- Mysql数据库
- 拓展:Mysql存储/查询数据
- 拓展:%Like无法使用索引怎么办
- 拓展:index(a,b,c)的查找步骤
- 拓展:index(a,b,c)索引的失效情况
- 拓展:order/group by使用索引的情况
- 拓展:事务4种隔离级别
- 拓展:多事务读——版本链
- 拓展:多事务读——Readview
- 拓展:多事务读—读已提交的实现
- 拓展:多事务读—可重复读的实现
- 拓展:日志:binLog记录模式
- 拓展:日志:binLog文件结构
- 拓展:日志:binLog写入机制
- 拓展:日志:binLog相关操作
- 拓展:日志:undoLog
- 拓展:多版本并发控制——MVCC
- 拓展:锁的分类
- 拓展:数据库中的锁
- 拓展:使用读锁
- 拓展:使用写锁
- 拓展:读锁、写锁综合案例
- 拓展:行锁、间隙锁
- 拓展:读已提交——加锁情况
- 拓展:可重复读——加锁情况
- 扩展:Mysql大字段如text/blob是怎么存储的?
- 扩展:数据库连接池原理
Mysql数据库
拓展:Mysql存储/查询数据
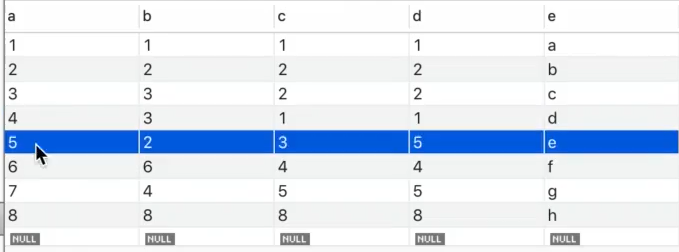
PS:表中的数据如上所示,索引为index(b,c,d)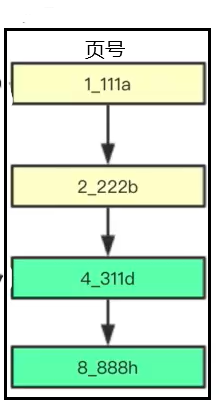 ——可以优化——>
——可以优化——>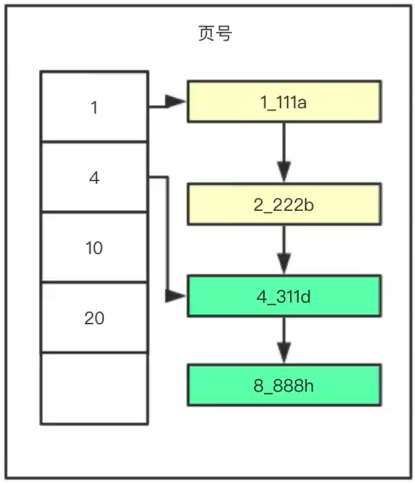
(1)图1说明了mysql中页面存储的是多行记录
(2)图2说明可以通过分组,即在页面中添加目录的形式,进一步优化图1链表查询的效率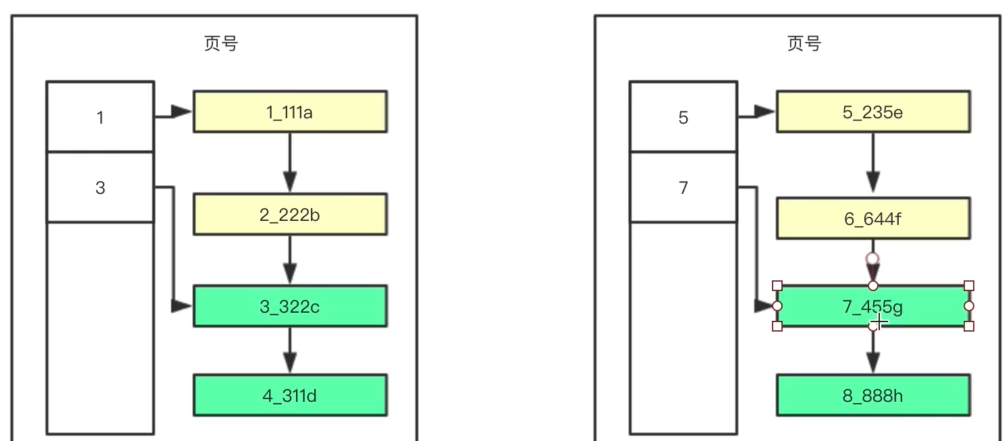
PS:需要存储多行数据,就会创建许多的页,那么mysql是如何在这些页面中查找到记录的?方案如下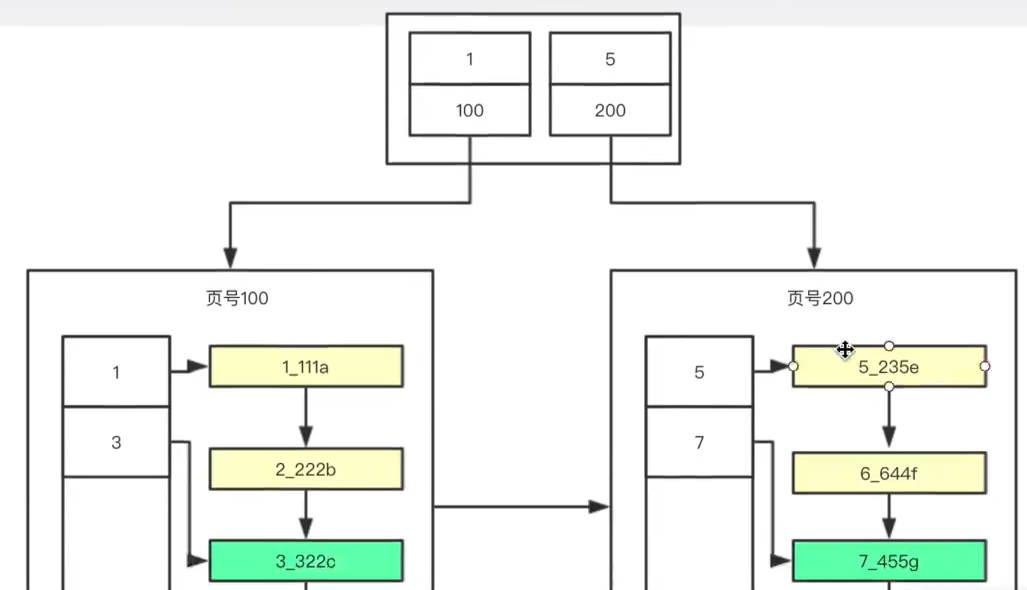
PS:解释如下
(1)要找到记录,需要找到记录所在的页,就需要通过以上的结构。
(2)100、200代表页号,1、5代表页面的索引列最小的值
(3)这样,当查询记录3时,会发现3是小于5,大于1的,因此在左边,找到页号为100的页面
(4)接着,查询页面100的页目录,找到行记录3的具体位置,然后返回结果
综上,可以看到Mysql是以页为单位存储多行数据,最后还通过mysql查询数据的过程,引出了索引的结果。
拓展:%Like无法使用索引怎么办
例如要存储以下的数据
aaa.com
bb.com
ccc.com
cv.cn
afg.me
如果要使用索引查出所有.com的数据行如何做呢?
可以在存入的时候使用String的反转函数,使得存入的数据是
com.aaa
com.bb
com.ccc
cn.cv
me.afg
这样的话,就可以使用 like%查询条件,利用索引来查询数据
拓展:index(a,b,c)的查找步骤
假设abc都是整型,且index(a,b,c)是普通索引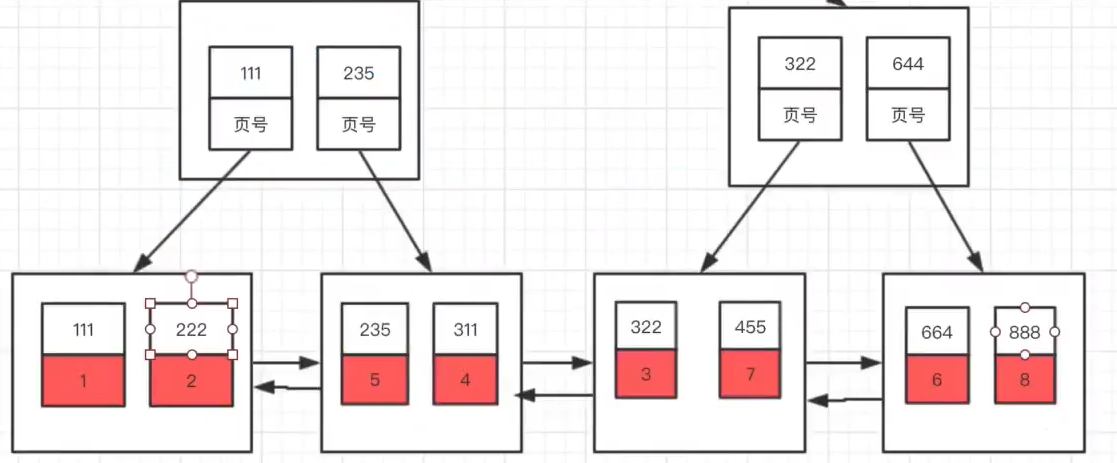
PS:以上是存入的数据的索引列,在索引中的组织形式,只画出了最后的两层,一般是3层;
叶子节点是页面,页面中的元素是数据行,这里为了为了简单,只画出两行;
非叶子节点也是页面,里边记录了数据行所在页面的地址,用于找到该索引列的值,所在的页面。
案例如下
当查询条件为 a=1 and b=1 and c=1时,执行引擎会做以下的几个操作
(1)将B+Tree的节点页面加载到内存当中,找到索引列 a =1所在的页面 ,来到叶子节点
(2)将叶子节点的页面加载到内存中,遍历页面,找到满足 b = 1的数据行
(3)接着再找到满足索引列c = 1的数据行,这样就找到了该行记录的主键key
(4)接着要使用该key再到由key为索引列构建的B+Tree中查找真实的记录(比较过程与上面1-3类似)
拓展:index(a,b,c)索引的失效情况
