from selenium import webdriver
from selenium.webdriver.chrome.options import Options # => 引入Chrome的配置
import time
配置
ch_options = Options()
ch_options.add_argument(“—headless”) # => 为Chrome配置无头模式
在启动浏览器时加入配置
driver = webdriver.Chrome(options=ch_options) # => 注意这里的参数
driver.get(‘http://baidu.com‘)
driver.find_element_by_id(‘kw’).send_keys(‘测试’)
driver.find_element_by_id(‘su’).click()
time.sleep(2)
只有截图才能看到效果咯
driver.save_screenshot(‘./ch.png’)
driver.quit()
防止网站识别Selenium代码(针对老版本)
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option(‘excludeSwitches’, [‘enable-automation’])
bro = Chrome(options=option)
url = “fudan.bbs.kaoyan.com” # 首页
bro.get(“http://fudan.bbs.kaoyan.com/“)
bro.implicitly_wait(10)
新版本如下:
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
options = ChromeOptions()
options.add_experimental_option(‘excludeSwitches’, [‘enable-automation’])
options.add_experimental_option(‘useAutomationExtension’, False)
bro = Chrome(options=options)
bro.execute_cdp_cmd(“Page.addScriptToEvaluateOnNewDocument”, {
“source”: “””
Object.defineProperty(navigator, ‘webdriver’, {
get: () => undefined
})
“””
})
url = “fudan.bbs.kaoyan.com” # 首页
bro.get(“http://fudan.bbs.kaoyan.com/“)
bro.implicitly_wait(10)
它是怎么做的的呢?一般情况下,我们使用Selenium打开一个网页时,会有一个提示:Chrome正受到自动测试软件的控制。
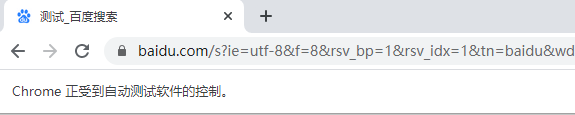
然后打开调试工具,点击consile,输入代码
window.navigator.webdriver
结果如下:
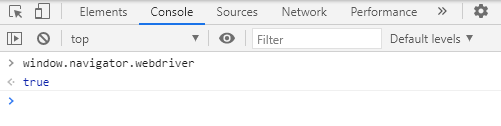
以淘宝为首,众多网站都针对 Selenium的js监测机制,就是上面的方法实现的。
那么如何解决呢?
只需要设置Chromedriver的启动参数即可解决问题。
在启动Chromedriver之前,为Chrome开启实验性功能参数excludeSwitches,它的值为['enable-automation'],代码同上。
运行上面的代码,就没有Chrome正受到自动测试软件的控制的提示了。
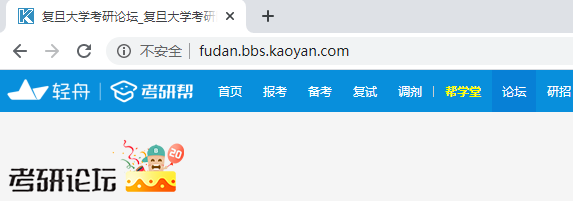
再次js代码
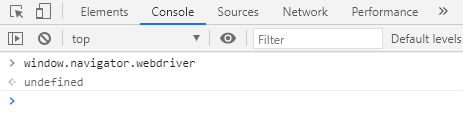
发现已经是undefined了,这样才是一个正常的浏览器了。
本文参考链接:
https://www.cnblogs.com/wukai66/p/12773479.html
https://zhuanlan.zhihu.com/p/117506307
本文参与腾讯云自媒体分享计划,欢迎正在阅读的你也加入,一起分享。

若有收获,就点个赞吧
0 人点赞
