基础定义:
226. 翻转二叉树(简单)
114. 二叉树展开为链表(中等)
116. 填充每个节点的下一个右侧节点指针(中等)
所有回溯、动归、分治算法,其实都是树的问题,而树的问题就永远逃不开树的递归遍历框架这几行破代码:
/* 二叉树遍历框架 */void traverse(TreeNode root) {// 前序遍历traverse(root.left)// 中序遍历traverse(root.right)// 后序遍历}
上篇公众号文章让读者留言说说对什么问题还有疑惑,我接下来可以重点写一写相关的文章。结果还有很多读者说觉得「递归」非常难以理解,说实话,递归解法应该是最简单,最容易理解的才对,行云流水地写递归代码是学好算法的基本功,而二叉树相关的题目就是最练习递归基本功,最练习框架思维的。
我先花一些篇幅说明二叉树算法的重要性。
一、二叉树的重要性
举个例子,比如说我们的经典算法「快速排序」和「归并排序」,对于这两个算法,你有什么理解?如果你告诉我,
快速排序就是个二叉树的前序遍历,
归并排序就是个二叉树的后序遍历,
那么我就知道你是个算法高手了。
为什么快速排序和归并排序能和二叉树扯上关系?我们来简单分析一下他们的算法思想和代码框架:
快速排序的逻辑是
- 若要对
nums[low..high]进行排序,我们先找一个分界点p - 通过交换元素使得
nums[low..p-1]都小于等于nums[p], - 且
nums[p+1..high]都大于nums[p] - 两个指针相遇的时候就是排好本次排序的时候
- 然后递归地去
nums[low..p-1]和nums[p+1..high]中寻找新的分界点,最后整个数组就被排序了。
快速排序的代码框架如下:
function sort(arr, low, high) {
/****** 前序遍历位置 ******/
// 通过交换元素构建分界点 p
let p = partition(arr, low, high); // partition:分割
/**********递归**********/
sort(arr, low, p - 1);
sort(arr, p + 1, high);
}
// 分割函数
let partition = (arr, left, right) => {
// 取随机项作为基准
let pivot = arr[Math.floor(Math.random() * (right - left + 1)) + left],
i = left,
j = right;
while (i < j) {
// 循环,直到在左边区域找到比pivot大的元素
while(arr[i] < pivot) {
i++;
}
// 循环,直到在右边区域找到比pivot 小的元素
while(arr[j] > pivot) {
j--;
}
// 两个循环出来的时候, 刚好一个大一个小
// 交换就完事了
if(i < j) {
[arr[i], arr[j]] = [arr[j], arr[i]];
}
// 当数组中存在重复数据时,即都为datum,但位置不同
// 继续递增i,防止死循环
if (arr[i] === arr[j] && i !== j) {
i++
}
}
return i; // i 和 j 已经一样了
}
先构造分界点,然后去左右子数组构造分界点,你看这不就是一个二叉树的前序遍历吗?
再说说归并排序的逻辑,若要对 nums[low..hi] 进行排序(先拆分,再合并)
- 我们先对
nums[low..mid]排序, - 再对
nums[mid+1..high]排序, - 最后把这两个有序的子数组合并,整个数组就排好序了。
归并排序的代码框架如下:
function mergeSort (nums, low, high) {
let len = arr.length
if (len < 2) {
return arr
}
let middle = Math.floor(len/2)
//拆分成两个子数组
let left = arr.slice(0, middle)
let right = arr.slice(middle,len)
//递归拆分
let mergeSortLeft = mergeSort(left)
let mergeSortRight = mergeSort(right)
/****** 后序遍历位置 ******/
// 合并两个排好序的子数组
// 能到这一步的时候,已经分成一个一组了,
return merge( mergeSortLeft,mergeSortRight)
/************************/
}
function merge(left, right) {
const result = [];
while(left.length && right.length){
// 注意: 判断的条件是小于或等于,如果只是小于,那么排序将不稳定.
