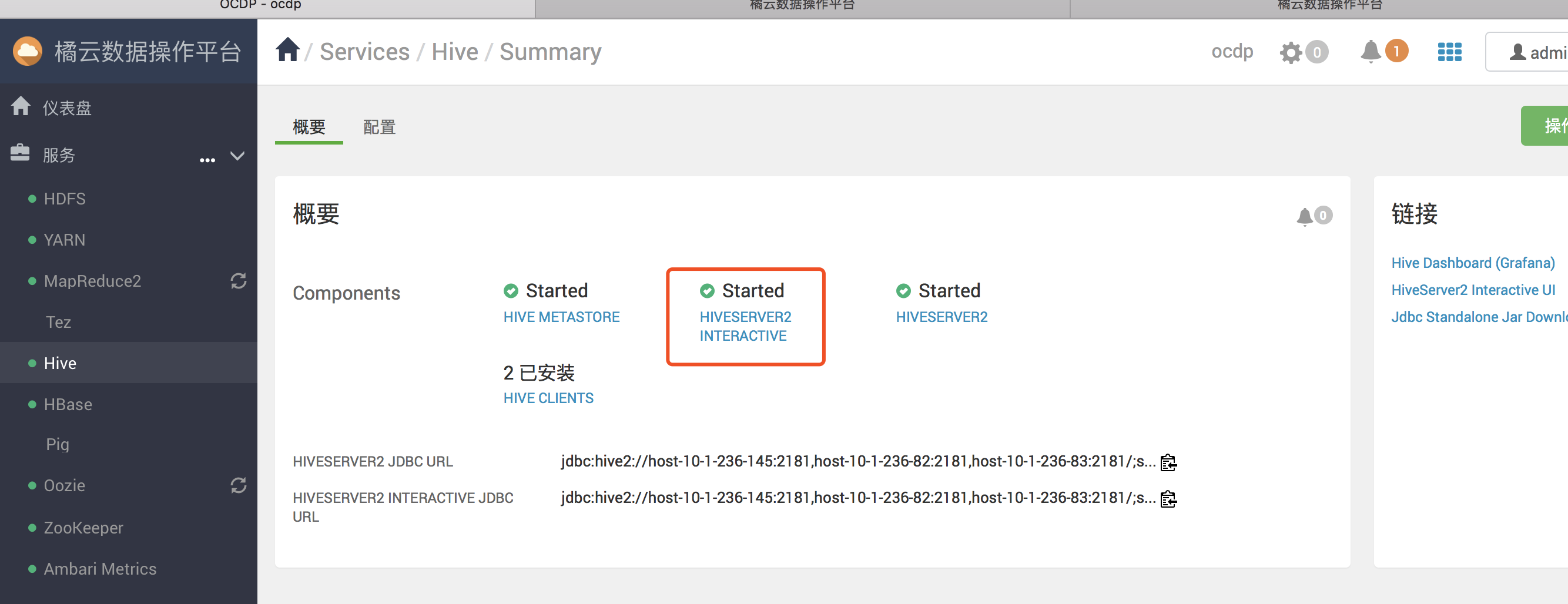
5.测试
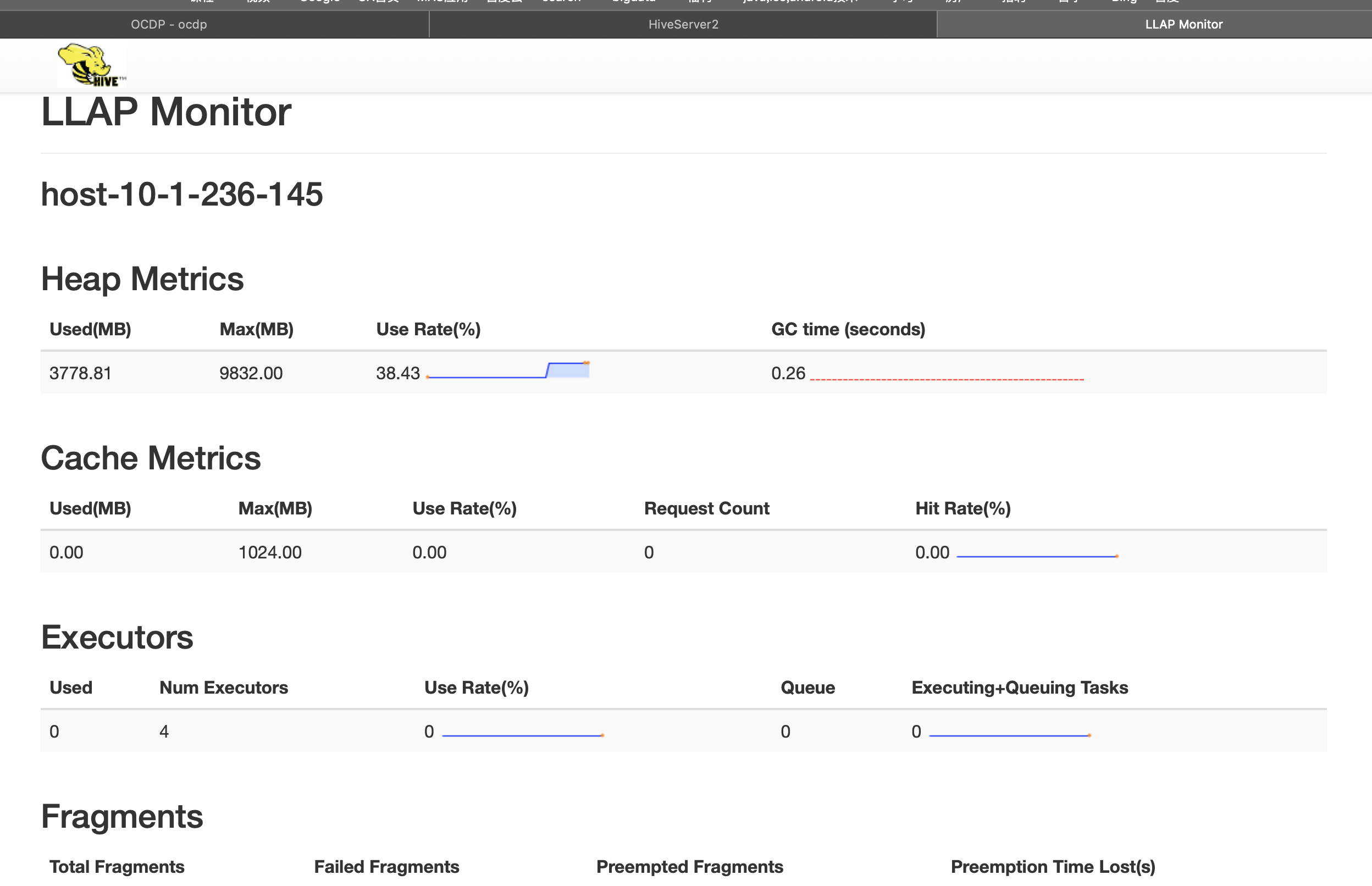
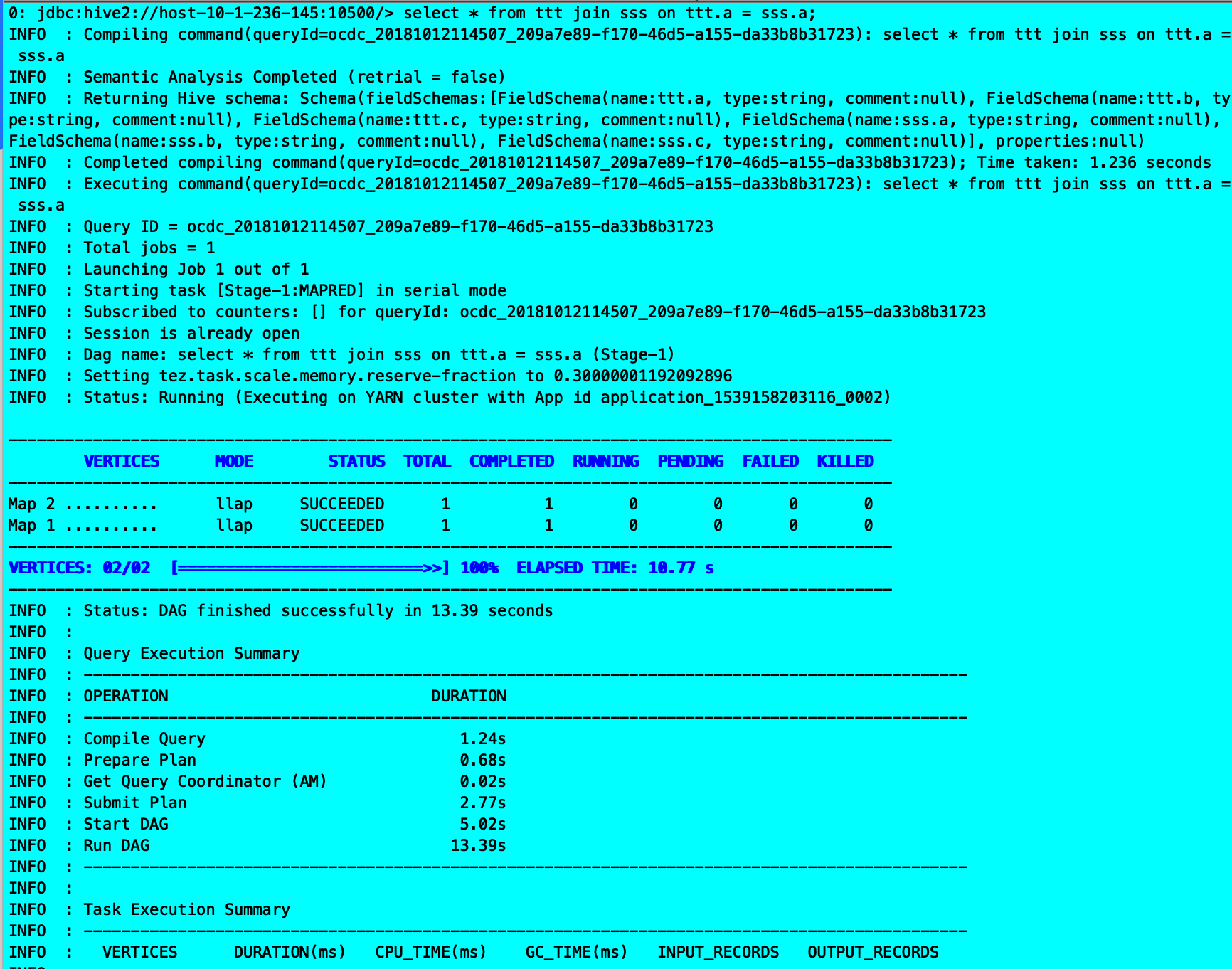
遇到问题:

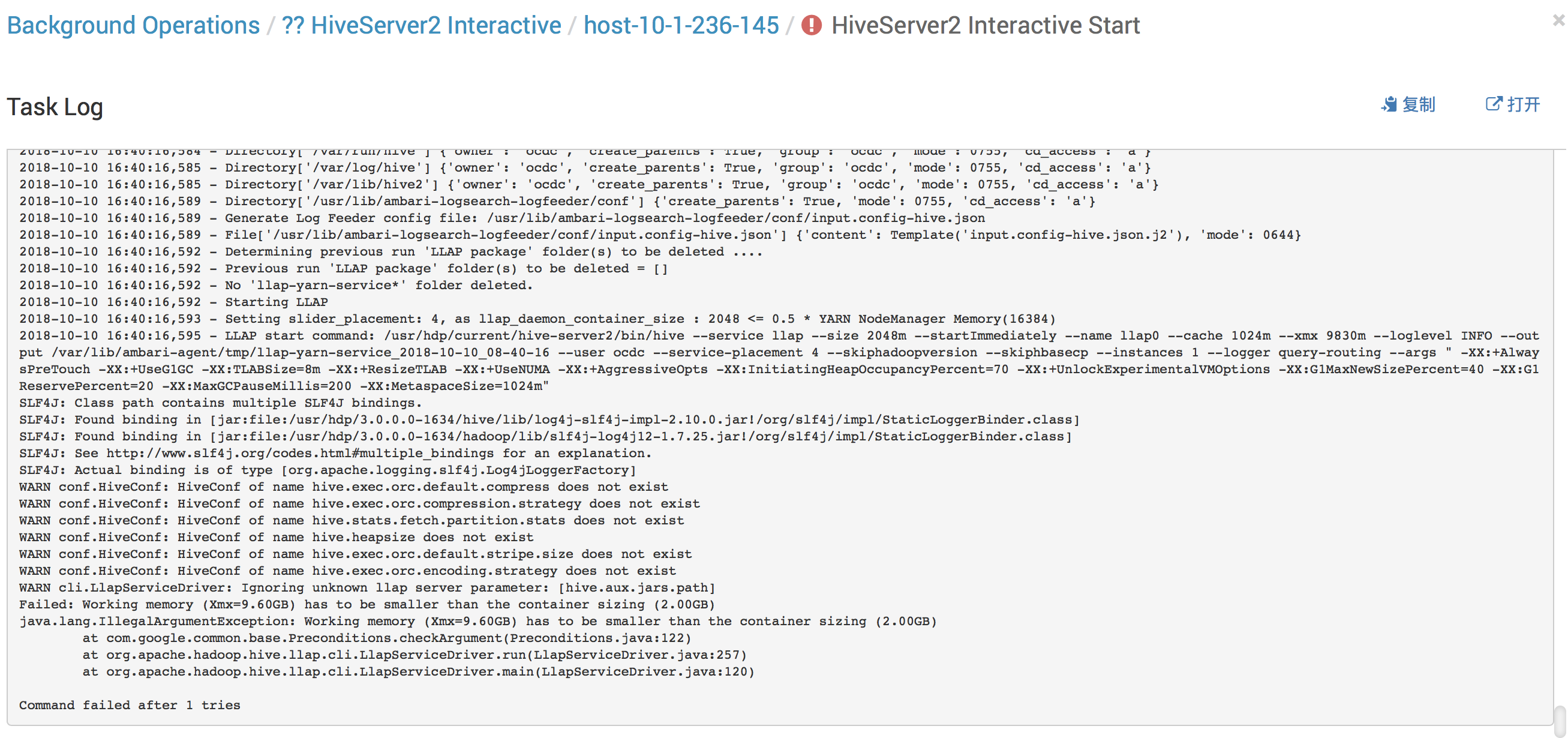
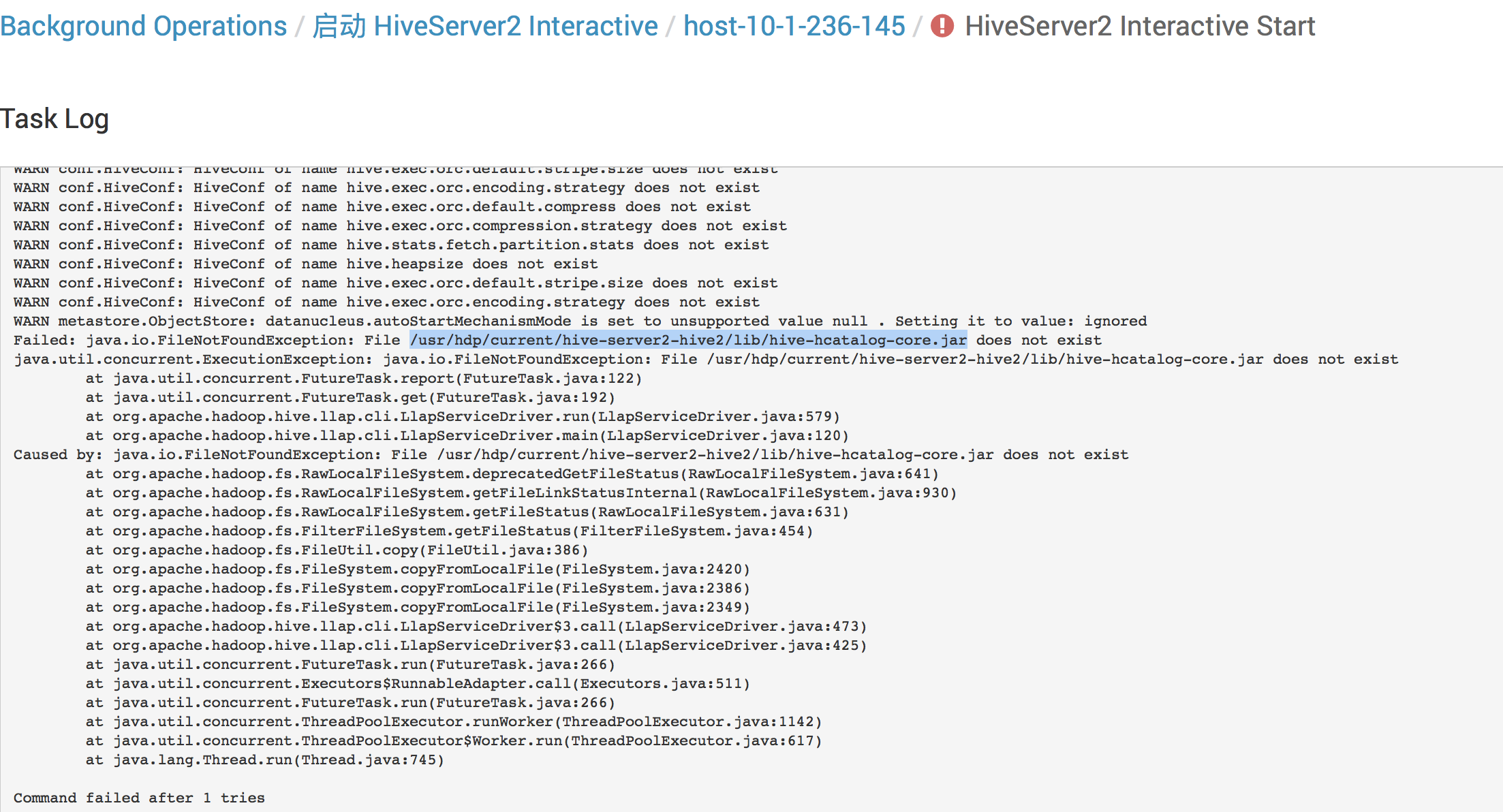
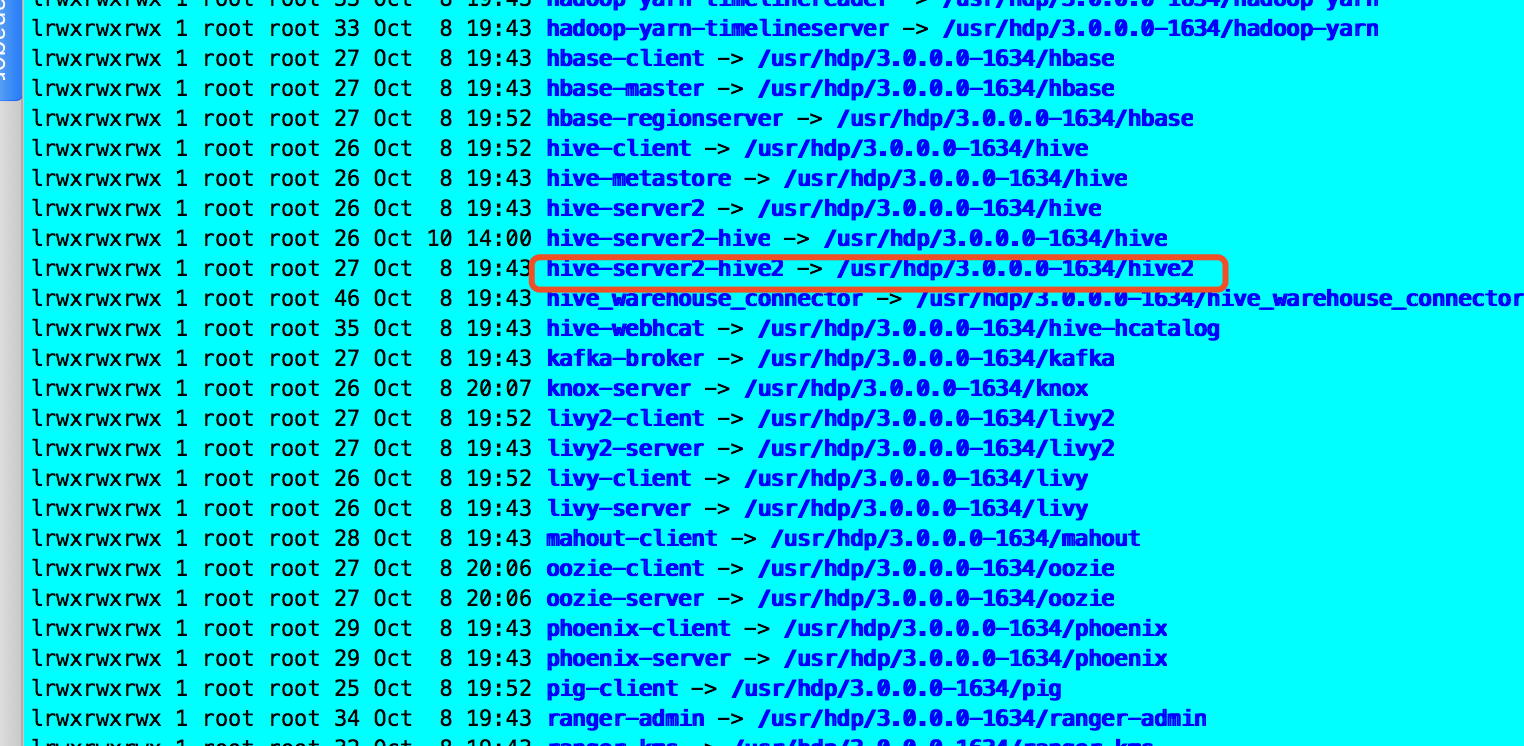
rm -rf /usr/hdp/current/hive-server2-hive2
ln -s /usr/hdp/3.0.0.0-1634/hive /usr/hdp/current/hive-server2-hive2
2. ACID v2
默认情况下,ACID v2和ACID处于启用状态。ACID v2在存储格式和执行引擎方面都有性能提升,与非ACID表相比,性能相同或更好。默认情况下启用ACID on以允许完全支持数据更新。官网链接:https://docs.hortonworks.com/HDPDocuments/HDP3/HDP-3.0.1/managing-hive/content/hive_acid_operations.html
功能描述:
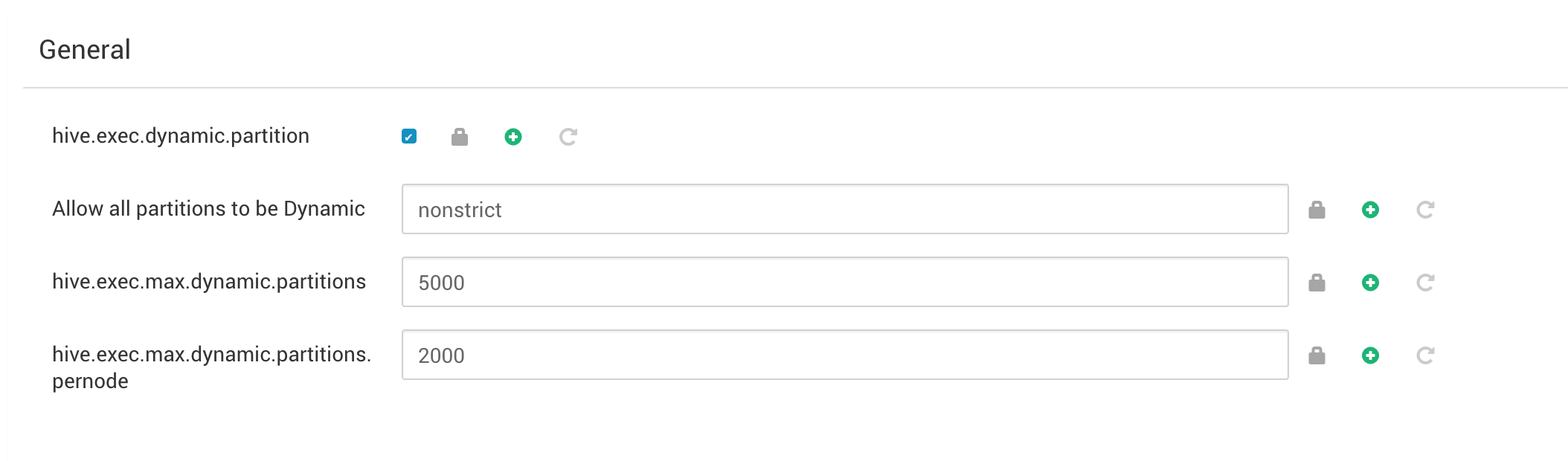
要在事务应用程序中包含INSERT,UPDATE和DELETE语句,必须将动态分区模式设置为nonstrict。
以下参数的默认限制已更改,以满足您的需求:
· hive.exec.max.dynamic.partitions
