redis问题
拓展:缓存穿透(实战)
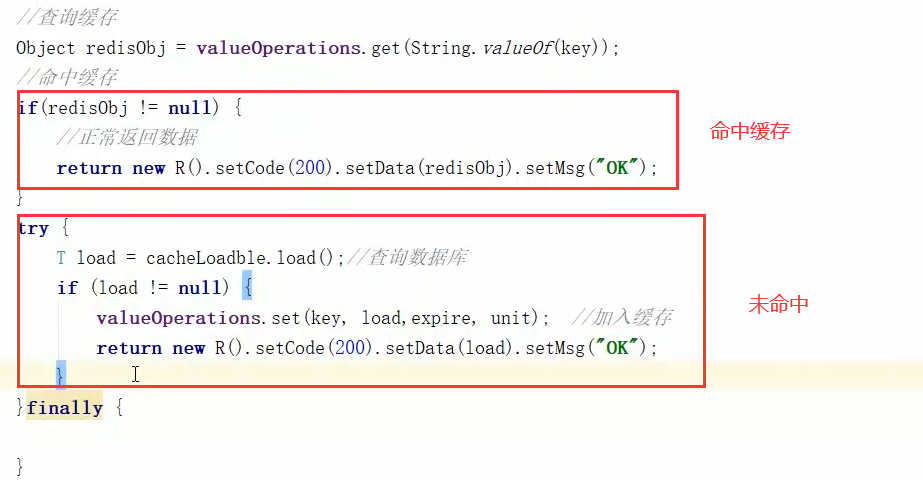
PS:该代码,当查询不存在的数据时,会透过缓存,同时数据库也不存在该数据,因此请求将会一直查询
数据库,这样会影响系统的整体性能,主要有两个方案解决
1、缓存空对象(优点:减少访问后端数据库请求;缺点:大量的空对象会占用redis的内存)
2、布隆过滤器(优点:过滤大部分无效的请求;缺点:无法删除,且难以维护)
实现:缓存空对象

PS:修改的代码有以上两个部分。
1、else:首先当数据库中查不到数据时,缓存NullValueResultDO这个空对象。这样下次就不会查数据库了
2、if:查询到的非空对象由两种,空对象和真实数据,需要再进行一个判断,如果是空对象,返回“查询无果”
实现:布隆过滤器

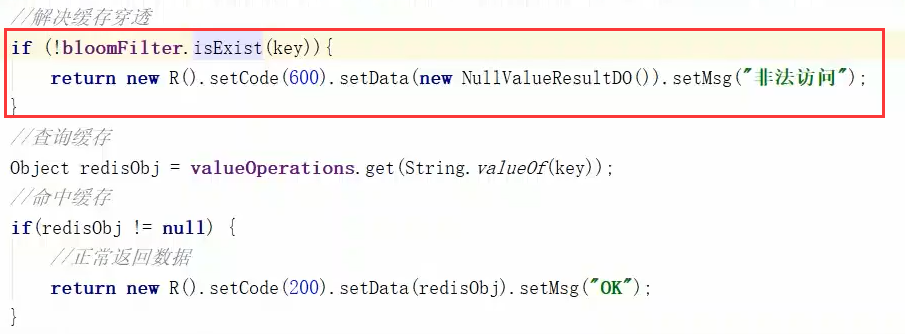
PS:基本的原理如上和需要修改的代码如上(详情以后再更新),优缺点如下
1、过滤掉很多无效的请求(当要查询的key,通过多个hash函数计算得到的bit位置不全为0,则必然不存在),
当然也会存在一定的误识率,但是只占极小部分,也就是说只有极小的无效请求会访问数据库,影响不大。
2、无法删除,因为多个key可能占用相同的bit位,删除某个key对应的bit位会影响多个key;同时难以维护,
当数据库中添加数据的时候,也需要在布隆过滤器中添加,否则该数据的key会被认为是无效数据,被拦截。
拓展:缓存击穿(实战)
缓存击穿主要就是一个并发问题,即缓存中没有对应的key,数据库中有,这样当在缓存中没有查到的时候,
或者说缓存中的key过期时,刚好有大量请求访问该key,这就会造成并发地访问数据库的情况,即多个请求
落到后端数据库中,容易导致数据库宕机。
解决方案:可以使用分布式锁来同步多个请求,控制只能让持有该锁的线程访问数据库,具体实现如下
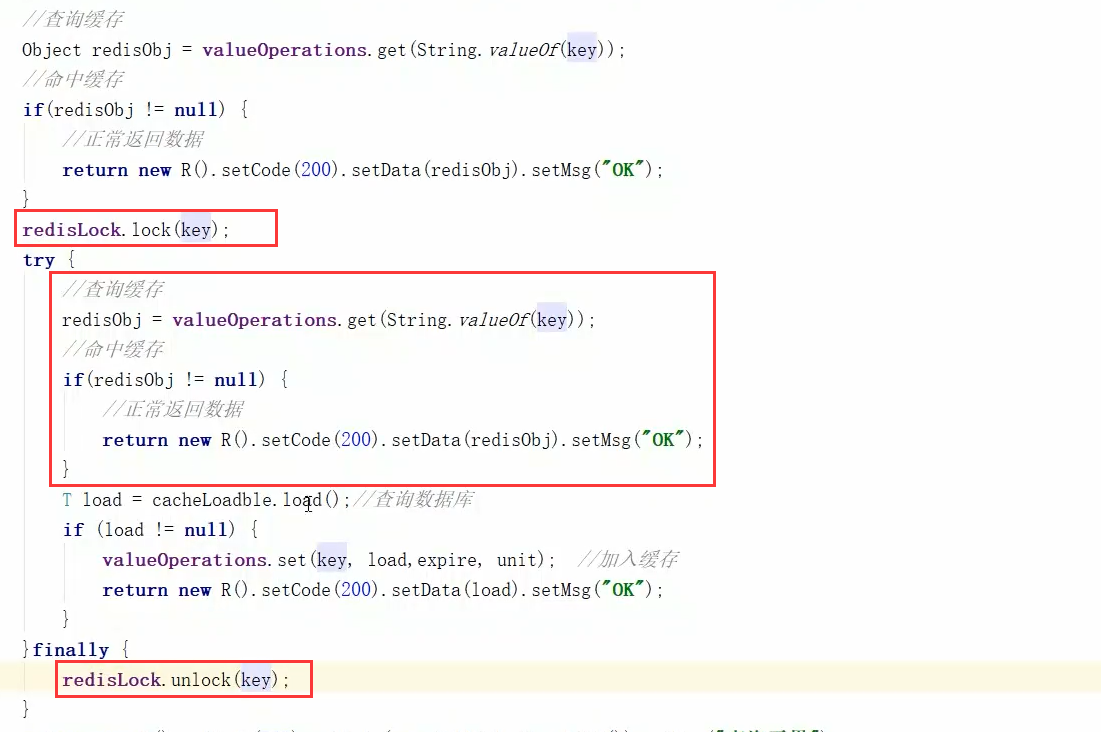
1、查询数据库之前进行加锁操作
2、再进行一次查询的目的是,多个线程申请锁时,持有锁的线程已经访问过数据库,同时将数据缓存到redis中,
那么后面的线程就不需要再访问数据库了,直接访问缓存即可。
3、解锁操作
测试方法:for循环访问缓存中没有的数据100次,可以看到后台只访问了1次数据库,不会并发访问多次。

拓展:缓存雪崩(思路)
数据大批量失效/redis集群宕机,导致大批量的请求直接落到数据库中,使得数据库承受巨大的压力,就称为雪崩
解决的方案:
1、搭建redis的高可用集群,避免redis集群宕机。
2、错开缓存数据的过期时间。
