1、查看kafka-reassign-partitions.sh脚本
cd kafka_home/bincat kafka-reassign-partitions.sh
#!/bin/bash# Licensed to the Apache Software Foundation (ASF) under one or more# contributor license agreements. See the NOTICE file distributed with# this work for additional information regarding copyright ownership.# The ASF licenses this file to You under the Apache License, Version 2.0# (the "License"); you may not use this file except in compliance with# the License. You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.exec $(dirname $0)/kafka-run-class.sh kafka.admin.ReassignPartitionsCommand "$@"
由上可得:kafka-reassign-partitions.sh脚本实际执行kafka-run-class.sh脚本,调用kafka.admin.ReassignPartitionsCommand类
2、ReassignPartitionsCommand类详情
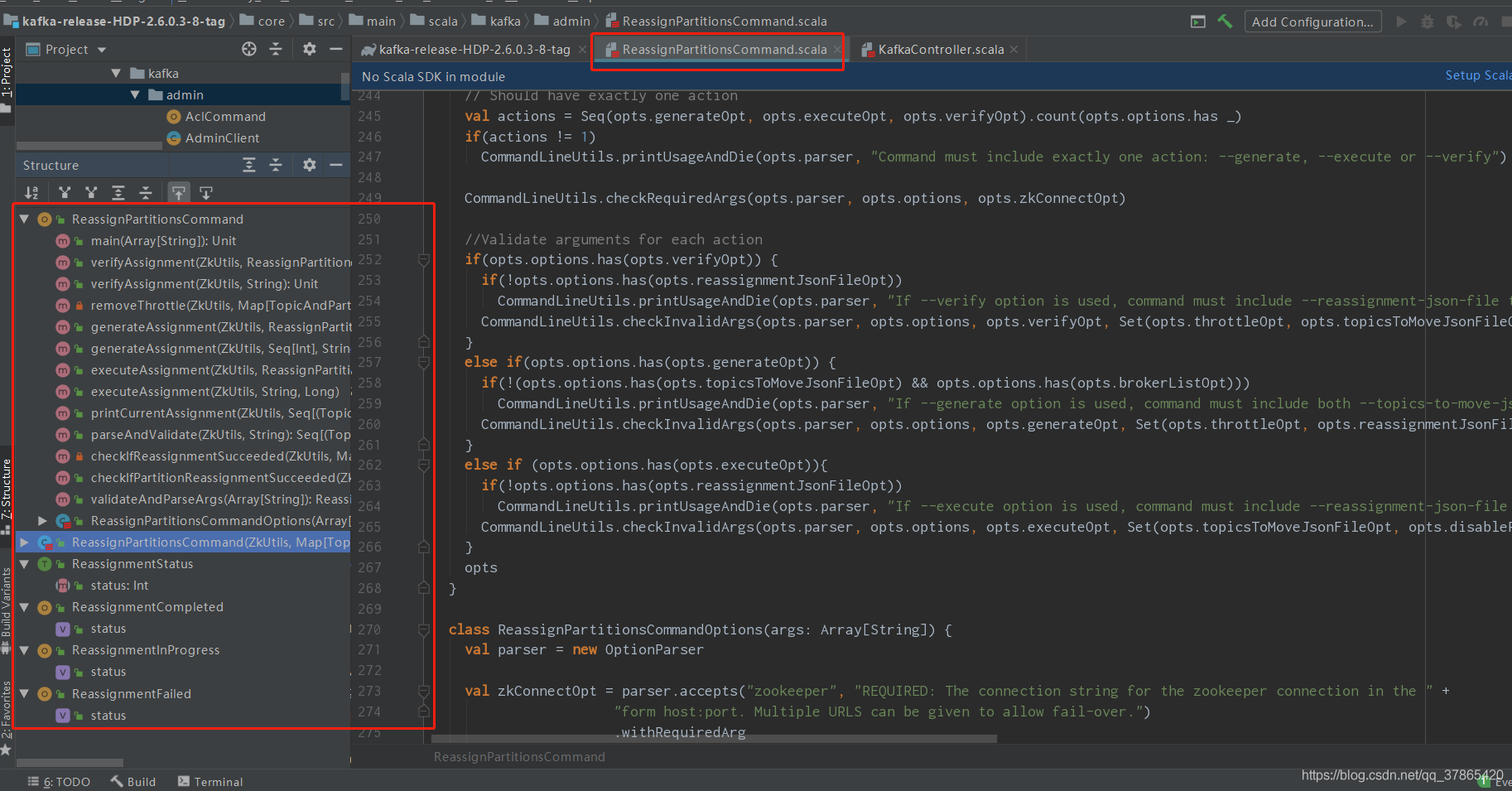
def executeAssignment(zkUtils: ZkUtils, opts: ReassignPartitionsCommandOptions) {//读取迁移计划json格式val reassignmentJsonFile = opts.options.valueOf(opts.reassignmentJsonFileOpt)//将迁移计划json格式转stringval reassignmentJsonString = Utils.readFileAsString(reassignmentJsonFile)//如果有限额的参数,则将限额的参数进行读取,传入executeAssignment中去val throttle = if (opts.options.has(opts.throttleOpt)) opts.options.valueOf(opts.throttleOpt) else -1executeAssignment(zkUtils, reassignmentJsonString, throttle)}def executeAssignment(zkUtils: ZkUtils, reassignmentJsonString: String, throttle: Long = -1) {val partitionsToBeReassigned = parseAndValidate(zkUtils, reassignmentJsonString)val reassignPartitionsCommand = new ReassignPartitionsCommand(zkUtils, partitionsToBeReassigned.toMap)// If there is an existing rebalance running, attempt to change its throttleif (zkUtils.pathExists(ZkUtils.ReassignPartitionsPath)) {println("There is an existing assignment running.")reassignPartitionsCommand.maybeLimit(throttle)}else {printCurrentAssignment(zkUtils, partitionsToBeReassigned)if (throttle >= 0)println(String.format("Warning: You must run Verify periodically, until the reassignment completes, to ensure the throttle is removed. You can also alter the throttle by rerunning the Execute command passing a new value."))if (reassignPartitionsCommand.reassignPartitions(throttle)) {println("Successfully started reassignment of partitions.")} elseprintln("Failed to reassign partitions %s".format(partitionsToBeReassigned))}}def reassignPartitions(throttle: Long = -1): Boolean = {maybeThrottle(throttle)try {val validPartitions = proposedAssignment.filter { case (p, _) => validatePartition(zkUtils, p.topic, p.partition) }if (validPartitions.isEmpty) falseelse {val jsonReassignmentData = ZkUtils.formatAsReassignmentJson(validPartitions)zkUtils.createPersistentPath(ZkUtils.ReassignPartitionsPath, jsonReassignmentData)true}} catch {case ze: ZkNodeExistsException =>val partitionsBeingReassigned = zkUtils.getPartitionsBeingReassigned()throw new AdminCommandFailedException("Partition reassignment currently in " +"progress for %s. Aborting operation".format(partitionsBeingReassigned))case e: Throwable => error("Admin command failed", e); false}}
