virtio 的基本原理
在虚拟化技术的早期,不同的虚拟化技术会针对不同硬盘设备和网络设备实现不同的驱动,虚拟机里面的操作系统也要根据不同的虚拟化技术和物理存储和网络设备,选择加载不同的驱动。但是,由于硬盘设备和网络设备太多了,驱动纷繁复杂。
后来慢慢就形成了一定的标准,这就是virtio,就是虚拟化 I/O 设备的意思。virtio 负责对于虚拟机提供统一的接口。也就是说,在虚拟机里面的操作系统加载的驱动,以后都统一加载 virtio 就可以了。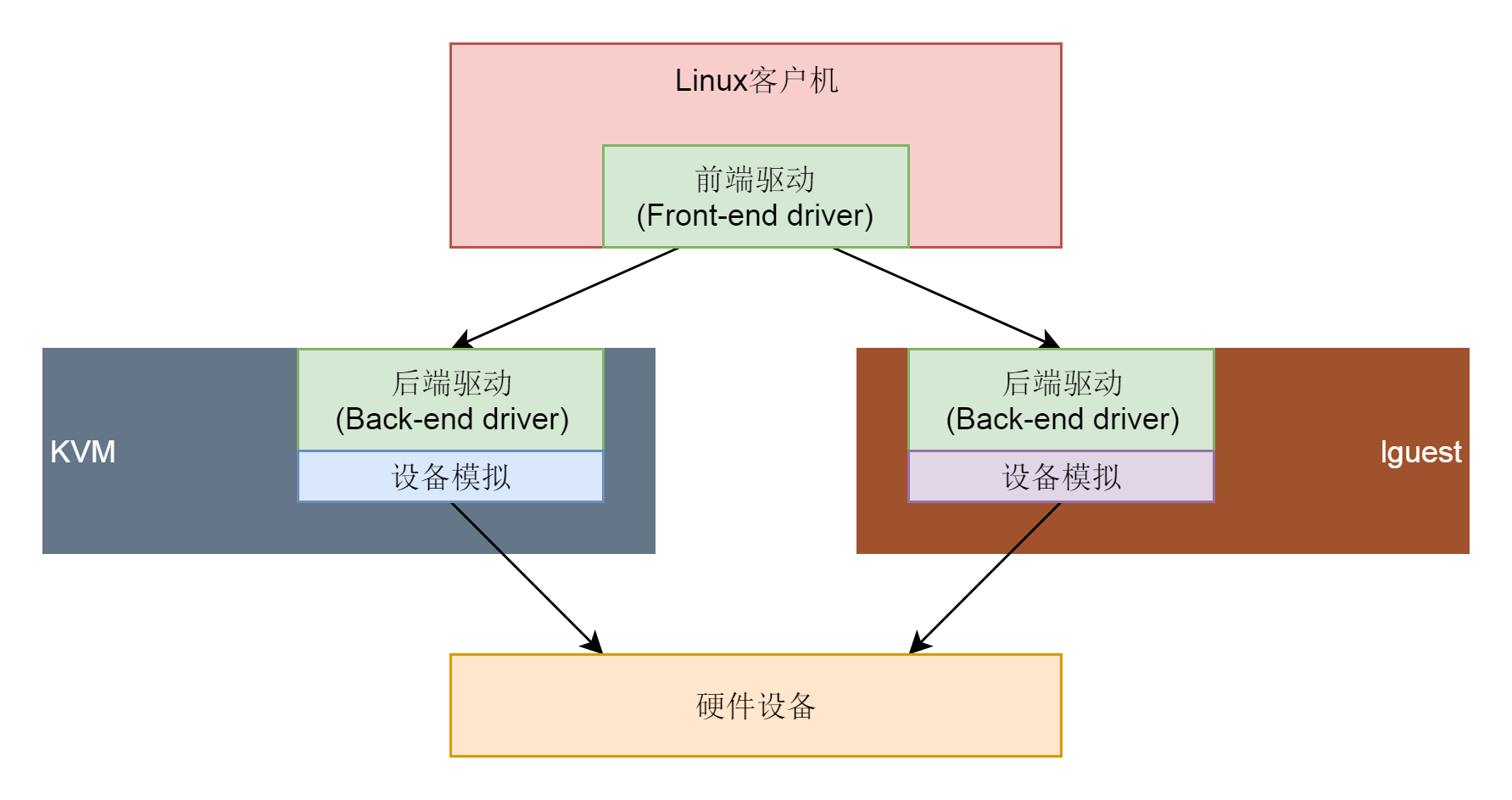
在虚拟机外,我们可以实现不同的 virtio 的后端,来适配不同的物理硬件设备。那 virtio 到底长什么样子呢?我们一起来看一看。
virtio 的架构可以分为四层。
- 首先,在虚拟机里面的 virtio 前端,针对不同类型的设备有不同的驱动程序,但是接口都是统一的。例如,硬盘就是 virtio_blk,网络就是 virtio_net。
- 其次,在宿主机的 qemu 里面,实现 virtio 后端的逻辑,主要就是操作硬件的设备。例如通过写一个物理机硬盘上的文件来完成虚拟机写入硬盘的操作。再如向内核协议栈发送一个网络包完成虚拟机对于网络的操作。
- 在 virtio 的前端和后端之间,有一个通信层,里面包含virtio 层和virtio-ring 层。virtio 这一层实现的是虚拟队列接口,算是前后端通信的桥梁。而 virtio-ring 则是该桥梁的具体实现。
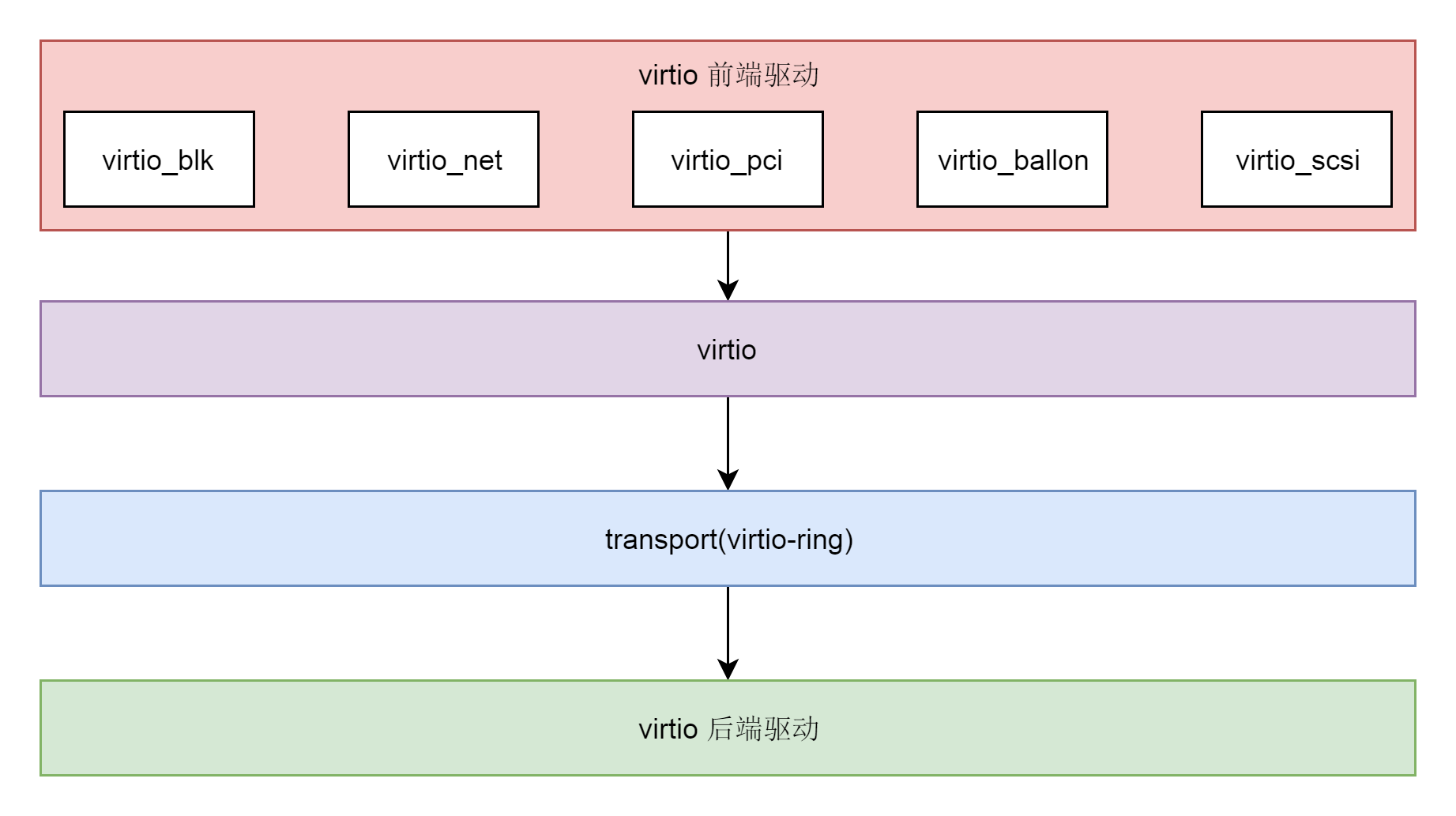
virtio 使用 virtqueue 进行前端和后端的高速通信。不同类型的设备队列数目不同。virtio-net 使用两个队列,一个用于接受,另一个用于发送;而 virtio-blk 仅使用一个队列。
如果客户机要向宿主机发送数据,宿主机会将数据的 buffer 添加到 virtqueue 中,然后通过写入寄存器通知宿主机。这样宿主机就可以从 virtqueue 中收到的 buffer 里面的数据。
了解了 virtio 的基本原理,接下来,我们以硬盘写入为例,具体看一下存储虚拟化的过程。
初始化阶段的存储虚拟化
和咱们在学习 CPU 的时候看到的一样,Virtio Block Device 也是一种类。它的继承关系如下:
static const TypeInfo device_type_info = {.name = TYPE_DEVICE,.parent = TYPE_OBJECT,.instance_size = sizeof(DeviceState),.instance_init = device_initfn,.instance_post_init = device_post_init,.instance_finalize = device_finalize,.class_base_init = device_class_base_init,.class_init = device_class_init,.abstract = true,.class_size = sizeof(DeviceClass),};static const TypeInfo virtio_device_info = {.name = TYPE_VIRTIO_DEVICE,.parent = TYPE_DEVICE,.instance_size = sizeof(VirtIODevice),.class_init = virtio_device_class_init,.instance_finalize = virtio_device_instance_finalize,.abstract = true,.class_size = sizeof(VirtioDeviceClass),};static const TypeInfo virtio_blk_info = {.name = TYPE_VIRTIO_BLK,.parent = TYPE_VIRTIO_DEVICE,.instance_size = sizeof(VirtIOBlock),.instance_init = virtio_blk_instance_init,.class_init = virtio_blk_class_init,};static void virtio_register_types(void){type_register_static(&virtio_blk_info);}type_init(virtio_register_types)复制代码
Virtio Block Device 这种类的定义是有多层继承关系的。TYPE_VIRTIO_BLK 的父类是 TYPE_VIRTIO_DEVICE,TYPE_VIRTIO_DEVICE 的父类是 TYPE_DEVICE,TYPE_DEVICE 的父类是 TYPE_OBJECT。到头了。
type_init 用于注册这种类。这里面每一层都有 class_init,用于从 TypeImpl 生产 xxxClass。还有 instance_init,可以将 xxxClass 初始化为实例。
在 TYPE_VIRTIO_BLK 层的 class_init 函数 virtio_blk_class_init 中,定义了 DeviceClass 的 realize 函数为 virtio_blk_device_realize,这一点在CPU那一节也有类似的结构。
static void virtio_blk_device_realize(DeviceState *dev, Error **errp){VirtIODevice *vdev = VIRTIO_DEVICE(dev);VirtIOBlock *s = VIRTIO_BLK(dev);VirtIOBlkConf *conf = &s->conf;......blkconf_blocksizes(&conf->conf);virtio_blk_set_config_size(s, s->host_features);virtio_init(vdev, "virtio-blk", VIRTIO_ID_BLOCK, s->config_size);s->blk = conf->conf.blk;s->rq = NULL;s->sector_mask = (s->conf.conf.logical_block_size / BDRV_SECTOR_SIZE) - 1;for (i = 0; i < conf->num_queues; i++) {virtio_add_queue(vdev, conf->queue_size, virtio_blk_handle_output);}virtio_blk_data_plane_create(vdev, conf, &s->dataplane, &err);s->change = qemu_add_vm_change_state_handler(virtio_blk_dma_restart_cb, s);blk_set_dev_ops(s->blk, &virtio_block_ops, s);blk_set_guest_block_size(s->blk, s->conf.conf.logical_block_size);blk_iostatus_enable(s->blk);}复制代码