· hive.exec.max.dynamic.partitions.pernode
1. 导航到hive-site.xml,然后打开它进行编辑。
2. 更改hive.exec.dynamic.partition.mode到nonstrict
功能实现:
create table eee
(a STRING,b STRING,c STRING)
clustered by (a) into 3 buckets stored as orc TBLPROPERTIES (‘transactional’=’true’);
insert into eee values(‘111’,’222’,’333’);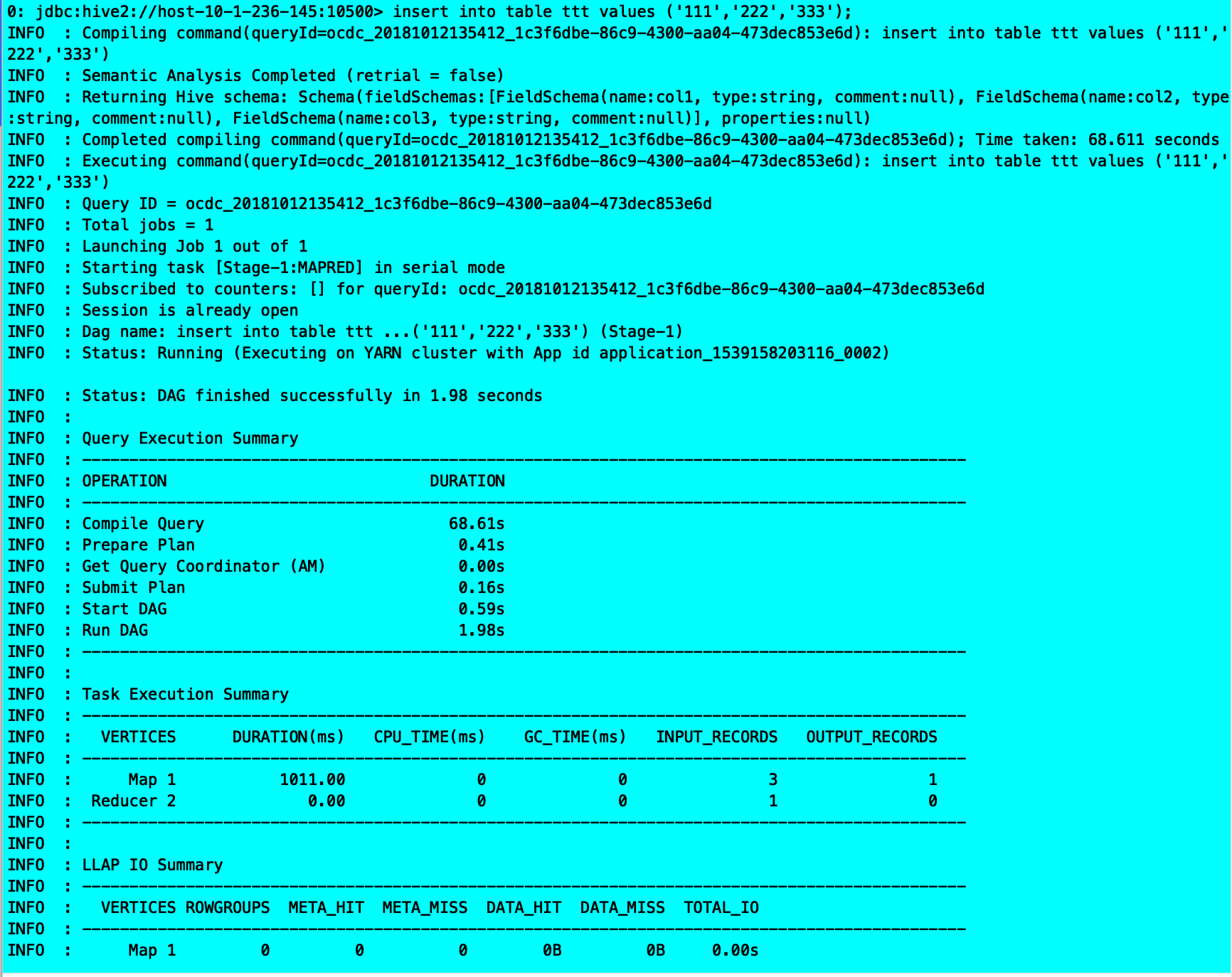
update eee set b=’121’ where a=’113’;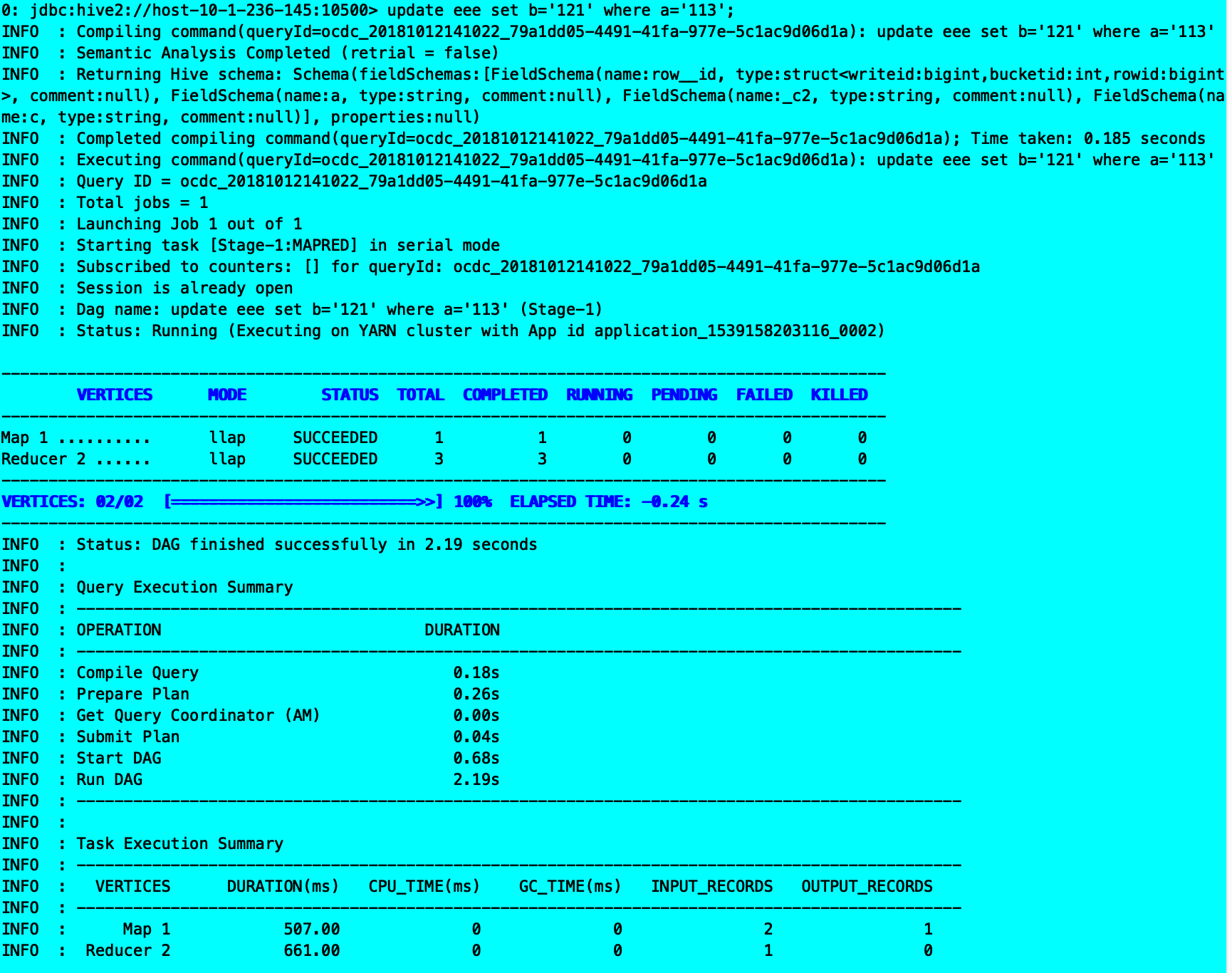
delete from eee where a=’111’;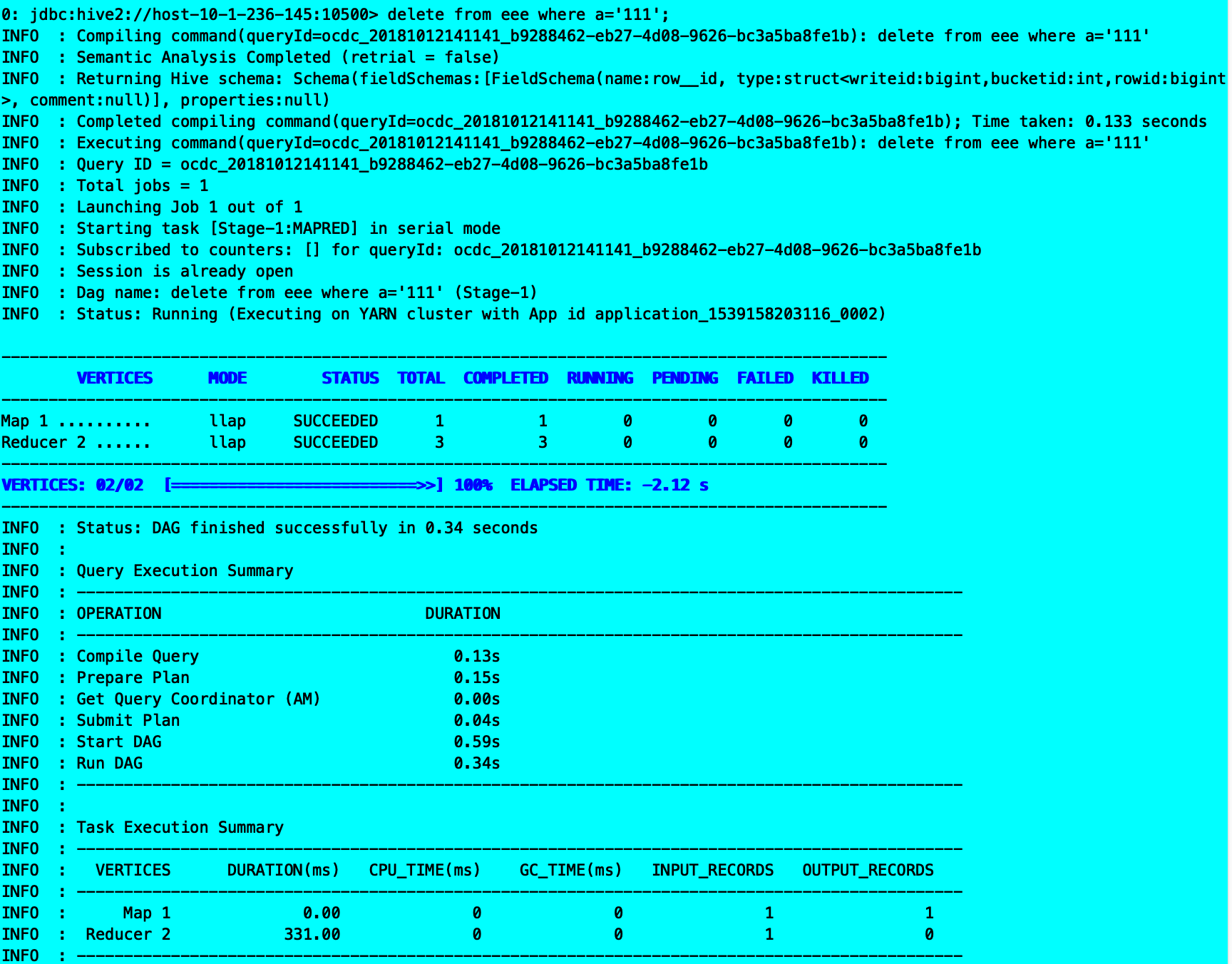
遇到问题:
3. 物化视图导航
Hive的查询引擎现在支持物化视图。查询引擎将在可用时自动使用实体化视图来加快查询速度。
功能描述:
在Apache Hive 3.0 里创建一个物化视图的语法规范如下:
功能实现:
create view tv as
select a, b, c, x, y, z from eee join xxx on a=x;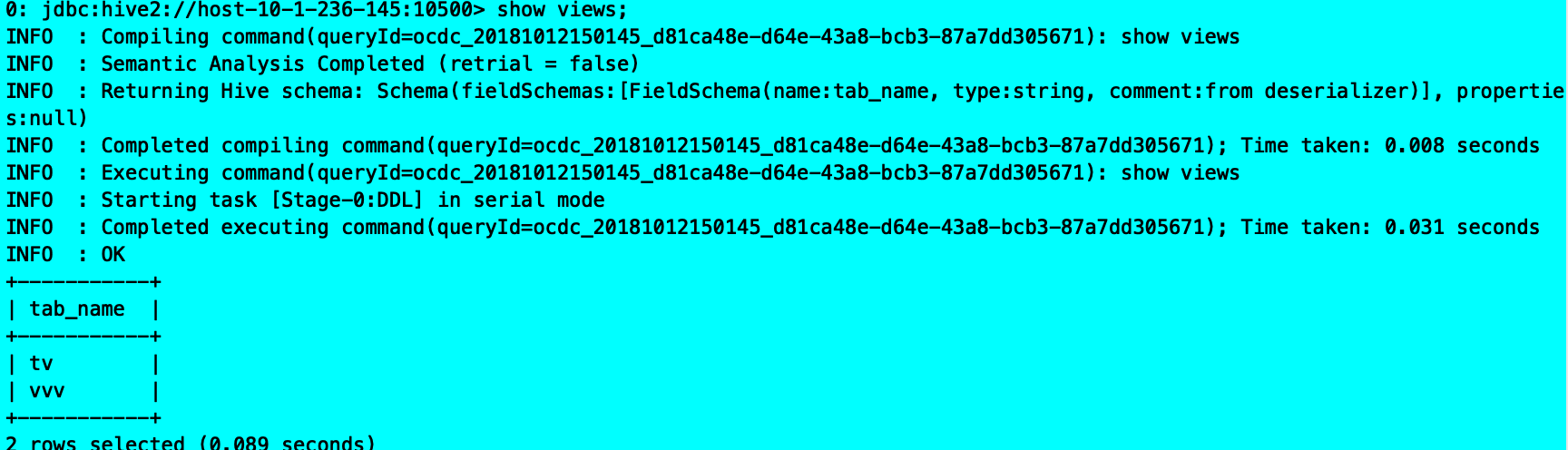
