简述区别
Java SPI 会一次性加载和实例化所有的实现类。
Dubbo SPI则自己实现了SPI,通过名字实例化指定的实现类,并且实现了IOC、AOP和自适应扩展SPI。
Dubbo依赖SPI实现了插件化的功能,几乎所有的组件做成了基于SPI实现,并且默认提供很多可以扩展的扩展点,实现了面向功能进行拆分的对扩展开放的架构。
Java SPI
约定在ClassPath下的META-INF/services/ 目录创建一个以服务接口命名的文件,然后文件里面记录的是此jar包提供的具体实现类的加载和实例化。
示例
package com.interview.demo.spi;/*** @Author leijs* @date 2022/4/8*/public interface NotifyService {void send();}
package com.interview.demo.spi;/*** @Author leijs* @date 2022/4/8*/public class MailService implements NotifyService{@Overridepublic void send() {System.out.println("send email");}}
package com.interview.demo.spi;/*** @Author leijs* @date 2022/4/8*/public class SmsService implements NotifyService{@Overridepublic void send() {System.out.println("send sms");}}
package com.interview.demo.spi;import java.util.Iterator;import java.util.ServiceLoader;/*** @Author leijs* @date 2022/4/8*/public class NotifyMain {public static void main(String[] args) {ServiceLoader<NotifyService> serviceLoader = ServiceLoader.load(NotifyService.class);Iterator<NotifyService> iterator = serviceLoader.iterator();while (iterator.hasNext()) {NotifyService notifyService = iterator.next();notifyService.send();}}}


源码分析




简单来说:就是用当前线程的ClassLoader,如果没有,就用SystemClassLoader, 然后清除一下缓存,再创建一个LazyIterator.
private class LazyIteratorimplements Iterator<S>{Class<S> service;ClassLoader loader;Enumeration<URL> configs = null;Iterator<String> pending = null;String nextName = null;private LazyIterator(Class<S> service, ClassLoader loader) {this.service = service;this.loader = loader;}private boolean hasNextService() {if (nextName != null) {return true;}if (configs == null) {try {String fullName = PREFIX + service.getName();if (loader == null)configs = ClassLoader.getSystemResources(fullName);elseconfigs = loader.getResources(fullName);} catch (IOException x) {fail(service, "Error locating configuration files", x);}}while ((pending == null) || !pending.hasNext()) {if (!configs.hasMoreElements()) {return false;}pending = parse(service, configs.nextElement());}nextName = pending.next();return true;}private S nextService() {if (!hasNextService())throw new NoSuchElementException();String cn = nextName;nextName = null;Class<?> c = null;try {c = Class.forName(cn, false, loader);} catch (ClassNotFoundException x) {fail(service,"Provider " + cn + " not found");}if (!service.isAssignableFrom(c)) {fail(service,"Provider " + cn + " not a subtype");}try {S p = service.cast(c.newInstance());providers.put(cn, p);return p;} catch (Throwable x) {fail(service,"Provider " + cn + " could not be instantiated",x);}throw new Error(); // This cannot happen}public boolean