正则解析
实战案例-糗图图片爬取
- 通过图片地址爬取一张图片:糗图图片
url = 'https://pic.qiushibaike.com/system/pictures/12464/124644653/medium/OCDQRBU16H6YGDS6.jpg'# content返回的的是二进制的图片数据img_data = requests.get(url=url).contentwith open('qioutu.jpg', 'wb') as fp:fp.write(img_data)
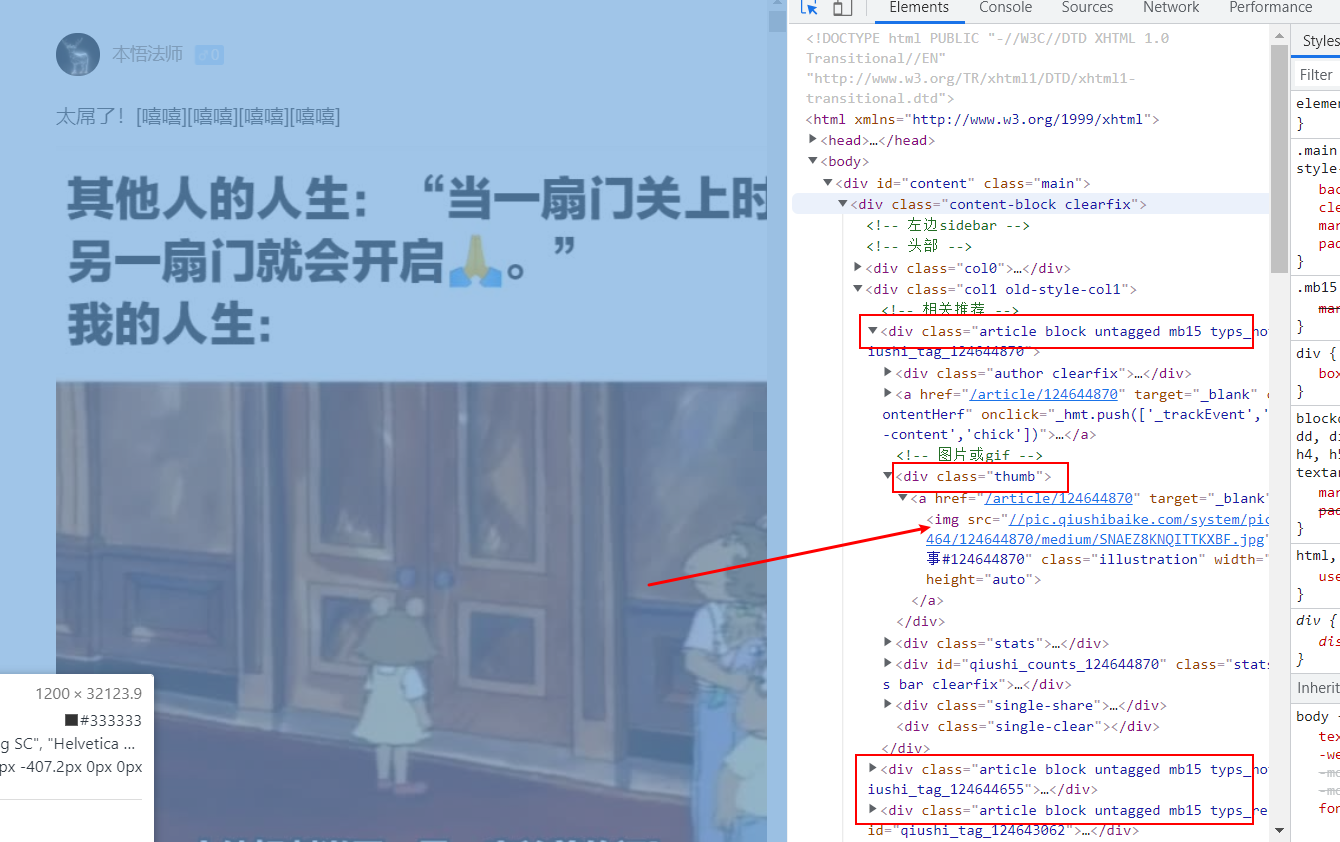
提取每张图片的‘img src’,里面包含了图片地址信息
正则表达式的编写过程:目的——提取img src
# 1、将一张图片所在的class‘thumb’源码复制过来<div class="thumb"><a href="/article/124644870" target="_blank"><img src="//pic.qiushibaike.com/system/pictures/12464/124644870/medium/SNAEZ8KNQITTKXBF.jpg" alt="糗事#124644870" class="illustration" width="100%" height="auto"></a></div># 2、写正则表达式ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'# 3、将正则表达式作用于源码即可提取所有图片地址形成一个列表
爬取图片到本地(还未进行分页操作)
def get_pic():# 创建存储图片的文件夹,若存在该文件夹则不执行if not os.path.exists('./qioutupics'):os.mkdir('./qioutupics')url = 'https://www.qiushibaike.com/imgrank/' # 网页地址headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/''92.0.4515.131 Safari/537.36'}# 使用通用爬虫对URL对应的一整张页面进行爬取page_text = requests.get(url=url, headers=headers).text# 使用聚集爬虫将页面中所有糗图进行解析ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'img_src_list = re.findall(ex, page_text, re.S)# print(img_src_list) # 打印要在return前面for src in img_src_list:src = 'https:' + src # 拼接全图片地址img_data = requests.get(url=src, headers=headers).contentimg_name = src.split('/')[-1]imgPath = './qioutupics/' + img_namewith open(imgPath, 'wb') as fp:fp.write(img_data)print(img_name, '下载成功!')# return img_src_list
分页操作
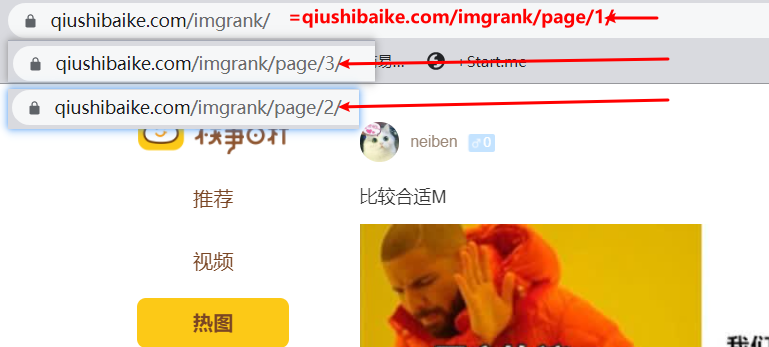
从第1,2,3页网址可以发现规律def get_pic(pagenum=None):# 创建存储图片的文件夹,若存在该文件夹则不执行if pagenum is None:pagenum = [1, 1]if not os.path.exists('./qioutupics'):os.mkdir('./qioutupics')url = 'https://www.qiushibaike.com/imgrank/page/%d/' # 网页地址headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/''92.0.4515.131 Safari/537.36'}for page in range(pagenum[0], pagenum[1]):new_url = format(url % page)# 使用通用爬虫对URL对应的一整张页面进行爬取page_text = requests.get(url=new_url, headers=headers).text# 使用聚集爬虫将页面中所有糗图进行解析ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'img_src_list = re.findall(ex, page_text, re.S)# print(img_src_list) # 打印要在return前面for src in img_src_list:src = 'https:' + src # 拼接全图片地址img_data = requests.get(url=src, headers=headers).contentimg_name = src.split('/')[-1]imgPath = './qioutupics/' + img_namewith open(imgPath, 'wb') as fp:fp.write(img_data)print(img_name, '下载成功!')# return img_src_listget_pic(pagenum=[1, 3]

若有收获,就点个赞吧
0 人点赞