当查询条件为以下的条件,会导致索引无法使用
1、 b=1 and c=1,即在B+Tree的查询条件为 x11,这时无法使用index(a,b,c)
2、 a=1 and b>1 and c>1, 即会查出a=1的记录所在的页,再查出满足 b > 1的记录,可以使用部分索引,
即使用了二级索引,a,b,没有使用索引列c,因为查询出来的 b>1的数据,并没有对c进行排序,例子如下
124
133
142
这样,最后一列c是4,3,2,是无序的,就无法使用到index(ab,c)中已经排好序的索引列c,因此只能使用index(a,b)
3、 a>1 and b>2,该情况和2情况类似,即依旧会使用部分索引,只能使用到index(a),例子如下
23x
27x
34x
可以看到,b列查询到的结果是3,7,3,是无序的,不能使用到index(a,b,c)中已经排好序的索引列b,因此只能
使用到index(a)
综上:
- 索引必须满足最左匹配原则,当左边的索引列缺失,就不会走索引;
- 当左边的索引列采用范围查询,如> 、<、!=,就会导致后面的索引列失效。
所有的辅助索引都需要经过:查找 + 回表的过程。
拓展:order/group by使用索引的情况
我们知道,索引就是一个排好序的数据结构,当使用order by进行排序的时候,如果能够让该SQL语句的执行
直接使用我们已经排好序的数据,这样,就不需要让CPU再进行一次排序了,案例如下。
索引为index(a,b,c),当查询条件为
1、select from table order by a,b,c;这样实际上是不会走索引的,原因如下
(1)执行该操作,如果走index(a,b,c),需要先从辅助索引的B+Tree中获取所有数据的主键,
然后在通过该主键在主键索引的B+Tree中找到真实的数据行。
(2)查询优化器发现,这样执行的性能比较低,还不如直接进行一次全表扫描,将该表所在的页面全部加载
到内存中,然后由CPU进行统一的排序,这样性能比走索引index(a,b,c)的效率要高
(3)因此,当我们执行explain 语句的时候,会发现type = All,extra = using filesort
PS:但是,当select 的结果不是 ,而是 a,b,c的子集时,这时候,通过辅助索引的B+Tree就可以找到需要的
结果集,这时查询优化器就会走index(a,b,c),type = index,extra = using index。
也就是中间可能有回表的过程
2、当查询条件为
select a from table order by b,c;这样实际上也是不可能会走索引的,排序的条件少了最左边的列a
那么如何进行一个优化呢?如果我们需要查询的条件是只有a=1的数据,那么可以这么优化
select a from table where a=1 order by b,c;这样就可以用来索引。
PS:分组和排序两者的情况类似,优化就是指,分组/排序如何使用到目前已经建立的索引。
拓展:事务4种隔离级别
前提:两个session,开启了两个事务t1、t2
1、读未提交:t2可以读取t1修改但是未提交的数据,出现脏读、不可重复读、幻读现象
2、读已提交:t2只能读取t1修改的、提交的数据,但是t2在两次相同的查询,查询所得的结果不同,
也就是不可重复读,也会出现幻读的现象。
3、可重复读:即使t1修改了数据行,提交了,t2也能保证在t2这个事务中相同的等值查询条件,查询所得
的结果相同,即确保可重复读,但是当条件是范围类型的时候,如 > 时,会查询到多出的数据,即幻读。
4、串行化:当t1、t2都是读操作时,互不影响,当出现读、写混合时,后开始事务的会阻塞,直到前面
的事务完成。避免幻读现象。
PS:另外,事务的4种隔离级别是数据库设计的规范,不同数据库都针对这些规范做了相应的实现。
比如,在Mysql中,隔离级别为可重复读就可以避免 “幻读”的现象,而oracle需要采用串行化的隔离
级别才能达到避免“幻读”的现象。
拓展:多事务读——版本链