由上可知
- executeAssignment(zkUtils: ZkUtils, opts: ReassignPartitionsCommandOptions)方法获取ReassignPartitionsCommandOptions参数对应的执行计划文件内容
- executeAssignment(zkUtils: ZkUtils, reassignmentJsonString: String, throttle: Long = -1)方法进行校验、判断限流值(以防分区重分配/迁移网络影响到leader,导致生产消费异常)
- reassignPartitions(throttle: Long = -1)方法中的
zkUtils.createPersistentPath(ZkUtils.ReassignPartitionsPath, jsonReassignmentData)在zk的/admin/reassign_partitions创建一个执行计划的节点,至此,execute命令执行结束,zk节点创建完毕,等待监听器监听、回调具体的执行逻辑
3、Controller监听动作
主controller会回调 KafkaController.onControllerFailover 这个方法, 这个方法注册了监听 “/admin/reassign_partitions” 目录的事件,如下代码
/*** This callback is invoked by the zookeeper leader elector on electing the current broker as the new controller.* It does the following things on the become-controller state change -* 1. Register controller epoch changed listener* 2. Increments the controller epoch* 3. Initializes the controller's context object that holds cache objects for current topics, live brokers and* leaders for all existing partitions.* 4. Starts the controller's channel manager* 5. Starts the replica state machine* 6. Starts the partition state machine* If it encounters any unexpected exception/error while becoming controller, it resigns as the current controller.* This ensures another controller election will be triggered and there will always be an actively serving controller*/def onControllerFailover() {if(isRunning) {info("Broker %d starting become controller state transition".format(config.brokerId))//read controller epoch from zkreadControllerEpochFromZookeeper()// increment the controller epochincrementControllerEpoch(zkUtils.zkClient)// before reading source of truth from zookeeper, register the listeners to get broker/topic callbacksregisterReassignedPartitionsListener()registerIsrChangeNotificationListener()registerPreferredReplicaElectionListener()partitionStateMachine.registerListeners()replicaStateMachine.registerListeners()initializeControllerContext()replicaStateMachine.startup()partitionStateMachine.startup()// register the partition change listeners for all existing topics on failovercontrollerContext.allTopics.foreach(topic => partitionStateMachine.registerPartitionChangeListener(topic))info("Broker %d is ready to serve as the new controller with epoch %d".format(config.brokerId, epoch))maybeTriggerPartitionReassignment()maybeTriggerPreferredReplicaElection()/* send partition leadership info to all live brokers */sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq)if (config.autoLeaderRebalanceEnable) {info("starting the partition rebalance scheduler")autoRebalanceScheduler.startup()autoRebalanceScheduler.schedule("partition-rebalance-thread", checkAndTriggerPartitionRebalance,5, config.leaderImbalanceCheckIntervalSeconds.toLong, TimeUnit.SECONDS)}deleteTopicManager.start()}elseinfo("Controller has been shut down, aborting startup/failover")}
4、Controller处理动作
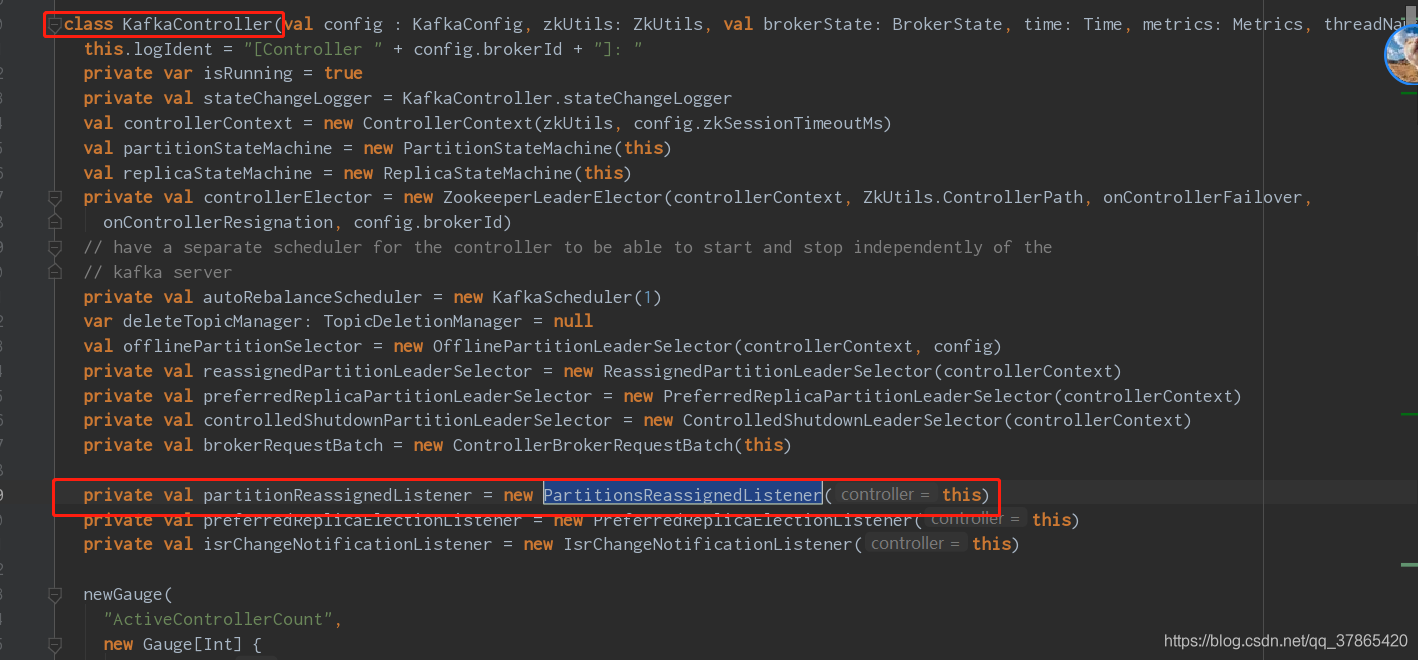
处理 事件是通过 PartitionsReassignedListener 的handleDataChange来处理的。
实际上最终处理的是通过 onPartitionReassignment的方法
/*** Starts the partition reassignment process unless -* 1. Partition previously existed* 2. New replicas are the same as existing replicas* 3. Any replica in the new set of replicas are dead* If any of the above conditions are satisfied, it logs an error and removes the partition from list of reassigned* partitions.*/class PartitionsReassignedListener(controller: KafkaController) extends IZkDataListener with Logging {this.logIdent = "[PartitionsReassignedListener on " + controller.config.brokerId + "]: "val zkUtils = controller.controllerContext.zkUtilsval controllerContext = controller.controllerContext/*** Invoked when some partitions are reassigned by the admin command** @throws Exception On any error.*/@throws(classOf[Exception])def handleDataChange(dataPath: String, data: Object) {debug("Partitions reassigned listener fired for path %s. Record partitions to be reassigned %s".format(dataPath, data))val partitionsReassignmentData = ZkUtils.parsePartitionReassignmentData(data.toString)val partitionsToBeReassigned = inLock(controllerContext.controllerLock) {partitionsReassignmentData.filterNot(p => controllerContext.partitionsBeingReassigned.contains(p._1))}partitionsToBeReassigned.foreach { partitionToBeReassigned =>inLock(controllerContext.controllerLock) {if(controller.deleteTopicManager.isTopicQueuedUpForDeletion(partitionToBeReassigned._1.topic)) {error("Skipping reassignment of partition %s for topic %s since it is currently being deleted".format(partitionToBeReassigned._1, partitionToBeReassigned._1.topic))controller.removePartitionFromReassignedPartitions(partitionToBeReassigned._1)} else {val context = new ReassignedPartitionsContext(partitionToBeReassigned._2)//initiateReassignReplicasForTopicPartition会调用onPartitionReassignment方法按照分配/迁移计划内容进行具体的数据迁移controller.initiateReassignReplicasForTopicPartition(partitionToBeReassigned._1, context)}}}}/*** Called when the leader information stored in zookeeper has been delete. Try to elect as the leader** @throws Exception On any error.*/@throws(classOf[Exception])def handleDataDeleted(dataPath: String) {}}