select a, x from eee join xxx on a=x;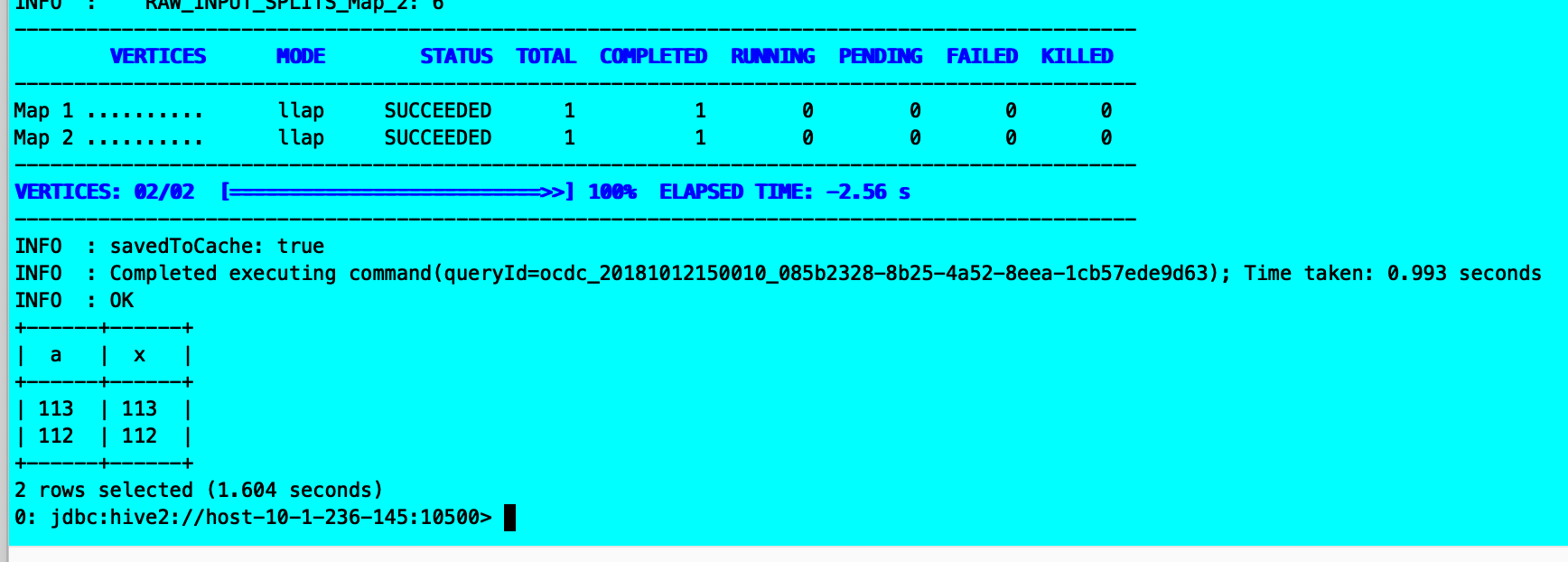
select a,x from tv where a=x;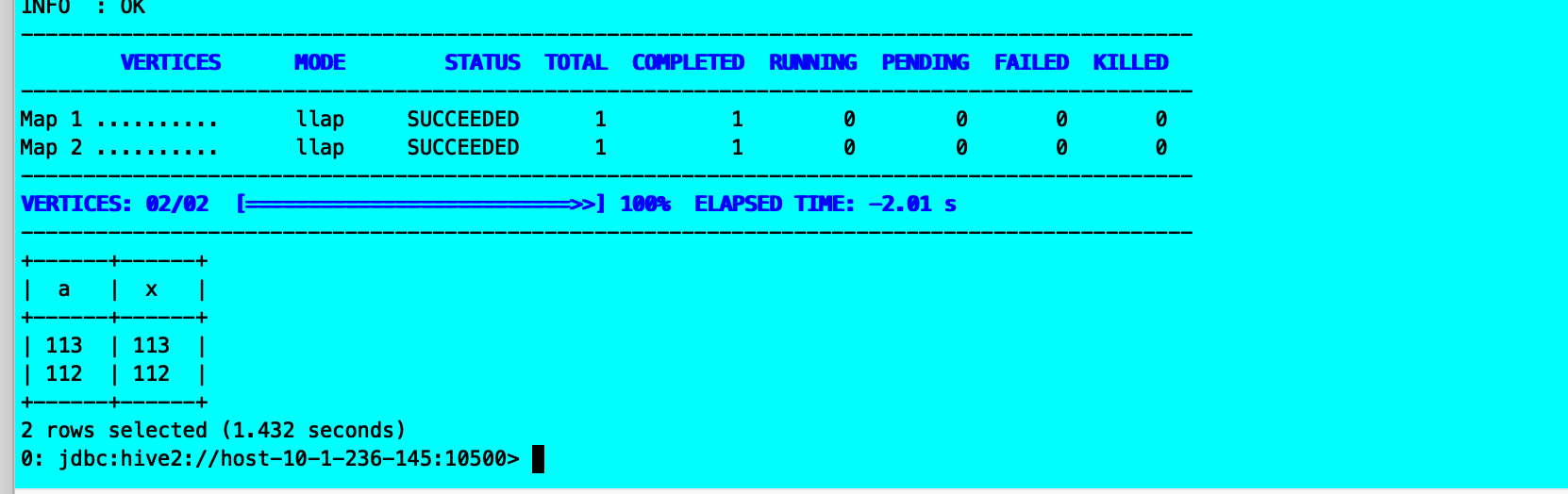
遇到问题:
4. 信息架构
Hive现在直接通过Hive SQL接口公开数据库的元数据(表,列等)
功能描述:
https://docs.hortonworks.com/HDPDocuments/HDP3/HDP-3.0.1/configuring-hive/content/hive_configure_the_apache_hive_metastore.html
功能实现:
遇到问题:
5. Hive Warehouse Connector
用于Spark的Hive Warehouse Connector。Hive Warehouse Connector允许您将Spark应用程序与Hive数据仓库连接。连接器自动处理ACID表。
功能描述:
https://docs.hortonworks.com/HDPDocuments/HDP3/HDP-3.0.1/integrating-hive/content/hive_configure_a_spark_hive_connection.html
使用Hive Warehouse Connector,可以使用低延迟分析处理(LLAP)从Apache Hive读取和编写Apache Spark DataFrames和Streaming DataFrame。
Apache Ranger和HiveWarehouseConnector库提供对Hive中Spark数据的行和列的细粒度访问。