在 virtio_blk_device_realize 函数中,我们先是通过 virtio_init 初始化 VirtIODevice 结构。
void virtio_init(VirtIODevice *vdev, const char *name,
uint16_t device_id, size_t config_size)
{
BusState *qbus = qdev_get_parent_bus(DEVICE(vdev));
VirtioBusClass *k = VIRTIO_BUS_GET_CLASS(qbus);
int i;
int nvectors = k->query_nvectors ? k->query_nvectors(qbus->parent) : 0;
if (nvectors) {
vdev->vector_queues =
g_malloc0(sizeof(*vdev->vector_queues) * nvectors);
}
vdev->device_id = device_id;
vdev->status = 0;
atomic_set(&vdev->isr, 0);
vdev->queue_sel = 0;
vdev->config_vector = VIRTIO_NO_VECTOR;
vdev->vq = g_malloc0(sizeof(VirtQueue) * VIRTIO_QUEUE_MAX);
vdev->vm_running = runstate_is_running();
vdev->broken = false;
for (i = 0; i < VIRTIO_QUEUE_MAX; i++) {
vdev->vq[i].vector = VIRTIO_NO_VECTOR;
vdev->vq[i].vdev = vdev;
vdev->vq[i].queue_index = i;
}
vdev->name = name;
vdev->config_len = config_size;
if (vdev->config_len) {
vdev->config = g_malloc0(config_size);
} else {
vdev->config = NULL;
}
vdev->vmstate = qemu_add_vm_change_state_handler(virtio_vmstate_change,
vdev);
vdev->device_endian = virtio_default_endian();
vdev->use_guest_notifier_mask = true;
}
复制代码
从 virtio_init 中可以看出,VirtIODevice 结构里面有一个 VirtQueue 数组,这就是 virtio 前端和后端互相传数据的队列,最多 VIRTIO_QUEUE_MAX 个。
我们回到 virtio_blk_device_realize 函数。接下来,根据配置的队列数目 num_queues,对于每个队列都调用 virtio_add_queue 来初始化队列。
VirtQueue *virtio_add_queue(VirtIODevice *vdev, int queue_size,
VirtIOHandleOutput handle_output)
{
int i;
vdev->vq[i].vring.num = queue_size;
vdev->vq[i].vring.num_default = queue_size;
vdev->vq[i].vring.align = VIRTIO_PCI_VRING_ALIGN;
vdev->vq[i].handle_output = handle_output;
vdev->vq[i].handle_aio_output = NULL;
return &vdev->vq[i];
}
复制代码
在每个 VirtQueue 中,都有一个 vring,用来维护这个队列里面的数据;另外还有一个函数 virtio_blk_handle_output,用于处理数据写入,这个函数我们后面会用到。
至此,VirtIODevice,VirtQueue,vring 之间的关系如下图所示。这是在 qemu 里面的对应关系,请你记好,后面我们还能看到类似的结构。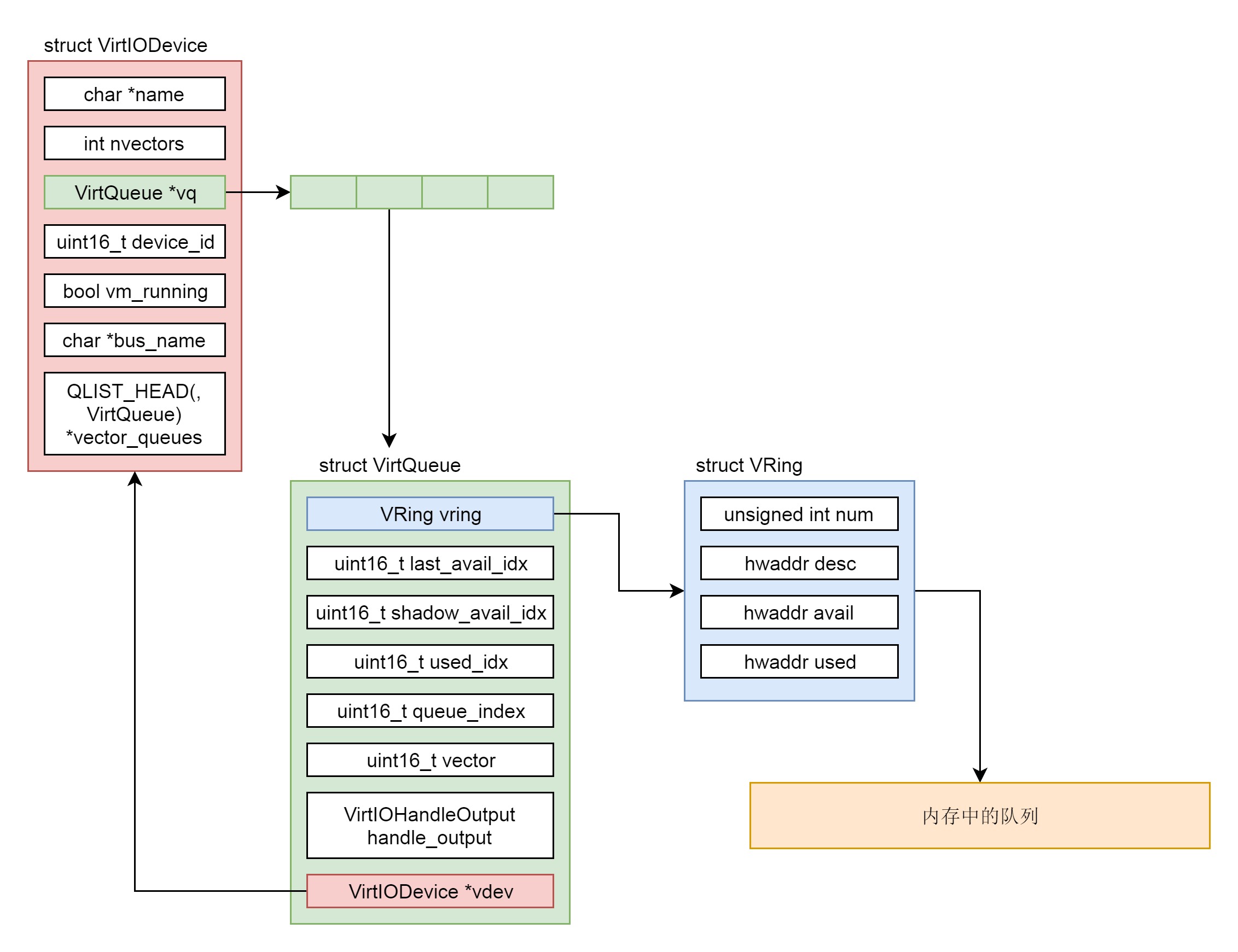
qemu 启动过程中的存储虚拟化
初始化过程解析完毕以后,我们接下来从 qemu 的启动过程看起。
对于硬盘的虚拟化,qemu 的启动参数里面有关的是下面两行:
-drive file=/var/lib/nova/instances/1f8e6f7e-5a70-4780-89c1-464dc0e7f308/disk,if=none,id=drive-virtio-disk0,format=qcow2,cache=none
-device virtio-blk-pci,scsi=off,bus=pci.0,addr=0x4,drive=drive-virtio-disk0,id=virtio-disk0,bootindex=1
复制代码
其中,第一行指定了宿主机硬盘上的一个文件,文件的格式是 qcow2,这个格式我们这里不准备解析它,你只要明白,对于宿主机上的一个文件,可以被 qemu 模拟称为客户机上的一块硬盘就可以了。
而第二行说明了,使用的驱动是 virtio-blk 驱动。
configure_blockdev(&bdo_queue, machine_class, snapshot);
复制代码
在 qemu 启动的 main 函数里面,初始化块设备,是通过 configure_blockdev 调用开始的。
static void configure_blockdev(BlockdevOptionsQueue *bdo_queue, MachineClass *machine_class, int snapshot)
{
......
if (qemu_opts_foreach(qemu_find_opts("drive"), drive_init_func,
&machine_class->block_default_type, &error_fatal)) {
.....
}
}
static int drive_init_func(void *opaque, QemuOpts *opts, Error **errp)
{
BlockInterfaceType *block_default_type = opaque;
return drive_new(opts, *block_default_type, errp) == NULL;
}
复制代码
在 configure_blockdev 中,我们能看到对于 drive 这个参数的解析,并且初始化这个设备要调用 drive_init_func 函数,这里面会调用 drive_new 创建一个设备。
DriveInfo *drive_new(QemuOpts *all_opts, BlockInterfaceType block_default_type, Error **errp)
