最近做科研时经常需要遍历整个 DataFrame,进行各种列操作,例如把某列的值全部转成 pd.Timestamp 格式或者将某两列的值进行 element-wise 运算之类的。大数据的数据量随便都是百万条起跳,如果只用 for 循环慢慢撸,不仅浪费时间也没效率。在一番 Google 和摸索后我找到了遍历 DataFrame 的至少 8 种方式,其中最快的和最慢的可以相差12000 倍!
本文以相加和相乘两种操作为例,测试 8 种方法的运行速度,并附上示范代码。
测试环境
Macbook Pro Retina with TouchBar (13inch, 2018) i5 8GB 512GBOS: macOS Catalina 10.5.2Python 3.7.5 (default, Nov 1 2019, 02:16:23)[Clang 11.0.0 (clang-1100.0.33.8)] on darwin
示范用数据
本来想造 100 万笔的,但是 100 万笔跑 %timeit 要跑很久,最后造了 3000 笔,己经足以体现运行速度差异。为了避免快取影响,每个子实验进行前都会用这个代码重造数据。
import pandas as pdimport numpy as np# 生成樣例數據def gen_sample():aaa = np.random.uniform(1,1000,3000)bbb = np.random.uniform(1,1000,3000)ccc = np.random.uniform(1,1000,3000)ddd = np.random.uniform(1,1000,3000)return pd.DataFrame({'aaa':aaa,'bbb':bbb, 'ccc': ccc, 'ddd': ddd, 'eee': None})
aaa、bbb 是本文要操作的对象;ccc、ddd 不会被操作到,只是要增大数据框的大小,模拟读入整个数据框和只读取 aaa、bbb 两列的速度差别;eee 用来存放结果
实验 1 - 两列元素相加
# aaa + bbb# python 循環 + iloc 定位def method0_sum(DF):for i in range(len(DF)):DF.iloc[i,4] = DF.iloc[i,0] + DF.iloc[i,1]# python 循環 + iat 定位def method1_sum(DF):for i in range(len(DF)):DF.iat[i,4] = DF.iat[i,0] + DF.iat[i,1]# pandas.DataFrame.iterrows() 迭代器def method2_sum(DF):for index, rows in DF.iterrows():rows['eee'] = rows['aaa'] + rows['bbb']# pandas.DataFrame.apply 迭代def method3_sum(DF):DF['eee'] = DF.apply(lambda x: x.aaa + x.bbb, axis=1)# pandas.DataFrame.apply 迭代 + 只讀兩列def method4_sum(DF):DF['eee'] = DF[['aaa','bbb']].apply(lambda x: x.aaa + x.bbb, axis=1)# 列表構造def method5_sum(DF):DF['eee'] = [ a+b for a,b in zip(DF['aaa'],DF['bbb']) ]# pandas 數組操作def method6_sum(DF):DF['eee'] = DF['aaa'] + DF['bbb']# numpy 數組操作def method7_sum(DF):DF['eee'] = DF['aaa'].values + DF['bbb'].values
实验 1 结果
df = gen_sample()%timeit method0_sum(df)df = gen_sample()%timeit method1_sum(df)df = gen_sample()%timeit method2_sum(df)df = gen_sample()%timeit method3_sum(df)df = gen_sample()%timeit method4_sum(df)df = gen_sample()%timeit method5_sum(df)df = gen_sample()%timeit method6_sum(df)df = gen_sample()%timeit method7_sum(df)2.06 s ± 140 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)56.9 ms ± 1.18 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)358 ms ± 24.