Hive Warehouse Connector支持以下应用程序:
· Spark-shell
· PySpark
· spark-submit脚本
可以使用HiveWarehouseConnector从Spark访问ACID和外部表。以下列表描述了Hive Warehouse Connector支持的一些操作:
· 描述表
· 为ORC格式的数据创建表
· 选择Hive数据并检索DataFrame
· 批量编写DataFrame到Hive
· 执行Hive更新语句
· 从Hive读取表数据,在Spark中转换它,并将其写入新的Hive表
· 使用HiveStreaming将数据帧或Spark流写入Hive
测试步骤:
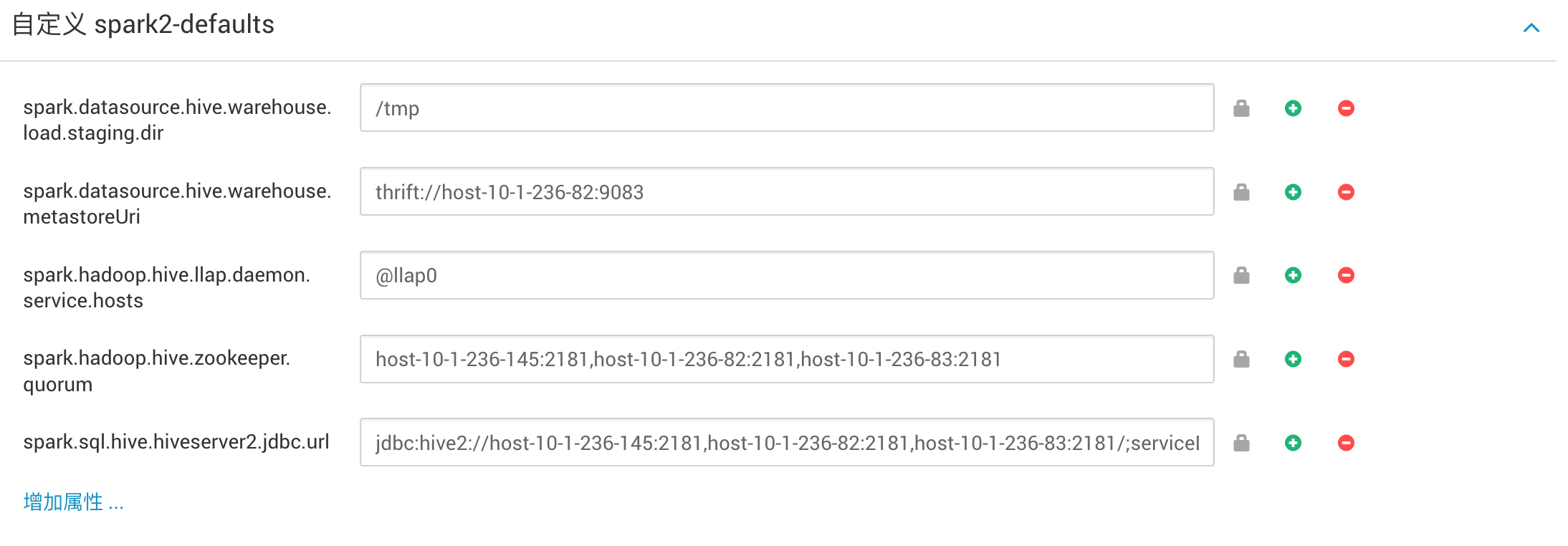
· Apache Spark-Apache Hive连接配置
您可以在Ambari中配置Spark属性,以使用Hive Warehouse Connector访问Hive中的数据。
配置属性:spark-2-defaults在Ambari中添加几个Spark属性才能使用Hive Warehouse Connector访问Hive中的数据。或者,可以为每个作业提供配置using —conf。
| 属性 | 描述 | 评论 |
|---|---|---|
| spark.sql.hive.hiveserver2.jdbc.url | HiveServer2 Interactive的URL | 在Ambari中,从Hive Summary> HIVESERVER2 INTERACTIVE JDBC URL复制值。 |