controller.initiateReassignReplicasForTopicPartition(partitionToBeReassigned._1, context)会调用onPartitionReassignment方法按照分配/迁移计划内容进行具体的数据迁移
def initiateReassignReplicasForTopicPartition(topicAndPartition: TopicAndPartition,reassignedPartitionContext: ReassignedPartitionsContext) {val newReplicas = reassignedPartitionContext.newReplicasval topic = topicAndPartition.topicval partition = topicAndPartition.partitionval aliveNewReplicas = newReplicas.filter(r => controllerContext.liveBrokerIds.contains(r))try {val assignedReplicasOpt = controllerContext.partitionReplicaAssignment.get(topicAndPartition)assignedReplicasOpt match {case Some(assignedReplicas) =>if(assignedReplicas == newReplicas) {throw new KafkaException("Partition %s to be reassigned is already assigned to replicas".format(topicAndPartition) +" %s. Ignoring request for partition reassignment".format(newReplicas.mkString(",")))} else {info("Handling reassignment of partition %s to new replicas %s".format(topicAndPartition, newReplicas.mkString(",")))// first register ISR change listenerwatchIsrChangesForReassignedPartition(topic, partition, reassignedPartitionContext)controllerContext.partitionsBeingReassigned.put(topicAndPartition, reassignedPartitionContext)// mark topic ineligible for deletion for the partitions being reassigneddeleteTopicManager.markTopicIneligibleForDeletion(Set(topic))//按照分配/迁移计划内容进行具体的数据迁移onPartitionReassignment(topicAndPartition, reassignedPartitionContext)}case None => throw new KafkaException("Attempt to reassign partition %s that doesn't exist".format(topicAndPartition))}} catch {case e: Throwable => error("Error completing reassignment of partition %s".format(topicAndPartition), e)// remove the partition from the admin path to unblock the admin clientremovePartitionFromReassignedPartitions(topicAndPartition)}}
5、onPartitionReassignment核心方法
/*** This callback is invoked by the reassigned partitions listener. When an admin command initiates a partition* reassignment, it creates the /admin/reassign_partitions path that triggers the zookeeper listener.* Reassigning replicas for a partition goes through a few steps listed in the code.* RAR = Reassigned replicas* OAR = Original list of replicas for partition* AR = current assigned replicas** 1. Update AR in ZK with OAR + RAR.