「二分查找」的思想在我们的生活和工作中很常见,「二分查找」通过不断缩小搜索区间的范围,直到找到目标元素或者没有找到目标元素。这里「不断缩小搜索区间」是一种 减而治之 的思想,也称为减治思想。
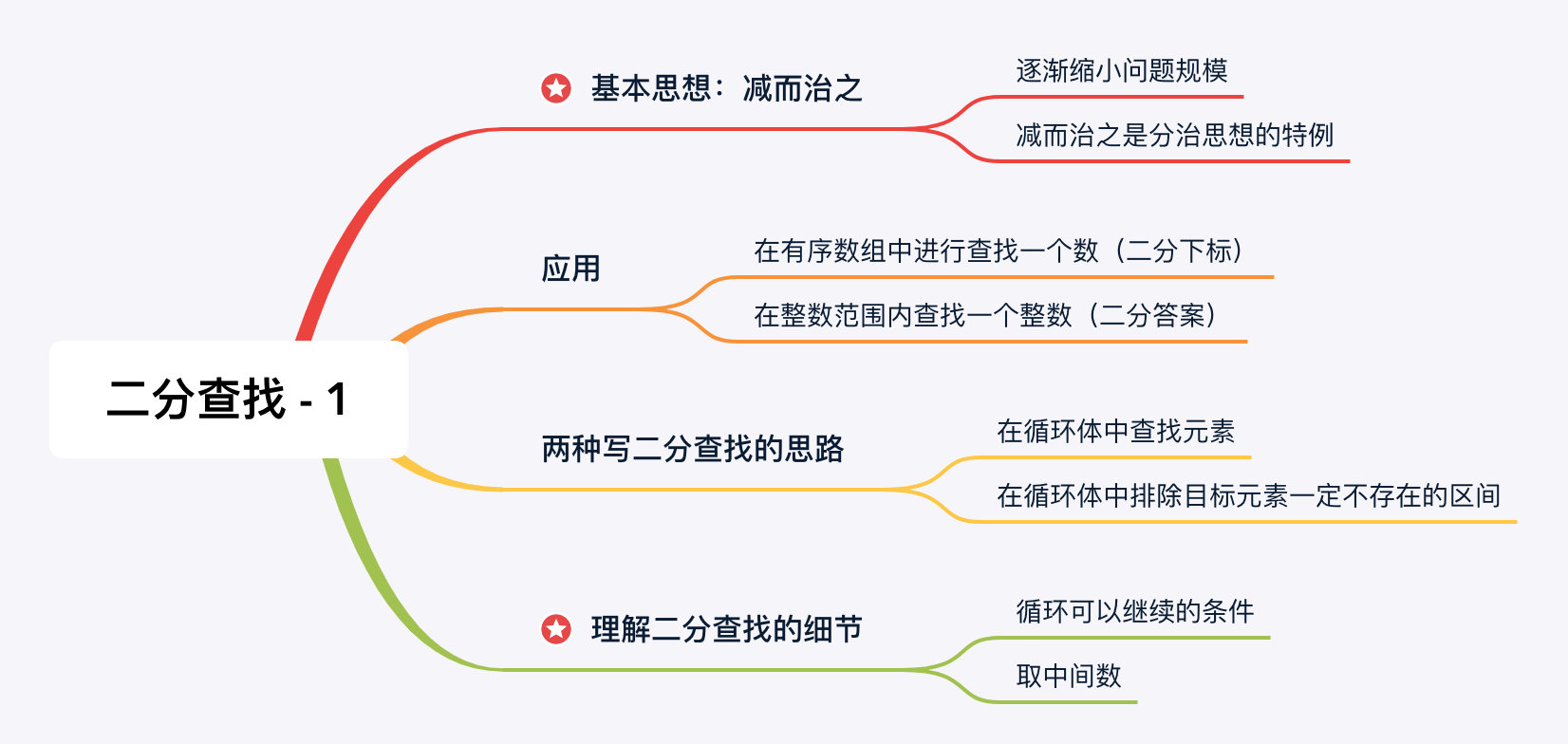
一、「减而治之」思想简介
这里「减」是「减少问题」规模的意思,治是「解决」的意思。「减治思想」从另一个角度说,是「排除法」,意即:
- 每一轮排除掉一定不存在目标元素的区间,在剩下 可能 存在目标元素的区间里继续查找。福尔摩斯说过当你排除一切不可能的情况,剩下的,不管多难以置信,那都是事实
- 每一次我们通过一些判断和操作,使得问题的规模逐渐减少。
- 又由于问题的规模是有限的,我们通过有限次的操作,一定可以解决这个问题。
可能有的朋友听说过「分治思想」,「分治思想」与「减治思想」的差别就在于,我们把一个问题拆分成若干个子问题以后,应用「减治思想」解决的问题就只在其中一个子问题里寻找答案。「分治思想」我们在下一章会向大家介绍。
例 1:以前央视二套的《幸运 52》栏目有一个「猜价格」游戏。游戏规则是:给出一个商品,告诉答题者它的价格在多少元(价格为整数)以内,让答题者猜,如果猜出的价格低于真正价格,主持人就说少了,高于真正的价格,就说多了,看谁能在最短的时间内猜中。这个游戏就是应用减治思想完成「猜价格」任务的。主持人说「多了」或这「少了」,就是给参与游戏的人反馈,让游戏者逐渐缩小价格区间,最终猜中价格。
例 2:不知道大家小时候查《新华字典》的时候是怎么查的,我经常不翻目录,直接根据要找的字的拼音,在字典里翻页。例如要找的字是「算」(汉语拼音首字母为 S),如果一开始翻到了 L 开头的页,那么我就会在 L 开头的页后面的页里任意挑一页。如果看到的是 T 开头的页,我就会在 T 开头的页前面的页里任意挑一页,这样的查字典的策略就应用了减治思想。
例 3:相信有不少程序员定位程序中的 bug 的时候,会在程序里打印一些变量的输出语句,逐步定位有问题的代码的行,这样的定位问题的方法也应用了「减治思想」
二、二分查找算法的**应用范围
在有序数组中进行查找一个数(二分下标)
这里「数组」和「有序」**是很重要的,我们知道:
- 数组具有 随机访问 的特性,由于数组在内存中 连续存放,因此我们可以通过数组的下标快速地访问到这个元素。
- 如果数据存放在链表中,访问一个元素我们都得通过遍历,有遍历的功夫我们早就找到了这个元素,因此,在链表中不适合使用二分查找。
在整数范围内查找一个整数(二分答案)
如果我们要找的是一个整数,并且我们知道这个整数的范围,那么我们就可以使用二分查找算法,逐渐缩小整数的范围。这一点其实也不难理解,假设我们要找的数最小值为 00,最大值为 NN,我们就可以把这个整数想象成数组 [0, 1, 2,…, N] 里的一个值,这个数组的下标和值是一样的,找数组的下标就等于找数组的值。这种二分法用于查找一个有范围的数,也被称为「二分答案」,或者「二分结果」,也就是在「答案区间」里或者是「结果区间」里逐渐缩小目标元素的范围;
