总结:
要注意:
- 区分操作系统,这里是Linux是实现
- 区分用户态于内核态
线程有自己的 1、本地数据-线程栈,也就是独立的栈空间。2、进程内共享的全局数据。3、线程私有数据
一个进程内肯定会有一个主线程,可以有多个线程。对于内核而言,无论是进程,还是线程,到了内核里面,我们统一都叫任务(Task),由一个统一的结构 **task_struct** 进行管理。内核会有相应的链表把这些 **task_struct 串起来。**``**这也就是为什么线程是操作系统调度的最小粒度了。**
那么如何区分进程和线程呢?主要看 pid 和 tgid
- 任何一个进程,如果只有主线程,那 pid 是自己,tgid【也就是target id】 是自己,group_leader 指向的还是自己。那这就是一个进程了。
- 但是,如果一个进程创建了其他线程,那就会有所变化了。线程有自己的 pid,**tgid 就是进程的主线程的 pid**,group_leader 指向的就是进程的主线程。这时候他就是一个线程了
进程管理 task_struct 的的结构图: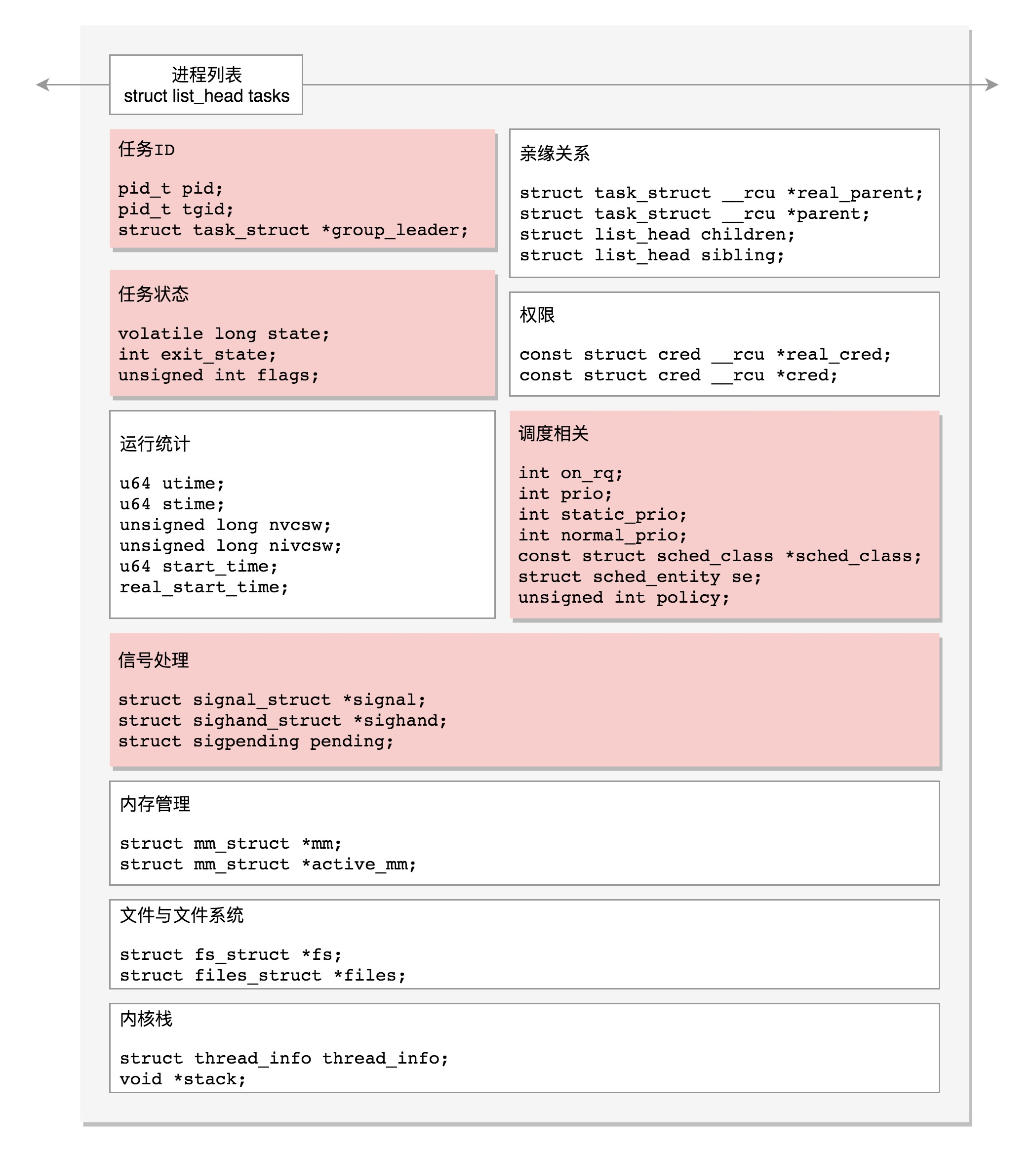
- 进程亲缘关系维护的数据结构,是一种很有参考价值的实现方式,在内核中会多个地方出现类似的结构;
- 进程权限中 setuid 的原理,这一点比较难理解,但是很重要,面试经常会考。
- 在用户态,应用程序进行了至少一次函数调用。32 位和 64 的传递参数的方式稍有不同,32 位的就是用函数栈,64 位的前 6 个参数用寄存器,其他的用函数栈。
- 在内核态,32 位和 64 位都使用内核栈,格式也稍有不同,主要集中在
