整体架构
参考了kafka: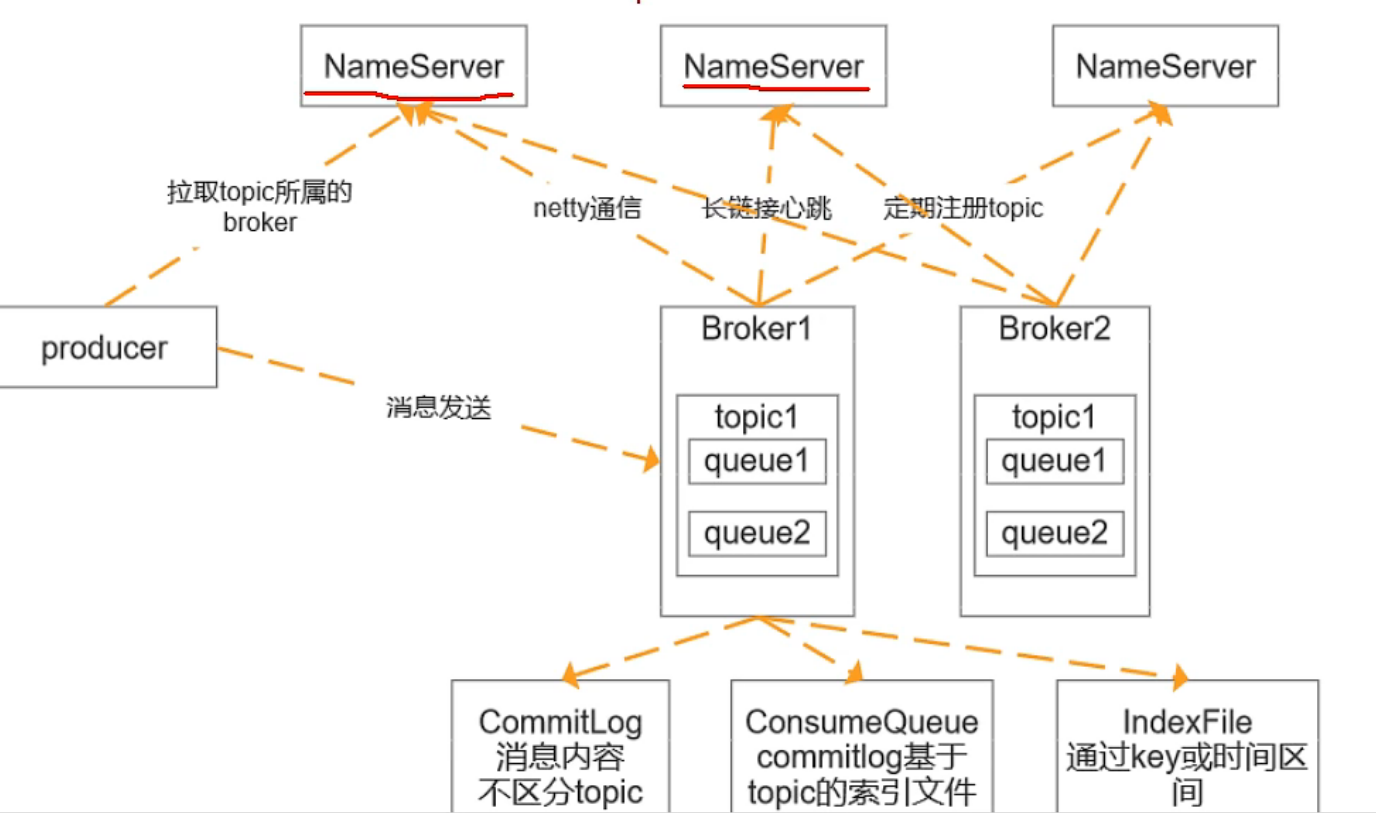
NameServer: 类似于kafka的ZK
ZK本身存在主从和数据同步的。nameServer是一个去中心化的结构,不进行通信,NameServer可用性比较高,主要为了维护消息路由信息。 路由信息包括了:BrokerServer Topic ConsumeQueueId
Broker:节点, 和每一个nameserver都有一个基于Netty的长连接,定期注册topic.
