跳跃表简介
跳跃表(skiplist)是一种随机化的数据结构,是一种与平衡树媲美的层次化链表结构,查找删除添加等操作都可以在对数期望时间下完成,以下是一个典型的例子: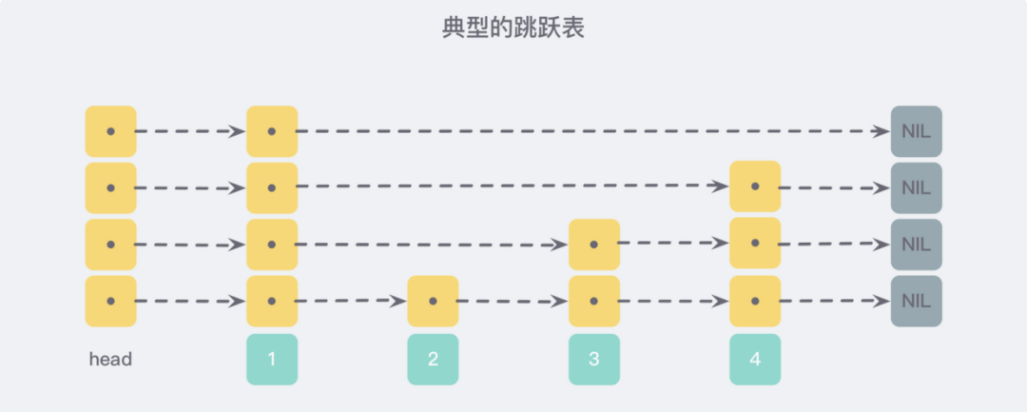
类似于redis中zset和hashMap的结合体。一方面是一个set保证了内部value的唯一性,另一方面又可以给每个value赋予一个排序的权重值score,来达到排序的目的。内部依赖一种叫做跳跃列表的数据结构。
为什么使用跳跃列表?
首先,zset要支持随机的插入和删除,所以不宜使用数组来实现。关于排序问题,我们很容易联想到红黑树、平衡树这样的树形结构,为什么redis不使用呢?
zset使用跳跃表实现。
性能考虑
在高并发的情况下,树形结构需要执行一些类似于rebalance这样可能涉及整颗树的操作,相对来说跳跃表的变化只涉及局部。
实现考虑
在复杂度与红黑树相同的情况下,跳跃表实现更简单也更直观。
本质是解决查找问题
普通的链表结构: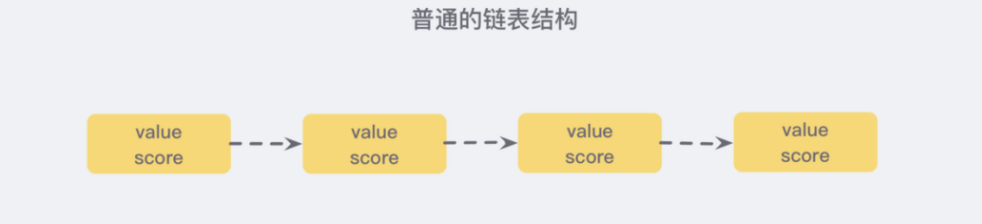
我们需要这个链表按照score值进行排序,这也就意味着,当我们需要添加新的元素时,我们需要定位到插入点,这样才可以继续保证链表是有序的,通常我们会采用二分查找法,但是二分查找的有序数组,链表没办法进行位置定位,我们除了遍历整个找到第一个比给定数据大的节点为止,似乎没有更好的办法。
但假如我们给每相邻的两个节点之间就添加一个指针, 让指针指向下一个节点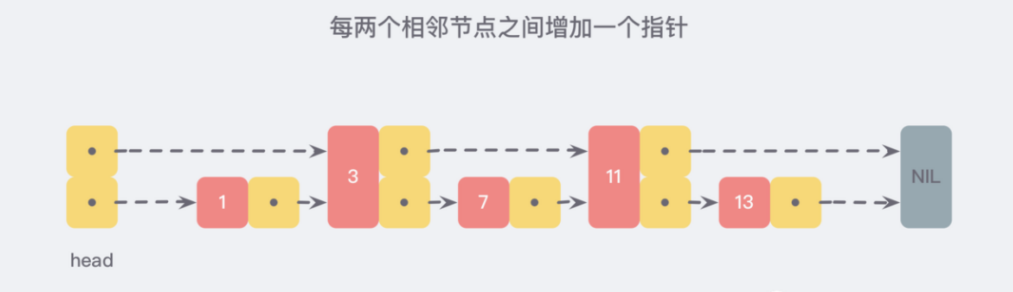 这样新增的指针连成一个新的链表,但它包含的数据却只有原来的一半。图中为3和11.
