数据结构
- 数组+链表(JDK1.7)
- 数组+链表+红黑树(1.8)
数组的每个地方都存了key-value的实例,Java7叫Entry,java8叫Node
本身数组的所有位置都是null, put插入会根据key的hash去计算一个index值。
为什么要使用链表?
数组的长度是有限的,在有限的长度使用哈希,哈希本身就存在概率性,可能多个key的hash值是一样的。
每一个Node节点都会保存自身的hash、key、value以及下个节点。Node源码: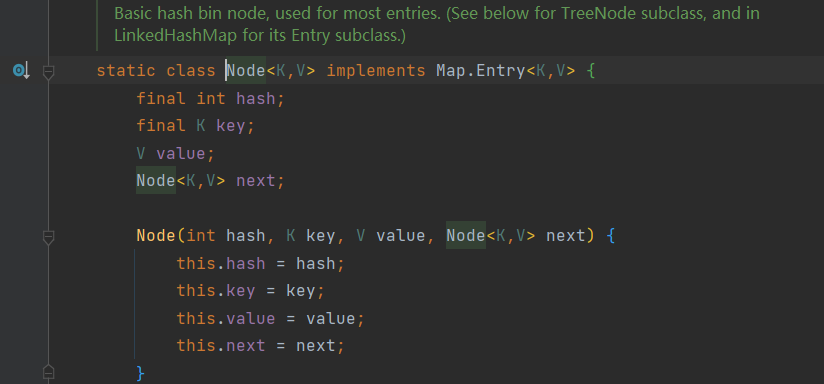
Entry节点插入的时候,是怎么插入的?
1.7 采用的是头插法,就是新来的值会代替原来的值,原来的值就顺推到链表中去。
因为代码的作者认为后来的值被查询的可能性更大一点,提升查找的效率。
1.8 采用尾插法。
首先要了解扩容机制. 头插法扩容的时候,会resize,可能出现环形链表 头插法会改变链表上的顺序,但是使用尾插法,在扩容时会保持链表元素原来的顺序,就不会出现链表成环的问题。
HashMap的扩容机制
数组的容量是有限的,数据多次插入,到达一定的数量就会进行扩容,也就是resize
什么时候resize ?
有两个因素:
- Capacity : HashMap当前长度
- LoadFactor: 负载因子,默认是0.75f
扩容的步骤
- 扩容: 创建一个新的Entry空数组,长度是原数组的2倍
- ReHash: 遍历原来的Entry数组,把所有的Entry重新Hash到新数组。
为什么要重新Hash, 不是直接复制过去?
长度扩容之后,Hash的规则也随之改变。
Hash的公式: index = HashCode(key) & (length -1 )
原来长度是8,位运算出来是2,新的长度是16,位运算结果就不一样了。
尾插法就线程安全了吗?
put、get 方法没有加同步锁,多线程情况下无法保证上一秒put的值下一秒get的时候还是原值,所以线程安全还是没有保障。
HashMap初始长度是多少?
16.
为啥是16?

为啥用位运算?不直接写16?HashMap赋初值最好是2的幂。
这样是为了位运算方便,效率高。选择16,是为了服务将key映射到index的算法。
所有的key都要拿到他的Hash,但是怎么尽可能的得到一个均匀分布的Hash呢?
如果是2的整数幂,length-1的值是所有二进制位全为1,这样index的结果等同于HashCode的后几位。
只要输入的hashCode本身分布均匀,Hash的算法的结果就是均匀的。
这是为了实现均匀分布。
为什么是16,不是8,不是32?
hashMap中链表大小超过8个转化为红黑树,小于6时重新变为链表,为什么?
根据泊松分布,负载因子默认为0.75的时候,单个hash槽内元素个数为8的概率小于百万分之一,所以将7作为一个分水岭,等于7的时候不转换,大于等于8的时候才转换,小于等于6的时候转化为链表。
扩展:
为什么重写equals的时候需要重写hashCode?
保证相同对象返回相同的hash值,不同的对象返回不同的HashCode
HashMap的key为什么常用String类型?
可以使用任何类作为Map 的key , 然而在使用之前,需要考虑以下几点
- 如果类重写了equals() 方法,也应该重写hashCode()方法。如果一个类没有使用equals(), 不应该在hashCode() 中使用它。
- 类的所有实例需要遵循与equals() 和hashCode() 相关的规则。
- 最好还是使用不可变类
- 缓存HashCode: String类在被创建的时候,hashcode就被缓存到hash成员变量中,因为String类是不可变的,所以hashcode是不会改变的。这样每次想使用hashcode的时候直接取就行了,而不用重新计算,提高了效率
- 由于String类不可变的特性,所以经常被用作HashMap的key,如果String类是可变的,内容改变,hashCode也会改变,当根据这个key从HashMap中取的时候有可能取不到value,或者取到错的value

若有收获,就点个赞吧
0 人点赞