hasNext() {if (acc == null) {return hasNextService();} else {PrivilegedAction<Boolean> action = new PrivilegedAction<Boolean>() {public Boolean run() { return hasNextService(); }};return AccessController.doPrivileged(action, acc);}}public S next() {if (acc == null) {return nextService();} else {PrivilegedAction<S> action = new PrivilegedAction<S>() {public S run() { return nextService(); }};return AccessController.doPrivileged(action, acc);}}public void remove() {throw new UnsupportedOperationException();}}
重点看下这个LazyIterator. 其实就是Iterator的实现类。使用hasNext()来做实例的循环。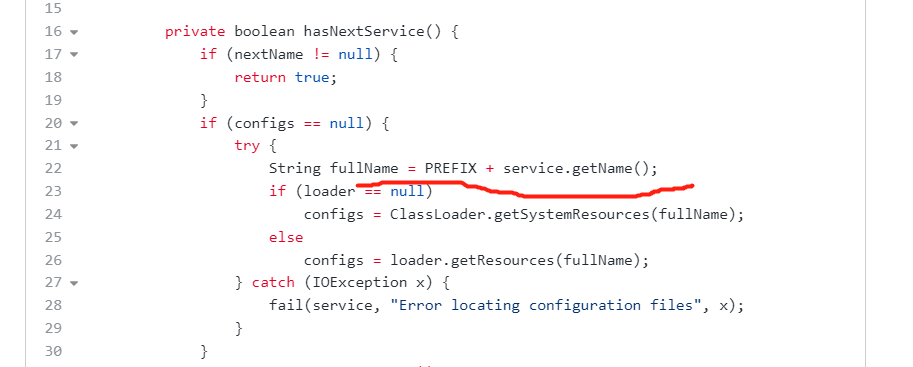
就是通过约定好的地方找到接口对应的文件,然后加载文件并解析文件里面的内容。
然后nextService()方法,
然后通过文件里面填写的全限名加载类,并且创建其实例放入缓存之后返回实例。
缓存key:类的全限名(实现类的), value是实例
缺点
在查找扩展实现类的时候,遍历SPI的配置文件并且将全部的实现类全部实例化,假如一个实现类初始化的该过程比较耗费资源且耗时,但是你的代码又用不到,这就产生了资源的浪费
也就是没法按需加载类。
Dubbo SPI
dubbo是这样设计的,配置文件里面存放的是键值对,这里截取一个cluster的配置。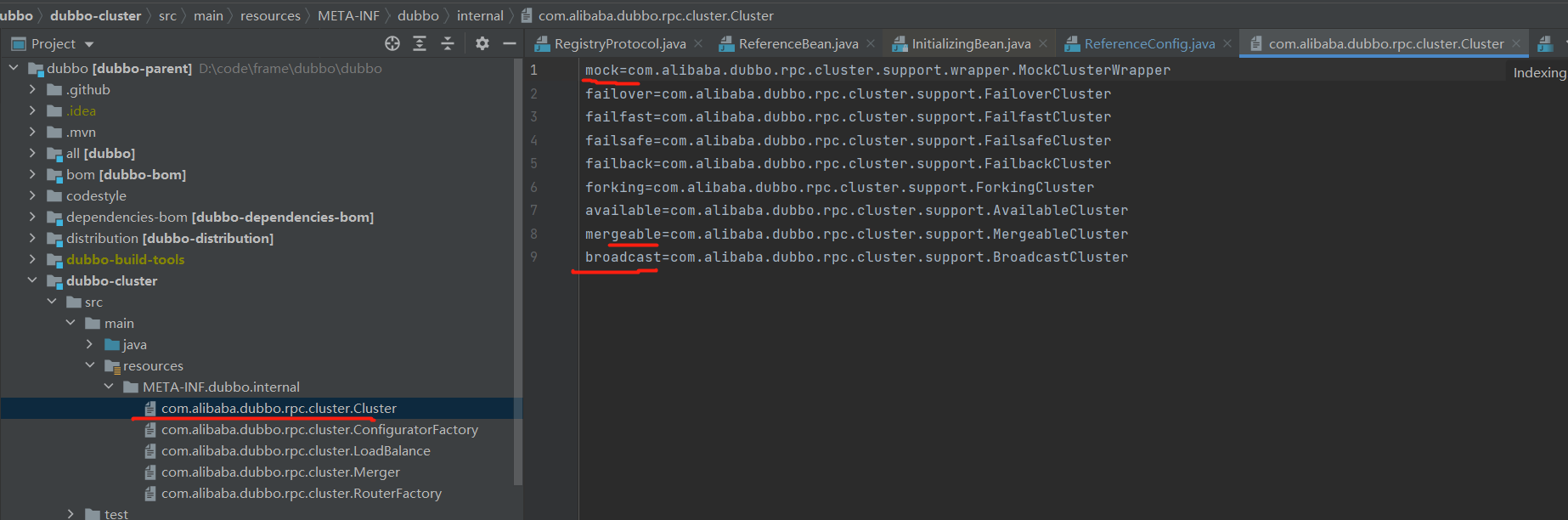
并且dubbo的SPI除了可以按需加载实现类之外,增加了IOC和AOP的特性,还有自适应扩展机制。
dubbo对配置文件的约定有以下三种:
- META-INF/services目录,该目录下的SPI文件是为了兼容Java SPI
- META-INF/dubbo 目录,存放用户自定义的SPI配置文件
- META-INF/dubbo/internal 该目录存放dubbo内部使用的SPI配置文件。
示例
注意:接口必须标注@SPI 注解,表明要用SPI机制。 ```java package com.alibaba.dubbo.rpc.cluster.spi;
import com.alibaba.dubbo.common.extension.SPI;
/**
- @Author leijs
- @date 2022/4/8 */ @SPI public interface MyCluster { void action(); }
```javapackage com.alibaba.dubbo.rpc.cluster.spi;/*** @Author leijs* @date 2022/4/8*/public class MysqlCluster implements MyCluster{@Overridepublic void action() {System.out.println("mysql action");}}
package com.alibaba.dubbo.rpc.cluster.spi;/*** @Author leijs* @date 2022/4/8*/public class RedisCluster implements MyCluster{@Overridepublic void action() {System.out.println("redis action");}}
package com.alibaba.dubbo.rpc.cluster.spi;import com.alibaba.dubbo.common.extension.ExtensionLoader;import org.junit.Test;/*** @Author leijs* @date 2022/4/8*/public class DubboSPITest {@Testpublic void test() {ExtensionLoader<MyCluster> extensionLoader = ExtensionLoader.getExtensionLoader(MyCluster.class);MyCluster redisCluster = extensionLoader.getExtension("redisCluster");redisCluster.action();MyCluster mysqlCluster = extensionLoader.getExtension("mysqlCluster");mysqlCluster.action();}}


源码分析
重点:ExtensionLoader。
大致流程:先通过接口找到一个ExtensionLoader,然后再通过extensionLoader.getExtension(name)得到指定名字的实现类实例。
private static final ConcurrentMap<Class<?>, ExtensionLoader<?>> EXTENSION_LOADERS = new ConcurrentHashMap<Class<?>, ExtensionLoader<?>>();
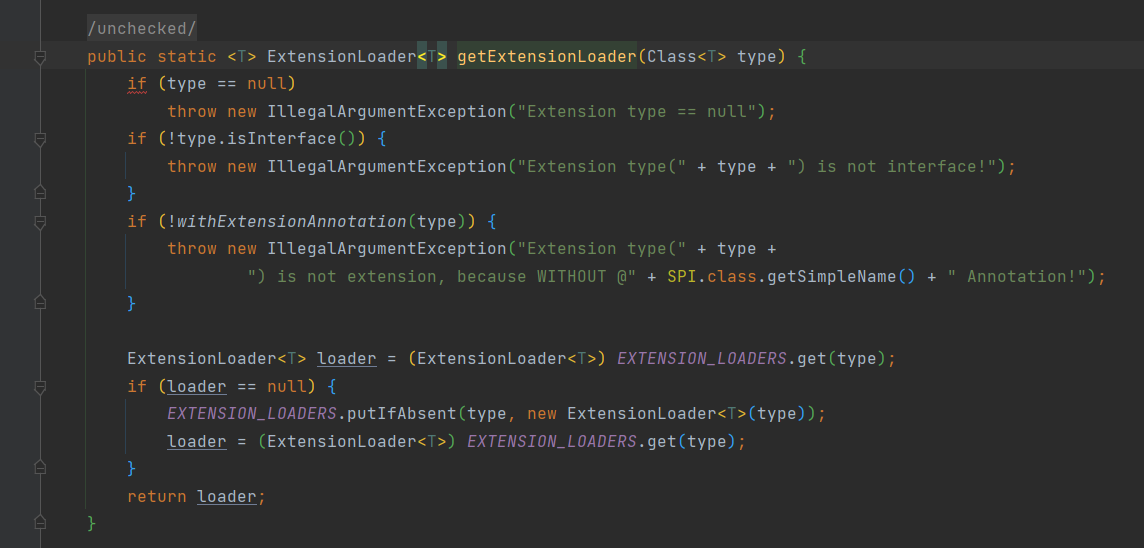
做了一些type等为空的判断之后,从缓存里面找是否存在这个类型的ExtensionLoader, 如果就新建一个塞入缓存,最后返回对应类的ExtensionLoader.