| spark.datasource.hive.warehouse.metastoreUri | Metastore的URI | 从hive.metastore.uris复制值。 |
| spark.datasource.hive.warehouse.load.staging.dir | 用于批量写入Hive的HDFS临时目录 | 例如, /tmp |
| spark.hadoop.hive.llap.daemon.service.hosts | LLAP服务的应用程序名称 | 从Advanced hive-interactive-site>复制值hive.llap.daemon.service.hosts |
| spark.hadoop.hive.zookeeper.quorum | LLAP使用的Zookeeper主机 | 从Advanced hive-site复制值hive.zookeeper.quorum |
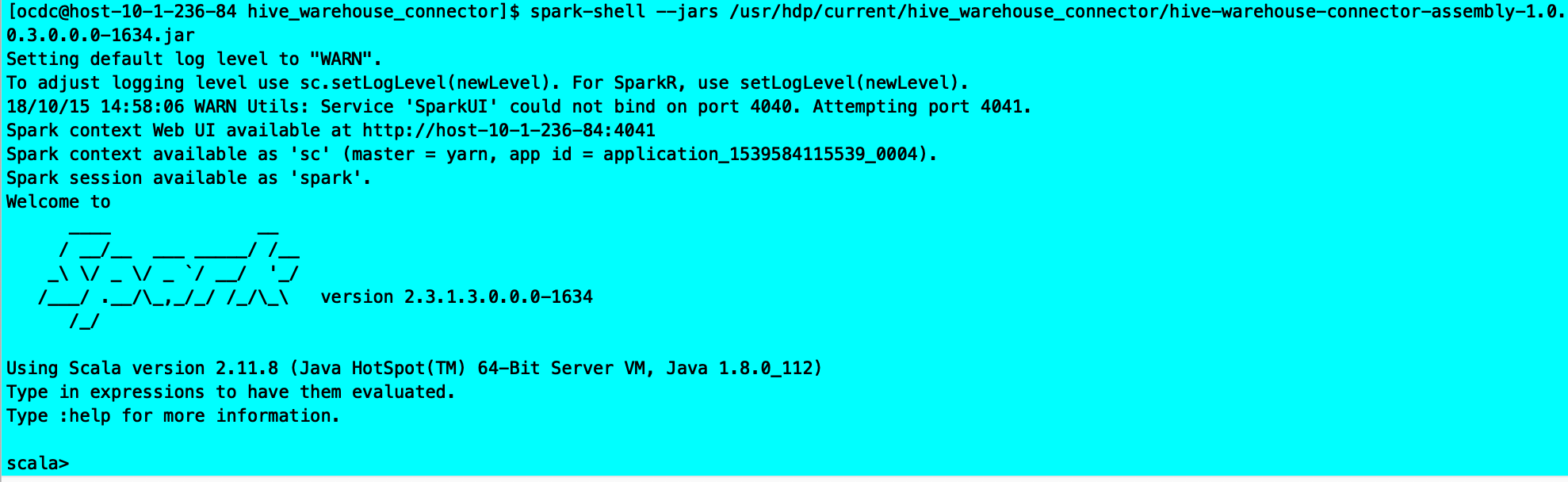
· 提交Hive Warehouse Connector Scala或Java应用程序
您可以提交基于HiveWarehouseConnector库的应用程序,以便在Spark Shell,PySpark和spark-submit。
步骤:
- 找到hive-warehouse-connector-assembly jar /usr/hdp/current/hive_warehouse_connector/。
- 使用连接器jar添加到应用程序提交 —jars。
spark-shell —jars /usr/hdp/current/hive-warehouse-connector/hive-warehouse-connector-assembly-