if(left[0] <= right[0]) {
//每次都要删除left或者right的第一个元素,将其加入result中
result.push(left.shift());
}
else{
result.push(right.shift());
}
}
//将剩下的元素加上
while (left.length) result.push(left.shift());
while (right.length) result.push(right.shift());
return result;
}
先对左右子数组排序,然后合并(类似合并有序链表的逻辑),你看这是不是二叉树的后序遍历框架?另外,这不就是传说中的分治算法嘛,不过如此呀。
如果你一眼就识破这些排序算法的底细,还需要背这些算法代码吗?这不是手到擒来,从框架慢慢扩展就能写出算法了。
说了这么多,旨在说明,二叉树的算法思想的运用广泛,甚至可以说,只要涉及递归,都可以抽象成二叉树的问题,所以本文和后续的 手把手带你刷二叉树(第二期) 以及 手把手刷二叉树(第三期),我们直接上几道比较有意思,且能体现出递归算法精妙的二叉树题目,东哥手把手教你怎么用算法框架搞定它们。
二、写递归算法的秘诀
我们前文 二叉树的最近公共祖先 写过,写递归算法的关键是要明确函数的「定义」是什么,然后相信这个定义,利用这个定义推导最终结果,绝不要跳入递归的细节。
怎么理解呢,我们用一个具体的例子来说,比如说让你计算一棵二叉树共有几个节点:
// 定义:count(root) 返回以 root 为根的树有多少节点
int count(TreeNode root) {
// base case
if (root == null) return 0;
// 自己加上子树的节点数就是整棵树的节点数
return 1 + count(root.left) + count(root.right);
}
这个问题非常简单,大家应该都会写这段代码,root 本身就是一个节点,加上左右子树的节点数就是以 root 为根的树的节点总数。
左右子树的节点数怎么算?其实就是计算根为 root.left 和 root.right 两棵树的节点数呗,按照定义,递归调用 count 函数即可算出来。
写树相关的算法,简单说就是,**先搞清楚当前 root 节点该做什么**,然后根据函数定义递归调用子节点,递归调用会让孩子节点做相同的事情。
我们接下来看几道算法题目实操一下。
三、算法实践
第一题、翻转二叉树
我们先从简单的题开始,看看力扣第 226 题「翻转二叉树」,输入一个二叉树根节点 root,让你把整棵树镜像翻转,比如输入的二叉树如下:
4
/ \
2 7
/ \ / \
1 3 6 9
算法原地翻转二叉树,使得以 root 为根的树变成:
4
/ \
7 2
/ \ / \
9 6 3 1
通过观察,我们发现只要把二叉树上的每一个节点的左右子节点进行交换,最后的结果就是完全翻转之后的二叉树。
可以直接写出解法代码:
// 将整棵树的节点翻转
TreeNode invertTree(TreeNode root) {
// base case
if (root == null) {
return null;
}
/**** 前序遍历位置 ****/
// root 节点需要交换它的左右子节点
TreeNode tmp = root.left;
root.left = root.right;
root.right = tmp;
// 让左右子节点继续翻转它们的子节点
invertTree(root.left);
invertTree(root.right);
return root;
}
这道题目比较简单,关键思路在于我们发现翻转整棵树就是交换每个节点的左右子节点,于是我们把交换左右子节点的代码放在了前序遍历的位置。
值得一提的是,如果把交换左右子节点的代码放在后序遍历的位置也是可以的,但是放在中序遍历的位置是不行的,请你想一想为什么?
放在中间,那么先做invert(left),再switch(把左边的移到右边去)然后invert(right),这次invert其实还是第一次invert的节点,左边invert两次,右边一次都没有。
首先讲这道题目是想告诉你,二叉树题目的一个难点就是,如何把题目的要求细化成每个节点需要做的事情。
这种洞察力需要多刷题训练,我们看下一道题。
第二题、填充二叉树节点的右侧指针
这是力扣第 116 题,看下题目:
首先,每个节点的 next 原本就指向 null。
- 对于每个节点 root,它的左孩子的 next 应改为指向它的右孩子(左右孩子肯定存在)
- 它的右孩子的 next 怎么找到右邻居呢?