- 三个日志文件:CommitLog 消息内容,不区分topic, 1G 1个。ConsumeQueueLog commitlog基于topic的索引文件,IndexFile是通过key或者时间区间的索引。
-
事务消息原理
依赖于TransactionListener接口
executeLocalTransaction 方法会在发送消息后调用,用于执行本地事务,如果本地事务执行成功,rocketmq再提交消息
- checkLockTransaction用于本地事务的检查,rocketmq依赖此方法做补偿
通过两个内部的topic来实现消息的两阶段支持。
prepare: 将消息(消息上带有事务的标识)投递到名为RMC_SYS_TRANS_HALF_TOPIC的topic中,而不是直接投递到真正的topic。
commit/rollback: producer再通过TransactionListener的executeLocalTransaction方法来执行本地事务,当producer的localTransation处理成功或者失败后,producer会向broker发送commit或者rollback命令,如果是COMMIT,则broker会将投递到RMC_SYS_TRANS_HALF_TOPIC中的消息投递到真实的topic中,然后再投递一个删除的消息到RMC_SYS_TRANS_HALF_TOPIC中,表示当前事务已完成。如果是rollback,则没有投递到真实topic的过程,只需要投递删除的消息到RMC_SYS_TRANS_HALF_TOPIC。最后,消息者和消息普通的消息一样消费消息。
- 第一阶段(prepare失败):给应用返回发送消息失败
- 事务失败:发送回滚命令给broker,由broker执行消息的回滚
- Commit或者rollback失败,由broker定时向producer发起事务回滚,如果本地事务成功,则提交消息事务,否则回滚消息事务。
事务检查由两种情况:
- commit/rollback: broker会执行相应的commit/rollback操作
如果type是TRANSACTION_NOT_TYPE,则一段时间后会检查,当检查次数超过上限(默认15次)则丢弃消息。
怎么实现顺序消息?
默认是不能保证的,需要程序去保证发送和消息的是同一个queue,多线程消费也无法保证
发送顺序:发送端自己业务逻辑保证先后,发往一个固定的Queue, 生产者可以在消息体上设置消息的顺序
发送者实现MessageQueueSelector, 选择一个queue进行发送,也可使用rocketmq提供的默认实现:SelectMessageQueueByHash: 按照参数的hashCode与可选择的队列进行求余操作
- SelectMessageQueueByRandom: 随机选择
mq: queue本身就是顺序追加写,只需要保证一个队列同一时间只有一个comsumer再消费,通过加锁实现,consumer上的顺序消息有一个定时任务,每隔一定的时间向broker发送请求演唱锁定。
pull模式:消费者需要自己维护需要拉取的queue, 一次拉取的消息都是顺序的,需要消费者自己保证顺序消费
pull模式:消费实例实现自MQPushConsumer接口,提供注册监听的方法消费消息,registerMessageListener、重载方法
- MessageListenerConcurrently : 并行消费
- MessageListenerOrderly: 串行消费,consumer会把消息放入本地队列并加锁,定时任务保证锁的同步。
持久化机制
CommitLog
日志数据文件,被所有的queue共享,大小为1G,写满之后重新生成,顺序写ConsumeQueue
逻辑queue, 消息先到达commitlog,然后异步转发到consumeQueue,包含queue在commitLog中的物理位置偏移量Offset,消息实体内容大小和message tag 的hash值,大小约为600W个字节,写满之后重新生成,顺序写index file
通过时间或者区间来查找commitlog中的消息,文件名以创建的时间戳命名,固定的单个index file大小为400M,可以保存2000W个索引
所有队列公用一个日志数据文件,避免了kafka分区数过多,日志文件过多导致的磁盘IO读写压力较大造成的性能瓶颈,rocketmq的queue只存储少量数据,更加轻量化,对磁盘的访问是串行化避免磁盘竞争,缺点在于,写入的顺序写,读写是随机读,写读ConsumeQueue,再读CommitLog,会降低消息读的效率。
消息发送到broker之后,会被写入commit log,写之前加锁,保证顺序写入,然后转发到ConsumeQueue
消息消费时先从ConsumeQueue读取在CommitLog中的起始位置偏移量Offset, 消息大小和消息tag的hashCode值,在从Commit Log中读取消息的内容。
- 同步刷盘:消息持久化到磁盘才会给生产者返回ack,可以保证消息可靠,但是会影响性能
- 异步刷盘:消息写入page Cache就返回ack给生产者,刷盘采用异步线程,降低读写延迟提高性能和吞吐。消息存在丢失的 风险。
如何保证不丢消息?