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)93 ms ± 1.57 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)90.3 ms ± 1.16 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)1.15 ms ± 39.8 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)273 µs ± 21.6 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)130 µs ± 2.91 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
实验 2 - 两列元素相乘
# aaa * bbb# python 循環 + iloc 定位def method0_times(DF):for i in range(len(DF)):DF.iloc[i,4] = DF.iloc[i,0] * DF.iloc[i,1]# python 循環 + iat 定位def method1_times(DF):for i in range(len(DF)):DF.iat[i,4] = DF.iat[i,0] * DF.iat[i,1]# pandas.DataFrame.iterrows() 迭代器def method2_times(DF):for index, rows in DF.iterrows():rows['eee'] = rows['aaa'] * rows['bbb']# pandas.DataFrame.apply 迭代def method3_times(DF):DF['eee'] = DF.apply(lambda x: x.aaa * x.bbb, axis=1)# pandas.DataFrame.apply 迭代 + 只讀兩列def method4_times(DF):DF['eee'] = DF[['aaa','bbb']].apply(lambda x: x.aaa * x.bbb, axis=1)# 列表構造def method5_times(DF):DF['eee'] = [ a*b for a,b in zip(DF['aaa'],DF['bbb']) ]# pandas 數組操作def method6_times(DF):DF['eee'] = DF['aaa'] * DF['bbb']# numpy 數組操作def method7_times(DF):DF['eee'] = DF['aaa'].values * DF['bbb'].values
实验 2 结果
df = gen_sample()%timeit method0_times(df)df = gen_sample()%timeit method1_times(df)df = gen_sample()%timeit method2_times(df)df = gen_sample()%timeit method3_times(df)df = gen_sample()%timeit method4_times(df)df = gen_sample()%timeit method5_times(df)df = gen_sample()%timeit method6_times(df)df = gen_sample()%timeit method7_times(df)2.04 s ± 78.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)58.4 ms ± 3.29 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)342 ms ± 8.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)89.1 ms ± 1.59 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)90.7 ms ± 769 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)1.1 ms ± 19.9 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)263 µs ± 11 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)131 µs ± 3.35 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
速度比较
我把结果可视化,方便比较运行速度。(顺便练习画图)
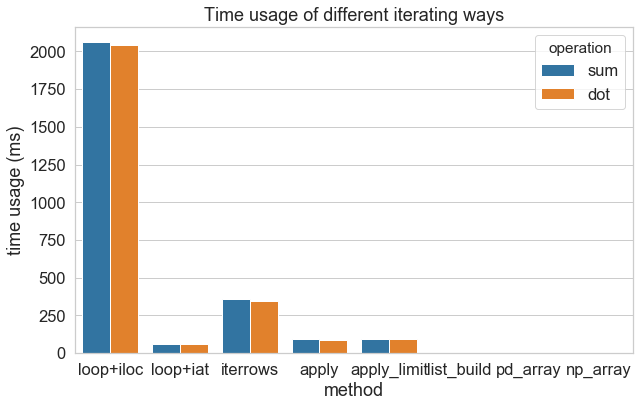