在我们做完一些问题以后,我们就会发现,其实二分查找不一定要求目标元素所在的区间是有序数组,也就是说「有序」这个条件可以放宽,半有序数组或者是山脉数组里都可以应用二分查找算法。
旋转数组和山脉数组有什么样的特点呢?可以通过当前元素附近的值推测出当前元素一侧的所有元素的性质,也就是说,旋转和山脉数组的值都有规律可循,元素的值不是随机出现的,在这个特点下,「减治思想」就可以应用在旋转数组和山脉数组里的一些问题上。我们可以把这两类数组统一归纳为部分有序数组。
三、二分查找算法的两种思路
我们这一章节向大家介绍两种编写二分查找算法的思路,它们仅仅只是在一些细节上有所不同,基本的思想都是减而治之。
思路 1:在循环体中查找元素(本节介绍)
思路 2:在循环体中排除目标元素一定不存在的区间(下一节介绍)
四、二分查找的最基本问题
一个最基本的「二分查找」问题是「力扣」第 704 题:二分查找。题目要求我们在一个有序数组里查找目标元素的下标,目标元素不存在,返回 -1−1。注意,这里题目中说:你可以假设数组中的元素是不重复。
分析:解决这个问题的思路和「猜价格」游戏是一样的。由于数组是有序且升序的数组,二分查找的思路是,先看位于数组中间的那个元素的值:
如果中间的那个元素正好等于目标元素,我们就可以直接返回这个元素的下标;
否则我们就需要在中间这个元素的左边或者右边继续查找。
下面我们来看一下代码:
参考代码 1:
/*** @description:* @param {Array} nums* @param {Number} target* @return {Number}*/// right = nums.length -1function binarySearch(nums, target) {let left = 0, right = nums.length - 1;while(left <= right) {let mid = left + ((right-left)>>1);if(nums[mid] == target) return mid; // 在循环体中找到了元素就直接返回else if (nums[mid] < target) left = mid + 1;else if (nums[mid] > target) right = mid - 1;return -1;}
说明:
这里应用的是二分查找算法的思路 1,在循环体中找到了元素就直接返回
我们每一次都会在一个区间里搜索目标元素。表示这个区间需要两个变量,那就是数组里区间的左右边界,分别用变量