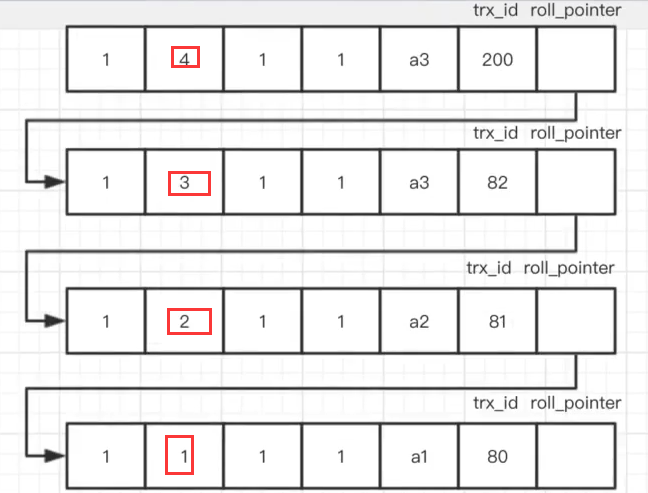
PS:Innodb创建的表的每一行记录都会有多个隐藏的列,与事务实现相关的主要是两个
1、trx_id:最新的、已经提交的事务的id
2、roll_pointer:一个指针,用于找到上一次修改的记录值
拓展:多事务读——Readview