* 2. Send LeaderAndIsr request to every replica in OAR + RAR (with AR as OAR + RAR). We do this by forcing an update* of the leader epoch in zookeeper.* 3. Start new replicas RAR - OAR by moving replicas in RAR - OAR to NewReplica state.* 4. Wait until all replicas in RAR are in sync with the leader.* 5 Move all replicas in RAR to OnlineReplica state.* 6. Set AR to RAR in memory.* 7. If the leader is not in RAR, elect a new leader from RAR. If new leader needs to be elected from RAR, a LeaderAndIsr* will be sent. If not, then leader epoch will be incremented in zookeeper and a LeaderAndIsr request will be sent.* In any case, the LeaderAndIsr request will have AR = RAR. This will prevent the leader from adding any replica in* RAR - OAR back in the isr.* 8. Move all replicas in OAR - RAR to OfflineReplica state. As part of OfflineReplica state change, we shrink the* isr to remove OAR - RAR in zookeeper and send a LeaderAndIsr ONLY to the Leader to notify it of the shrunk isr.* After that, we send a StopReplica (delete = false) to the replicas in OAR - RAR.* 9. Move all replicas in OAR - RAR to NonExistentReplica state. This will send a StopReplica (delete = true) to* the replicas in OAR - RAR to physically delete the replicas on disk.* 10. Update AR in ZK with RAR.* 11. Update the /admin/reassign_partitions path in ZK to remove this partition.* 12. After electing leader, the replicas and isr information changes. So resend the update metadata request to every broker.** For example, if OAR = {1, 2, 3} and RAR = {4,5,6}, the values in the assigned replica (AR) and leader/isr path in ZK* may go through the following transition.* AR leader/isr* {1,2,3} 1/{1,2,3} (initial state)* {1,2,3,4,5,6} 1/{1,2,3} (step 2)* {1,2,3,4,5,6} 1/{1,2,3,4,5,6} (step 4)* {1,2,3,4,5,6} 4/{1,2,3,4,5,6} (step 7)* {1,2,3,4,5,6} 4/{4,5,6} (step 8)* {4,5,6} 4/{4,5,6} (step 10)** Note that we have to update AR in ZK with RAR last since it's the only place where we store OAR persistently.* This way, if the controller crashes before that step, we can still recover.*/def onPartitionReassignment(topicAndPartition: TopicAndPartition, reassignedPartitionContext: ReassignedPartitionsContext) {//reassignedPartitionContext对象为执行计划中的每一个分区详情。reassignedReplicas为每个分区计划重分配的副本对应的brokerId集合.val reassignedReplicas = reassignedPartitionContext.newReplicas/*根据要进行重新的副本分配的topic-partition,从zk中对应的topic/partition的state中找到对应的leader的切换顺序集合(isr)的集合,如果重新分配的副本集合在isr的集合中都包含时,areReplicasInIsr函数的返回值为true,否则表示新的副本集合中有副本不在isr中包含返回值为false.