**pt_regs**结构上。 - 在内核态,32 位和 64 位的内核栈和 task_struct 的关联关系不同。32 位主要靠 thread_info,64 位主要靠 Per-CPU 变量。
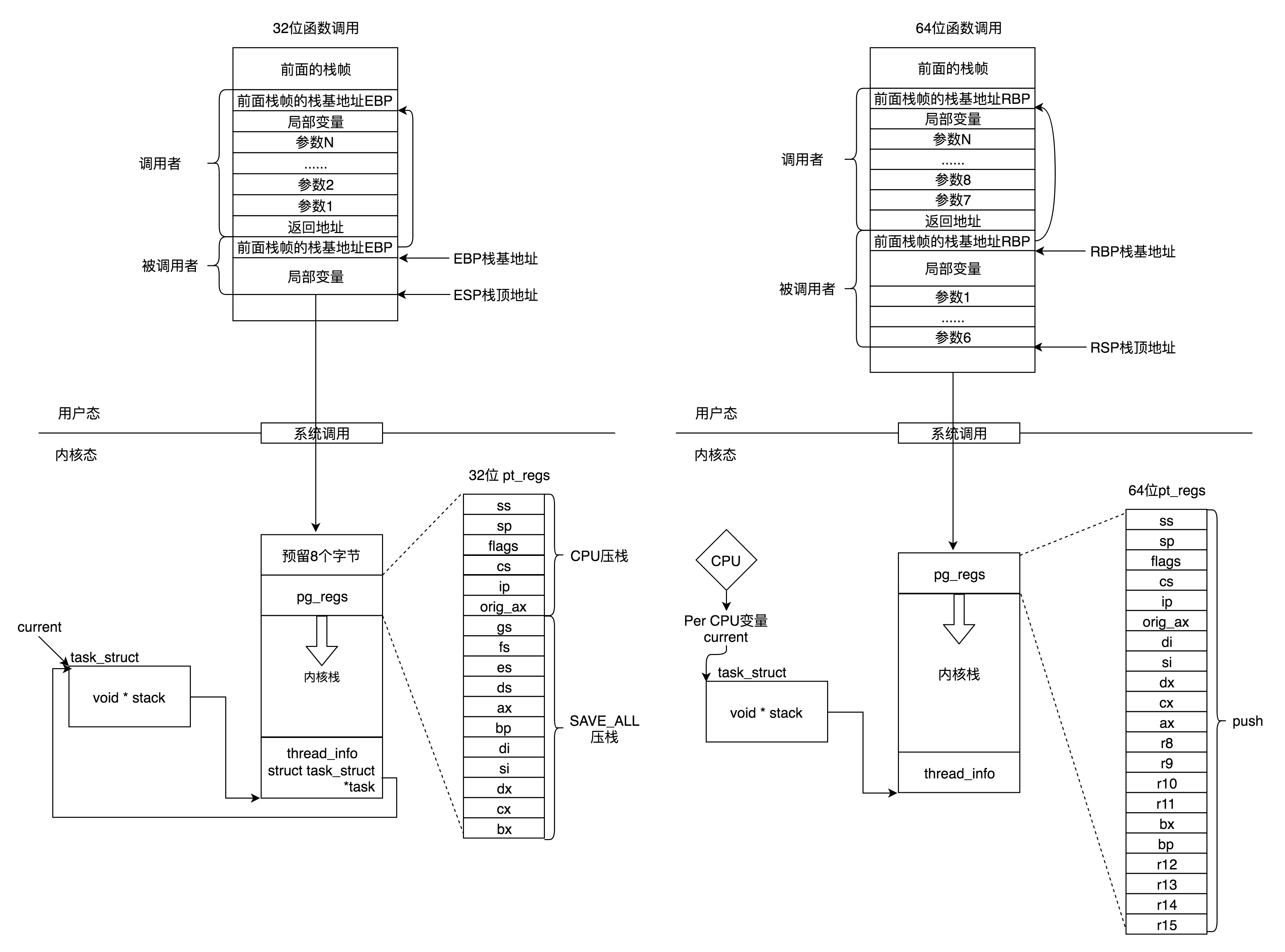
task_struct
Linux 里面,无论是进程,还是线程,到了内核里面,我们统一都叫任务(Task),由一个统一的结构task_struct进行管理。
Linux 内核也应该先弄一个链表,将所有的 task_struct 串起来。
struct list_head tasks;
任务 ID
pid_t pid; // process idpid_t tgid; // thread group ID!!!struct task_struct *group_leader;
上述数据结构的作用:
- 任务展示
- 给任务下发指令
任何一个进程,如果只有主线程**,那 pid 是自己,tgid【也就是target id】 是自己,group_leader 指向的还是自己。
但是,如果一个进程创建了其他线程,那就会有所变化了。线程有自己的 pid,tgid 就是进程的主线程的 pid,group_leader 指向的就是进程的主线程。
有了 tgid,我们就知道 tast_struct 代表的是一个进程还是代表一个线程: 【pid 是自己,tgid 是自己就可以理解做一个进程了】
信号处理
task_struct 里面关于信号处理的字段:
/* Signal handlers: */struct signal_struct *signal;struct sighand_struct *sighand;sigset_t blocked;sigset_t real_blocked;sigset_t saved_sigmask;struct sigpending pending;unsigned long sas_ss_sp;size_t sas_ss_size;unsigned int sas_ss_flags;