接下来看getExtension方法,是从类对应的ExtensionLoader中通过名字找到实例化完的实现类。
public T getExtension(String name) {if (name == null || name.length() == 0)throw new IllegalArgumentException("Extension name == null");if ("true".equals(name)) {return getDefaultExtension();}Holder<Object> holder = cachedInstances.get(name);if (holder == null) {cachedInstances.putIfAbsent(name, new Holder<Object>());holder = cachedInstances.get(name);}Object instance = holder.get();if (instance == null) {synchronized (holder) {instance = holder.get();if (instance == null) {instance = createExtension(name);holder.set(instance);}}}return (T) instance;}
重点就是createExtension()
private T createExtension(String name) {Class<?> clazz = getExtensionClasses().get(name);if (clazz == null) {throw findException(name);}try {T instance = (T) EXTENSION_INSTANCES.get(clazz);if (instance == null) {EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance());instance = (T) EXTENSION_INSTANCES.get(clazz);}injectExtension(instance);Set<Class<?>> wrapperClasses = cachedWrapperClasses;if (wrapperClasses != null && !wrapperClasses.isEmpty()) {for (Class<?> wrapperClass : wrapperClasses) {instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));}}return instance;} catch (Throwable t) {throw new IllegalStateException("Extension instance(name: " + name + ", class: " +type + ") could not be instantiated: " + t.getMessage(), t);}}
先找实现类,判断缓存是否有这个实例,没有就反射建个实例,然后执行set方法注入,如果有找到包装类的话,再包一层。
整体逻辑很清晰,先找实现类,判断缓存是否有实例,没有就反射建个实例,然后执行 set 方法依赖注入。如果有找到包装类的话,再包一层。
到这步为止我先画个图,大家理一理,还是很简单的。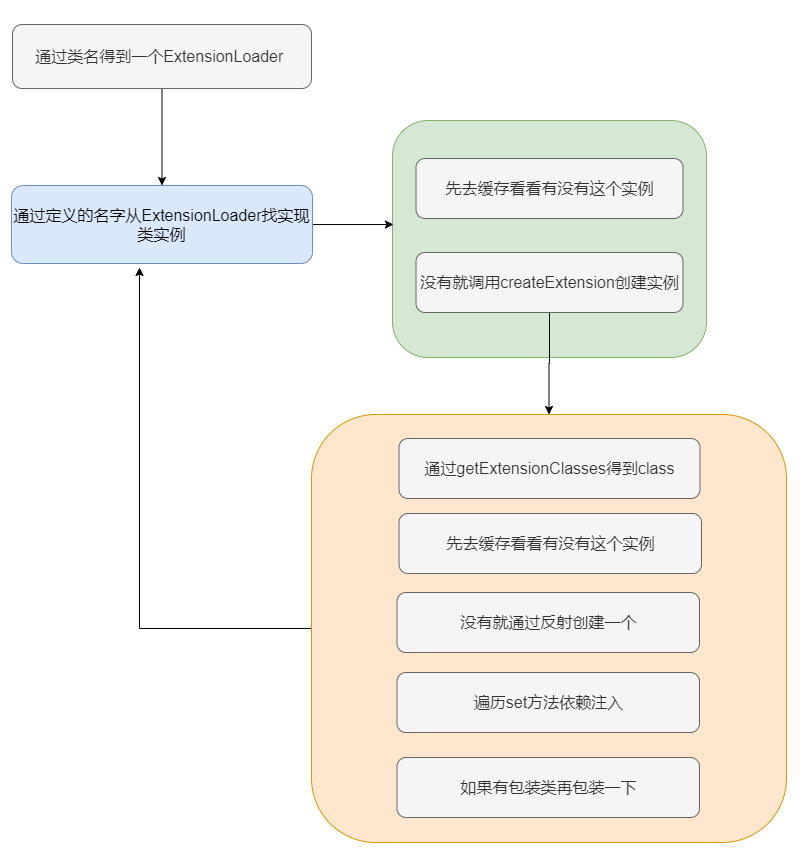
那么问题来了 getExtensionClasses() 是怎么找的呢?injectExtension() 如何注入的呢(其实我已经说了set方法注入)?为什么需要包装类呢?
