1、Procedure V2的使用
功能描述:
Procedure V2, 是hbase1.1版本引入的一套fault-tolerant的执行multi-steps-job的框架, 目前主要用在Master中, 比如创建表,删除表等操作。procedure v2主要是为了解决之前的方案中存在的问题, 比如,任务意外中断后,中间状态需要人工接入, 难以追溯任务状态等问题。
Hbase2.0中ProcedureV2提供了一个持久化的手段(通过ProcedureWAL,一种类似RegionServer中WAL的日志持久化到HDFS上),使master在宕机后能够继续之前未完成的任务继续完成。同时,ProcedureV2提供了非常丰富的状态转换并支持回滚执行,即使执行到某一个步骤出错,master也可以按照用户的逻辑对之前的步骤进行回滚。比如建表到某一个步骤失败了,而之前已经在HDFS中创建了一些新region的文件夹,那么ProcedureV2在rollback的时候,可以把这些残留删除掉。
但是这样做的问题是:一旦ProcedureWAL出现了损坏,或者Procedure本身存在bug,这个后果就是灾难性的。
https://yq.aliyun.com/articles/601096?utm_content=m_1000002729
功能实现:
OCDP5.0使用的hbase版本为:2.0.0.3,该版本中默认已经集成使用了ProcedureV2,我们可以通过hbase界面查看: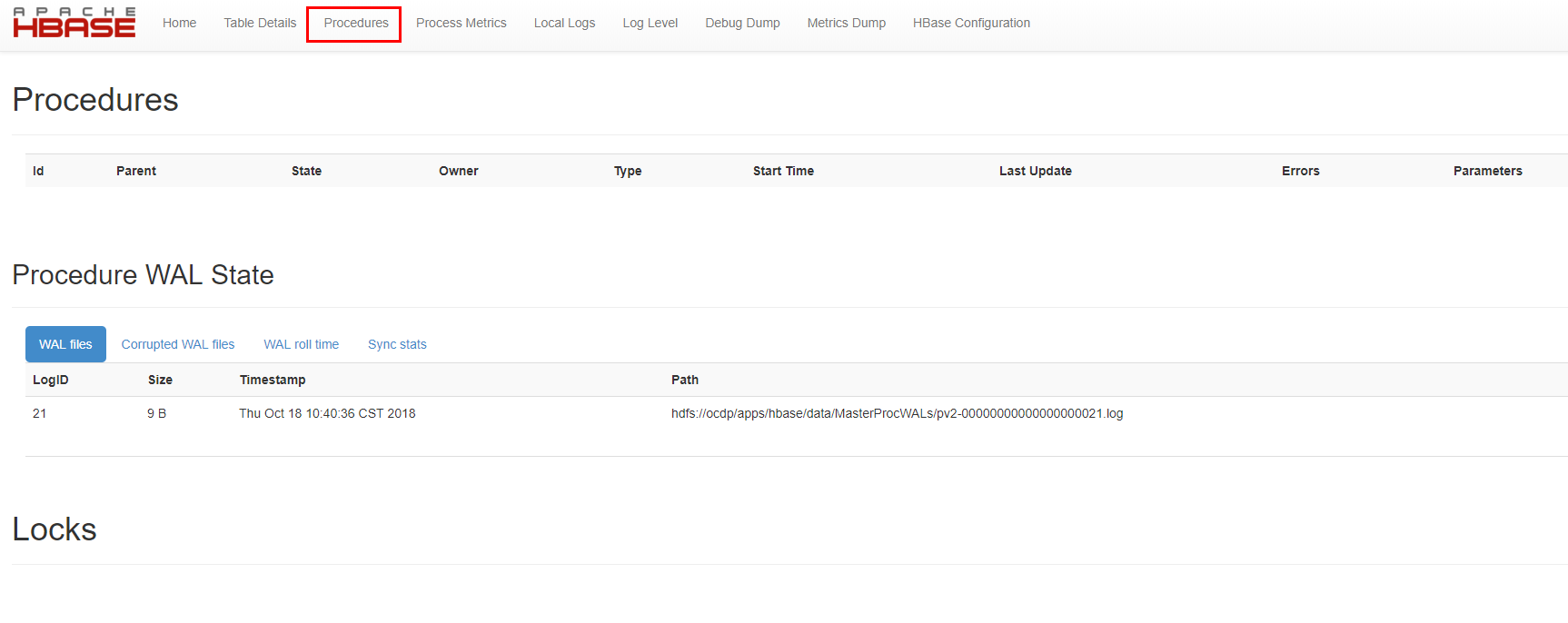
我们创建一张表后界面显示: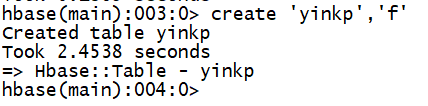
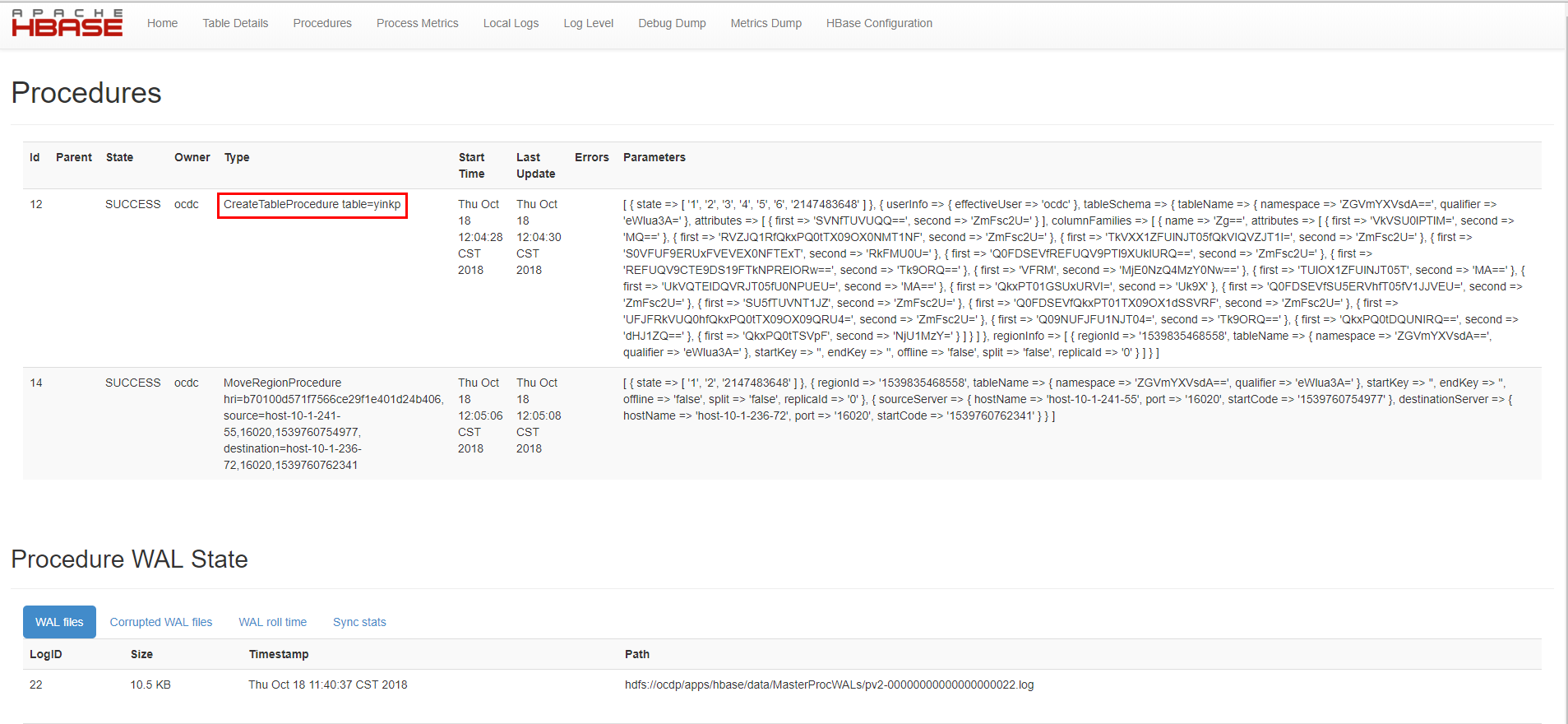
遇到问题:
2、完全脱堆读/写路径
功能描述:
在HBase的读和写链路中,均会产生大量的内存垃圾和碎片。比如说写请求时需要从Connection的ByteBuffer中拷贝数据到KeyValue结构中,在把这些KeyValue结构写入memstore时,又需要将其拷贝到MSLAB中,WAL Edit的构建,Memstore的flush等等,都会产生大量的临时对象,和生命周期结束的对象。随着写压力的上升,GC的压力也会越大。读链路也同样存在这样的问题,cache的置换,block数据的decoding,写网络中的拷贝等等过程,都会无形中加重GC的负担。