可以看到最快的数组操作和最慢的 for+iloc 相比差了将近万倍,是秒级和微秒级的差别。所有方法运行速度大小关系如下(由慢至快):for 循环 + iloc < pd.iterrows < for 循环 + at < pd.apply pd 列表构造 = np 列表构造 < pd 数组操作 < np 数组操作。pd 和 np 列表构造的速度几乎一样,np 列表构造略快一些(1.15 毫秒和 1.09 毫秒的差别),所以实验只做 pd 列表构造。
把两个秒级操作去掉,详细地比较一下
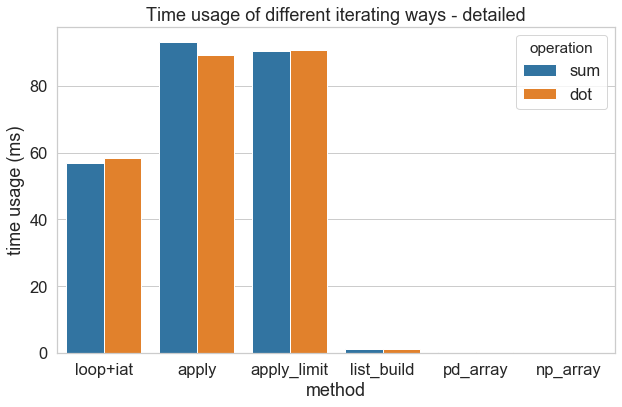
列表构造把除了数组操作以外的其他方法按在地上磨擦,数组操作把列表构造按在地上磨擦。值得注意的是,for 循环 + iat 的组合比 pandas 提供的最快遍历方法 apply 快 40% 左右,也就是说就算不懂 apply 的用法,只要把 loc/iloc 改成 at/iat,依然可以有明显的提速。另外,DataFrame 的栏位很多的时候,apply_limit 方法其实会比对对整个数据框 apply 快很多(因为不用每次读取整个数据框),只是示范数据的栏位不多所以在这里显现不出差异。
pandas 的数组操作和 numpy 的数组操作单独对比:
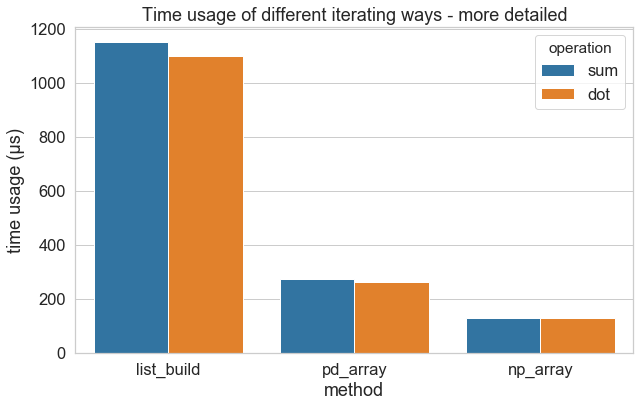
列表构造的运行速度是毫秒级的,数组操作是微秒级,np 数组操作是 pd 数组操作的两倍。
作图代码
x = ['loop+iloc','loop+iat','iterrows','apply','apply_limit','list_build','pd_array','np_array']y_sum = [2.06*1000 , 56.9, 358, 93, 90.3, 1.15, 273/1000, 130/1000] # 單位: msy_dot = [2.04*1000 , 58.4, 342, 89.1, 90.7, 1.10, 263/1000, 131/1000] # 單位: msres = pd.DataFrame({'method': x*2, 'time': y_sum + y_dot, 'operation': ['sum']*len(x) + ['dot']*len(x)})import matplotlib.pyplot as pltimport seaborn as sns%matplotlib inlinesns.set_style('whitegrid')plt.figure(figsize=(10, 6))with sns.plotting_context("notebook", font_scale=1.5):ax = sns.barplot(x='method', y='time', hue='operation', data=res)plt.title('Time usage of different iterating ways')plt.ylabel('time usage (ms)')plt.figure(figsize=(10, 6))with sns.plotting_context("notebook", font_scale=1.5):ax = sns.barplot(x='method', y='time', hue='operation', data=res[~res.method.isin(['loop+iloc','iterrows'])])plt.title('Time usage of different iterating ways - detailed')plt.ylabel('time usage (ms)')res_2 = res[res.method.isin(['list_build','pd_array','np_array'])].copy()res_2['time'] = res_2['time'].values * 1000plt.figure(figsize=(10, 6))with sns.plotting_context("notebook", font_scale=1.5):ax = sns.barplot(x='method', y='time', hue='operation', data=res_2)plt.title('Time usage of different iterating ways - pd_series vs np_array')plt.ylabel('time usage (µs)')
结论
优先使用 numpy 数组操作!不能数组操作的时候用列表构造!
能用 at/iat 就不用 loc/iloc,能用 apply 就不用迭代,能用数组操作就不用其他方法。
运行速度:np 数组操作 > pd 数组操作 >>> np 列表构造 = pd 列表构造 >>> for 循环 + at > pd(分片).apply > pd.apply >>> pd.iterrows > for 循环 + iloc
关于 at/iat 和 loc/iloc 的速度比较,请见参考资料[4]。
参考资料

若有收获,就点个赞吧
0 人点赞