- 只要 root.next 存在(只要爸爸有右邻居),就能保证 root.right 有右邻居,让 root.right.next 指向 root.next.left。如下图。

于是,每个节点的处理逻辑:
root.left.next = root.right; // 左孩子的next指向右孩子
if (root.next) { // 如果当前root有右邻居,则右孩子有右邻居:root.next.left
root.right.next = root.next.left;
}
递归从上往下,先处理当前节点,再处理它的左、右子树中的节点 —— 前序遍历。
function dfs (root) {
节点root的处理逻辑
dfs(root.left)
dfs(root.right)
}
何时结束递归?当遍历到叶子节点,它没有孩子,不用修改孩子的 next 指向。
if (root.left == null && root.right == null) {
return;
}
代码:
const connect = (root) => {
if (root == null) {
return root;
}
dfs(root);
const dfs = (root) => {
// 子树为空
if (root.left == null && root.right == null) {
return;
}
// 左子树连右子树
root.left.next = root.right;
// 自己有右兄弟
if (root.next) {
// 有右兄弟就可以让右子树连
root.right.next = root.next.left;
}
dfs(root.left);
dfs(root.right);
};
return root;
};
复盘总结
- 对于整棵树的根节点,它的 next 是对的,不用修改。
- 下面的子节点的 next 是要修改的。所以可以用 DFS,从上往下去修改。
- 左孩子的 next 肯定要修改,右孩子的 next 可能要修改。
- 后者的修改,需要有一个前提 —— 自己的 next 要存在,右孩子才能找到右邻居。
第三题、将二叉树展开为链表
函数签名如下:
void flatten(TreeNode root);
我们尝试给出这个函数的定义:
给 flatten 函数输入一个节点 root,那么以 root 为根的二叉树就会被拉平为一条链表。
我们再梳理一下,如何按题目要求把一棵树拉平成一条链表?很简单,以下流程:
- 将
root的左子树和右子树拉平。 - 将
root的右子树接到左子树下方,然后将整个左子树作为右子树。
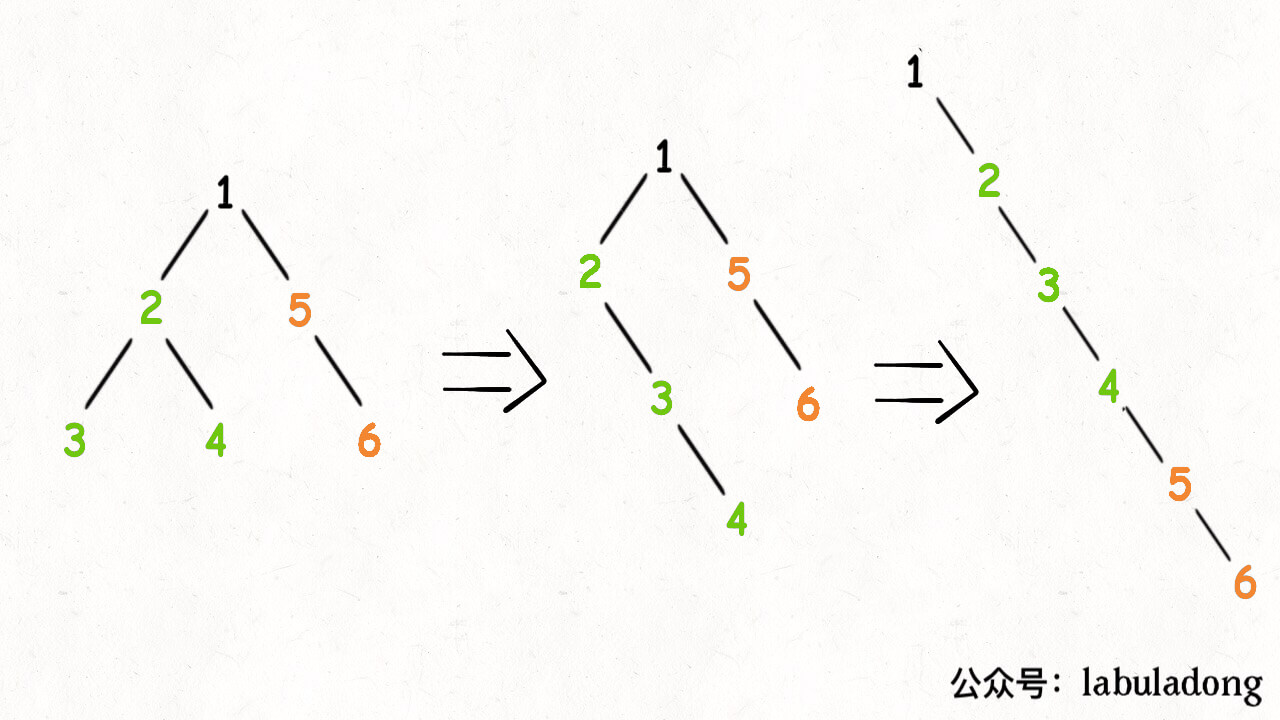
上面三步看起来最难的应该是第一步对吧,如何把 root 的左右子树拉平?其实很简单,按照 flatten 函数的定义,对 root 的左右子树递归调用 flatten 函数即可:
// 定义:将以 root 为根的树拉平为链表
void flatten(TreeNode root) {
// base case
if (root == null) return;
flatten(root.left);
flatten(root.right);