而HBase2.0中引入的全链路offheap功能,正是为了解决这些GC问题。Java的内存分为onheap和offheap,而GC只会整理onheap的堆。全链路Offheap,就意味着HBase在读写过程中,KeyValue的整个生命周期都会在offheap中进行,HBase自行管理offheap的内存,减少GC压力和GC停顿。
功能实现:
https://yq.aliyun.com/news/244134
1. 配置:
修改hbase-env.sh 添加:
export HBASE_OFFHEAPSIZE=5G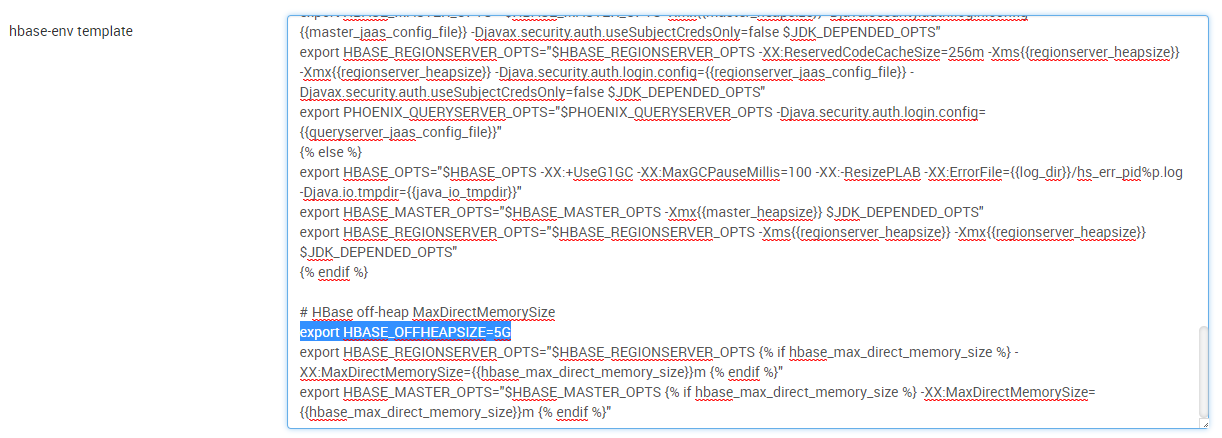
修改hbase-site.xml添加:
然后通过ambari界面重启hbase服务使配置生效。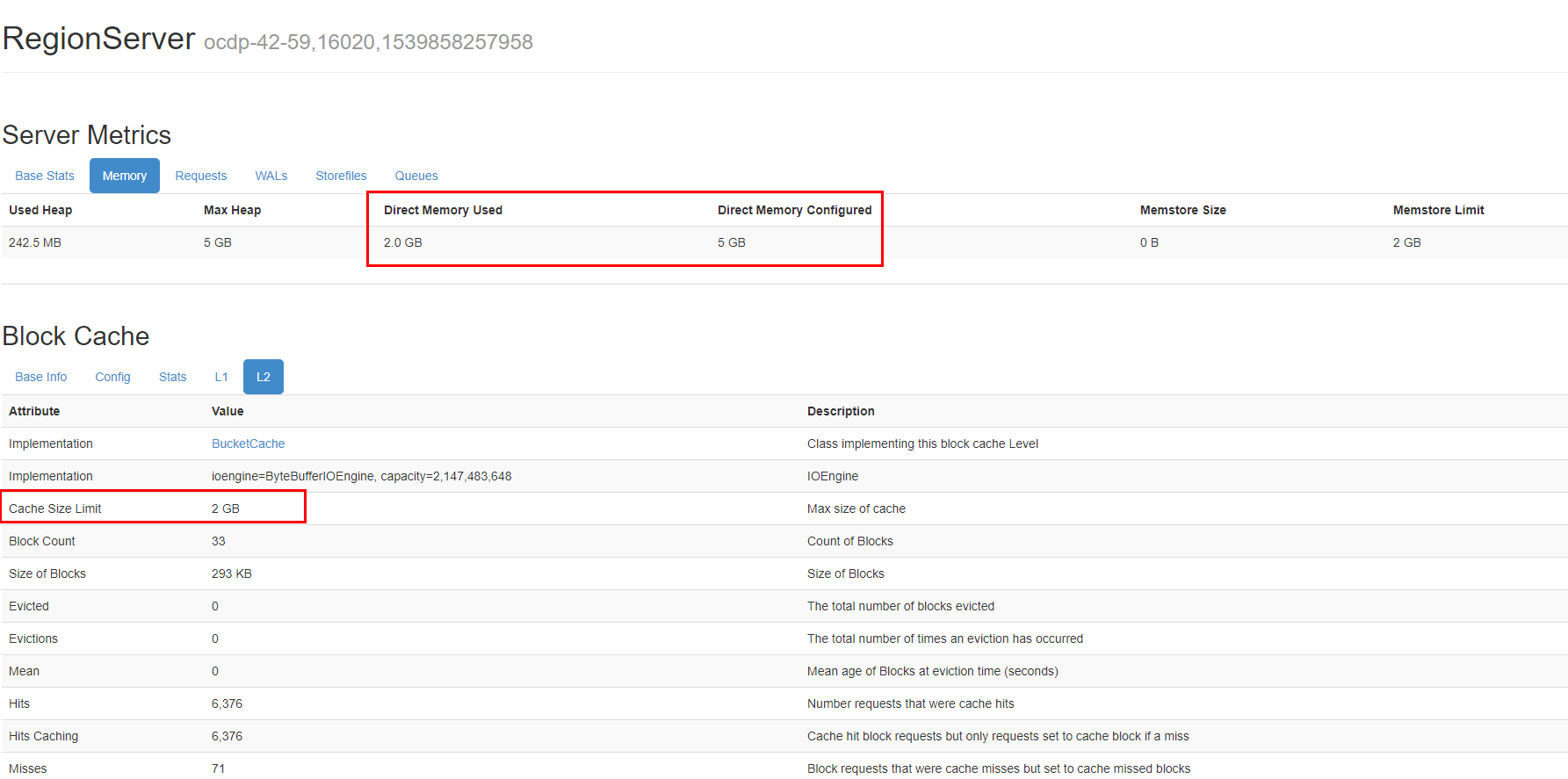
2. 对比测试:
(1)没有开启offheap,我们对hbase进行插入测试,观察regionserver进程的GC情况。
hbase pe —nomapred —oneCon=true —valueSize=200 —compress=SNAPPY —rows=150000 —autoFlush=true —presplit=64 randomWrite 64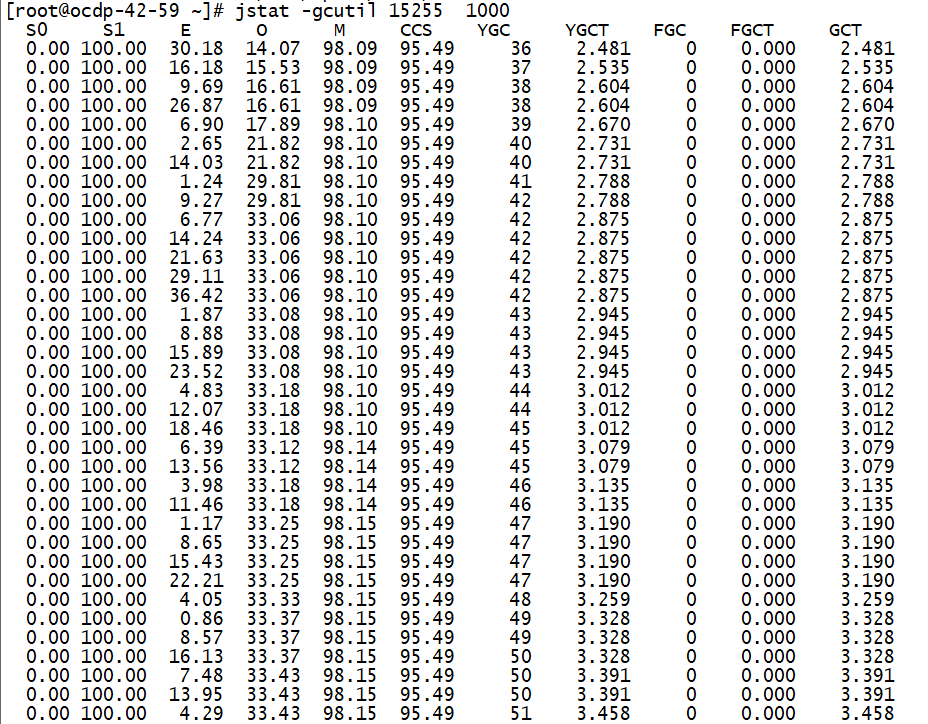