功能实现:


遇到问题:
6. JDBC存储连接器
您现在可以将任何JDBC数据库的表映射到Hive,并与其他表一起查询这些表
功能描述:
https://docs.hortonworks.com/HDPDocuments/HDP3/HDP-3.0.1/hive-workload-commands/content/hive_create_mapping.html
创建映射
使用此命令创建自动将查询路由到特定池的映射。
CREATE MAPPING语法
CREATE{USER|GROUP| APPLICATION }MAPPING`'entity_name' IN planname { TO pool_path | UNMANAGED } [ WITH ORDER num ]<br /> <br />entity_name:JDBC连接用户,JDBC连接用户组或JDBC应用程序名称<br />PLAN_NAME:资源计划名称<br />pool_path:查询池名称的层次结构,以点表示法表示<br />NUM:整数<br />创建映射示例<br />CREATE GROUP MAPPING 'students' IN rp1 TO pool1 WITH ORDER 1<br />CREATE GROUP MAPPING 'teachers' IN rp1 TO pool2 WITH ORDER 3<br />CREATE APPLICATION MAPPING 'app1' IN rp1 TO pool3 WITH ORDER 2<br />假设默认池是pool4,则会发生以下映射:<br />来自小组学生用户的查询将转到pool1。<br />使用app1的用户访问pool2,除非他们是小组学生。<br />组教师中的用户转到pool3,除非他们也是小组学生或正在使用app1。<br />不在学生或教师中且未使用应用程序app1的用户转到pool4。<br />创建映射描述<br />可以基于实体名称标识的用户,组或应用程序创建映射。将用户,组或应用程序实体映射到池会将查询从这些实体路由到池。池中的查询处于工作负载管理之下。<br />**用户或组映射**<br />作为管理员,您可以为特定用户或组配置有效的非应用程序映射。池必须存在。或者,您可以设置hive.server2.wm.allow.any.pool.via.jdbc为true。例如,每个映射到单独池的两个不同组中的用户可以显式地向任一池提交查询,而不管应用的相应映射的优先级如何。<br />工作负载管理基于授权在集群上的HDFS组配置上获取组或用户。默认情况下,这些是Apache Hadoop用户和组,但您可以配置轻量级目录协议(LDAP)和其他机制。<br />**应用映射**<br />要基于应用程序创建映射,请使用以下名称之一:<br />applicationNameJDBC连接字符串中的属性<br />使用SetClientInfo JDBC API和ApplicationName密钥。<br />要配置对任何池的显式查询,请通过wmPool`JDBC连接字符串中的属性使用多个映射 。
非托管查询
来自未_映射到池的用户,组或应用程序的查询是不受管理的。查询不在工作负载管理之下。
订购规则