{
const char *value;
BlockBackend *blk;
DriveInfo *dinfo = NULL;
QDict *bs_opts;
QemuOpts *legacy_opts;
DriveMediaType media = MEDIA_DISK;
BlockInterfaceType type;
int max_devs, bus_id, unit_id, index;
const char *werror, *rerror;
bool read_only = false;
bool copy_on_read;
const char *filename;
Error *local_err = NULL;
int i;
......
legacy_opts = qemu_opts_create(&qemu_legacy_drive_opts, NULL, 0,
&error_abort);
......
/* Add virtio block device */
if (type == IF_VIRTIO) {
QemuOpts *devopts;
devopts = qemu_opts_create(qemu_find_opts("device"), NULL, 0,
&error_abort);
qemu_opt_set(devopts, "driver", "virtio-blk-pci", &error_abort);
qemu_opt_set(devopts, "drive", qdict_get_str(bs_opts, "id"),
&error_abort);
}
filename = qemu_opt_get(legacy_opts, "file");
......
/* Actual block device init: Functionality shared with blockdev-add */
blk = blockdev_init(filename, bs_opts, &local_err);
......
/* Create legacy DriveInfo */
dinfo = g_malloc0(sizeof(*dinfo));
dinfo->opts = all_opts;
dinfo->type = type;
dinfo->bus = bus_id;
dinfo->unit = unit_id;
blk_set_legacy_dinfo(blk, dinfo);
switch(type) {
case IF_IDE:
case IF_SCSI:
case IF_XEN:
case IF_NONE:
dinfo->media_cd = media == MEDIA_CDROM;
break;
default:
break;
}
......
}
复制代码
在 drive_new 里面,会解析 qemu 的启动参数。对于 virtio 来讲,会解析 device 参数,把 driver 设置为 virtio-blk-pci;还会解析 file 参数,就是指向那个宿主机上的文件。
接下来,drive_new 会调用 blockdev_init,根据参数进行初始化,最后会创建一个 DriveInfo 来管理这个设备。
我们重点来看 blockdev_init。在这里面,我们发现,如果 file 不为空,则应该调用 blk_new_open 打开宿主机上的硬盘文件,返回的结果是 BlockBackend,对应我们上面讲原理的时候的 virtio 的后端。
BlockBackend *blk_new_open(const char *filename, const char *reference,
QDict *options, int flags, Error **errp)
{
BlockBackend *blk;
BlockDriverState *bs;
uint64_t perm = 0;
......
blk = blk_new(perm, BLK_PERM_ALL);
bs = bdrv_open(filename, reference, options, flags, errp);
blk->root = bdrv_root_attach_child(bs, "root", &child_root,
perm, BLK_PERM_ALL, blk, errp);
return blk;
}
复制代码
接下来的调用链为:bdrv_open->bdrv_open_inherit->bdrv_open_common.
static int bdrv_open_common(BlockDriverState *bs, BlockBackend *file,
QDict *options, Error **errp)
{
int ret, open_flags;
const char *filename;
const char *driver_name = NULL;
const char *node_name = NULL;
const char *discard;
QemuOpts *opts;
BlockDriver *drv;
Error *local_err = NULL;
......
drv = bdrv_find_format(driver_name);
......
ret = bdrv_open_driver(bs, drv, node_name, options, open_flags, errp);
......
}
static int bdrv_open_driver(BlockDriverState *bs, BlockDriver *drv,
const char *node_name, QDict *options,
int open_flags, Error **errp)
{
......
bs->drv = drv;
bs->read_only = !(bs->open_flags & BDRV_O_RDWR);
bs->opaque = g_malloc0(drv->instance_size);
if (drv->bdrv_open) {
ret = drv->bdrv_open(bs, options, open_flags, &local_err);
}
......
}
复制代码
在 bdrv_open_common 中,根据硬盘文件的格式,得到 BlockDriver。因为虚拟机的硬盘文件格式有很多种,qcow2 是一种,raw 是一种,vmdk 是一种,各有优缺点,启动虚拟机的时候,可以自由选择。
对于不同的格式,打开的方式不一样,我们拿 qcow2 来解析。它的 BlockDriver 定义如下:
BlockDriver bdrv_qcow2 = {
.format_name = "qcow2",
.instance_size = sizeof(BDRVQcow2State),
.bdrv_probe = qcow2_probe,
.bdrv_open = qcow2_open,
.bdrv_close = qcow2_close,
......