读未提交:读取数据的最新版本 串行化:加锁访问 读已提交和可重复读:Read View
PS:在事务进行select查询的时候,会生成一个readview,其中有一个m_ids会记录当前未提交的所有事务id
拓展:多事务读—读已提交的实现
PS:以下分别是两个事务的查询流程图,以及该行记录的版本链图
A(300)表示事务A的事务id是300
B(200)表示事务B的事务id是200
接着事务A进行一次查询,查询当前隔离级别(读已提交)下改行记录的最新值
接着事务B进行一次提交,A再进行一次查询,查看该行记录的最新值
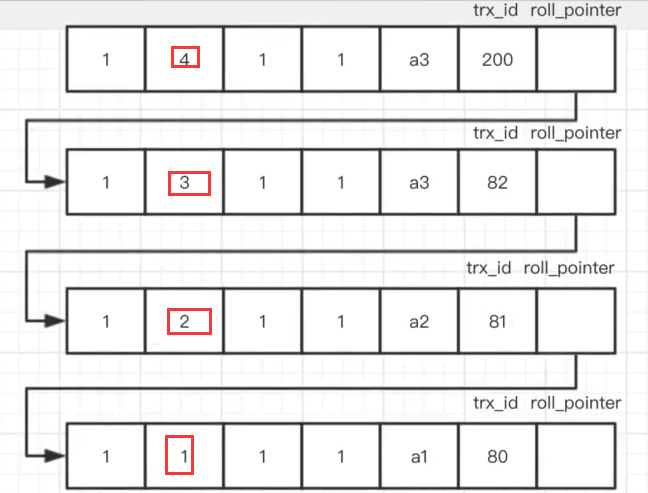
如当事务A进行查询的时候,需要找到已经提交的,最新的记录的值
1、产生1个readview,其中会维护一个数组m_ids,表示当前还没有提交的事务有哪些
2、对比当前行的trx_id,或者说遍历版本链,找到不存在于m_ids的事务id对应的行
3、该事务id所对应的行,就是最新的、已经提交过的修改值,对比过程如下
(1)当前记录的trx_id为200,在m_ids中,继续查找版本链
(2)当前记录的trx_id为82,在m_ids中,继续查找版本链
(3)当前记录的trx_id为81,在m_ids中,继续查找版本链
(4)当前记录的trx_id为80,不再m_ids中,即该记录值是A事务能够查看的,最新的记录值
当B进行提交的时候,会将B的事务id,即200,从m_ids中删除
接着A遍历该记录的版本链,发现200不在m_ids中,说明该记录已经被提交,就返回该行记录,
作为当前该记录行的最新修改值。
综上:事务隔离中的“读已提交”是通过数据行中的两个隐藏列、以及readview中的m_ids实现的。
1、trx_id
2、roll_pointer
3、readview的m_ids数组
每次查询,都会进行以下的操作
1、遍历该行记录roll_pointer列维护的一个版本链表,
2、比较记录值对应的trx_id是否在m_ids中,在的说明该事务还未提交,继续遍历版本链,否则返回
拓展:多事务读—可重复读的实现

