requests:基于网络请求的模块,功能强大,效率极高
作用:模拟浏览器发请求
如何使用:(requests模块的编码流程)
- 指定url
- 发起请求
- 获取响应数据
- 持久化存储(数据)
基础案例
1、爬取搜狗指定词条对应的搜索结果页面(简易网页采集器)
可能出现的问题
- 乱码的问题:响应数据不是‘utf-8’格式(原因),用.encoding=’utf-8’转换编码格式(解决方法)
- 数据丢失(比人工浏览到的数据少):异常访问请求(没有伪请求头UA-headers)
```python
encoding: utf-8
“”” @author: linpions @software: PyCharm @file: 案例1:爬取搜狗词条结果.py @time: 2021-12-26 20:10 “””
import requests
url = ‘https://www.sogou.com/web‘ keywords = input(‘enter a key word:’) headers = { ‘User-Agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36’ }
实现参数动态化
params参数(字典):保存请求时URL携带的参数
params = { ‘query’: keywords, }
response = requests.get(url=url, params=params, headers=headers) response.encoding = ‘utf-8’ page_text = response.text
file_Name = ‘搜狗词条:’ + keywords + ‘.html’ with open(file_Name, ‘w’, encoding=’utf-8’) as fp: fp.write(page_text) print(file_Name, ‘爬取完毕!’)
<a name="DhTVW"></a>### 2、破解百度翻译- url: https://fanyi.baidu.com/v2transapi?from=en&to=zh- 局部刷新,Ajax请求```pythondef baidu_fanyi(keyword=None):url = 'https://fanyi.baidu.com/v2transapi'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/''92.0.4515.131 Safari/537.36','cookie': 'BIDUPSID=2437C970398B3648E3DCEFC3DA3F453F; PSTM=1588134641; BDUSS=2FNVTNXWFREN3lOS2VZWlh6eHJvcjdUWGN4d3RueWRKaGVCYWtJWHV6QnVDdjFmRVFBQUFBJCQAAAAAAAAAAAEAAADdjgBCwe7GvdfTAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAG591V9ufdVfN; BDUSS_BFESS=2FNVTNXWFREN3lOS2VZWlh6eHJvcjdUWGN4d3RueWRKaGVCYWtJWHV6QnVDdjFmRVFBQUFBJCQAAAAAAAAAAAEAAADdjgBCwe7GvdfTAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAG591V9ufdVfN; H_WISE_SIDS=110085_127969_128701_131423_144966_154214_156927_160878_164955_165135_165328_166148_167069_167112_167300_168029_168542_168626_168748_168763_168896_169308_169536_169882_170154_170240_170244_170330_170475_170548_170578_170581_170583_170588_170632_170754_170806_171446_171463_171567_171581; __yjs_duid=1_583e334168fb61ad031df70449fa28b11620848721011; BAIDUID=88DF09015FADA78B679498D7716BC9F3:FG=1; BAIDUID_BFESS=9AC90C484D04DC1AD589BE66E2DC00C5:FG=1; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1629183095; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1629184241; __yjs_st=2_ZDRiNjhmMDM0ZWI2MTRmM2MyZDYyZDg3NTg5NGFhZmJkNmQzODZjZmUxNGQ5NmYxZmIyNTRiOTg1Y2Y5NjYzMDM0NzMzNWVjYTYyYjNjMjlkMThmZWRhYjZhZWYzNzliZjI1ZWM2YjExZmJlODUyMTI3YjFjNTU4Y2I5OGM1ZGFjNzNmNDA0N2Q2NjAzYzY4ZDZiYzUzZTcxYzE1ZjA5OTAwMmVkNWM2YjlmYTFjY2U3ZTQwOWU4NzVhZTlmMDEyYmU3NDVhYTVmOWEyYTVjOGUxNzUzNjI2Y2U3NTRkNmQyYTExMjUzNGJhYWVkMzgyOTMzZDFjOTVhOGVhODM3OV83XzI0MTkxNGNi; ab_sr=1.0.1_ZDg0NDMwZGY4ZWZiMTA5YjgzMmVlMDU0M2MxZDRkMzY4NDQ3MGI4YThlNjNhYTFiMGJhZTUzNzRkZTI5NjI5NzUwMGNkYjBmZTQ3MTBhN2FkMjgyMDg5OGNkMTkyOTg5M2UxYmNjYmE3NzUyZGM1ZGM4N2M5NzliNzBlYTg3ZTJlNjMwNTU3OTdjMmFkNTRjMDg3OTEyMDJiMjg2MmU5NGMzZjdiM2U3NjUyZTBjNjg1ODEyYTc5Yzk5MTI5NTAw',}data = {'from': 'en','to': 'zh','query': keyword,'transtype': 'realtime','simple_means_flag': '3','sign': '871501.634748','token': '6567483e2686ce76cd8bbdb797a1a5bd','domain': 'common',}response = requests.post(url=url, data=data, headers=headers)page_text = response.json()# page_text = page_text['data']return page_text
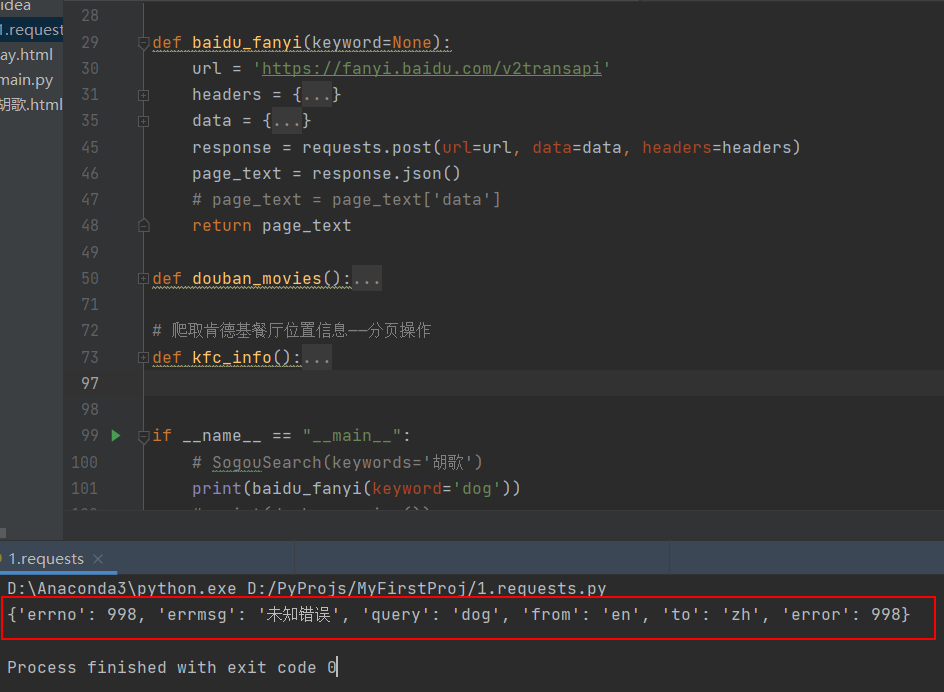
当改变要翻译的内容时,返回的不是想要的结果,出现997/998错误
原因:百度翻译增加了反爬机制,所以爬虫程序获取不到翻译结果了;参考分析方式进行学习;因为你被反爬了,headers(重点是useragent)和代理ip和动态验证码,这三个加上基本就没问题了
【Python】关于爬取百度翻译以及”errno”:998&”errno”:997_RedMaple-程序员宅基地
- sign、cookie是动态的,会变
解决方案:
- 修改url为手机版的地址:http://fanyi.baidu.com/basetrans 或者 https://fanyi.baidu.com/sug
User-Agent也用手机版的
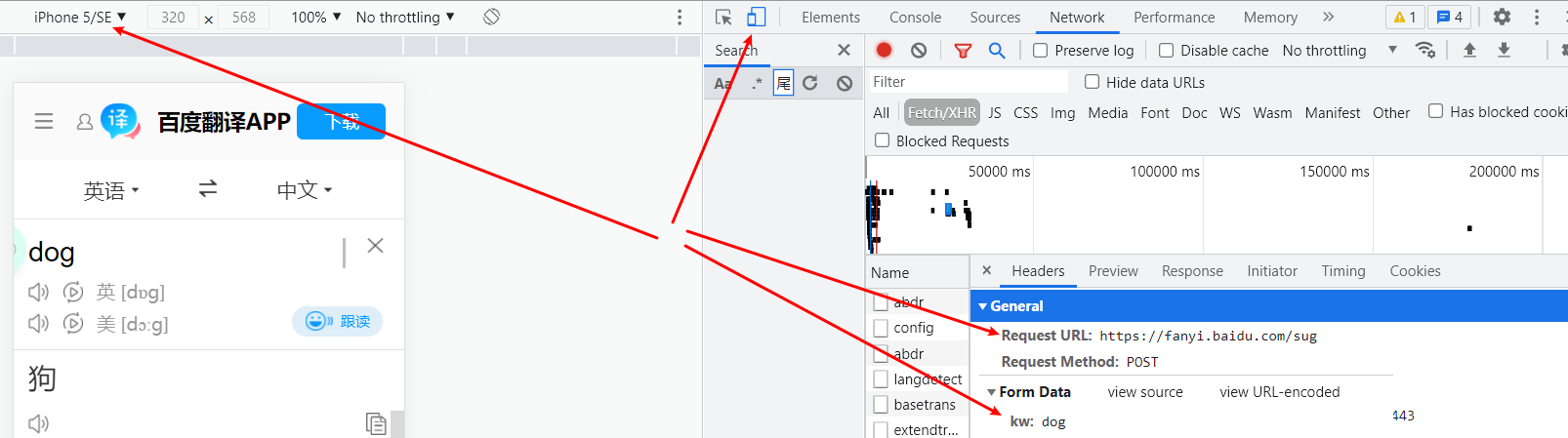
# 解决cookie和sign动态变化问题def baidu_fanyi2(keyword=None):url = 'https://fanyi.baidu.com/sug'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/''92.0.4515.131 Safari/537.36',# 'cookie': 'BIDUPSID=2437C970398B3648E3DCEFC3DA3F453F; PSTM=1588134641; BDUSS=2FNVTNXWFREN3lOS2VZWlh6eHJvcjdUWGN4d3RueWRKaGVCYWtJWHV6QnVDdjFmRVFBQUFBJCQAAAAAAAAAAAEAAADdjgBCwe7GvdfTAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAG591V9ufdVfN; BDUSS_BFESS=2FNVTNXWFREN3lOS2VZWlh6eHJvcjdUWGN4d3RueWRKaGVCYWtJWHV6QnVDdjFmRVFBQUFBJCQAAAAAAAAAAAEAAADdjgBCwe7GvdfTAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAG591V9ufdVfN; H_WISE_SIDS=110085_127969_128701_131423_144966_154214_156927_160878_164955_165135_165328_166148_167069_167112_167300_168029_168542_168626_168748_168763_168896_169308_169536_169882_170154_170240_170244_170330_170475_170548_170578_170581_170583_170588_170632_170754_170806_171446_171463_171567_171581; __yjs_duid=1_583e334168fb61ad031df70449fa28b11620848721011; BAIDUID=88DF09015FADA78B679498D7716BC9F3:FG=1; BAIDUID_BFESS=9AC90C484D04DC1AD589BE66E2DC00C5:FG=1; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1629183095; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1629184241; __yjs_st=2_ZDRiNjhmMDM0ZWI2MTRmM2MyZDYyZDg3NTg5NGFhZmJkNmQzODZjZmUxNGQ5NmYxZmIyNTRiOTg1Y2Y5NjYzMDM0NzMzNWVjYTYyYjNjMjlkMThmZWRhYjZhZWYzNzliZjI1ZWM2YjExZmJlODUyMTI3YjFjNTU4Y2I5OGM1ZGFjNzNmNDA0N2Q2NjAzYzY4ZDZiYzUzZTcxYzE1ZjA5OTAwMmVkNWM2YjlmYTFjY2U3ZTQwOWU4NzVhZTlmMDEyYmU3NDVhYTVmOWEyYTVjOGUxNzUzNjI2Y2U3NTRkNmQyYTExMjUzNGJhYWVkMzgyOTMzZDFjOTVhOGVhODM3OV83XzI0MTkxNGNi; ab_sr=1.0.1_ZDg0NDMwZGY4ZWZiMTA5YjgzMmVlMDU0M2MxZDRkMzY4NDQ3MGI4YThlNjNhYTFiMGJhZTUzNzRkZTI5NjI5NzUwMGNkYjBmZTQ3MTBhN2FkMjgyMDg5OGNkMTkyOTg5M2UxYmNjYmE3NzUyZGM1ZGM4N2M5NzliNzBlYTg3ZTJlNjMwNTU3OTdjMmFkNTRjMDg3OTEyMDJiMjg2MmU5NGMzZjdiM2U3NjUyZTBjNjg1ODEyYTc5Yzk5MTI5NTAw',}data = {'kw': keyword,}response = requests.post(url=url, data=data, headers=headers)page_text = response.json()# page_text = page_text['data']return page_text
3、爬取豆瓣电影详情数据