这里如果是true时,执行的是对副本的具体分配,如果是false的情况时,会更新每个partition的state的内容为新的副本信息,并设置新添加的副本的状态为NewReplica的状态,*///{1,2,3} 1/{1,2,3} (initial state)if (!areReplicasInIsr(topicAndPartition.topic, topicAndPartition.partition, reassignedReplicas)) {info("New replicas %s for partition %s being ".format(reassignedReplicas.mkString(","), topicAndPartition) +"reassigned not yet caught up with the leader")//这里先得到新分配的副本与已经存在的副本的差集,也就是新分配的副本在现在的副本中不包含的集合val newReplicasNotInOldReplicaList = reassignedReplicas.toSet -- controllerContext.partitionReplicaAssignment(topicAndPartition).toSet//这里得到新分配的副本与已经存在的副本集合的全集.val newAndOldReplicas = (reassignedPartitionContext.newReplicas ++ controllerContext.partitionReplicaAssignment(topicAndPartition)).toSet//1. Update AR in ZK with OAR + RAR.//这里把新分配的replicas的副本集合与已经存在的副本集合进行合并后,得到一个新的副本集合,//把这个集合更新到partitionReplicaAssignment集合中对应的partition上//把这个topic对应的所有的partition的副本集合当成内容分配信息存储到zk的/brokers/topics/topicName节点中.// 由topic修改的监听程序来处理对这个zk节点的变化后的流程进行处理.updateAssignedReplicasForPartition(topicAndPartition, newAndOldReplicas.toSeq)//{1,2,3,4,5,6} 1/{1,2,3} (step 2)//2. Send LeaderAndIsr request to every replica in OAR + RAR (with AR as OAR + RAR).//(1)这里根据对应的partition的新的副本信息(原来分配的副本加上新分配的副本),生成向每一个副本所在的broker// 进行leaderIsr状态的请求(这个请求主要是当前的partition对应的副本集合),存储到leaderAndIsrRequestMap集合中,// 在提交请求时从这个集合中读取数据,这个集合中是存储的LeaderAndIsrRequest请求,//(2)这里根据对应的partition,这里在updateMetadataRequestMap集合中存储向所有的broker发送partition的// metadata修改的UpdateMetadataRequest请求,这个请求中,如果topic已经被删除,发送的请求的leader的id是-2,// 否则发送的请求是正常的请求,只是副本集合发生了变化.//(3)向对应的broker发送上面生成的两个请求.这个请求发送的前提是broker已经被启动.updateLeaderEpochAndSendRequest(topicAndPartition, controllerContext.partitionReplicaAssignment(topicAndPartition),newAndOldReplicas.toSeq)//3. replicas in RAR - OAR -> NewReplica//通过对所有的新添加的副本进行迭代,通过replicaStateMachine实例更新副本状态为NewReplicastartNewReplicasForReassignedPartition(topicAndPartition, reassignedPartitionContext, newReplicasNotInOldReplicaList)info("Waiting for new replicas %s for partition %s being ".format(reassignedReplicas.mkString(","), topicAndPartition) +"reassigned to catch up with the leader")} else {//这种情况下,表示当前重新分配的副本在isr的集合中都存在,//先得到老的已经分配的副本//4. Wait until all replicas in RAR are in sync with the leader.val oldReplicas = controllerContext.partitionReplicaAssignment(topicAndPartition).toSet -- reassignedReplicas.toSet//并设置这些老的副本的状态为OnlineReplica.//5. replicas in RAR -> OnlineReplicareassignedReplicas.foreach { replica =>replicaStateMachine.handleStateChanges(Set(new PartitionAndReplica(topicAndPartition.topic, topicAndPartition.partition,replica)), OnlineReplica)}//6. Set AR to RAR in memory.