left和right表示,一开始的时候,左边界的值等于0,右边界的值等于数组的长度减1;接下来我们在一个循环体里面处理,循环可以继续的条件是
left <= right,表示:在区间只有 1 个元素的时候,依然需要进行相关逻辑的判断。这个逻辑是,先看一下区间里位于中间的那个元素的值:如果它是目标元素,就直接返回它的下标。如果不是,可以根据中间元素的左边区间和右边区间的所有元素的数值,看看目标元素应该落在哪个区间里;
如果中间位置的元素比目标元素严格小,由于整个数组是有序的,中间位置以及中间位置的左边的所有元素的数值一定比目标元素小,那么下一轮搜索就应该在 [mid + 1, right] 左闭右闭这个区间里查找,这个时候我们将左边界 left 的值设置为 mid + 1
否则,中间位置的元素比目标元素严格大,依然是由于整个数组是有序的,中间位置以及中间位置的右边的所有元素的数值一定比目标元素大,那么下一轮搜索就应该在 [left, mid - 1] 左闭右闭这个区间里查找,这个时候我们将右边界 right 的值设置为 mid - 1 。
退出循环以后,表示这个数组里不存在目标元素,根据题目意思,返回 -1−1。
复杂度分析:
时间复杂度:二分查找的时间复杂度是 O(logN),这里 N 是输入数组的长度;
怎么理解这个表达式呢?我们知道复杂度表示的算法的操作数和是输入数据的规模 NN 之间的关系,由于二分查找每一次都将问题近似地缩减为上一次问题规模的一半,最差情况下,也就是没有找到目标元素的时候,最后两步,区间里剩下的元素个数依次为 1 和 0。我们把问题的规模依次列出来,是这样的:
由于循环体内部的操作次数是常数次的,因此循环体执行的次数就是「二分查找」算法的时间复杂度。循环体执行的次数就是从 N 到 1 这个等比数列的项数,由于这个等比数列的公比是  ,我们依据高中学习过的对数的定义,就知道了,从 N 到 1 这个等比数列的项数为
,我们依据高中学习过的对数的定义,就知道了,从 N 到 1 这个等比数列的项数为  。为什么是上取整呢,因为这里的 N 有可能不是 2 的方幂。又由于我们计算复杂度的时候,常数加法项忽略,因此时间复杂度是 O(logN)。空间复杂度:由于二分查找算法在执行的过程中只使用到常数个临时变量,因此空间复杂度是 O(1)。
。为什么是上取整呢,因为这里的 N 有可能不是 2 的方幂。又由于我们计算复杂度的时候,常数加法项忽略,因此时间复杂度是 O(logN)。空间复杂度:由于二分查找算法在执行的过程中只使用到常数个临时变量,因此空间复杂度是 O(1)。
补充说明:这一题还有「递归」的写法,感兴趣的朋友可以查阅资料写出递归的写法。
二分查找的细节(重点)
「二分查找」算法,初学的朋友真正在使用的时候,可能会遇到各种各样的问题。什么样的问题呢?
我看到别人写的二分查找的代码的写法跟我在课本上学习的写法不太一样,他们的代码是什么意思?为什么要这样写?
