拓展:负载均衡——随机算法(实现思路)
随机算法的演进过程如下,假设是3台机器
简单随机算法
1、为3台机器都分配一个唯一的id
2、将3台机器的ip地址都维护在1个map中,map
3、调用random类随机获取一个uuid,对3取余,得到id
4、根据id,在map中获取到对应的ip
带权随机算法
1、为3台机器分配一个区间,区间根据机器设置的权重来划分
2、通过uuid取模获取到随机数,注意除数不是机器个数,而是总权重
3、判断该随机数位于哪个区间
4、获取该区间对应的机器的ip地址
拓展:负载均衡——轮询算法(实现思路)
简单轮询算法
1、将3台机器的ip维护在一个list中
2、维护一个int类型的全局变量pos
3、调用list.get(int index)方法,获取处理此次请求的ip地址
4、pos++ % list.size(),代表下一次处理请求的ip地址在list中的index
配置如下:
A:5
B:1
C:1
实现效果:
A B C A B C……….
带权轮询算法
1、将3台机器的ip维护在一个list中,为每个机器都分配一个区间
2、维护一个int类型的全局变量pos
3、对requestID取模,除数为设置的总权重,算出该请求位于哪个区间
3、判断pos的值,是否位于某个区间,返回对应机器的ip地址
4、pos++ % 总权重,计算下一次处理该请求的机器对应的pos
配置如下:
A:5
B:1
C:1
实现效果:
A A A A A B C A A A A A B C ……..
平滑加权轮询算法(待实现)
配置如下:
A:5
B:1
C:1
实现效果:
A A B A A A C A A B A A A C ………
PS:优势,不会向普通的带权轮询算法一样,同一时间多个请求都压在同一个服务器上,其他服务器空闲
拓展:负载均衡——哈希一致性(思路)
问题背景:分布式系统存在的session问题
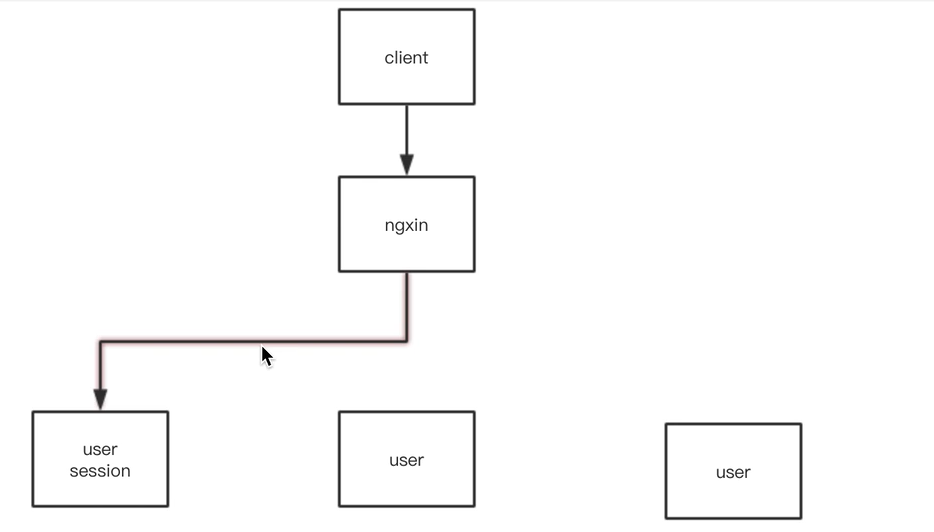
PS:以上是分布式系统存在的问题,解释如下
1、客户端登录,服务端产生一个session
2、下一次用户操作,访问的是user集群的其他节点,发现没有session,就会要求用户重新登录
解决方案:让每一次客户端请求,都访问的是同一个user节点,这就要求nginx的负载均衡算法能够
做到根据请求的ip地址,映射到同一个user节点,这就是所谓的一致性hash算法
解决方案的探讨(最终采取的是hash环的方案)
基本的思路:client IP ==》hash算法 ==》hashcode ==》server IP
1、方案1:将所有的hashcode与server IP的对应关系提前缓存起来;但实际上hashcode是无穷无尽的,
因为我们不清楚客户端IP,客户端IP是未确定的,所以该方案不可行。