这样新增的指针连成一个新的链表,但它包含的数据却只有原来的一半。图中为3和11.
利用同样的方式,我们可以在新产生的链表上,继续为每两个相邻的节点增加一个指针,从而产生第三层链表: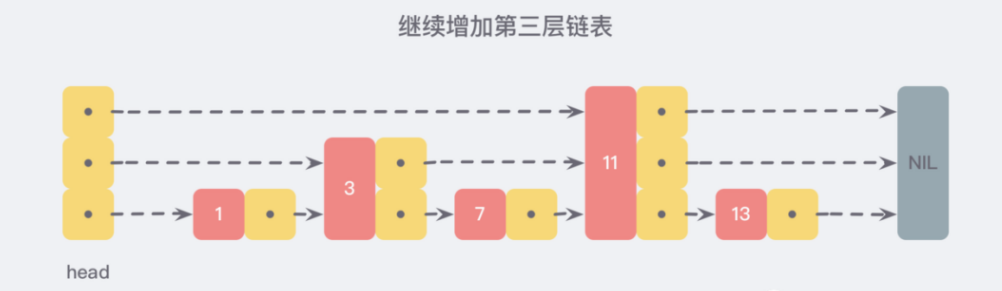
在这个新的三层链表结构中,我们试着 查找 13,那么沿着最上层链表首先比较的是 11,发现 11 比 13 小,于是我们就知道只需要到 11 后面继续查找,从而一下子跳过了 11 前面的所有节点。
可以想象,当链表足够长,这样的多层链表结构可以帮助我们跳过很多下层节点,从而加快查找的效率。
更进一步的跳跃表
跳跃表 skiplist 就是受到这种多层链表结构的启发而设计出来的。按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似于一个二分查找,使得查找的时间复杂度可以降低到 O(logn)。
但是,这种方法在插入数据的时候有很大的问题。新插入一个节点之后,就会打乱上下相邻两层链表上节点个数严格的 2:1 的对应关系。如果要维持这种对应关系,就必须把新插入的节点后面的所有节点 (也包括新插入的节点) 重新进行调整,这会让时间复杂度重新蜕化成 O(n)。删除数据也有同样的问题。
skiplist 为了避免这一问题,它不要求上下相邻两层链表之间的节点个数有严格的对应关系,而是 为每个节点随机出一个层数(level)。比如,一个节点随机出的层数是 3,那么就把它链入到第 1 层到第 3 层这三层链表中。为了表达清楚,下图展示了如何通过一步步的插入操作从而形成一个 skiplist 的过程:
从上面的创建和插入的过程中可以看出,每一个节点的层数(level)是随机出来的,而且新插入一个节点并不会影响到其他节点的层数,因此,插入操作只需要修改节点前后的指针,而不需要对多个节点都进行调整,这就降低了插入操作的复杂度。
现在我们假设从我们刚才创建的这个结构中查找 23 这个不存在的数,那么查找路径会如下图:
Redis 跳跃表默认允许最大的层数是 32,被源码中 ZSKIPLIST_MAXLEVEL 定义,当 Level[0] 有 264 个元素时,才能达到 32 层,所以定义 32 完全够用了。
参考文档:

若有收获,就点个赞吧
0 人点赞