getExtensionClasses
这个方法进去也是先去缓存中找,如果缓存是空的,那么调用 loadExtensionClasses,我们就来看下这个方法。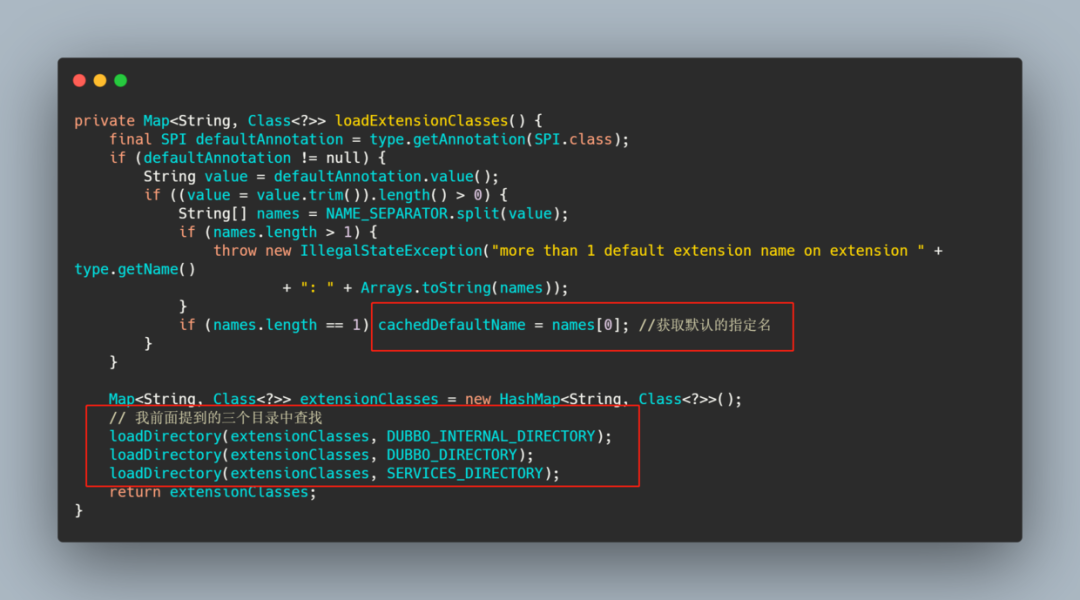
而 loadDirectory里面就是根据类名和指定的目录,找到文件先获取所有的资源,然后一个一个去加载类,然后再通过loadClass去做一下缓存操作。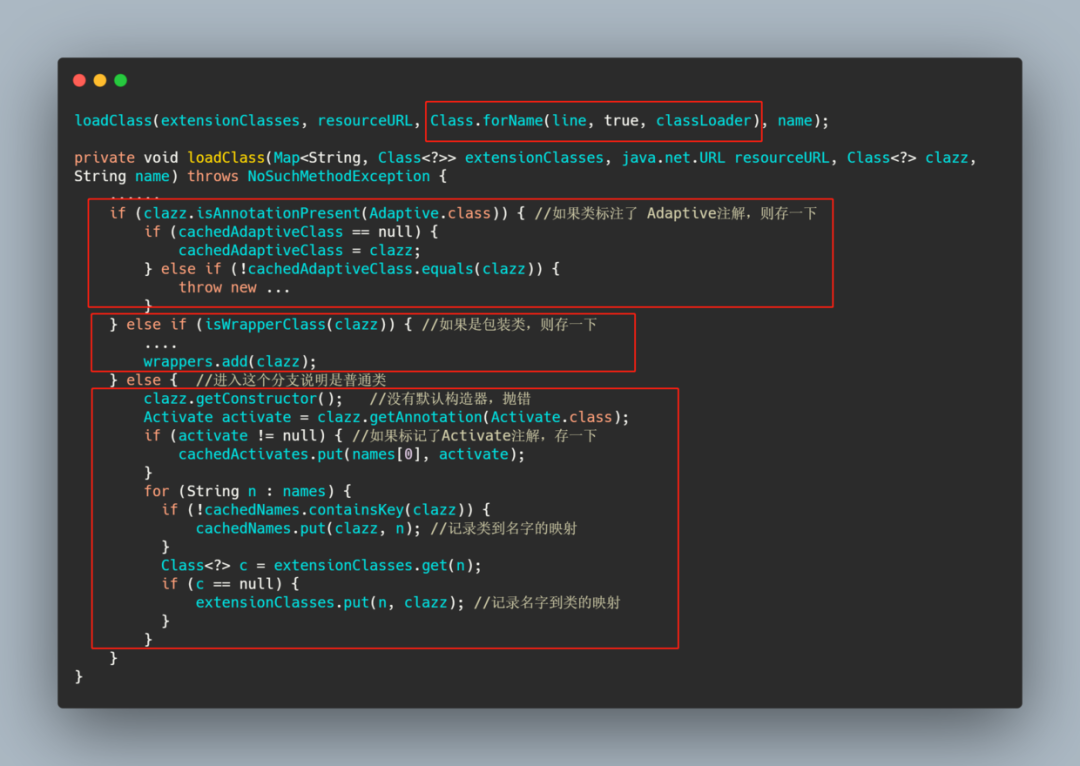
可以看到,loadClass 之前已经加载了类,loadClass 只是根据类上面的情况做不同的缓存。分别有 Adaptive 、WrapperClass 和普通类这三种,普通类又将Activate记录了一下。至此对于普通的类来说整个 SPI 过程完结了。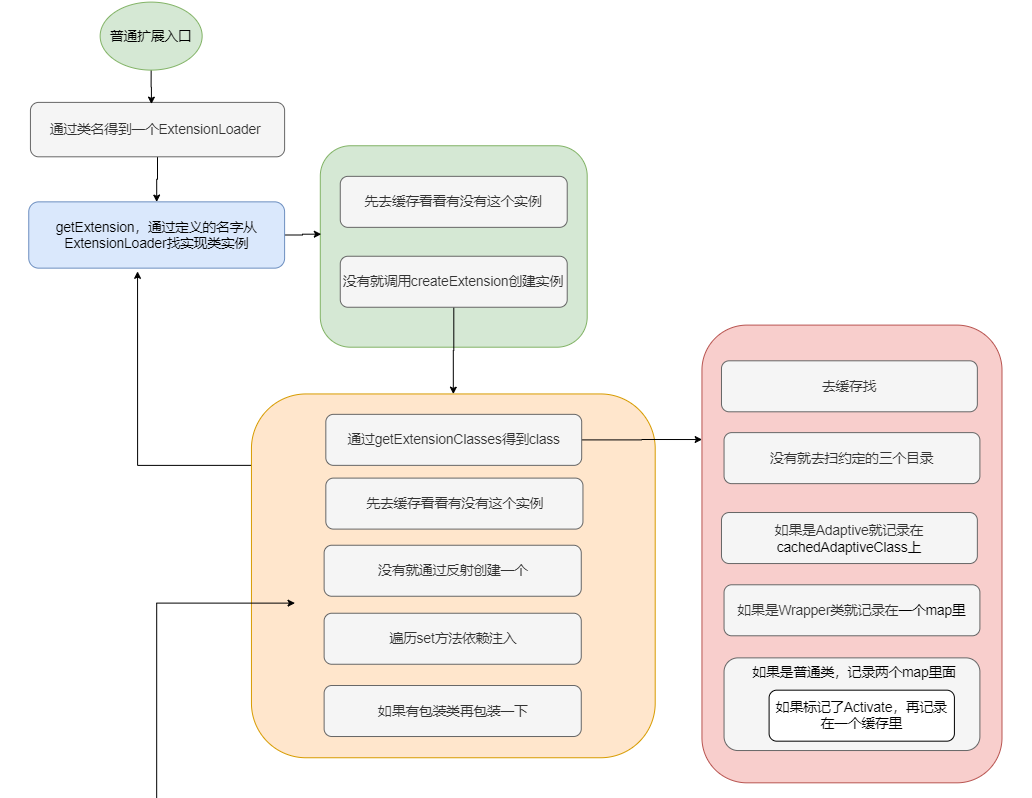
接下来我们分别看不是普通类的几种东西是干啥用的。
Adaptive 注解 - 自适应扩展
在进入这个注解分析之前,我们需要知道 Dubbo 的自适应扩展机制。
我们先来看一个场景,首先我们根据配置来进行 SPI 扩展的加载,但是我不想在启动的时候让扩展被加载,我想根据请求时候的参数来动态选择对应的扩展。
怎么做呢?
