一、问题现在
Active NameNode日志出现异常IPC‘s epoch [X] is less than the last promised epoch [X+1],出现短期的双Active<br />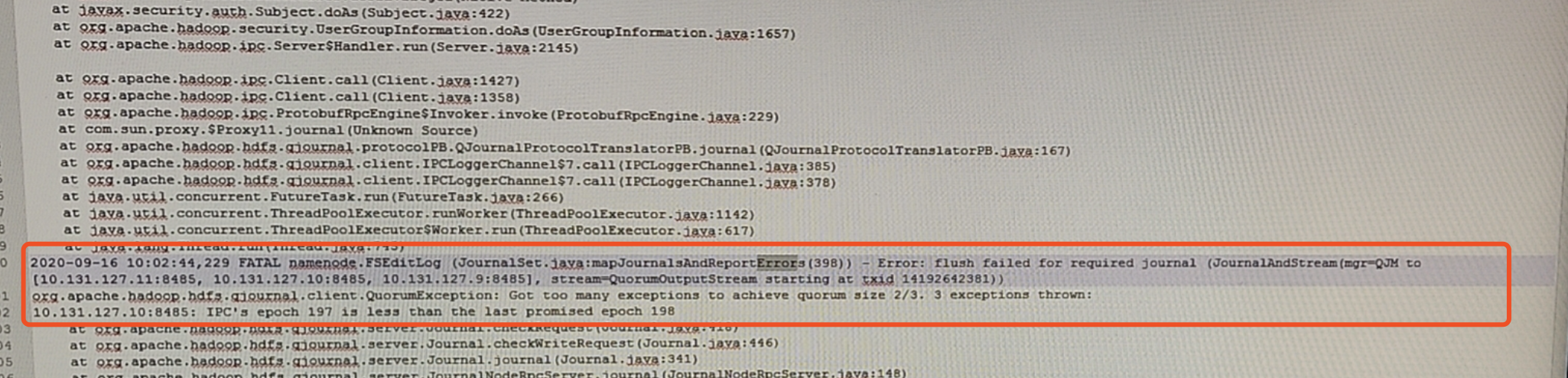
二、原因分析
【HDFS机制】:该问题属于hdfs对于脑列的异常保护,属于正常行为,不影响业务。
1、ZKFC1对NameNode1(Active)进行健康检查,因为长时间监控不到NN1的回复,认为该NameNode1不健康,主动释 放zk中的ActiveStandbyElectorLock,此时NN1还是active(因为zkfc与NameNode1连接异常,不能将其 shutdown)。
zkfc log:2020-09-16 02:11:02,720 WARN org.apache.hadoop.ha.HealthMonitor: Transport-level exception trying to monitor health of NameNode at namenode01/172.21.248.14:9005: Call From namenode01/172.21.248.14 to namenode02:9005 failed on socket timeout exception: java.net.SocketTimeoutException: 45000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/172.21.248.14:47271 remote=namenode01/172.21.248.14:9005]; For more details see: http://wiki.apache.org/hadoop/SocketTimeout2020-09-16 02:12:12,825 WARN org.apache.hadoop.ha.FailoverController: Unable to gracefully make NameNode at namenode02/172.21.248.13:9005 standby (unable to connect)java.net.SocketTimeoutException: Call From namenode01/172.21.248.14 to namenode02:9005 failed on socket timeout exception: java.net.SocketTimeoutException: 5000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/172.21.248.14:59156 remote=namenode02/172.21.248.13:9005]; For more details see: http://wiki.apache.org/hadoop/SocketTimeout
2、ZKFC2在zk中竞争到ActiveStandbyElectorLock,将NameNode2(原来的Standby)变成Active,同时会更新JN中的epoch使其+1。
3、NameNode1(原先的Active)再次去操作JournalNode的editlog时发现自己的epoch比JN的epoch小1,促使自己重启,成为Standby NameNode。
NN1 log:2020-09-16 12:20:59,017 FATAL org.apache.hadoop.hdfs.server.namenode.FSEditLog: Error: flush failed for required journal (JournalAndStream(mgr=QJM to [10.1.1.107:8485, 192.10.1.208:8485,192.10.1.209:8485], stream=QuorumOutputStream starting at txid 22795230)) org.apache.hadoop.hdfs.qjournal.client.QuorumException: Got too many exceptions to achieve quorum size 2/3. 3 exceptions thrown: 192.10.1.208:8485: IPC‘s epoch 115 is less than the last promised epoch 116
三、解决方案
在core-site.xml文件中修改ha.health-monitor.rpc-timeout.ms参数值,来扩大zkfc监控检查超时时间。
<property><name>ha.health-monitor.rpc-timeout.ms</name><value>180000</value></property>

若有收获,就点个赞吧
0 人点赞