可选的WITH ORDER子句确定规则的优先级。如果应用多个规则(例如,用户规则和组规则或多个组),则最低有序规则优先。如果未指定排序(或相同),则用户规则优先于应用程序规则,应用程序规则优先于组规则。具有相同优先级的组规则的顺序未定义。
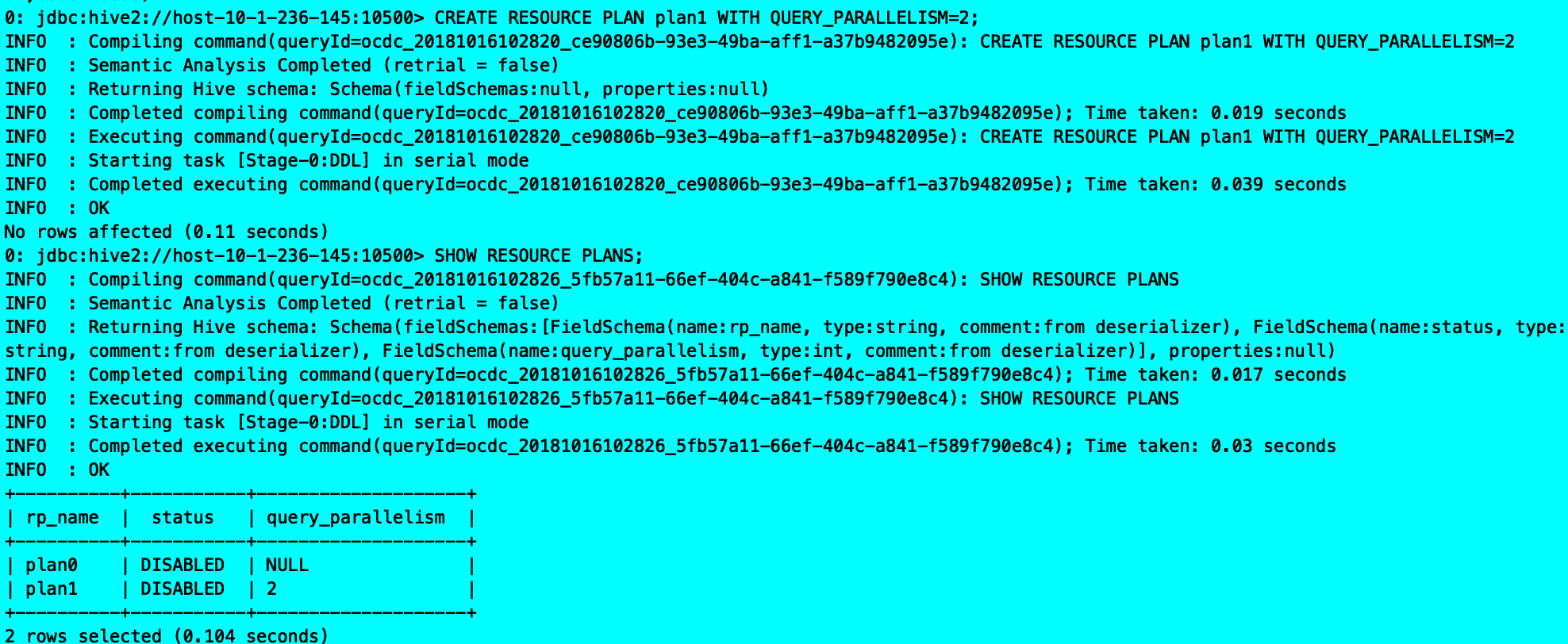
创建步骤:
创建资源计划
CREATE RESOURCE PLAN plan_name [ WITH QUERY_PARALLELISM=number | LIKE name]
CREATE RESOURCE PLAN plan1 WITH QUERY_PARALLELISM=2
创建池
CREATE POOL plan_name.path WITH ALLOC_FRACTION = decimal, QUERY_PARALLELISM = num, [ SCHEDULING_POLICY = scheduling_value ]
CREATE POOL plan1.child1 WITH ALLOC_FRACTION = 0.75, QUERY_PARALLELISM = 2
创建映射
CREATE { USER | GROUP | APPLICATION } MAPPING ‘entity_name’ IN plan_name { TO pool_path | UNMANAGED } [ WITH ORDER num ]
CREATE GROUP MAPPING ‘name’ IN plan1 TO child1 WITH ORDER 3
功能实现:
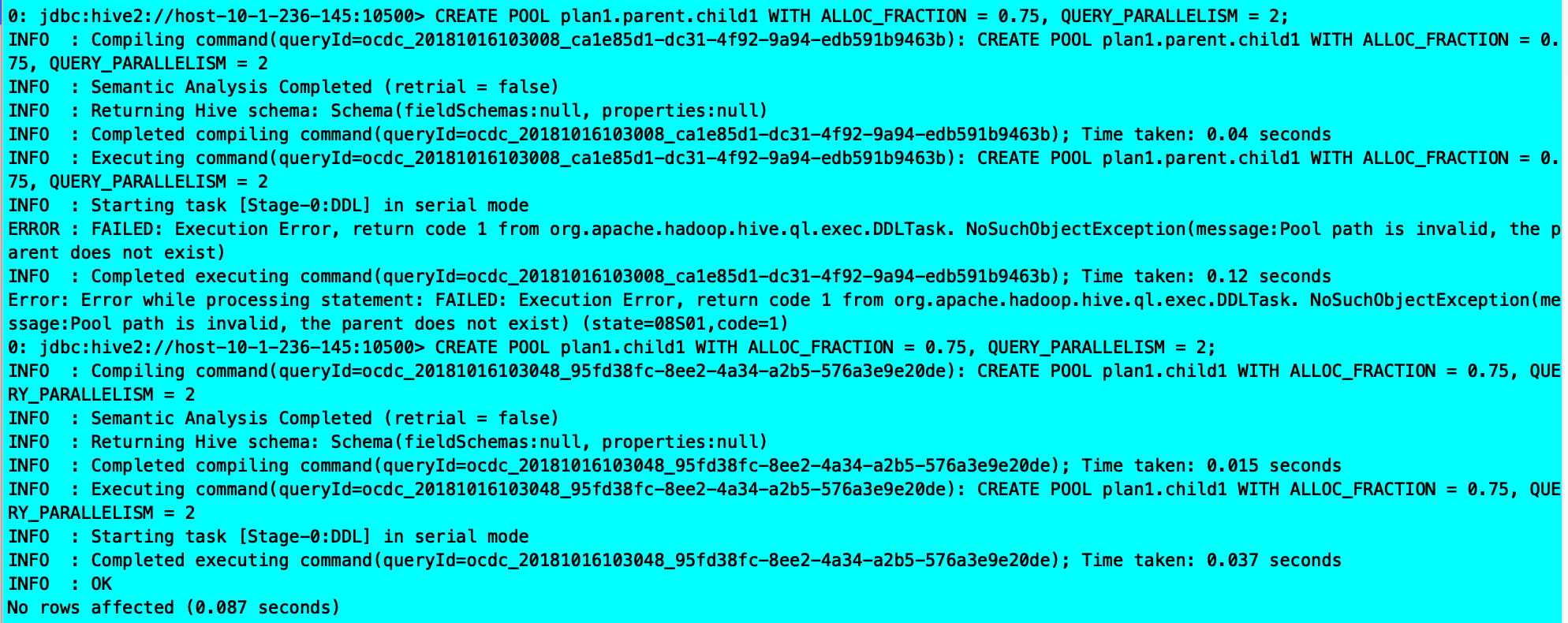

遇到问题:

若有收获,就点个赞吧
0 人点赞