.bdrv_snapshot_create = qcow2_snapshot_create,
.bdrv_snapshot_goto = qcow2_snapshot_goto,
.bdrv_snapshot_delete = qcow2_snapshot_delete,
.bdrv_snapshot_list = qcow2_snapshot_list,
.bdrv_snapshot_load_tmp = qcow2_snapshot_load_tmp,
.bdrv_measure = qcow2_measure,
.bdrv_get_info = qcow2_get_info,
.bdrv_get_specific_info = qcow2_get_specific_info,
.bdrv_save_vmstate = qcow2_save_vmstate,
.bdrv_load_vmstate = qcow2_load_vmstate,
.supports_backing = true,
.bdrv_change_backing_file = qcow2_change_backing_file,
.bdrv_refresh_limits = qcow2_refresh_limits,
......
};
复制代码
根据上面的定义,对于 qcow2 来讲,bdrv_open 调用的是 qcow2_open。
static int qcow2_open(BlockDriverState *bs, QDict *options, int flags,
Error **errp)
{
BDRVQcow2State *s = bs->opaque;
QCow2OpenCo qoc = {
.bs = bs,
.options = options,
.flags = flags,
.errp = errp,
.ret = -EINPROGRESS
};
bs->file = bdrv_open_child(NULL, options, "file", bs, &child_file,
false, errp);
qemu_coroutine_enter(qemu_coroutine_create(qcow2_open_entry, &qoc));
......
}
复制代码
在 qcow2_open 中,我们会通过 qemu_coroutine_enter 进入一个协程 coroutine。什么叫协程呢?我们可以简单地将它理解为用户态自己实现的线程。
前面咱们讲线程的时候说过,如果一个程序想实现并发,可以创建多个线程,但是线程是一个内核的概念,创建的每一个线程内核都能看到,内核的调度也是以线程为单位的。这对于普通的进程没有什么问题,但是对于 qemu 这种虚拟机,如果在用户态和内核态切换来切换去,由于还涉及虚拟机的状态,代价比较大。
但是,qemu 的设备也是需要多线程能力的,怎么办呢?我们就在用户态实现一个类似线程的东西,也就是协程,用于实现并发,并且不被内核看到,调度全部在用户态完成。
从后面的读写过程可以看出,协程在后端经常使用。这里打开一个 qcow2 文件就是使用一个协程,创建一个协程和创建一个线程很像,也需要指定一个函数来执行,qcow2_open_entry 就是协程的函数。
static void coroutine_fn qcow2_open_entry(void *opaque)
{
QCow2OpenCo *qoc = opaque;
BDRVQcow2State *s = qoc->bs->opaque;
qemu_co_mutex_lock(&s->lock);
qoc->ret = qcow2_do_open(qoc->bs, qoc->options, qoc->flags, qoc->errp);
qemu_co_mutex_unlock(&s->lock);
}
复制代码
我们可以看到,qcow2_open_entry 函数前面有一个 coroutine_fn,说明它是一个协程函数。在 qcow2_do_open 中,qcow2_do_open 根据 qcow2 的格式打开硬盘文件。这个格式官网就有,我们这里就不花篇幅解析了。
总结时刻
我们这里来总结一下,存储虚拟化的过程分为前端、后端和中间的队列。
- 前端有前端的块设备驱动 Front-end driver,在客户机的内核里面,它符合普通设备驱动的格式,对外通过 VFS 暴露文件系统接口给客户机里面的应用。这一部分这一节我们没有讲,放在下一节解析。
- 后端有后端的设备驱动 Back-end driver,在宿主机的 qemu 进程中,当收到客户机的写入请求的时候,调用文件系统的 write 函数,写入宿主机的 VFS 文件系统,最终写到物理硬盘设备上的 qcow2 文件。
- 中间的队列用于前端和后端之间传输数据,在前端的设备驱动和后端的设备驱动,都有类似的数据结构 virt-queue 来管理这些队列,这一部分这一节我们也没有讲,也放到下一节解析。
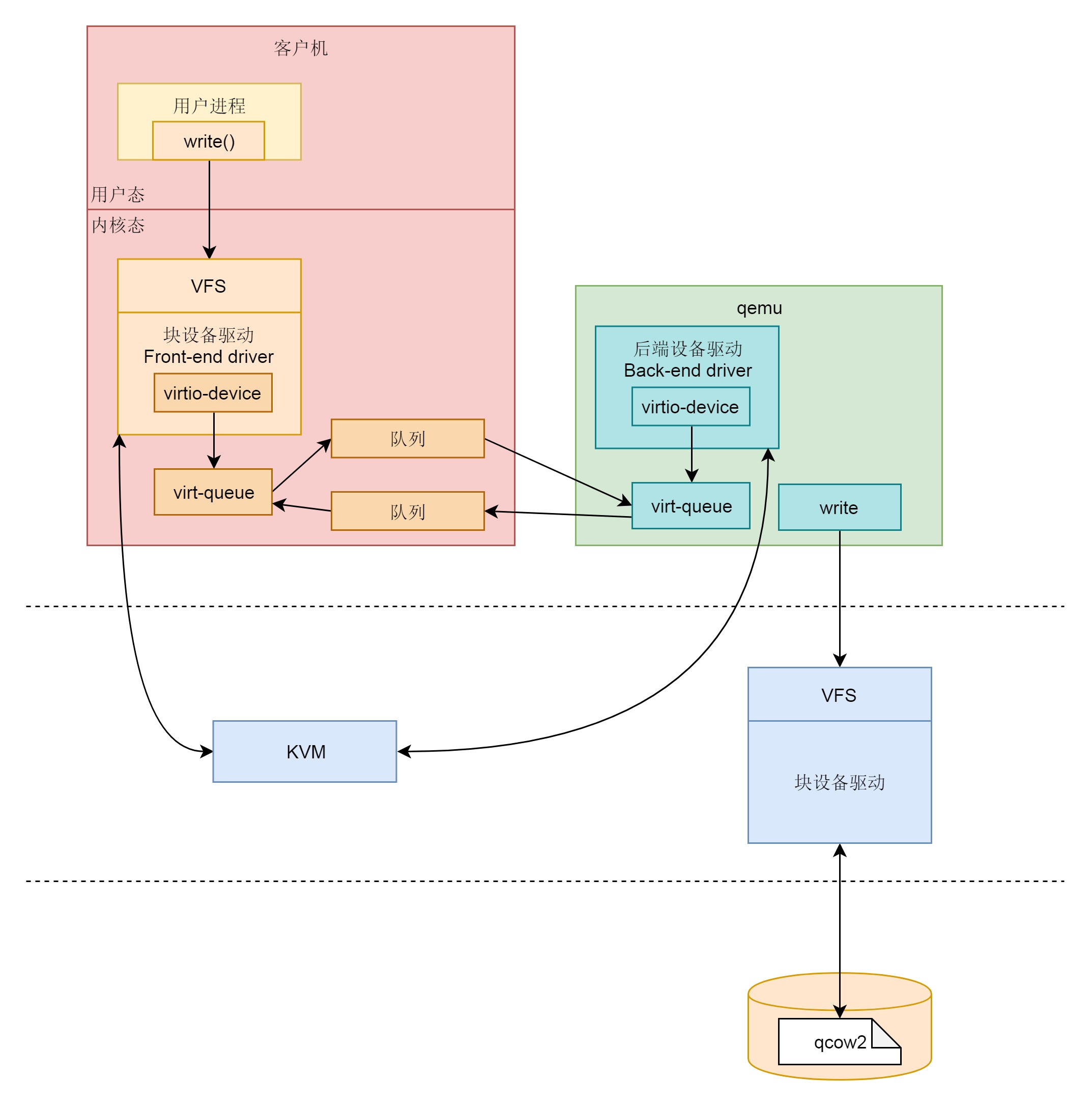
如果我们要往虚拟机的一个进程写入一个文件,该怎么做呢?最终这个文件又是如何落到宿主机上的硬盘文件的呢?这一节,我们一起来看一看。
前端设备驱动 virtio_blk
虚拟机里面的进程写入一个文件,当然要通过文件系统。整个过程和咱们在文件系统那一节讲的过程没有区别。只是到了设备驱动层,我们看到的就不是普通的硬盘驱动了,而是 virtio 的驱动。
virtio 的驱动程序代码在 Linux 操作系统的源代码里面,文件名叫 drivers/block/virtio_blk.c。
static int __init init(void)
{
int error;
virtblk_wq = alloc_workqueue("virtio-blk", 0, 0);
major = register_blkdev(0, "virtblk");
error = register_virtio_driver(&virtio_blk);
......