Dubbo 通过一个代理机制实现了自适应扩展,简单的说就是为你想扩展的接口生成一个代理类,可以通过JDK 或者 javassist 编译你生成的代理类代码,然后通过反射创建实例。
这个实例里面的实现会根据本来方法的请求参数得知需要的扩展类,然后通过 ExtensionLoader.getExtensionLoader(type.class).getExtension(从参数得来的name),来获取真正的实例来调用。
我从官网搞了个例子,大家来看下。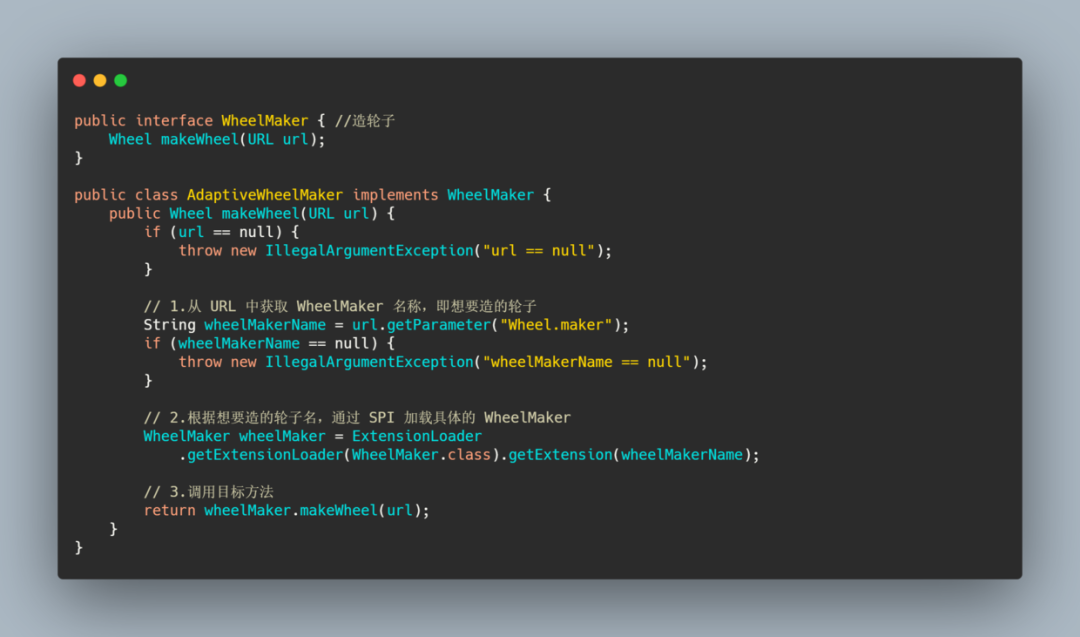
现在大家应该对自适应扩展有了一定的认识了,我们再来看下源码,到底怎么做的。
这个注解就是自适应扩展相关的注解,可以修饰类和方法上,在修饰类的时候不会生成代理类,因为这个类就是代理类,修饰在方法上的时候会生成代理类。
Adaptive 注解在类上
比如这个 ExtensionFactory 有三个实现类,其中一个实现类就被标注了 Adaptive 注解。