拓展:redis单机做分布式锁(思路)
设计分布式锁,主要的问题有
1、死锁问题:可以通过设置过期时间解决
2、锁误删问题:可以通过设置一个uuid来解决
PS:但是分布式场景下,还是会存在以下的问题。
并发导致再次“锁误删问题”
前面讲到为锁设置uuid可以避免锁误删问题,但是,由于程序可能存在多个线程并发的场景,如
(1)获取到锁
(2)执行业务逻辑
(3)判断redis中的锁是否是自己持有的
(4)删除redis中持有的锁
以上的场景会出现一个问题,当确定redis中的锁是本线程持有的,接着要执行删除的时候,突然CPU切换到其他
线程,接着redis锁会因过期时间而自动被删除,其他线程就可以设置redis锁,这样还是会出现锁误删的问题。
方案:使用lua脚本,使得“判断与删除”操作变成一个原子操作。
过期时间设置不合理导致的“锁误删问题”
(1)锁设置过期时间2s
(2)业务代码,可能由于网络原因,CPU调度原因执行时间超过2s(总之,就是想说明执行时间是“不确定”)
(3)锁过期,导致其他线程可以持有锁,这样在同一个集群中,就会有多个线程执行同一段代码,即并发问题
方案:使用线程池的方式,创建一个分支线程,每隔T/3 秒就给主线程“续命”,这样就不会有集群中的线程并发问题。目前市面上已经有这一类思想的实现框架redission。
拓展:redis集群做分布式锁(思路)
前面提到的是redis单机作为分布式锁的实现原理,但是通常来说是采用一个redis集群来作为分布式锁的。
主要的思路如下
1、首先,架构上肯定是读写分离,主从架构的,即设置写操作都发送给主节点,读操作可以直接由从节点处理。
2、接着,就需要考虑redis集群的高可用性,即节点宕机之后怎么办
(1)正常情况下,线程1获取到redis集群的锁,主节点对从节点发送同步请求,同步锁信息
(2)当从节点宕机,不影响,因为setnx操作是由主节点进行的。
(3)当主节点宕机,需要通过哨兵机制(自动选举)选举出新的leader
(4)由于主节点同步锁信息需要通过网络IO,这样就有时延,当主节点宕机后,新的leader节点没有同步到锁信息,这样其他线程执行setnx命令就会在新的leader节点中设置锁,这样整个集群中就存在两个线程在同一时刻拥有同一把锁,就出现线程安全问题。
方案:采用过半机制,即当线程1发送setnx获取锁时,不会马上返回,而是等到leader节点将锁的信息同步到一半
以上的follower节点才返回,即线程1获取锁成功,这样当leader宕机后,绝大多数节点也都有原来的锁信息,这样就不会出现集群的同一时刻有多个线程公用同一把锁的情况。
扩展:redis最大支持多少key?