在这一章节我们就依次回答这些问题,并且对它们作一些比较。
细节 1:循环可以继续的条件
while (left <= right) 表示在区间里只剩下一个元素的时候,我们还需要继续查找,因此循环可以继续的条件是 left <= right,这一行代码对应了二分查找算法的思路 1:在循环体中查找元素。
细节 2:取中间数的代码
取中间数的代码 int mid = (left + right) / 2; ,严格意义上是有 bug 的,这是因为在 left 和 right 很大的时候,left + right 有可能会发生整型溢出,这个时候推荐的写法是:
let mid = left + (right - left) / 2;
这里要向大家说明的是 /2 这个写法表示 下取整。这里可能有的朋友有疑问:这里取中间位置元素的时候,为什么是取中间靠左的这个位置,能不能取中间靠右那个位置呢?答案是完全可以的。先请大家自己思考一下这个问题,我们放在细节 3 说。
有些朋友可能会看到 int mid = (left + right) >> 1; 这样的写法,这是因为整数右移 1 位和除以 2(向下取整)是等价的,这样写的原因是因为位运算比整除运算要快一点。但事实上,高级的编程语言,对于 / 2 和除以 2 的方幂的时候,在底层都会转化成为位运算,我们作为程序员在编码的时候没有必要这么做,就写我们这个逻辑本来要表达的意思即可,这种位运算的写法,在 C++ 代码里可能还需要注意优先级的问题。
在 Java 和 JavaScript 里有一种很酷的写法:
int mid = (left + right) >>> 1;
这种写法也是完全可以的,这是因为 **>>> **是无符号右移,在 left + right 发生整型溢出的时候,右移一位,由于高位补 0 ,依然能够保证结果正确。如果是写 Java 和 JavaScript 的朋友,可以这样写。在 Python 语言里,在 32 位整型溢出的时候,会自动转成长整形,这些很细枝末节的地方,其实不是我们学习算法要关注的重点。
我个人认为这几种种写法差别不大,因为绝大多数的算法面试和在线测评系统给出的测试数据,数组的长度都不会很长,遇到 left + right 整型溢出的概率是很低的,我们推荐大家写 int mid = left + (right - left) / 2;,让面试官知道你注意了整型溢出这个知识点即可。
有趣的事:二分查找算法取中间数可能会发生整形溢出这件事,是隐含在这个算法中将近 10 年的 bug。这一点提示我们,可能我们在设计一个算法的时候,会认为这个算法是完美的,但是检验一个算法,得真正地把这个算法执行起来。作为工程师,我们需要解决算法在真正运行的过程中遇到的问题,尤其是大家学习到算法的高阶内容的时候,就会看到,很多时候,理论上看起来很完美的东西,真正应用于实践的时候,可能是另外一个样子,可能大家听过「最佳实践」这个词,作为工程师而言,实证的精神是必须具备的。
细节 3:取中间数可不可以上取整
我们在「细节 2」里介绍了 int mid = (left + right) / 2; 这个表达示里 / 2 这个除号表示的含义是下取整。很显然,在区间里有偶数个元素的时候位于中间的数有 2 个,这个表达式只能取到位于左边的那个数。一个很自然的想法是,可不可以取右边呢?遇到类似的问题,首先推荐的做法是:试一试就知道了,刚刚我们说了实证的精神,就把
let mid = (left + right + 1) / 2;// 或者let mid = left + (right - left + 1) / 2;
提交给「力扣」第 704 题的系统测评。结果是可以通过测评。
我们想一想这是为什么呢?因为我们的思路是根据中间那个位置的数值决定下一轮搜索在哪个区间,每一轮要看的那个数当然可以不必是位于中间的那个元素,靠左和靠右都是没有问题的。
甚至取到每个区间的三分之一、四分之一、五分之四,都是没有问题的。下面大家看到的这两种写法是可以通过系统测评的:
let mid = left + (right - left) / 3;let mid = left + 4 * (right - left) / 5;
一般而言,取位于区间起点二分之一处,首先是因为这样写简单,还有一个更重要的原因是:取中间位置的那个元素在平均意义下效果最好。这一点怎么理解呢?
我们还以《幸运 52》的「猜价格」游戏为例,如果主持人会要求在 11 到 100100 这个区间里猜商品的价格。
如果主持人说这个商品是一只圆珠笔,观众一开始猜的价格就不会太高;
如果主持人说这个商品是一只台灯,或者是一个书包,观众一开始猜的价格就不会太低。
那如果主持人什么都不说,是不是一开始猜 5050 会更好一点。也就是说,在没有任何「先验知识」的情况下,在搜索区间里猜中间位置是最好的。
练习
查阅资料,使用「递归」函数的写法完成「力扣」第 704 题:二分查找;
完成「力扣」第 374 题:猜数字大小。

若有收获,就点个赞吧
0 人点赞