生产者
- 同步阻塞的方式发送消息,加上失败重试机制,可能broker存储失败,而可以通过查询确认
- 异步发送需要重写回调方法,检查发送结果
- ack机制,可能存储Commit Log,存储ConsumeQueue失败,此时对消费者不可见
生产者
- Broker在启动的时候会向所有的nameservier注册,并保持长连接,每30秒发送一次心跳
- Produdcer在发送消息的时候从NameServer获取Broker服务器地址,根据负载均衡算法选择一台服务器来发发送消息
Consumer消费消息的时候同样从NameServer获取Borker的地址,然后主动拉取消息来消费。
使用mq如何保证分布式事务的最终一致性?
分布式事务:业务相关的多个操作要保证他们同时成功同时失败。
事务的最终一致性:和强一致性对应。
需要保证两点:生产者需要保证消息能够100%投递,事务消息机制
- 消费者一端需要保证幂等消费
保证消费的幂等性
防止消费者重复消费的问题,所有的mq产品都没有主动解决幂等性的问题,需要由消费者自行控制。
-
MQ怎么保证消息的高效读写
零拷贝计数来优化文件的读写。
传统文件的拷贝方式:
硬件拷贝 -> 内核拷贝 -> 用户空间
零拷贝:
省略用户空间的拷贝,用户空间支持拿到一次虚拟的映射,映射修改,整个文件是在内存空间完成读写,减少了两次拷贝。这就是mmap. Mmap方式通过MappedByteBuffer对象进行操作,transfile通过FileChannel来进行操作。
在底层使用DirectMemory技术。
mmap适合操作比较小的文件,通常文件大小不超过1.5G到2G之间。 RocketMq当中使用Mmap方式来进行文件的读写。先初始化1G的文件,然后再往里面去写数据。
如何保证消息的顺序
全局有序,局部有序;MQ只需要保证局部有序,不需要保证全局有序。
MessageQueneSelector。把消息发送到一个固定的队列上去。
消费者端注册一个监听,MessageListenerOrderly
MQ的结构就是先进先出。
核心:生产者把一组有序的消息放到同一个队列中,而消费者一次消费整个队列当中的消息。
如何进行产品选型
| MQ 产品 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|
| Kafka | 1. 吞吐量非常大 1. 性能非常好 1. 集群高可用 |
1. 会丢失数据 1. 功能比较单一 |
日志分析、大数据采集 |
| Rabbit Mq | 1. 消息可靠性高 1. 功能全面 |
1. 吞吐量比较低,并发性能不高 1. 消息积压会严重影响性能 1. erlang语言不好定制 |
适合小规模场景 |
| Rocket mq | 1. 高吞吐、高性能、高可用 1. 功能比较全面 |
1. 开源版本功能不如云上商业版 1. 官方文档和周边生态不太成熟,客户端只支持java |
几乎是全场景。 |

若有收获,就点个赞吧
0 人点赞