//7. Send LeaderAndIsr request with a potential new leader (if current leader not in RAR) and// a new AR (using RAR) and same isr to every broker in RAR//如果新分配的副本集合中不包含当前的partition的leader节点时,通过partitionStateMachine实例// 更新partition的状态为OnlinePartition.同时通过ReassignedPartitionLeaderSelector实例重新选择leader.//(1)如果新分配的副本集合中不包含当前的partition的leader节点时,通过partitionStateMachine实例更新partition的状态为OnlinePartition.// 同时通过ReassignedPartitionLeaderSelector实例重新选择leader.//(2)如果当前活着的broker节点中包含有Partition的leader节点时,向所有的broker节点发送更新leaderAndIsr与metadata的请求.//(3)如果当前的partition的leader节点已经下线,通过partitionStateMachine实例更新partition的状态为OnlinePartition.// 同时通过ReassignedPartitionLeaderSelector实例重新选择leader.moveReassignedPartitionLeaderIfRequired(topicAndPartition, reassignedPartitionContext)//(1)更新replicaStateMachine中老副本的状态为OfflineReplica状态,并向这个副本对应的节点发起StopReplicaRequest请求.// 更新zk中topic,paritions,state节点下isr的信息多原来的副本节点中移出这个节点.并向余下的isr节点发起LeaderAndIsrRequest的选择请求.//(2)更新replicaStateMachine中对应此partition的此副本状态为ReplicaDeletionStarted状态,// 并向需要执行副本删除的节点发起StopReplicaRequest请求,此时请求的deletePartition的属性值为true.后面的步骤在这里执行完成后才会执行.//(3)更新此partition对应此副本的状态为ReplicaDeletionSuccessful状态.//(4)从replicaStateMachine的replicaState集合中移出此partition对应被下线的副本的副本状态.// 并更新partitionReplicaAssignment集合的副本集合,从这个集合中也移出此节点.//8. replicas in OAR - RAR -> Offline (force those replicas out of isr)//9. replicas in OAR - RAR -> NonExistentReplica (force those replicas to be deleted)stopOldReplicasOfReassignedPartition(topicAndPartition, reassignedPartitionContext, oldReplicas)//更新partitionReplicaAssignment集合中对应此partition的副本集合,并更新这个topic对应zk的节点信息,// 主要是所有的partitions的副本集合都会更新一次.由topic修改的监听程序来处理对这个zk节点的变化后的流程进行处理.//10. Update AR in ZK with RAR.updateAssignedReplicasForPartition(topicAndPartition, reassignedReplicas)//取消对partition的isr的修改的监听程序,并从partitionsBeingReassigned集合中移出这个准备重新分配的partition.//11. Update the /admin/reassign_partitions path in ZK to remove this partition.removePartitionFromReassignedPartitions(topicAndPartition)info("Removed partition %s from the list of reassigned partitions in zookeeper".format(topicAndPartition))controllerContext.partitionsBeingReassigned.remove(topicAndPartition)//向所有的broker节点发送此partition的metadata修改的UpdateMetadataRequest请求.//12. After electing leader, the replicas and isr information changes, so resend the update metadata request to every brokersendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set(topicAndPartition))//如果topic是已经被删除的topic,从准备删除的topic集合中移出这个topic// signal delete topic thread if reassignment for some partitions belonging to topics being deleted just completeddeleteTopicManager.resumeDeletionForTopics(Set(topicAndPartition.topic))}}

若有收获,就点个赞吧
0 人点赞