在 ExtensionLoader 构造的时候就会去通过getAdaptiveExtension 获取指定的扩展类的 ExtensionFactory。
我们再来看下 AdaptiveExtensionFactory 的实现。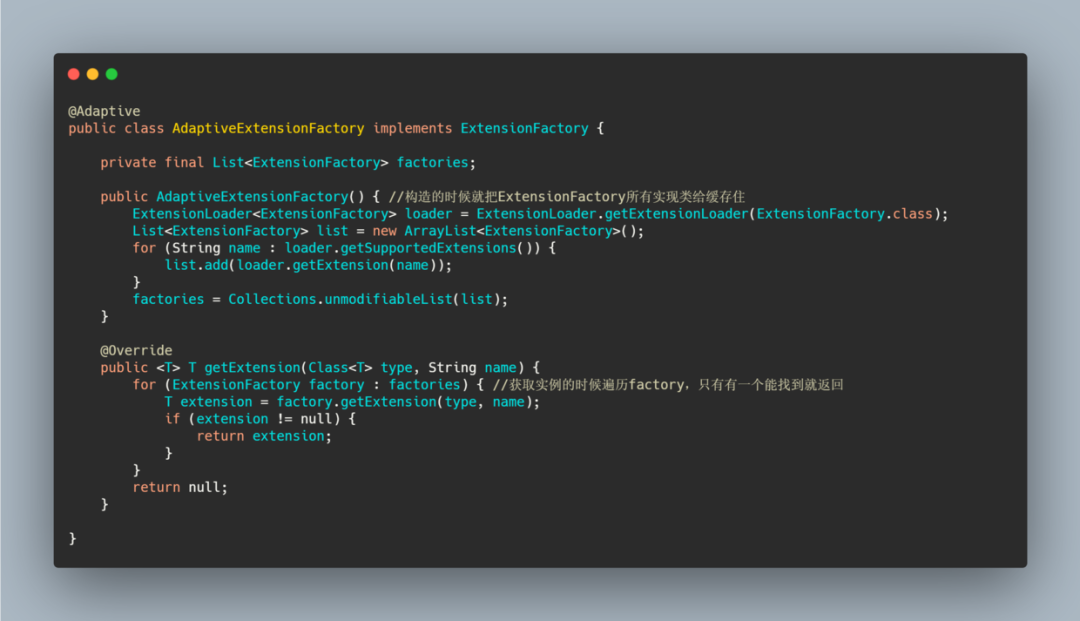
可以看到先缓存了所有实现类,然后在获取的时候通过遍历找到对应的 Extension。
我们再来深入分析一波 getAdaptiveExtension 里面到底干了什么。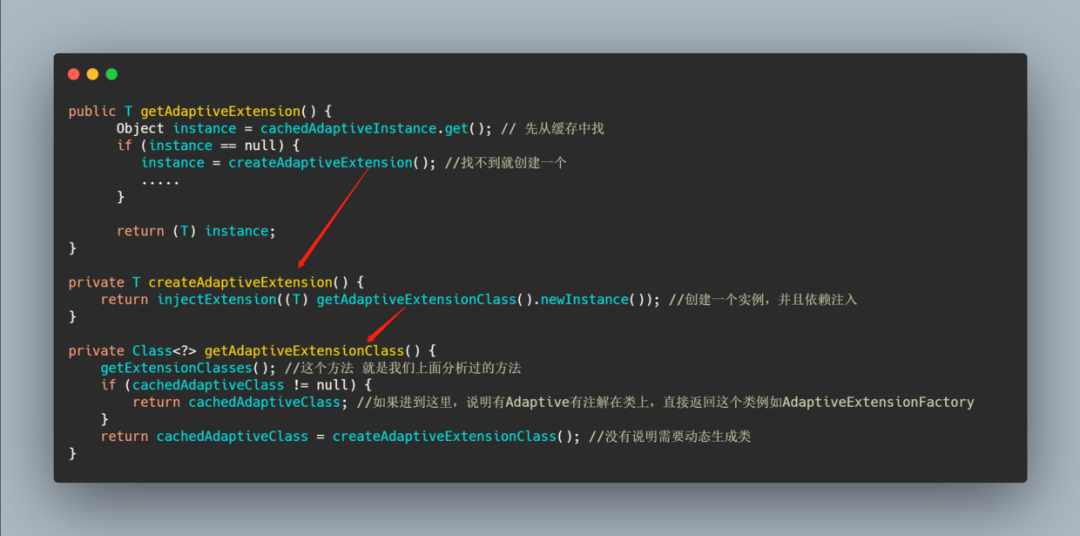
到这里其实已经和上文分析的 getExtensionClasses中loadClass 对 Adaptive 特殊缓存相呼应上了。
Adaptive 注解在方法上
注解在方法上则需要动态拼接代码,然后动态生成类,我们以 Protocol 为例子来看一下。
Protocol 没有实现类注释了 Adaptive ,但是接口上有两个方法注解了 Adaptive ,有两个方法没有。
因此它走的逻辑应该应该是 createAdaptiveExtensionClass,