PS:解释如下,和读已提交的实现类似,不同的是,当B事务进行提交的时候,A事务中,该行记录的
readview中的m_ids不会删除B事务的id,即200,也就是说,事务A还是认为B事务是没有提交的,这样
就不会读取到B事务的修改,确保了可重复读。
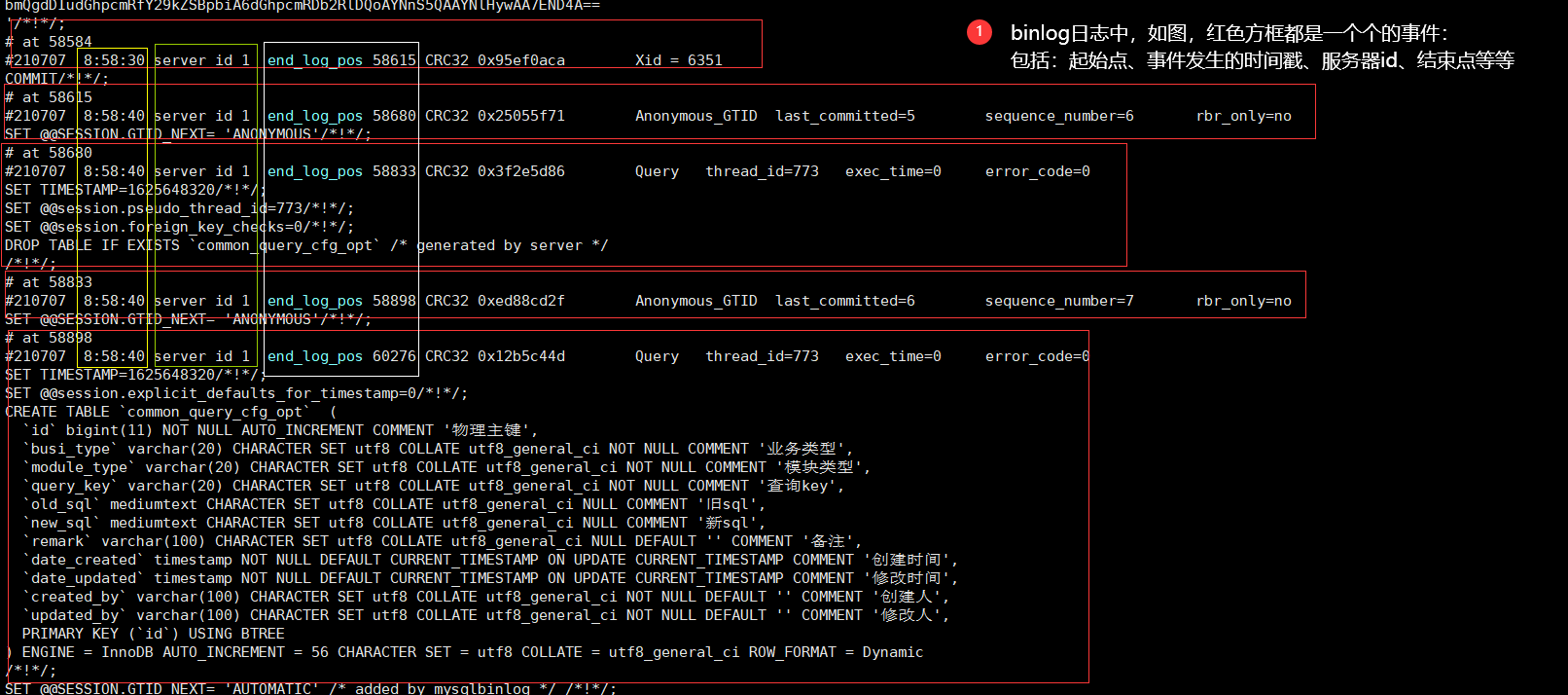
拓展:日志:binLog记录模式