}
module_init(init);
module_exit(fini);
MODULE_DEVICE_TABLE(virtio, id_table);
MODULE_DESCRIPTION("Virtio block driver");
MODULE_LICENSE("GPL");
static struct virtio_driver virtio_blk = {
......
.driver.name = KBUILD_MODNAME,
.driver.owner = THIS_MODULE,
.id_table = id_table,
.probe = virtblk_probe,
.remove = virtblk_remove,
......
};
复制代码
前面我们介绍过设备驱动程序,从这里的代码中,我们能看到非常熟悉的结构。它会创建一个 workqueue,注册一个块设备,并获得一个主设备号,然后注册一个驱动函数 virtio_blk。
当一个设备驱动作为一个内核模块被初始化的时候,probe 函数会被调用,因而我们来看一下 virtblk_probe。
static int virtblk_probe(struct virtio_device *vdev)
{
struct virtio_blk *vblk;
struct request_queue *q;
......
vdev->priv = vblk = kmalloc(sizeof(*vblk), GFP_KERNEL);
vblk->vdev = vdev;
vblk->sg_elems = sg_elems;
INIT_WORK(&vblk->config_work, virtblk_config_changed_work);
......
err = init_vq(vblk);
......
vblk->disk = alloc_disk(1 << PART_BITS);
memset(&vblk->tag_set, 0, sizeof(vblk->tag_set));
vblk->tag_set.ops = &virtio_mq_ops;
vblk->tag_set.queue_depth = virtblk_queue_depth;
vblk->tag_set.numa_node = NUMA_NO_NODE;
vblk->tag_set.flags = BLK_MQ_F_SHOULD_MERGE;
vblk->tag_set.cmd_size =
sizeof(struct virtblk_req) +
sizeof(struct scatterlist) * sg_elems;
vblk->tag_set.driver_data = vblk;
vblk->tag_set.nr_hw_queues = vblk->num_vqs;
err = blk_mq_alloc_tag_set(&vblk->tag_set);
......
q = blk_mq_init_queue(&vblk->tag_set);
vblk->disk->queue = q;
q->queuedata = vblk;
virtblk_name_format("vd", index, vblk->disk->disk_name, DISK_NAME_LEN);
vblk->disk->major = major;
vblk->disk->first_minor = index_to_minor(index);
vblk->disk->private_data = vblk;
vblk->disk->fops = &virtblk_fops;
vblk->disk->flags |= GENHD_FL_EXT_DEVT;
vblk->index = index;
......
device_add_disk(&vdev->dev, vblk->disk);
err = device_create_file(disk_to_dev(vblk->disk), &dev_attr_serial);
......
}
复制代码
在 virtblk_probe 中,我们首先看到的是 struct request_queue,这是每一个块设备都有的一个队列。还记得吗?它有两个函数,一个是 make_request_fn 函数,用于生成 request;另一个是 request_fn 函数,用于处理 request。
这个 request_queue 的初始化过程在 blk_mq_init_queue 中。它会调用 blk_mq_init_allocated_queue->blk_queue_make_request。在这里面,我们可以将 make_request_fn 函数设置为 blk_mq_make_request,也就是说,一旦上层有写入请求,我们就通过 blk_mq_make_request 这个函数,将请求放入 request_queue 队列中。
另外,在 virtblk_probe 中,我们会初始化一个 gendisk。前面我们也讲了,每一个块设备都有这样一个结构。
在 virtblk_probe 中,还有一件重要的事情就是,init_vq 会来初始化 virtqueue。
static int init_vq(struct virtio_blk *vblk)
{
int err;
int i;
vq_callback_t **callbacks;
const char **names;
struct virtqueue **vqs;
unsigned short num_vqs;
struct virtio_device *vdev = vblk->vdev;
......
vblk->vqs = kmalloc_array(num_vqs, sizeof(*vblk->vqs), GFP_KERNEL);
names = kmalloc_array(num_vqs, sizeof(*names), GFP_KERNEL);
callbacks = kmalloc_array(num_vqs, sizeof(*callbacks), GFP_KERNEL);
vqs = kmalloc_array(num_vqs, sizeof(*vqs), GFP_KERNEL);
......
for (i = 0; i < num_vqs; i++) {
callbacks[i] = virtblk_done;
names[i] = vblk->vqs[i].name;
}
/* Discover virtqueues and write information to configuration. */
err = virtio_find_vqs(vdev, num_vqs, vqs, callbacks, names, &desc);
for (i = 0; i < num_vqs; i++) {
vblk->vqs[i].vq = vqs[i];
}
vblk->num_vqs = num_vqs;
......
}
复制代码
按照上面的原理来说,virtqueue 是一个介于客户机前端和 qemu 后端的一个结构,用于在这两端之间传递数据。这里建立的 struct virtqueue 是客户机前端对于队列的管理的数据结构,在客户机的 linux 内核中通过 kmalloc_array 进行分配。
而队列的实体需要通过函数 virtio_find_vqs 查找或者生成,所以这里我们还把 callback 函数指定为 virtblk_done。当 buffer 使用发生变化的时候,我们需要调用这个 callback 函数进行通知。
static inline
int virtio_find_vqs(struct virtio_device *vdev, unsigned nvqs,
struct virtqueue *vqs[], vq_callback_t *callbacks[],
const char * const names[],
struct irq_affinity *desc)
{
return vdev->config->find_vqs(vdev, nvqs, vqs, callbacks, names, NULL, desc);
}
static const struct virtio_config_ops virtio_pci_config_ops = {
.get = vp_get,
.set = vp_set,
.generation = vp_generation,
.get_status = vp_get_status,
.set_status = vp_set_status,
.reset = vp_reset,
.find_vqs = vp_modern_find_vqs,
.del_vqs = vp_del_vqs,
.get_features = vp_get_features,
.finalize_features = vp_finalize_features,
.bus_name = vp_bus_name,
.set_vq_affinity = vp_set_vq_affinity,
.get_vq_affinity = vp_get_vq_affinity,
};
复制代码
根据 virtio_config_ops 的定义,virtio_find_vqs 会调用 vp_modern_find_vqs。
static int vp_modern_find_vqs(struct virtio_device *vdev, unsigned nvqs,
struct virtqueue *vqs[],
vq_callback_t *callbacks[],
const char * const names[], const bool *ctx,
struct irq_affinity *desc)
{
struct virtio_pci_device *vp_dev = to_vp_device(vdev);
struct virtqueue *vq;
int rc = vp_find_vqs(vdev, nvqs, vqs, callbacks, names, ctx, desc);
/* Select and activate all queues. Has to be done last: once we do
* this, there's no way to go back except reset.
*/
list_for_each_entry(vq, &vdev->vqs, list) {
vp_iowrite16(vq->index, &vp_dev->common->queue_select);
vp_iowrite16(1, &vp_dev->common->queue_enable);
}
return 0;
}
复制代码
在 vp_modern_find_vqs 中,vp_find_vqs 会调用 vp_find_vqs_intx。
static int vp_find_vqs_intx(struct virtio_device *vdev, unsigned nvqs,
struct virtqueue *vqs[], vq_callback_t *callbacks[],
const char * const names[], const bool *ctx)
{
struct virtio_pci_device *vp_dev = to_vp_device(vdev);
int i, err;
vp_dev->vqs = kcalloc(nvqs, sizeof(*vp_dev->vqs), GFP_KERNEL);
err = request_irq(vp_dev->pci_dev->irq, vp_interrupt, IRQF_SHARED,
dev_name(&vdev->dev), vp_dev);
vp_dev->intx_enabled = 1;
vp_dev->per_vq_vectors = false;
for (i = 0; i < nvqs; ++i) {
vqs[i] = vp_setup_vq(vdev, i, callbacks[i], names[i],
ctx ? ctx[i] : false,
VIRTIO_MSI_NO_VECTOR);
......