难题:动态加载的数据
动态加载的数据:
- 无法每次实现可见即可得
- 非固定URL请求到的数据
判断是否动态加载数据小技巧:进入抓包工具,在preview页面搜索页面数据,不能搜索到即为动态加载
定位数据包(不是都能定位到):原因:如果动态加载的数据是经过加密的密文数据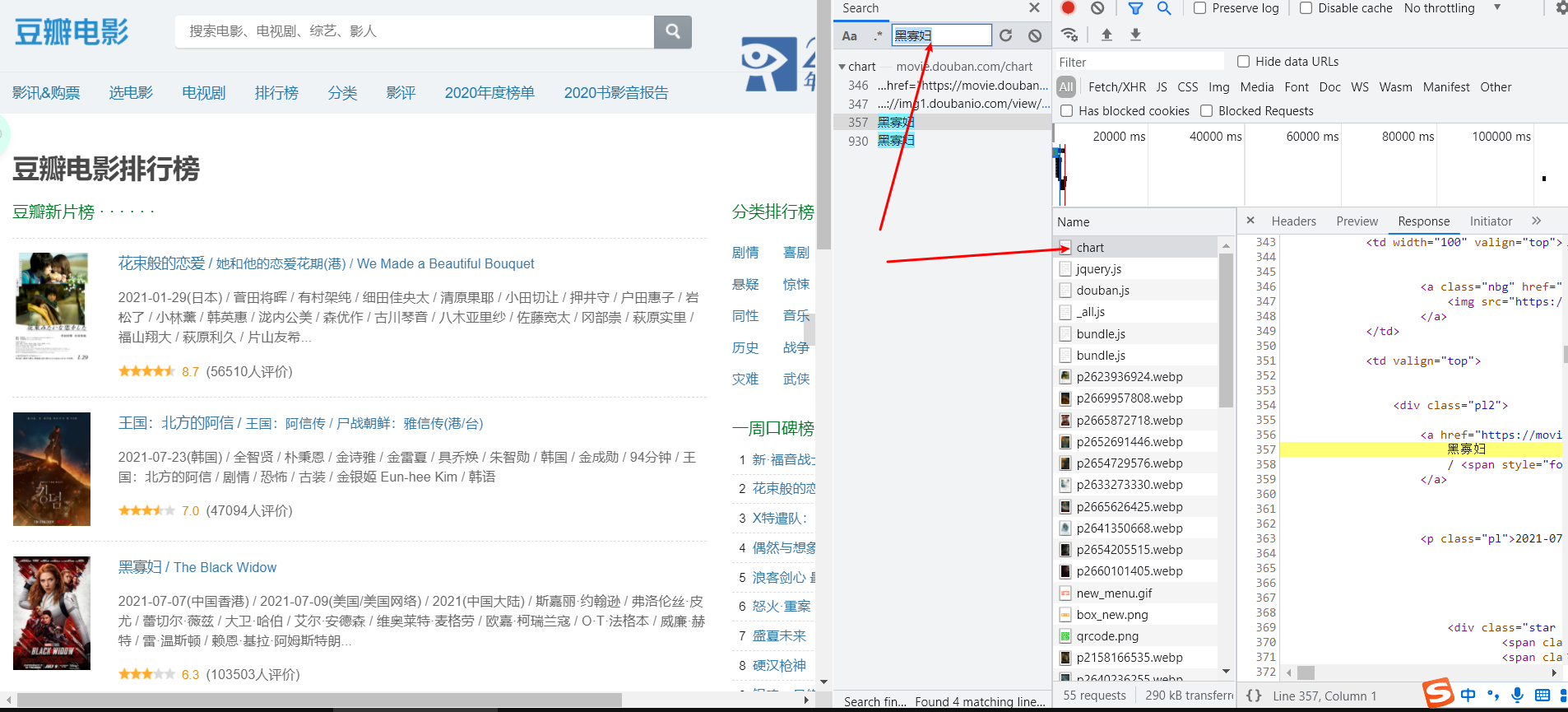
从该数据包可以获取:
- 请求的URL
- 请求方式
- 请求携带的参数
- 看到响应的数据
解析json数据时出错:【Python】JSONDecodeError: Expecting value: line 1 column 1 (char 0)
https://blog.csdn.net/qq_29757283/article/details/98252728
原因:但是因为传递给 json.loads 的参数不符合 JSON 格式,所以抛出异常。
- 键值对使用单引号而非双引号。
- 参数为(或含有)普通的字符串格式(plain or html)。
pandas创建空dataframe
Python Pandas 向DataFrame中添加一行/一列
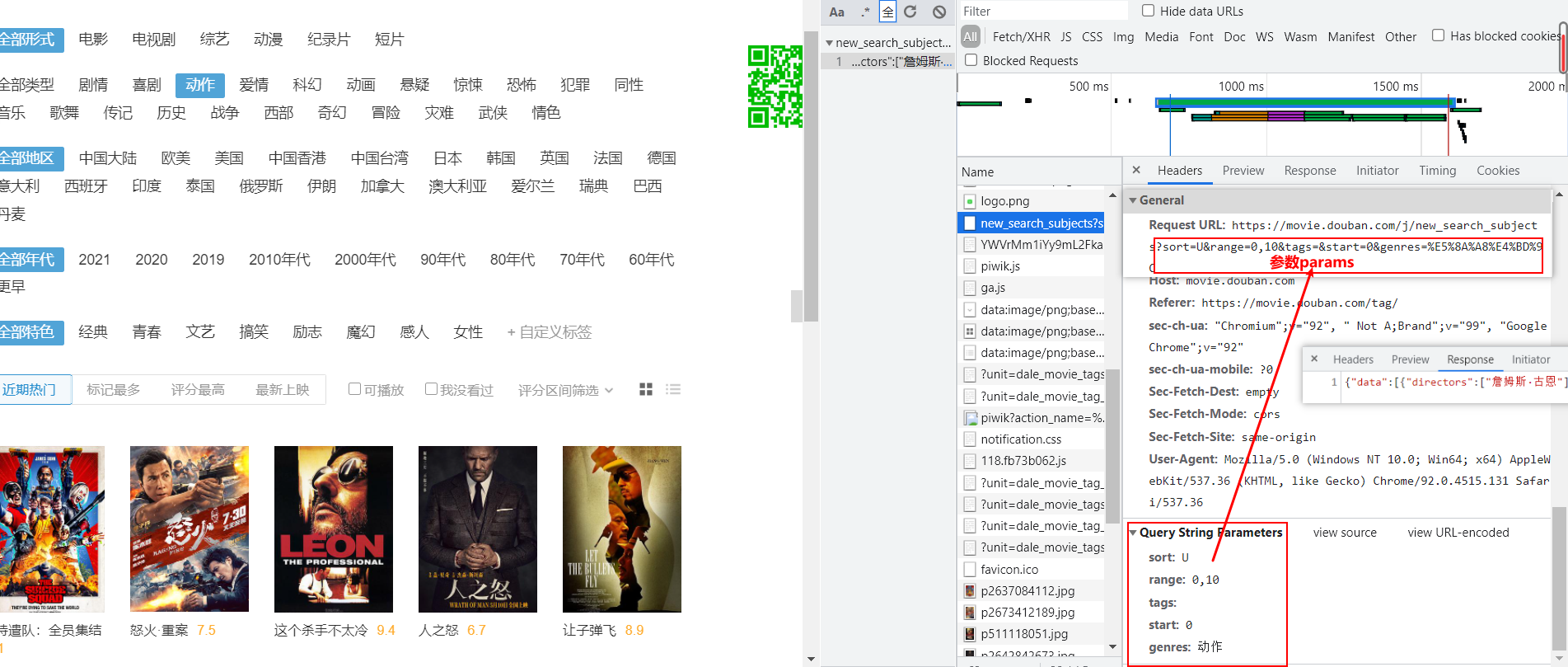
def douban_movies():url = 'https://movie.douban.com/j/new_search_subjects'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/''92.0.4515.131 Safari/537.36'}params = {'sort': 'U','range': '0,10','tags': '','start': '0',}response = requests.get(url=url, params=params, headers=headers)page_text = response.json() # .json()获取字符串形式的json数据序列化成列表df = pd.DataFrame(columns=['电影名', '评分']) # 数据写入dataframe# 解析出电影的名称+评分id = 0for movie in page_text['data']:df.loc[id] = [movie['title'], movie['rate']]id += 1return df# 多次爬取后有反爬机制,需登录操作
4、分页操作——爬取肯德基餐厅位置
- URL:http://www.kfc.com.cn/kfccda/storelist/index.aspx
- 录入关键字并按搜索才加载出位置信息:发起的是Ajax请求
- 基于抓包工具定位到该Ajax请求的数据包,从该数据包中捕获到:
- 请求的URL
- 请求方式(GET or POST)
- 请求携带的参数(一般在headers最后)
- 看到响应数据
- 跟GET请求参数动态化的封装不同的是封装为data,不是params
爬取多页数据:修改参数并加入循环 ```python def kfc_info(): url = ‘http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword‘ headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/''92.0.4515.131 Safari/537.36'
} df = pd.DataFrame(columns=[‘餐厅名’, ‘详细位置’]) id = 0 for page in range(1, 9):
data = {'cname': '','pid': '','keyword': '广州','pageIndex': str(page),'pageSize': '10',}response = requests.post(url=url, data=data, headers=headers)page_text = response.json()for dic in page_text['Table1']:df.loc[id] = [dic['storeName'], dic['addressDetail']]id += 1
return df
<a name="axdgb"></a>### 5、药监局数据爬取[药监局](http://scxk.nmpa.gov.cn:81/xk/)中的企业详情数据<br />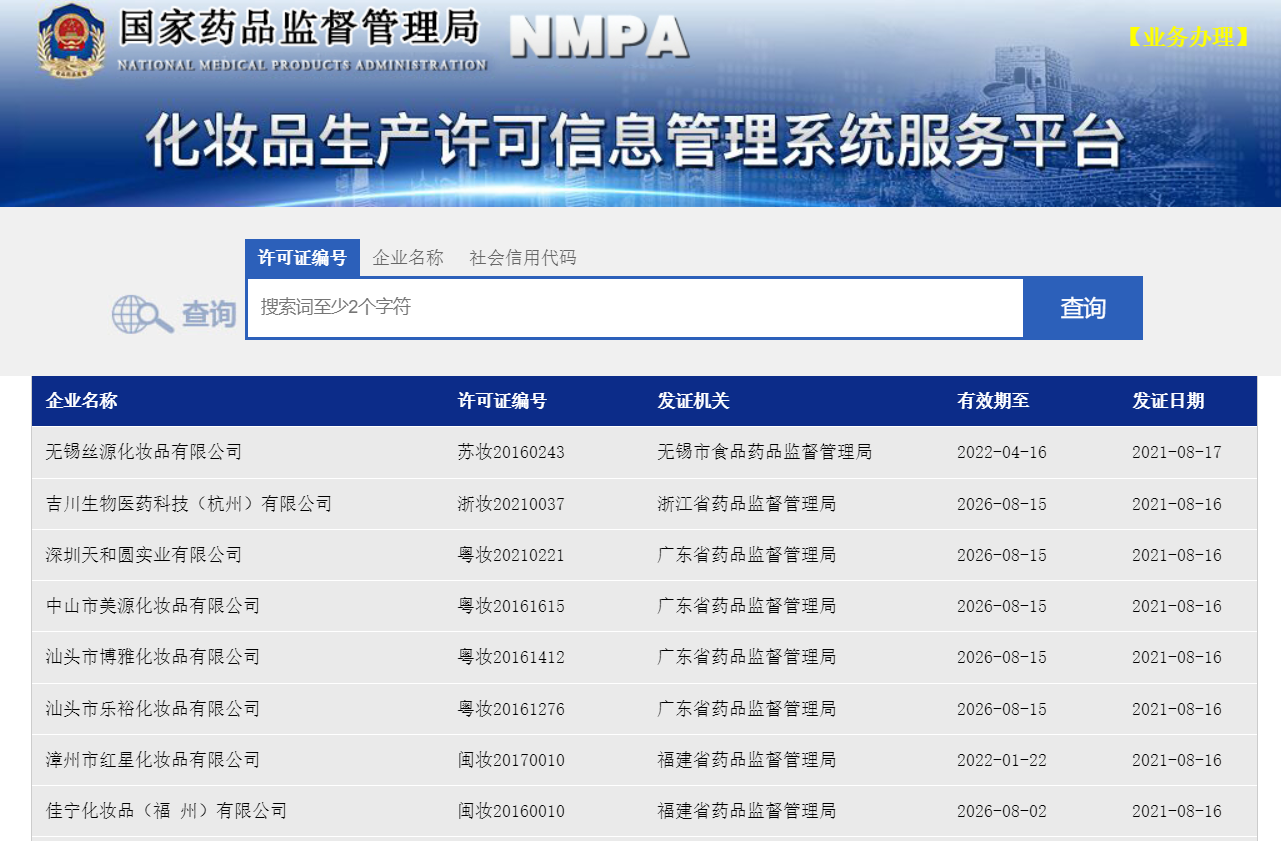<br />- 不用数据解析- 数据都是动态出来的(Ajax请求)- 突破点:每个企业的详情页的参数id是列表页的id```pythondef get_canpanysid(pageNum=None):url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/''92.0.4515.131 Safari/537.36'}df = pd.DataFrame(columns=['企业名称', 'ID'])id = 0for page in range(1, pageNum+1):data = {'on': 'true','page': str(page),'pageSize': '15','productName': '','conditionType': '1','applyname': '','applysn': '',}response = requests.post(url=url, data=data, headers=headers)page_text = response.json()for dic in page_text['list']:df.loc[id] = [dic['EPS_NAME'], dic['ID']]id += 1return dfdef get_canpanysinfo(pageNum=None):url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/''92.0.4515.131 Safari/537.36'}df = pd.DataFrame(columns=['企业名称', '许可证编号', '许可项目', '企业住所', '生产地址', '社会信用代码', '法定代表人','企业负责人', '质量负责人', '发证机关', '签发人', '日常监督管理机构', '日常监督管理人员','有效期至', '发证日期', '状态', '投诉举报电话'])ID_df = get_canpanysid(pageNum=pageNum)id = 0for ID in ID_df['ID']:data = {'id': ID,}response = requests.post(url=url, data=data, headers=headers)response.encoding = 'utf-8'page_text = response.json()df.loc[id, '企业名称'] = page_text['epsName']df.loc[id, '许可证编号'] = page_text['productSn']df.loc[id, '许可项目'] = page_text['certStr']df.loc[id, '企业住所'] = page_text['epsAddress']df.loc[id, '生产地址'] = page_text['epsProductAddress']df.loc[id, '社会信用代码'] = page_text['businessLicenseNumber']df.loc[id, '法定代表人'] = page_text['legalPerson']df.loc[id, '企业负责人'] = page_text['businessPerson']df.loc[id, '质量负责人'] = page_text['qualityPerson']df.loc[id, '发证机关'] = page_text['qfManagerName']df.loc[id, '签发人'] = page_text['xkName']df.loc[id, '日常监督管理机构'] = page_text['rcManagerDepartName']df.loc[id, '日常监督管理人员'] = page_text['rcManagerUser']df.loc[id, '有效期至'] = page_text['xkDate']df.loc[id, '发证日期'] = page_text['xkDateStr']df.loc[id, '状态'] = '正常'df.loc[id, '投诉举报电话'] = '12331'id += 1df.to_csv('canpanysinfo.csv', encoding='utf-8')return df

若有收获,就点个赞吧
0 人点赞