拓展:日志:binLog文件结构

实际情况如下
拓展:日志:binLog写入机制

拓展:日志:binLog相关操作
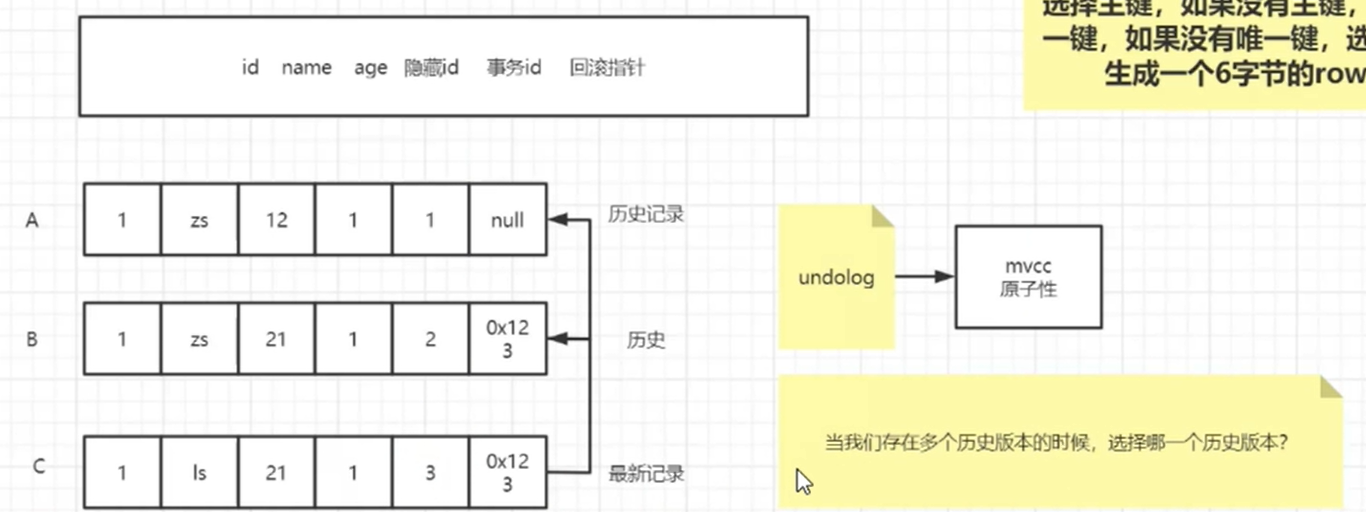
拓展:日志:undoLog
结论:mysql事务的原子性(要么全部执行,要么都不执行)是通过undolog来实现的。
说明:
- mysql中的每一行数据包含很多隐藏列,如隐藏id、事务id、回滚指针等,这是mvcc机制的要求
- 每一行都有一条历史数据链表,这些历史数据保存在undolog中
- undolog是事务实现回滚的数据基础
拓展:多版本并发控制——MVCC
为什么使用MVCC
数据库的锁机制,解决了并发情况下,多事务操作数据库的线程安全问题,但是存在一个问题,
读写操作互斥,导致数据库的并发性不是很好,然后MVCC通过 版本链+readview技术,使得
多事务的读、写操作不互斥,在隔离级别为“可重复读、读已提交”的情况下提高了数据库的
并发性能。
MVCC是什么
大多数的MySQL事务型存储引擎,如InnoDB,Falcon以及PBXT都在使用一种简单的行锁机制。事实上,他们都和另外一种用来增加并发性的被称为“多版本并发控制(MVCC)”的机制来一起使用。你可将MVCC看成行级别锁的一种妥协,它在许多情况下避免了使用锁,同时可以提供更小的开销
MVCC有什么用
MVCC维持一个数据的多个版本使读写操作没有冲突,即写操作不阻塞读,也就是说数据元素X上的每一个写操作产生X的一个新版本,当需要读取X的时候,就会从该版本中选择其中一个版本。由于消除了数据库中数据元素读和写操作的冲突,因此具有更好的并发性能。特别是对于数据库读和写两种方法,他们不用等待其他同样要对该行数据进行写操作、读操作的完成,全部的读、写操作都可以并发执行(写、写就不行)
MVCC在数据库中的应用
通过版本链 + readview实现了“读已提交”、“可重复读”的隔离机制。
PS:简单看看上面的截图即可。
总而言之:MVCC是在数据库多事务的情况下,提高并发性的一种机制,通常和锁机制一起使用。
通过使用版本链的方式使得读、写操作互不阻塞,在数据库中实现了“读已提交”、“可重复读”的隔离机制。
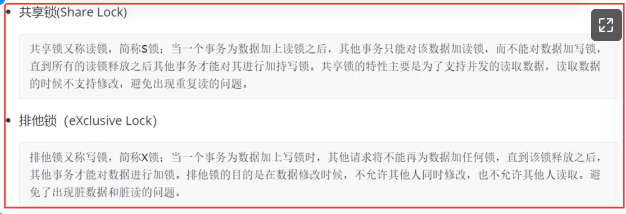
拓展:锁的分类
按照不同的维度来考虑