}
}
复制代码
在 vp_find_vqs_intx 中,我们通过 request_irq 注册一个中断处理函数 vp_interrupt,当设备的配置信息发生改变,会产生一个中断,当设备向队列中写入信息时,也会会产生一个中断,我们称为 vq 中断,中断处理函数需要调用相应的队列的回调函数。
然后,我们根据队列的数目,依次调用 vp_setup_vq,完成 virtqueue、vring 的分配和初始化。
static struct virtqueue *vp_setup_vq(struct virtio_device *vdev, unsigned index,
void (*callback)(struct virtqueue *vq),
const char *name,
bool ctx,
u16 msix_vec)
{
struct virtio_pci_device *vp_dev = to_vp_device(vdev);
struct virtio_pci_vq_info *info = kmalloc(sizeof *info, GFP_KERNEL);
struct virtqueue *vq;
unsigned long flags;
......
vq = vp_dev->setup_vq(vp_dev, info, index, callback, name, ctx,
msix_vec);
info->vq = vq;
if (callback) {
spin_lock_irqsave(&vp_dev->lock, flags);
list_add(&info->node, &vp_dev->virtqueues);
spin_unlock_irqrestore(&vp_dev->lock, flags);
} else {
INIT_LIST_HEAD(&info->node);
}
vp_dev->vqs[index] = info;
return vq;
}
static struct virtqueue *setup_vq(struct virtio_pci_device *vp_dev,
struct virtio_pci_vq_info *info,
unsigned index,
void (*callback)(struct virtqueue *vq),
const char *name,
bool ctx,
u16 msix_vec)
{
struct virtio_pci_common_cfg __iomem *cfg = vp_dev->common;
struct virtqueue *vq;
u16 num, off;
int err;
/* Select the queue we're interested in */
vp_iowrite16(index, &cfg->queue_select);
/* Check if queue is either not available or already active. */
num = vp_ioread16(&cfg->queue_size);
/* get offset of notification word for this vq */
off = vp_ioread16(&cfg->queue_notify_off);
info->msix_vector = msix_vec;
/* create the vring */
vq = vring_create_virtqueue(index, num,
SMP_CACHE_BYTES, &vp_dev->vdev,
true, true, ctx,
vp_notify, callback, name);
/* activate the queue */
vp_iowrite16(virtqueue_get_vring_size(vq), &cfg->queue_size);
vp_iowrite64_twopart(virtqueue_get_desc_addr(vq),
&cfg->queue_desc_lo, &cfg->queue_desc_hi);
vp_iowrite64_twopart(virtqueue_get_avail_addr(vq),
&cfg->queue_avail_lo, &cfg->queue_avail_hi);
vp_iowrite64_twopart(virtqueue_get_used_addr(vq),
&cfg->queue_used_lo, &cfg->queue_used_hi);
......
return vq;
}
struct virtqueue *vring_create_virtqueue(
unsigned int index,
unsigned int num,
unsigned int vring_align,
struct virtio_device *vdev,
bool weak_barriers,
bool may_reduce_num,
bool context,
bool (*notify)(struct virtqueue *),
void (*callback)(struct virtqueue *),
const char *name)
{
struct virtqueue *vq;
void *queue = NULL;
dma_addr_t dma_addr;
size_t queue_size_in_bytes;
struct vring vring;
/* TODO: allocate each queue chunk individually */
for (; num && vring_size(num, vring_align) > PAGE_SIZE; num /= 2) {
queue = vring_alloc_queue(vdev, vring_size(num, vring_align),
&dma_addr,
GFP_KERNEL|__GFP_NOWARN|__GFP_ZERO);
if (queue)
break;
}
if (!queue) {
/* Try to get a single page. You are my only hope! */
queue = vring_alloc_queue(vdev, vring_size(num, vring_align),
&dma_addr, GFP_KERNEL|__GFP_ZERO);
}
queue_size_in_bytes = vring_size(num, vring_align);
vring_init(&vring, num, queue, vring_align);
vq = __vring_new_virtqueue(index, vring, vdev, weak_barriers, context, notify, callback, name);
to_vvq(vq)->queue_dma_addr = dma_addr;
to_vvq(vq)->queue_size_in_bytes = queue_size_in_bytes;
to_vvq(vq)->we_own_ring = true;
return vq;
}
复制代码
在 vring_create_virtqueue 中,我们会调用 vring_alloc_queue,来创建队列所需要的内存空间,然后调用 vring_init 初始化结构 struct vring,来管理队列的内存空间,调用 __vring_new_virtqueue,来创建 struct vring_virtqueue。
这个结构的一开始,是 struct virtqueue,它也是 struct virtqueue 的一个扩展,紧接着后面就是 struct vring。
struct vring_virtqueue {
struct virtqueue vq;
/* Actual memory layout for this queue */
struct vring vring;
......
}
复制代码
至此我们发现,虚拟机里面的 virtio 的前端是这样的结构:struct virtio_device 里面有一个 struct vring_virtqueue,在 struct vring_virtqueue 里面有一个 struct vring。
中间 virtio 队列的管理
还记不记得我们上面讲 qemu 初始化的时候,virtio 的后端有数据结构 VirtIODevice,VirtQueue 和 vring 一模一样,前端和后端对应起来,都应该指向刚才创建的那一段内存。
现在的问题是,我们刚才分配的内存在客户机的内核里面,如何告知 qemu 来访问这段内存呢?
别忘了,qemu 模拟出来的 virtio block device 只是一个 PCI 设备。对于客户机来讲,这是一个外部设备,我们可以通过给外部设备发送指令的方式告知外部设备,这就是代码中 vp_iowrite16 的作用。它会调用专门给外部设备发送指令的函数 iowrite,告诉外部的 PCI 设备。
告知的有三个地址 virtqueue_get_desc_addr、virtqueue_get_avail_addr,virtqueue_get_used_addr。从客户机角度来看,这里面的地址都是物理地址,也即 GPA(Guest Physical Address)。因为只有物理地址才是客户机和 qemu 程序都认可的地址,本来客户机的物理内存也是 qemu 模拟出来的。
在 qemu 中,对 PCI 总线添加一个设备的时候,我们会调用 virtio_pci_device_plugged。
static void virtio_pci_device_plugged(DeviceState *d, Error **errp)
{
VirtIOPCIProxy *proxy = VIRTIO_PCI(d);
......
memory_region_init_io(&proxy->bar, OBJECT(proxy),
&virtio_pci_config_ops,
proxy, "virtio-pci", size);
......
}
static const MemoryRegionOps virtio_pci_config_ops = {
.read = virtio_pci_config_read,
.write = virtio_pci_config_write,
.impl = {
.min_access_size = 1,
.max_access_size = 4,
},
.endianness = DEVICE_LITTLE_ENDIAN,
};
复制代码
在这里面,对于这个加载的设备进行 I/O 操作,会映射到读写某一块内存空间,对应的操作为 virtio_pci_config_ops,也即写入这块内存空间,这就相当于对于这个 PCI 设备进行某种配置。
对 PCI 设备进行配置的时候,会有这样的调用链:virtio_pci_config_write->virtio_ioport_write->virtio_queue_set_addr。设置 virtio 的 queue 的地址是一项很重要的操作。
void virtio_queue_set_addr(VirtIODevice *vdev, int n, hwaddr addr)
{
vdev->vq[n].vring.desc = addr;
virtio_queue_update_rings(vdev, n);
}
复制代码
从这里我们可以看出,qemu 后端的 VirtIODevice 的 VirtQueue 的 vring 的地址,被设置成了刚才给队列分配的内存的 GPA。
接着,我们来看一下这个队列的格式。
/* Virtio ring descriptors: 16 bytes. These can chain together via "next". */
struct vring_desc {
/* Address (guest-physical). */
__virtio64 addr;
/* Length. */
__virtio32 len;
/* The flags as indicated above. */
__virtio16 flags;
/* We chain unused descriptors via this, too */
__virtio16 next;
};
struct vring_avail {
__virtio16 flags;
__virtio16 idx;
__virtio16 ring[];
};
/* u32 is used here for ids for padding reasons. */
struct vring_used_elem {
/* Index of start of used descriptor chain. */
__virtio32 id;
/* Total length of the descriptor chain which was used (written to) */
__virtio32 len;
};
struct vring_used {
__virtio16 flags;
__virtio16 idx;
struct vring_used_elem ring[];
};
struct vring {
unsigned int num;
struct vring_desc *desc;
struct vring_avail *avail;
struct vring_used *used;
};
复制代码
vring 包含三个成员:
- vring_desc 指向分配的内存块,用于存放客户机和 qemu 之间传输的数据。