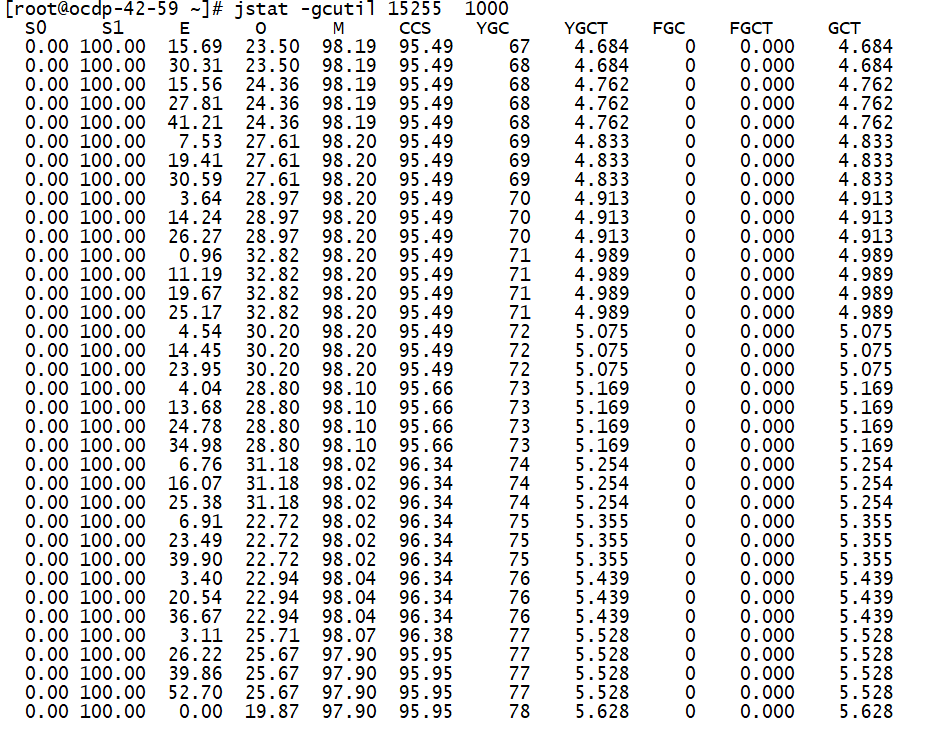
从上面打印regionserver进程GC情况可以看出,大约4s进行一次yang GC,GC时长约:89ms
(2)开启offheap,我们对hbase进行插入和读取测试,观察regionserver进程的GC情况。
hbase pe —nomapred —oneCon=true —valueSize=200 —compress=SNAPPY —rows=150000 —autoFlush=true —presplit=64 randomWrite 64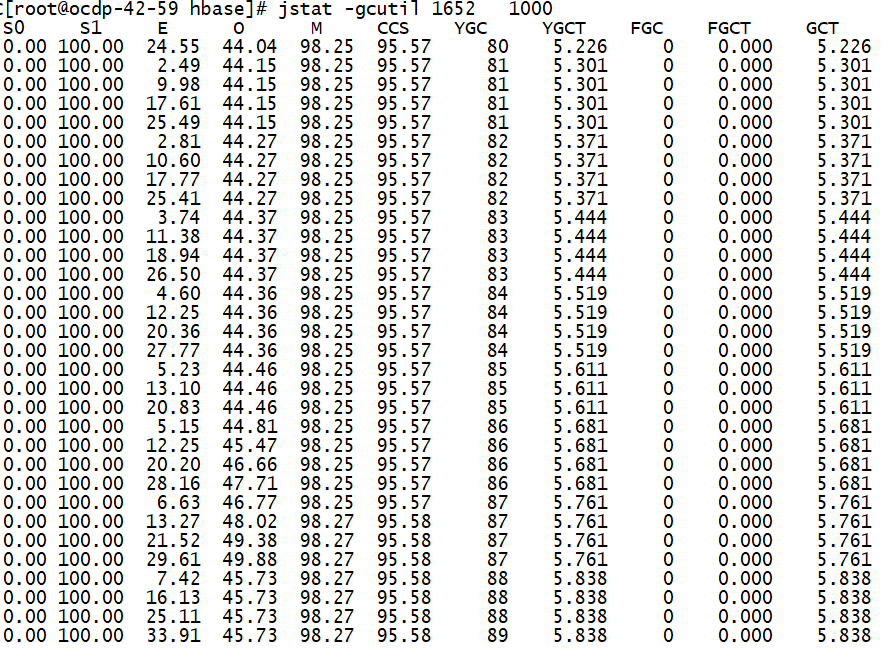
从上面打印regionserver进程GC情况可以看出,大约4s进行一次yang GC,GC时长约:75ms
GC时长变短。(测试环境没测试出明显效果)
3. 结论:
使用hbase的堆外内存可以缩短regionserver进程的GC时间,防止应用超时。
遇到问题:
3、内存中的压缩
功能描述:
In-Memory Compaction是HBase2.0中的重要特性之一,通过在内存中引入LSM结构,减少多余数据,实现降低flush频率和减小写放大的效果。
也就是说,之前memorystore中的数据是不压缩的,写满了就直接flush到磁盘上。开启In-Memory Compaction后,memorystore中的数据会进行压缩,这样会减少memorystore flush的频率,降低磁盘I/O,对hbase性能有提升。
https://www.cnblogs.com/hbase-community/p/8879871.html
功能实现:
1.配置:
注: 默认不压缩memstore,可以配置成BASIC/EAGER/ADAPTIVE对memstore进行压缩
compaction策略
当一个active segment被flush到pipeline中之后,后台会触发一个任务对pipeline中的数据进行合并。合并任务会对pipeline中所有segment进行scan,将他们的索引合并为一个。有三种合并策略可供选择:Basic,Eager,Adaptive。
Basic compaction策略和Eager compaction策略的区别在于如何处理cell数据。Basic compaction不会清理多余的数据版本,这样就不需要对cell的内存进行拷贝。而Eager compaction会过滤重复的数据,并清理多余的版本,这意味着会有额外的开销:例如如果使用了MSLAB存储cell数据,就需要把经过清理之后的cell从旧的MSLAB拷贝到新的MSLAB。basic适用于所有写入模式,eager则主要针对数据大量淘汰的场景:例如消息队列、购物车等。
Adaptive策略则是根据数据的重复情况来决定是否使用Eager策略。在Adaptive策略中,首先会对待合并的segment进行评估,方法是在已经统计过不重复key个数的segment中,找出cell个数最多的一个,然后用这个segment的numUniqueKeys / getCellsCount得到一个比例,如果比例小于设定的阈值,则使用Eager策略,否则使用Basic策略。
重启hbase生效。
2. 建表设置:
create ‘
create ‘yinkp3’, {NAME => ‘f’ ,IN_MEMORY_COMPACTION => ‘BASIC’}
遇到问题:
配置后不能自动生效,仍需要建表时指定。

若有收获,就点个赞吧
0 人点赞