1、按照锁的属性分类
2、按照锁的粒度来分类
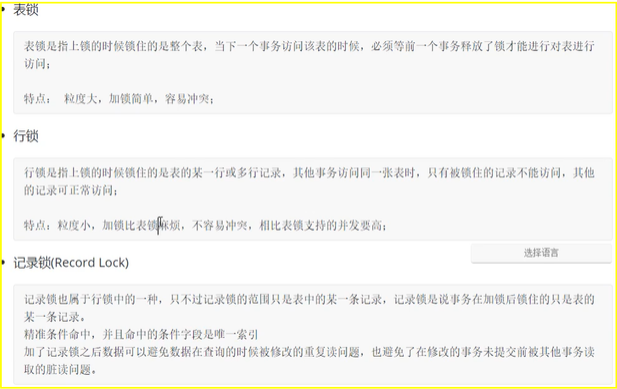

以上两种分类还说的过去。比如,读锁可以是行锁、表锁;行锁也可以是读锁、写锁。 以下按照状态分类,个人觉得不合理。
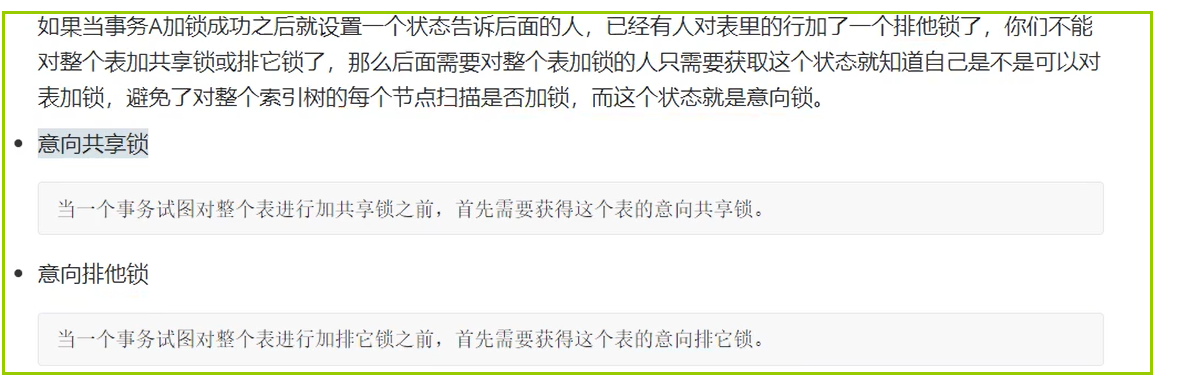
PS:严格来说,这两个不能称为锁,只是“提高加锁效率”的两个状态;另外,
从上面的描述来看,加锁是需要扫描索引树的,因此是需要成本的。所以这两个状态
可以让事务提高加锁的效率。
拓展:数据库中的锁


PS:解释如下
1、读锁:对数据行加读锁,能加多把读锁,不能加写锁,能进行读操作,不能进行写操作
2、写锁:对数据行加写锁,只能加1把锁,不能加其他的读锁、写锁,只能排队
3、select不会加锁,不会造成锁冲突
拓展:使用读锁

