https://www.jianshu.com/p/f7cb0b3f337a 下载安装教程
官方网站:https://github.com/tesseract-ocr/tesseract
官方文档:https://github.com/tesseract-ocr/tessdoc
语言包地址:https://github.com/tesseract-ocr/tessdata
下载地址:https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w64-setup-v5.0.0.20211201.zip
- 安装:需额外下载中文包(如果要识别中文)
- 配置环境变量:安装目录
C:\Program Files\Tesseract-OCRC:\Program Files\Tesseract-OCR\tessdata - 验证是否配置成功:cmd 输入 tesseract 回车,看信息即可
方式1:cmd 识别
进入cmd
输入:tesseract 图片路径 识别结果文件名(.txt)
方式2:python识别
- 安装库:pytesseract pillow
- 脚本示例 ```python import pytesseract from PIL import Image
img_path = ‘test.png’ im = Image.open(img_path)
识别文字
string = pytesseract.image_to_string(im, lang=”eng”, config=”—psm 7”) # 识别数字和字母要加后面两个参数 print(string)
如识别报错,则如下操作:<br />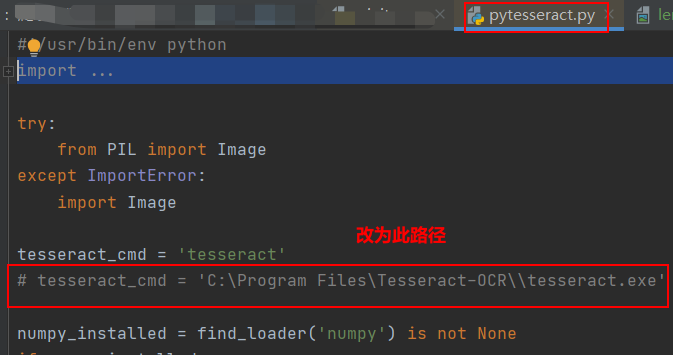<br />中文语言包训练集下载<a name="KhtD2"></a># 应用一:识别PDF**原理解释:**1. 用 pdf2image 中的 convert_from_path 将 pdf 文件转化为 ppm 文件(图片)1. 用 numpy.array 将 ppm 文件转化为三维矩阵1. 用 pytesseract.image_to_string 识别图像矩阵中的文字1. 输出文本信息,并进行校对,可以借助 word 等软件进行拼写检测```pythonimport numpy as npimport pytesseractfrom pdf2image import convert_from_pathdef pdf_ocr(fname, **kwargs):images = convert_from_path(fname, **kwargs)text = ''for img in images:img = np.array(img)text += pytesseract.image_to_string(img)return textfname = 'example.pdf'# text = pdf_ocr(fname, first_page=7, last_page=8)text = pdf_ocr(fname)print(text)

若有收获,就点个赞吧
0 人点赞