- avail->ring[] 是发送端维护的环形队列,指向需要接收端处理的 vring_desc。
used->ring[] 是接收端维护的环形队列,指向自己已经处理过了的 vring_desc。
数据写入的流程
接下来,我们来看,真的写入一个数据的时候,会发生什么。
按照上面 virtio 驱动初始化的时候的逻辑,blk_mq_make_request 会被调用。这个函数比较复杂,会分成多个分支,但是最终都会调用到 request_queue 的 virtio_mq_ops 的 queue_rq 函数。struct request_queue *q = rq->q; q->mq_ops->queue_rq(hctx, &bd); static const struct blk_mq_ops virtio_mq_ops = { .queue_rq = virtio_queue_rq, .complete = virtblk_request_done, .init_request = virtblk_init_request, .map_queues = virtblk_map_queues, }; 复制代码根据 virtio_mq_ops 的定义,我们现在要调用 virtio_queue_rq。
static blk_status_t virtio_queue_rq(struct blk_mq_hw_ctx *hctx, const struct blk_mq_queue_data *bd) { struct virtio_blk *vblk = hctx->queue->queuedata; struct request *req = bd->rq; struct virtblk_req *vbr = blk_mq_rq_to_pdu(req); ...... err = virtblk_add_req(vblk->vqs[qid].vq, vbr, vbr->sg, num); ...... if (notify) virtqueue_notify(vblk->vqs[qid].vq); return BLK_STS_OK; } 复制代码在 virtio_queue_rq 中,我们会将请求写入的数据,通过 virtblk_add_req 放入 struct virtqueue。
因此,接下来的调用链为:virtblk_add_req->virtqueue_add_sgs->virtqueue_add。static inline int virtqueue_add(struct virtqueue *_vq, struct scatterlist *sgs[], unsigned int total_sg, unsigned int out_sgs, unsigned int in_sgs, void *data, void *ctx, gfp_t gfp) { struct vring_virtqueue *vq = to_vvq(_vq); struct scatterlist *sg; struct vring_desc *desc; unsigned int i, n, avail, descs_used, uninitialized_var(prev), err_idx; int head; bool indirect; ...... head = vq->free_head; indirect = false; desc = vq->vring.desc; i = head; descs_used = total_sg; for (n = 0; n < out_sgs; n++) { for (sg = sgs[n]; sg; sg = sg_next(sg)) { dma_addr_t addr = vring_map_one_sg(vq, sg, DMA_TO_DEVICE); ...... desc[i].flags = cpu_to_virtio16(_vq->vdev, VRING_DESC_F_NEXT); desc[i].addr = cpu_to_virtio64(_vq->vdev, addr); desc[i].len = cpu_to_virtio32(_vq->vdev, sg->length); prev = i; i = virtio16_to_cpu(_vq->vdev, desc[i].next); } } /* Last one doesn't continue. */ desc[prev].flags &= cpu_to_virtio16(_vq->vdev, ~VRING_DESC_F_NEXT); /* We're using some buffers from the free list. */ vq->vq.num_free -= descs_used; /* Update free pointer */ vq->free_head = i; /* Store token and indirect buffer state. */ vq->desc_state[head].data = data; /* Put entry in available array (but don't update avail->idx until they do sync). */ avail = vq->avail_idx_shadow & (vq->vring.num - 1); vq->vring.avail->ring[avail] = cpu_to_virtio16(_vq->vdev, head); /* Descriptors and available array need to be set before we expose the new available array entries. */ virtio_wmb(vq->weak_barriers); vq->avail_idx_shadow++; vq->vring.avail->idx = cpu_to_virtio16(_vq->vdev, vq->avail_idx_shadow); vq->num_added++; ...... return 0; } 复制代码在 virtqueue_add 函数中,我们能看到,free_head 指向的整个内存块空闲链表的起始位置,用 head 变量记住这个起始位置。
接下来,i 也指向这个起始位置,然后是一个 for 循环,将数据放到内存块里面,放的过程中,next 不断指向下一个空闲位置,这样空闲的内存块被不断的占用。等所有的写入都结束了,i 就会指向这次存放的内存块的下一个空闲位置,然后 free_head 就指向 i,因为前面的都填满了。
至此,从 head 到 i 之间的内存块,就是这次写入的全部数据。
于是,在 vring 的 avail 变量中,在 ring[] 数组中分配新的一项,在 avail 的位置,avail 的计算是 avail_idx_shadow & (vq->vring.num - 1),其中,avail_idx_shadow 是上一次的 avail 的位置。这里如果超过了 ring[] 数组的下标,则重新跳到起始位置,就说明是一个环。这次分配的新的 avail 的位置就存放新写入的从 head 到 i 之间的内存块。然后是 avail_idx_shadow++,这说明这一块内存可以被接收方读取了。
接下来,我们回到 virtio_queue_rq,调用 virtqueue_notify 通知接收方。而 virtqueue_notify 会调用 vp_notify。bool vp_notify(struct virtqueue *vq) { /* we write the queue's selector into the notification register to * signal the other end */ iowrite16(vq->index, (void __iomem *)vq->priv); return true; } 复制代码然后,我们写入一个 I/O 会触发 VM exit。我们在解析 CPU 的时候看到过这个逻辑。
int kvm_cpu_exec(CPUState *cpu) { struct kvm_run *run = cpu->kvm_run; int ret, run_ret; ...... run_ret = kvm_vcpu_ioctl(cpu, KVM_RUN, 0); ...... switch (run->exit_reason) { case KVM_EXIT_IO: DPRINTF("handle_io\n"); /* Called outside BQL */ kvm_handle_io(run->io.port, attrs, (uint8_t *)run + run->io.data_offset, run->io.direction, run->io.size, run->io.count); ret = 0; break; } ...... } 复制代码这次写入的也是一个 I/O 的内存空间,同样会触发 virtio_ioport_write,这次会调用 virtio_queue_notify。
void virtio_queue_notify(VirtIODevice *vdev, int n) { VirtQueue *vq = &vdev->vq[n]; ...... if (vq->handle_aio_output) { event_notifier_set(&vq->host_notifier); } else if (vq->handle_output) { vq->handle_output(vdev, vq); } } 复制代码virtio_queue_notify 会调用 VirtQueue 的 handle_output 函数,前面我们已经设置过这个函数了,是 virtio_blk_handle_output。
接下来的调用链为:virtio_blk_handle_output->virtio_blk_handle_output_do->virtio_blk_handle_vq。bool virtio_blk_handle_vq(VirtIOBlock *s, VirtQueue *vq) { VirtIOBlockReq *req; MultiReqBuffer mrb = {}; bool progress = false; ...... do { virtio_queue_set_notification(vq, 0); while ((req = virtio_blk_get_request(s, vq))) { progress = true; if (virtio_blk_handle_request(req, &mrb)) { virtqueue_detach_element(req->vq, &req->elem, 0); virtio_blk_free_request(req); break; } } virtio_queue_set_notification(vq, 1); } while (!virtio_queue_empty(vq)); if (mrb.num_reqs) { virtio_blk_submit_multireq(s->blk, &mrb); } ...... return progress; } 复制代码在 virtio_blk_handle_vq 中,有一个 while 循环,在循环中调用函数 virtio_blk_get_request 从 vq 中取出请求,然后调用 virtio_blk_handle_request 处理从 vq 中取出的请求。