这里定义了哪些信号被阻塞暂不处理(blocked),哪些信号尚等待处理(pending),哪些信号正在通过信号处理函数进行处理(sighand)。处理的结果可以是忽略,可以是结束进程等等。
信号处理函数默认使用用户态的函数栈,当然也可以开辟新的栈专门用于信号处理,这就是 sas_ss_xxx 这三个变量的作用。
task_struct 里面有一个 struct sigpending pending。如果我们进入 struct signal_struct signal 去看的话,还有一个 struct sigpending shared_pending。*它们一个是本任务的,一个是线程组共享的。
任务状态
在 task_struct 里面,涉及任务状态的是下面这几个变量:
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */int exit_state;unsigned int flags;
state(状态)可以取的值定义在 include/linux/sched.h 头文件中。
/* Used in tsk->state: */#define TASK_RUNNING 0#define TASK_INTERRUPTIBLE 1#define TASK_UNINTERRUPTIBLE 2#define __TASK_STOPPED 4#define __TASK_TRACED 8/* Used in tsk->exit_state: */#define EXIT_DEAD 16#define EXIT_ZOMBIE 32#define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD)/* Used in tsk->state again: */#define TASK_DEAD 64#define TASK_WAKEKILL 128#define TASK_WAKING 256#define TASK_PARKED 512#define TASK_NOLOAD 1024#define TASK_NEW 2048#define TASK_STATE_MAX 4096
从定义的数值很容易看出来,flags 是通过 bitset 的方式设置的,也就是说,当前是什么状态,哪一位就置一。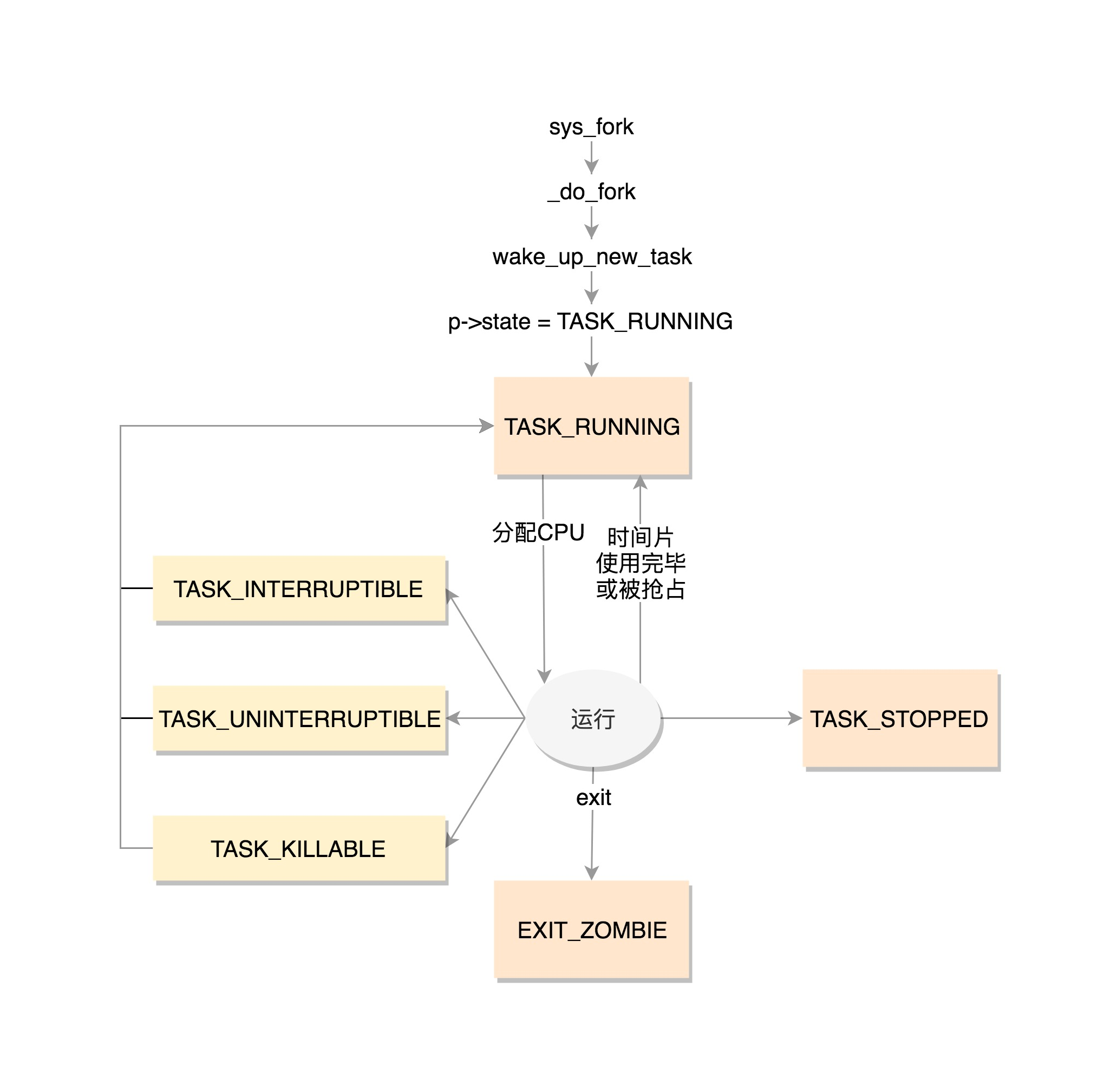
TASK_RUNNING 并不是说进程正在运行,而是表示进程在时刻准备运行的状态。当处于这个状态的进程获得时间片的时候,就是在运行中;如果没有获得时间片,就说明它被其他进程抢占了,在等待再次分配时间片。
**
在运行中的进程,一旦要进行一些 I/O 操作,需要等待 I/O 完毕,这个时候会释放 CPU,进入睡眠状态。
在 Linux 中,有两种睡眠状态。
一种是TASK_INTERRUPTIBLE,可中断的睡眠状态。这是一种浅睡眠的状态,也就是说,虽然在睡眠,等待 I/O 完成,但是这个时候一个信号来的时候,进程还是要被唤醒。只不过唤醒后,不是继续刚才的操作,而是进行信号处理。当然程序员可以根据自己的意愿,来写信号处理函数,例如收到某些信号,就放弃等待这个 I/O 操作完成,直接退出,也可也收到某些信息,继续等待。
另一种睡眠是TASK_UNINTERRUPTIBLE,不可中断的睡眠状态。这是一种深度睡眠状态,不可被信号唤醒,只能死等 I/O 操作完成。一旦 I/O 操作因为特殊原因不能完成,这个时候,谁也叫不醒这个进程了。 kill 它呢?别忘了,kill 本身也是一个信号,既然这个状态不可被信号唤醒,kill 信号也被忽略了。除非重启电脑,没有其他办法。因此,这是一个比较危险的事情,除非程序员极其有把握,不然还是不要设置成TASK_UNINTERRUPTIBLE。