2、方案2:根据hashcode的不同,划分不同的区间,每个区间都对应有1个server IP处理请求。
解决了client IP不确定导致hashcode不确定的问题。基本流程如下图所示
(1)ip1、ip2、ip3、ip4分别对应4个服务器IP的hashcode
(2)将hash值分为4个区间
(3)每个区间都有固定的server IP来处理请求
(4)如:hashcode位于 ip4~ip1之间就交由server 1来处理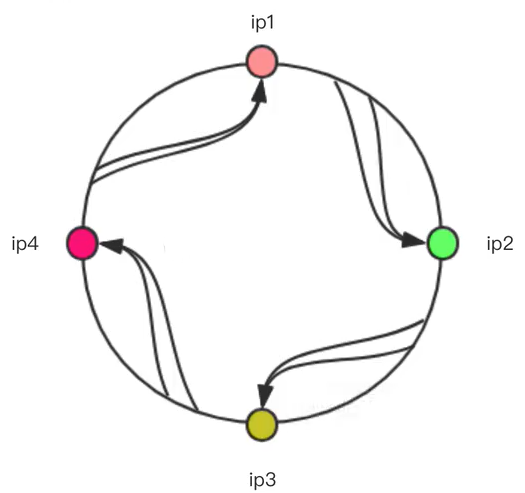
3、改进3:在hash环上划分更多的虚拟节点
当其中有一个节点宕机,意味着后面的节点需要处理更多的请求,因此为了使请求分配地更加“均衡”,
引入多个虚拟节点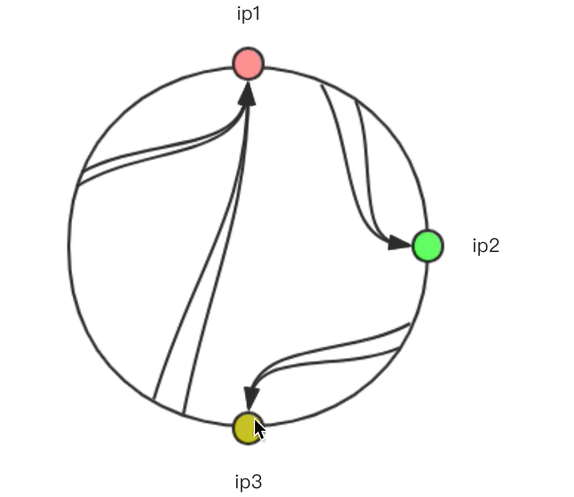

PS:这样,当ip4挂了之后,hashcode位于ip1-2~ip3-2之间的请求都将由hashcode为ip3-2对应的服务器来处理
而不会导致ip4负责的1/4个环的请求都落在ip1机器上。
总结:hash一致性算法,实际上就是根据客户端ip,来最终确定处理该客户端请求的服务器的ip地址, 确保了同一个客户端的多个请求都由同一个服务器来处理;采用的方式是hash环的方式;hash环主要 就是由多个虚拟节点组成的环状结构,每个虚拟节点存储的就是一个服务的ip,以及其对应的hashcode
拓展:常用的分布式ID解决方案
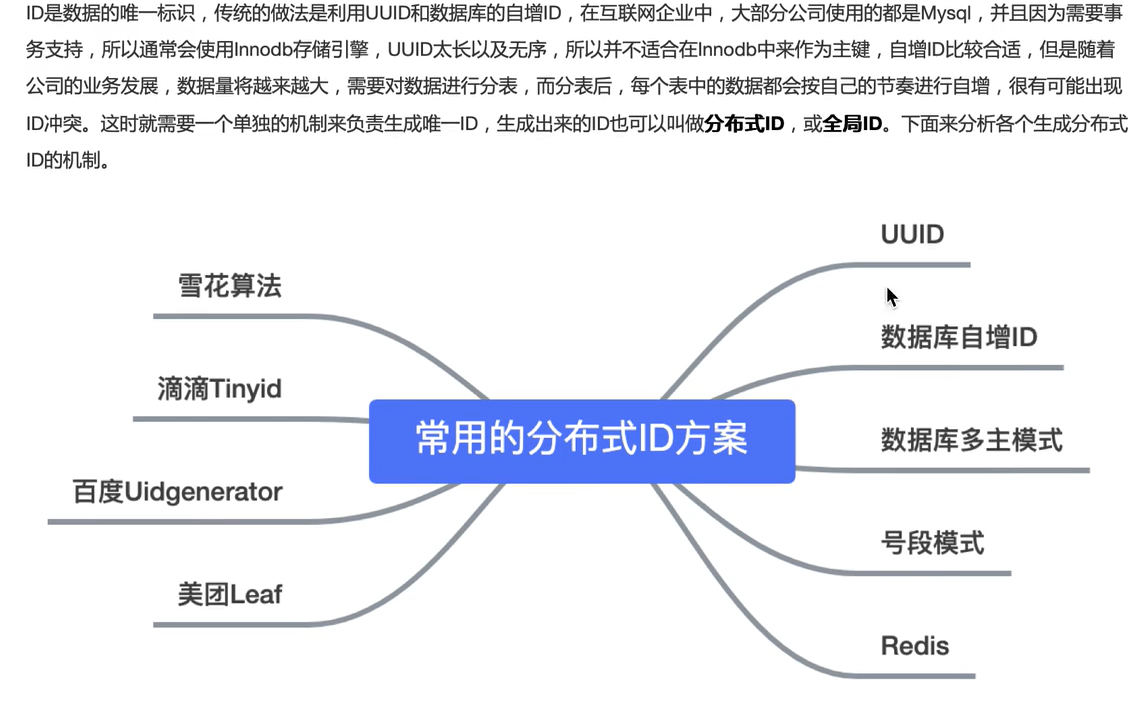
PS:重点,分布式系统中,如何确保某个服务集群,如mysql分表之后,多张位于不同服务器的表的记录的id唯一,是一个问题。虽然uuid是一个方案,但是uuid过长,不适合做主键,于是就提出了许多其他的分布式ID的解决方案,主要方案如上。
PS:该分布式系统的ID生成器必须要保证“高可用”、“高性能”
1、UUID
2、公共数据库的自增ID
3、雪花算法
拓展:分布式ID:雪花算法
基本介绍
雪花算法,就是负责生成一个long型的,即64个bit位的ID的一个算法,该64位ID的结构如下
bit位的分配解释
1、第1位:符号位,不参与运算
2、41位:表示某一时刻,单位是毫秒
3、10位:表示分布式系统集群中的某一台机器
4、12位:表示产生的序列号(该序列号的最大值同时也表示该机器能够在1ms处理的最大并发请求)
核心思想:让负责生成分布式ID的机器,在每毫秒内生成不一样的序列号
最终目的:确保整个分布式系统中,每次请求生成的ID都不一样。
实现方案(github:https://github.com/beyondfengyu/SnowFlake)
实际上,不少互联网大厂都基于雪花算法,实现了自己的分布式ID生成器,美团、滴滴、百度等