具体在里面如何生成代码的我就不再深入了,有兴趣的自己去看吧,我就把成品解析一下,就差不多了。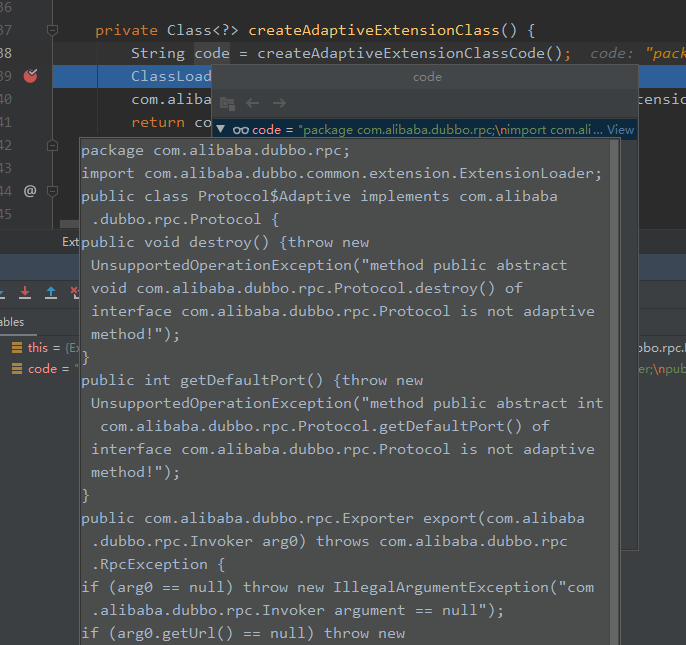
我美化一下给大家看看。
可以看到会生成包,也会生成 import 语句,类名就是接口加个$Adaptive,并且实现这接口,没有标记 Adaptive 注解的方法调用的话直接抛错。
我们再来看一下标注了注解的方法,我就拿 export 举例。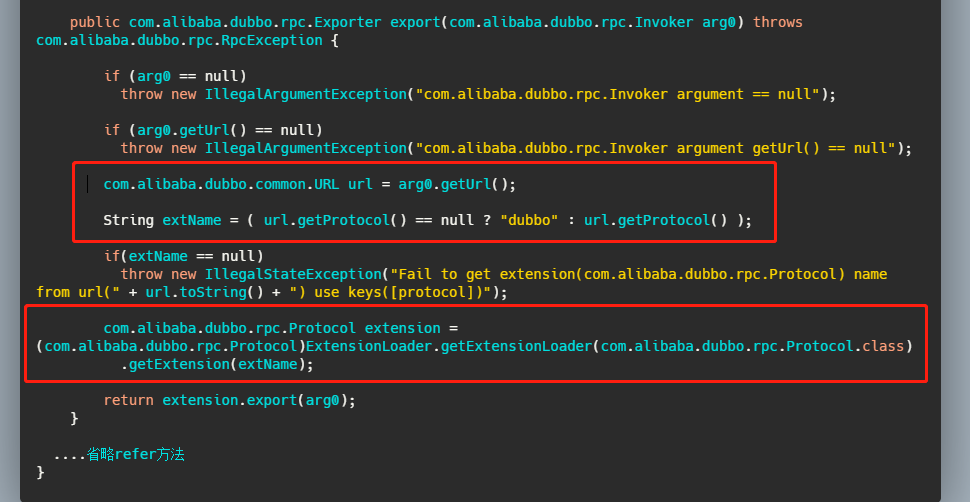
就像我前面说的那样,根据请求的参数,即 URL 得到具体要调用的实现类名,然后再调用 getExtension 获取。
整个自适应扩展流程如下。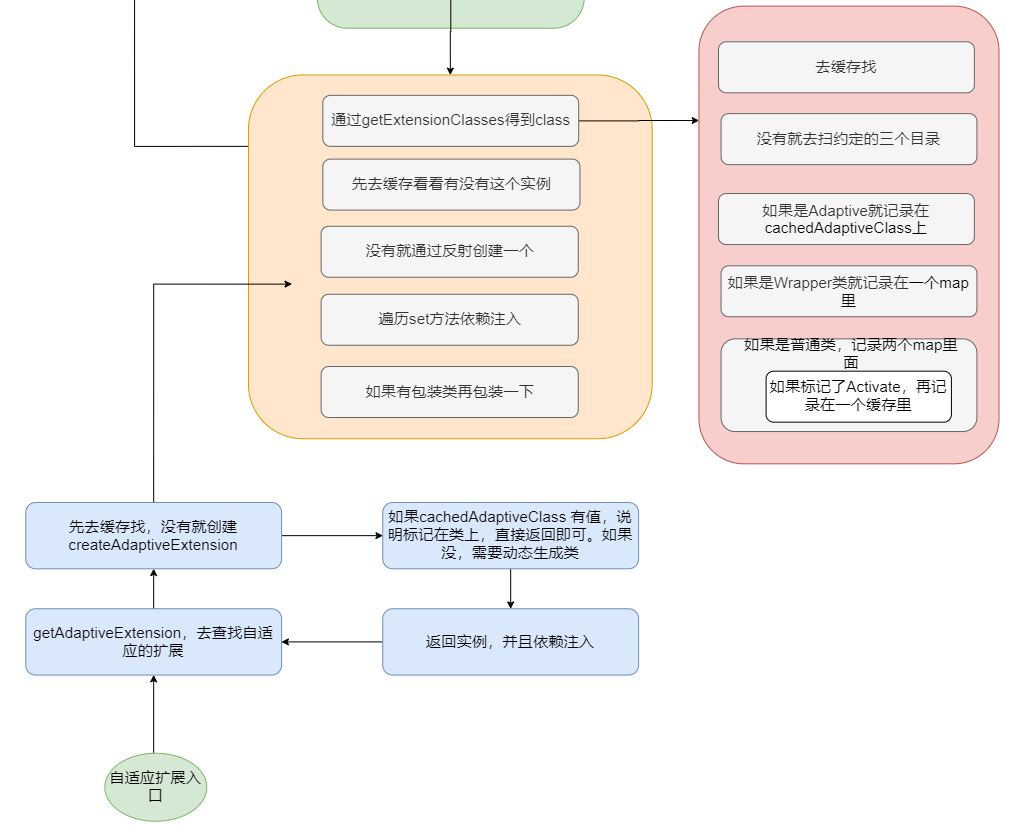
WrapperClass - AOP
包装类是因为一个扩展接口可能有多个扩展实现类,而这些扩展实现类会有一个相同的或者公共的逻辑,如果每个实现类都写一遍代码就重复了,并且比较不好维护。