我们先来看 virtio_blk_get_request。static VirtIOBlockReq *virtio_blk_get_request(VirtIOBlock *s, VirtQueue *vq) { VirtIOBlockReq *req = virtqueue_pop(vq, sizeof(VirtIOBlockReq)); if (req) { virtio_blk_init_request(s, vq, req); } return req; } void *virtqueue_pop(VirtQueue *vq, size_t sz) { unsigned int i, head, max; VRingMemoryRegionCaches *caches; MemoryRegionCache *desc_cache; int64_t len; VirtIODevice *vdev = vq->vdev; VirtQueueElement *elem = NULL; unsigned out_num, in_num, elem_entries; hwaddr addr[VIRTQUEUE_MAX_SIZE]; struct iovec iov[VIRTQUEUE_MAX_SIZE]; VRingDesc desc; int rc; ...... /* When we start there are none of either input nor output. */ out_num = in_num = elem_entries = 0; max = vq->vring.num; i = head; caches = vring_get_region_caches(vq); desc_cache = &caches->desc; vring_desc_read(vdev, &desc, desc_cache, i); ...... /* Collect all the descriptors */ do { bool map_ok; if (desc.flags & VRING_DESC_F_WRITE) { map_ok = virtqueue_map_desc(vdev, &in_num, addr + out_num, iov + out_num, VIRTQUEUE_MAX_SIZE - out_num, true, desc.addr, desc.len); } else { map_ok = virtqueue_map_desc(vdev, &out_num, addr, iov, VIRTQUEUE_MAX_SIZE, false, desc.addr, desc.len); } ...... rc = virtqueue_read_next_desc(vdev, &desc, desc_cache, max, &i); } while (rc == VIRTQUEUE_READ_DESC_MORE); ...... /* Now copy what we have collected and mapped */ elem = virtqueue_alloc_element(sz, out_num, in_num); elem->index = head; for (i = 0; i < out_num; i++) { elem->out_addr[i] = addr[i]; elem->out_sg[i] = iov[i]; } for (i = 0; i < in_num; i++) { elem->in_addr[i] = addr[out_num + i]; elem->in_sg[i] = iov[out_num + i]; } vq->inuse++; ...... return elem; } 复制代码我们可以看到,virtio_blk_get_request 会调用 virtqueue_pop。在这里面,我们能看到对于 vring 的操作,也即从这里面将客户机里面写入的数据读取出来,放到 VirtIOBlockReq 结构中。
接下来,我们就要调用 virtio_blk_handle_request 处理这些数据。所以接下来的调用链为:virtio_blk_handle_request->virtio_blk_submit_multireq->submit_requests。static inline void submit_requests(BlockBackend *blk, MultiReqBuffer *mrb,int start, int num_reqs, int niov) { QEMUIOVector *qiov = &mrb->reqs[start]->qiov; int64_t sector_num = mrb->reqs[start]->sector_num; bool is_write = mrb->is_write; if (num_reqs > 1) { int i; struct iovec *tmp_iov = qiov->iov; int tmp_niov = qiov->niov; qemu_iovec_init(qiov, niov); for (i = 0; i < tmp_niov; i++) { qemu_iovec_add(qiov, tmp_iov[i].iov_base, tmp_iov[i].iov_len); } for (i = start + 1; i < start + num_reqs; i++) { qemu_iovec_concat(qiov, &mrb->reqs[i]->qiov, 0, mrb->reqs[i]->qiov.size); mrb->reqs[i - 1]->mr_next = mrb->reqs[i]; } block_acct_merge_done(blk_get_stats(blk), is_write ? BLOCK_ACCT_WRITE : BLOCK_ACCT_READ, num_reqs - 1); } if (is_write) { blk_aio_pwritev(blk, sector_num << BDRV_SECTOR_BITS, qiov, 0, virtio_blk_rw_complete, mrb->reqs[start]); } else { blk_aio_preadv(blk, sector_num << BDRV_SECTOR_BITS, qiov, 0, virtio_blk_rw_complete, mrb->reqs[start]); } } 复制代码在 submit_requests 中,我们看到了 BlockBackend。这是在 qemu 启动的时候,打开 qcow2 文件的时候生成的,现在我们可以用它来写入文件了,调用的是 blk_aio_pwritev。
BlockAIOCB *blk_aio_pwritev(BlockBackend *blk, int64_t offset, QEMUIOVector *qiov, BdrvRequestFlags flags, BlockCompletionFunc *cb, void *opaque) { return blk_aio_prwv(blk, offset, qiov->size, qiov, blk_aio_write_entry, flags, cb, opaque); } static BlockAIOCB *blk_aio_prwv(BlockBackend *blk, int64_t offset, int bytes, void *iobuf, CoroutineEntry co_entry, BdrvRequestFlags flags, BlockCompletionFunc *cb, void *opaque) { BlkAioEmAIOCB *acb; Coroutine *co; acb = blk_aio_get(&blk_aio_em_aiocb_info, blk, cb, opaque); acb->rwco = (BlkRwCo) { .blk = blk, .offset = offset, .iobuf = iobuf, .flags = flags, .ret = NOT_DONE, }; acb->bytes = bytes; acb->has_returned = false; co = qemu_coroutine_create(co_entry, acb); bdrv_coroutine_enter(blk_bs(blk), co); acb->has_returned = true; return &acb->common; } 复制代码在 blk_aio_pwritev 中,我们看到,又是创建了一个协程来进行写入。写入完毕之后调用 virtio_blk_rw_complete->virtio_blk_req_complete。
static void virtio_blk_req_complete(VirtIOBlockReq *req, unsigned char status) { VirtIOBlock *s = req->dev; VirtIODevice *vdev = VIRTIO_DEVICE(s); trace_virtio_blk_req_complete(vdev, req, status); stb_p(&req->in->status, status); virtqueue_push(req->vq, &req->elem, req->in_len); virtio_notify(vdev, req->vq); } 复制代码在 virtio_blk_req_complete 中,我们先是调用 virtqueue_push,更新 vring 中 used 变量,表示这部分已经写入完毕,空间可以回收利用了。但是,这部分的改变仅仅改变了 qemu 后端的 vring,我们还需要通知客户机中 virtio 前端的 vring 的值,因而要调用 virtio_notify。virtio_notify 会调用 virtio_irq 发送一个中断。
还记得咱们前面注册过一个中断处理函数 vp_interrupt 吗?它就是干这个事情的。static irqreturn_t vp_interrupt(int irq, void *opaque) { struct virtio_pci_device *vp_dev = opaque; u8 isr; /* reading the ISR has the effect of also clearing it so it's very * important to save off the value. */ isr = ioread8(vp_dev->isr); /* Configuration change? Tell driver if it wants to know. */ if (isr & VIRTIO_PCI_ISR_CONFIG) vp_config_changed(irq, opaque); return vp_vring_interrupt(irq, opaque); } 复制代码就像前面说的一样 vp_interrupt 这个中断处理函数,一是处理配置变化,二是处理 I/O 结束。第二种的调用链为:vp_interrupt->vp_vring_interrupt->vring_interrupt。
irqreturn_t vring_interrupt(int irq, void *_vq) { struct vring_virtqueue *vq = to_vvq(_vq); ...... if (vq->vq.callback) vq->vq.callback(&vq->vq); return IRQ_HANDLED; } 复制代码在 vring_interrupt 中,我们会调用 callback 函数,这个也是在前面注册过的,是 virtblk_done。
接下来的调用链为:virtblk_done->virtqueue_get_buf->virtqueue_get_buf_ctx。void *virtqueue_get_buf_ctx(struct virtqueue *_vq, unsigned int *len, void **ctx) { struct vring_virtqueue *vq = to_vvq(_vq); void *ret; unsigned int i; u16 last_used; ...... last_used = (vq->last_used_idx & (vq->vring.num - 1)); i = virtio32_to_cpu(_vq->vdev, vq->vring.used->ring[last_used].id); *len = virtio32_to_cpu(_vq->vdev, vq->vring.used->ring[last_used].len); ...... /* detach_buf clears data, so grab it now. */ ret = vq->desc_state[i].data; detach_buf(vq, i, ctx); vq->last_used_idx++; ...... return ret; } 复制代码在 virtqueue_get_buf_ctx 中,我们可以看到,virtio 前端的 vring 中的 last_used_idx 加一,说明这块数据 qemu 后端已经消费完毕。我们可以通过 detach_buf 将其放入空闲队列中,留给以后的写入请求使用。
至此,整个存储虚拟化的写入流程才全部完成。总结时刻
下面我们来总结一下存储虚拟化的场景下,整个写入的过程。
在虚拟机里面,应用层调用 write 系统调用写入文件。
- write 系统调用进入虚拟机里面的内核,经过 VFS,通用块设备层,I/O 调度层,到达块设备驱动。
- 虚拟机里面的块设备驱动是 virtio_blk,它和通用的块设备驱动一样,有一个 request queue,另外有一个函数 make_request_fn 会被设置为 blk_mq_make_request,这个函数用于将请求放入队列。
- 虚拟机里面的块设备驱动是 virtio_blk 会注册一个中断处理函数 vp_interrupt。当 qemu 写入完成之后,它会通知虚拟机里面的块设备驱动。
- blk_mq_make_request 最终调用 virtqueue_add,将请求添加到传输队列 virtqueue 中,然后调用 virtqueue_notify 通知 qemu。
- 在 qemu 中,本来虚拟机正处于 KVM_RUN 的状态,也即处于客户机状态。
- qemu 收到通知后,通过 VM exit 指令退出客户机状态,进入宿主机状态,根据退出原因,得知有 I/O 需要处理。
- qemu 调用 virtio_blk_handle_output,最终调用 virtio_blk_handle_vq。
- virtio_blk_handle_vq 里面有一个循环,在循环中,virtio_blk_get_request 函数从传输队列中拿出请求,然后调用 virtio_blk_handle_request 处理请求。
- virtio_blk_handle_request 会调用 blk_aio_pwritev,通过 BlockBackend 驱动写入 qcow2 文件。
- 写入完毕之后,virtio_blk_req_complete 会调用 virtio_notify 通知虚拟机里面的驱动。数据写入完成,刚才注册的中断处理函数 vp_interrupt 会收到这个通知。
课堂练习

若有收获,就点个赞吧
0 人点赞