一个key或是value大小最大是512M
redis单个实例最多能存多少个key键,每个值能存储多少个元素?
一个单实例的redis最多能支持2^32个键,差不多就是2.5亿个,每个key中的值也是可以存 2^32行数据,所以服务器的内存才是我们所担心的。
扩展:redis的IO复用模型?
- 解决的问题
Redis 的 I/O 多路复用模型有效的解决单线程的服务端,使用不阻塞方式处理多个 client 端请求问题。
为什么 Redis 中要使用 I/O 多路复用这种技术呢?因为 Redis 是跑在「单线程」中的,所有的操作都是按照顺序线性执行的,但是「由于读写操作等待用户输入 或 输出都是阻塞的」,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导,致整个进程无法对其它客户提供服务。而 I/O 多路复用就是为了解决这个问题而出现的。「为了让单线程(进程)的服务端应用同时处理多个客户端的事件,Redis 采用了 IO 多路复用机制。」
I/O 多路复用其实是使用一个线程来检查多个 Socket 的就绪状态,在单个线程中通过记录跟踪每一个 socket(I/O流)的状态来管理处理多个 I/O 流。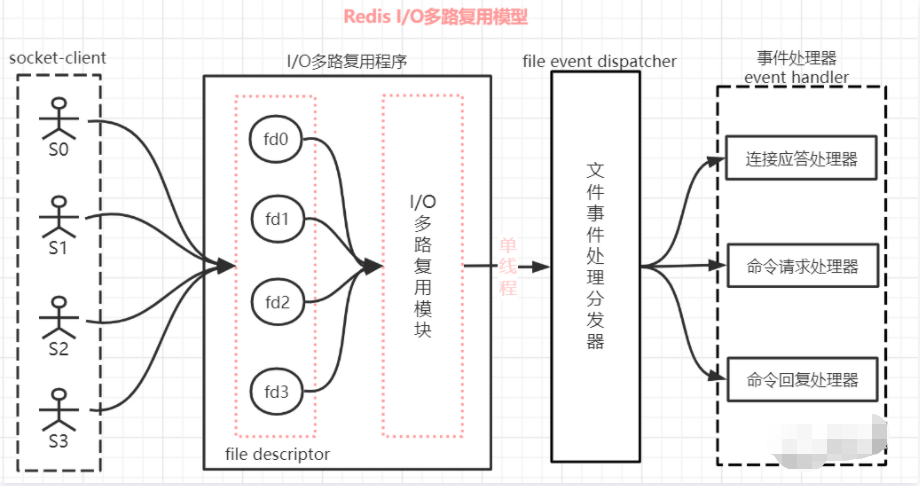
如上图对 Redis 的 I/O 多路复用模型进行一下描述说明:
- (1)一个 socket 客户端与服务端连接时,会生成对应一个套接字描述符(套接字描述符是文件描述符的一种),每一个 socket 网络连接其实都对应一个文件描述符。
- (2)多个客户端与服务端连接时,Redis 使用 「I/O 多路复用程序」 将客户端 socket 对应的 FD 注册到监听列表(一个队列)中。当客服端执行 read、write 等操作命令时,I/O 多路复用程序会将命令封装成一个事件,并绑定到对应的 FD 上。
- (3)「文件事件处理器」使用 I/O 多路复用模块同时监控多个文件描述符(fd)的读写情况,当 accept、read、write 和 close 文件事件产生时,文件事件处理器就会回调 FD 绑定的事件处理器进行处理相关命令操作。
例如:以 Redis 的 I/O 多路复用程序 epoll 函数为例 多个客户端连接服务端时,Redis 会将客户端 socket 对应的 fd 注册进 epoll,然后 epoll 同时监听多个文件描述符(FD)是否有数据到来,如果有数据来了就通知事件处理器赶紧处理,这样就不会存在服务端一直等待某个客户端给数据的情形。 #(I/O多路复用程序函数有 select、poll、epoll、kqueue)
复制
- (5)整个文件事件处理器是在单线程上运行的,但是通过 I/O 多路复用模块的引入,实现了同时对多个 FD 读写的监控,当其中一个 client 端达到写或读的状态,文件事件处理器就马上执行,从而就不会出现 I/O 堵塞的问题,提高了网络通信的性能。
- (6)如上图,Redis 的 I/O 多路复用模式使用的是 「Reactor 设置模式」的方式来实现。
- 总结:
- (1) Redis 的 I/O 多路复用程序函数有 select、poll、epoll、kqueue。select 作为备选方案,由于其在使用时会扫描全部监听的文件描述符,并且只能同时服务 1024 个文件描述符,所以是备选方案。
- (2) I/O 多路复用模型是利用 select、poll、epoll 函数可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉。当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),依次顺序的处理就绪的流,这种做法就避免了大量无用的等待操作。

若有收获,就点个赞吧
0 人点赞