/**** 后序遍历位置 ****/
// 1. 左右子树已经被拉平成一条链表
// 这里先暂存左右子树
TreeNode left = root.left;
TreeNode right = root.right;
// 2. 将左子树作为右子树
root.left = null;
root.right = left;
// 3. 将原先的右子树接到当前右子树的末端
TreeNode p = root;
while (p.right != null) {
p = p.right;
}
p.right = right;
}
你看,这就是递归的魅力,你说 flatten 函数是怎么把左右子树拉平的?说不清楚,但是只要知道 flatten 的定义如此,相信这个定义,让 root 做它该做的事情,然后 flatten 函数就会按照定义工作。另外注意递归框架是后序遍历,因为我们要先拉平左右子树才能进行后续操作。
至此,这道题也解决了,我们旧文 k 个一组翻转链表 的递归思路和本题也有一些类似。
基础小题:
二叉树深度:
var maxDepth = function(root) { if (!root) return 0; else { let leftDepth = maxDepth(root.left), rightDepth = maxDepth(root.right); // 只挑大的 let childDepth = leftDepth > rightDepth ? leftDepth : rightDepth; return childDepth + 1; } };对称二叉树 ```javascript 1 / \ 2 2 / \ / \ 3 4 4 3
/**
- @param {TreeNode} root
- @return {boolean} */ var isSymmetric = function(root) { if (!root) return true; return isSym(root.left, root.right); };
function isSym(t1, t2) {
if (!t1 && !t2) return true; // 两个都空
if (!t1 || !t2) return false; // 两个有一个不空(都空被判断过了)
// 都不空
return (
t1.val === t2.val && // 左右子树
isSym(t1.left, t2.right) && // 子树的子树对称
isSym(t1.right, t2.left)
);
}
```
四、最后总结
递归算法的关键要明确函数的定义,相信这个定义,而不要跳进递归细节。
写二叉树的算法题,都是基于递归框架的,我们先要搞清楚 root 节点它自己要做什么,然后根据题目要求选择使用前序,中序,后续的递归框架。
二叉树题目的难点在于如何通过题目的要求思考出每一个节点需要做什么,这个只能通过多刷题进行练习了。
如果本文讲的三道题对你有一些启发,请三连,数据好的话东哥下次再来一波手把手刷题文,你会发现二叉树的题真的是越刷越顺手,欲罢不能,恨不得一口气把二叉树的题刷通。
接下来请阅读 手把手刷二叉树(第二期) 和 手把手刷二叉树(第三期)。

若有收获,就点个赞吧
0 人点赞