因此就搞了个包装类,Dubbo 里帮你自动包装,只需要某个扩展类的构造函数只有一个参数,并且是扩展接口类型,就会被判定为包装类,然后记录下来,用来包装别的实现类。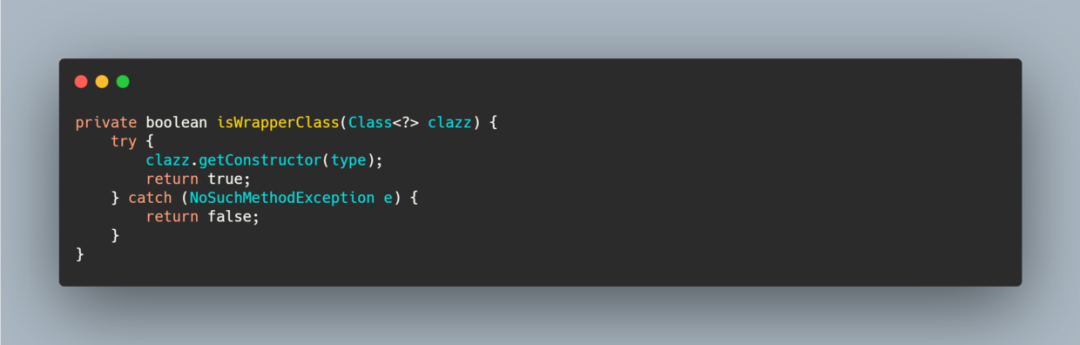
简单又巧妙,这就是 AOP 了。
injectExtension - IOC
直接看代码,很简单,就是查找 set 方法,根据参数找到依赖对象则注入。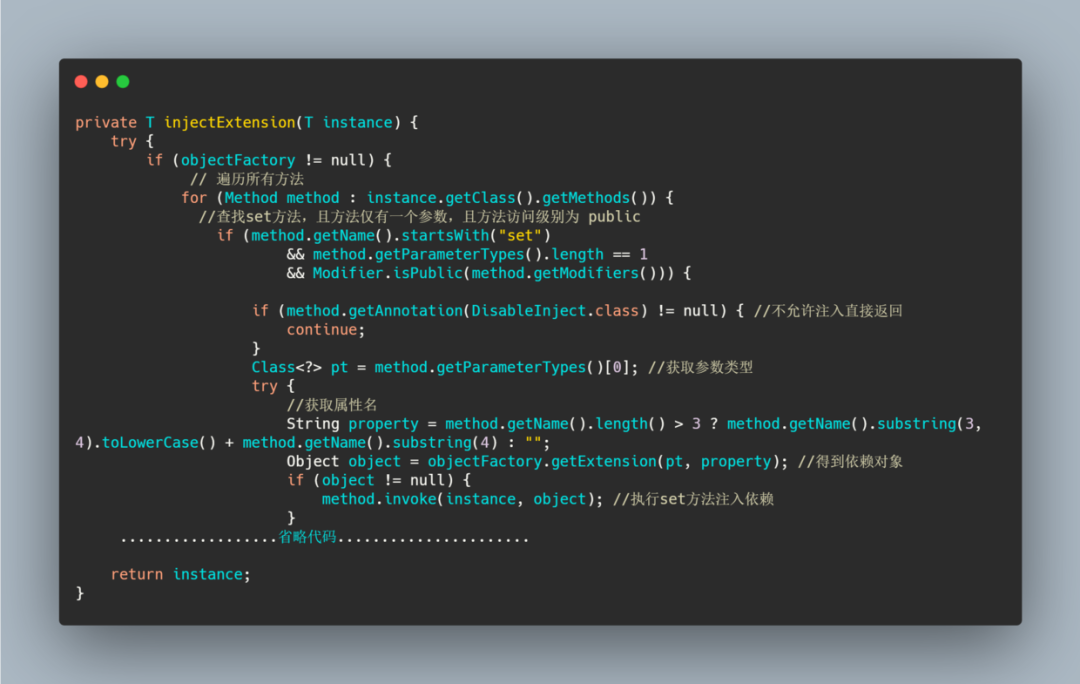
这就是 IOC。
Activate 注解
这个注解我就简单的说下,拿 Filter 举例,Filter 有很多实现类,在某些场景下需要其中的几个实现类,而某些场景下需要另外几个,而 Activate 注解就是标记这个用的。
它有三个属性,group 表示修饰在哪个端,是 provider 还是 consumer,value 表示在 URL参数中出现才会被激活,order 表示实现类的顺序。
总结
先放个上述过程完整的图。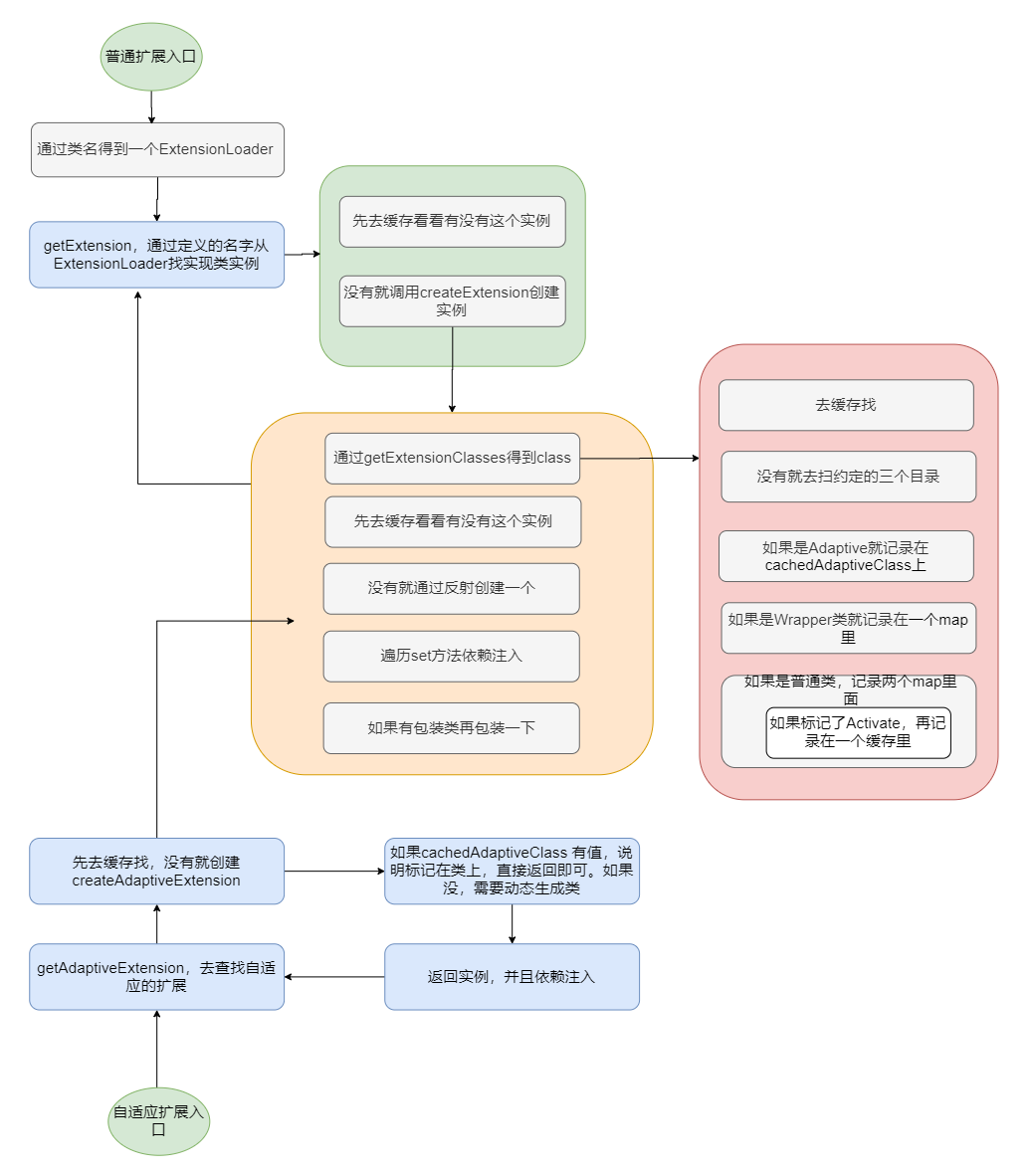

若有收获,就点个赞吧
0 人点赞