以下是雪花算法的基本思路:
/*** snowflake算法 -- java实现*/public class SnowFlake {/*** 起始的时间戳*/private final static long START_STMP = 1480166465631L;/*** 每一部分占用的位数*/private final static long SEQUENCE_BIT = 12; //序列号占用的位数private final static long MACHINE_BIT = 5; //机器标识占用的位数private final static long DATACENTER_BIT = 5;//数据中心占用的位数/*** 每一部分的最大值*/private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);/*** 每一部分向左的位移*/private final static long MACHINE_LEFT = SEQUENCE_BIT;private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;private long datacenterId; //数据中心private long machineId; //机器标识private long sequence = 0L; //序列号private long lastStmp = -1L;//上一次时间戳// 初始化public SnowFlake(long datacenterId, long machineId) {if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");}if (machineId > MAX_MACHINE_NUM || machineId < 0) {throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");}this.datacenterId = datacenterId;this.machineId = machineId;}/*** 产生下一个ID** @return*/public synchronized long nextId() {long currStmp = getNewstmp();if (currStmp < lastStmp) {throw new RuntimeException("Clock moved backwards. Refusing to generate id");}if (currStmp == lastStmp) {//相同毫秒内,序列号自增sequence = (sequence + 1) & MAX_SEQUENCE;//同一毫秒的序列数已经达到最大,等待下一毫秒if (sequence == 0L) {currStmp = getNextMill();}} else {//不同毫秒内,序列号置为0sequence = 0L;}lastStmp = currStmp;// 构造返回的结果(64位)return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分| datacenterId << DATACENTER_LEFT //数据中心部分| machineId << MACHINE_LEFT //机器标识部分| sequence; //序列号部分}private long getNextMill() {long mill = getNewstmp();while (mill <= lastStmp) {mill = getNewstmp();}return mill;}private long getNewstmp() {return System.currentTimeMillis();}public static void main(String[] args) {SnowFlake snowFlake = new SnowFlake(2, 3);for (int i = 0; i < (1 << 12); i++) {System.out.println(snowFlake.nextId());}}}
拓展:分布式事务:案例演示
分布式事务:同一个数据库连接的事务,属于同一个事务,不是分布式事务;分布式事务指的是不同数据库连接
下的事务,主要是指在分布式系统中,不同数据库连接操作数据库引发的一些事务问题。案例如下


PS:解释如下
1、项目1、项目2单独部署在不同机器上(即两个不同的项目)
2、项目1的test事务方法往数据库插入server1记录,然后发起远程调用项目2的事务方法往数据库插入server2记录
3、由于项目1的test方法出现异常,且是事务方法,所以会回滚,因此出现问题
4、但是结果是:数据库中会插入server2记录,server2不会回滚
拓展:分布式事务实现思路
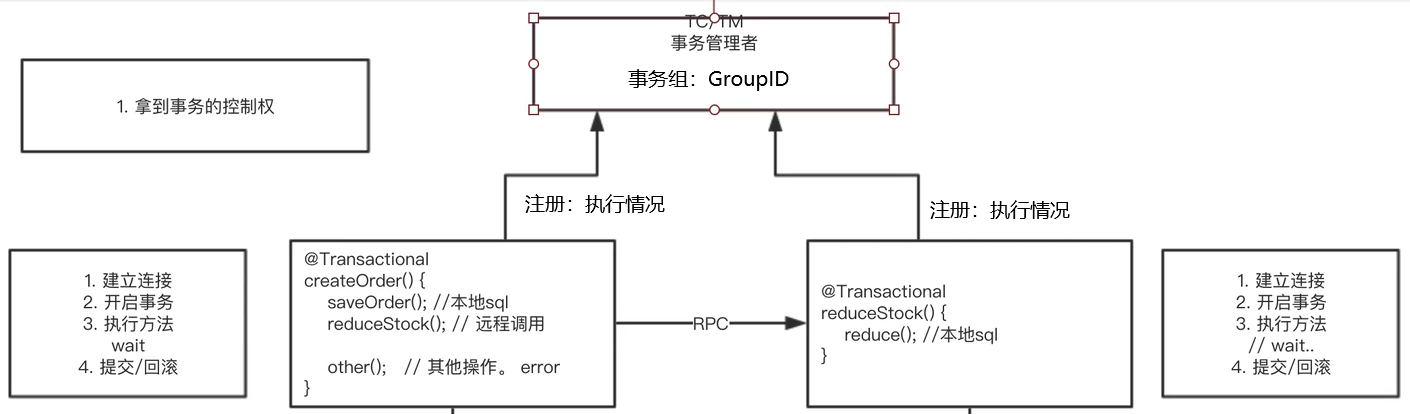
PS:解释如下
1、一个事务方法的执行情况
(1)建立连接
(2)开启事务
(3)处理逻辑
(4)提交事务
2、如何实现分布式事务呢?
(1)首先需要一个事务管理器,来管理整个服务调用的所有事物,每次调用都会有一个事务组ID
(2)整个调用链中涉及的事务都需要将其注册信息注册到事务管理者的事务组中
(3)当事务管理者发现事务组ID中有某个事务执行失败,就会导致整个事务组中的所有事物回滚

若有收获,就点个赞吧
0 人点赞