PS:其他事务不能加写锁
拓展:使用写锁

PS:其他事务不能加读、写锁
PS:暂时认为,以上的3种情况,会加上写锁
拓展:读锁、写锁综合案例

PS:可以看到,数据可以有多个读锁,不能有写锁
PS:可以看到,Inoodb创建的表的行记录执行select操作时,不会加任何锁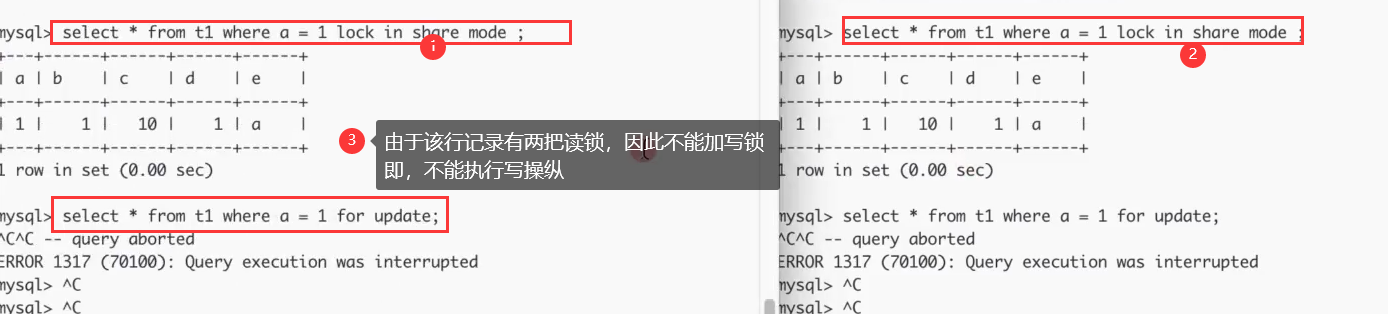
PS:测试结论如上
拓展:行锁、间隙锁

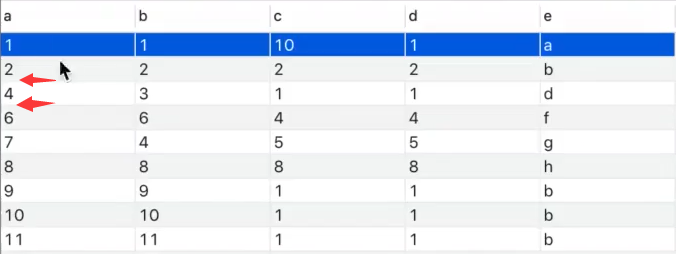
PS:解释如下,距离,锁定的行时4
1、行锁:锁定第4行
2、间隙锁:锁定第3和第5行
3、范围锁:锁定第3、4、5行
拓展:读已提交——加锁情况
1、查询:在查询中,使用for update添加写锁只会对查出来的数据进行加锁,其他没有查出来的数据,
依旧可以被其他事务访问。
拓展:可重复读——加锁情况
1、查询:在查询中,使用for update添加写锁只会对查出来的数据进行加锁,其他没有查出来的数据,
依旧可以被其他事务访问。
2、不可以插入“已查出的结果”相邻的数据,因为在可重复读的隔离级别下,“已查出的结果”附近
的间隙会添加间隙锁,只要插入的数据在处于这个间隙,就会阻塞。(适用于update,delete)
PS:这就是为什么mysql 的可重复读隔离机制可以避免幻读的原因。如当查询条件为 a>1时,是无法
插入a > 1的记录的,会阻塞,而读已提交的隔离级别则可以插入。
扩展:Mysql大字段如text/blob是怎么存储的?
mysql把text和BLOB当作一个独立的大对象来处理,存储引擎在存储时通常做特殊的处理



扩展:数据库连接池原理
运行原理:
数据库连接池在初始化的时候会创建initialSize个连接,当有数据库操作时,会从池中取出一个连接。如果当前池中正在使用的连接数等于maxActive,则会等待一段时间,等待其他操作释放掉某一个连接,如果这个等待时间超过了maxWait,则会报错;如果当前正在使用的连接数没有达到maxActive,则判断当前是否空闲连接,如果有则直接使用空闲连接,如果没有则新建立一个连接。在连接使用完毕后,不是将其物理连接关闭,而是将其放入池中等待其他操作复用。 同时连接池内部有机制判断,如果当前的总的连接数少于miniIdle,则会建立新的空闲连接,以保证连接数得到miniIdle。如果当前连接池中某个连接在空闲了timeBetweenEvictionRunsMillis时间后仍然没有使用,则被物理性的关闭掉。有些数据库连接的时候有超时限制(mysql连接在8小时后断开),或者由于网络中断等原因,连接池的连接会出现失效的情况,这时候设置一个testWhileIdle参数为true,可以保证连接池内部定时检测连接的可用性,不可用的连接会被抛弃或者重建,最大情况的保证从连接池中得到的Connection对象是可用的。当然,为了保证绝对的可用性,你也可以使用testOnBorrow为true(即在获取Connection对象时检测其可用性),不过这样会影响性能。

若有收获,就点个赞吧
0 人点赞