于是,我们就有了一种新的进程睡眠状态,TASK_KILLABLE,可以终止的新睡眠状态。进程处于这种状态中,它的运行原理类似 TASK_UNINTERRUPTIBLE,只不过可以响应致命信号。
从定义可以看出,TASK_WAKEKILL 用于在接收到致命信号时唤醒进程,而 TASK_KILLABLE 相当于这两位都设置了。
#define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE)
TASK_STOPPED 是在进程接收到 SIGSTOP、SIGTTIN、SIGTSTP 或者 SIGTTOU 信号之后进入该状态。
TASK_TRACED 表示进程被 debugger 等进程监视,进程执行被调试程序所停止。当一个进程被另外的进程所监视,每一个信号都会让进程进入该状态。
一旦一个进程要结束,先进入的是 EXIT_ZOMBIE 状态,但是这个时候它的父进程还没有使用 wait() 等系统调用来获知它的终止信息,此时进程就成了僵尸进程。
EXIT_DEAD 是进程的最终状态。
EXIT_ZOMBIE 和 EXIT_DEAD 也可以用于 exit_state。
上面的进程状态和进程的运行、调度有关系,还有其他的一些状态,我们称为标志。放在 flags 字段中,这些字段都被定义称为宏,以 PF 开头。我这里举几个例子。
#define PF_EXITING 0x00000004#define PF_VCPU 0x00000010#define PF_FORKNOEXEC 0x00000040
PF_EXITING表示正在退出。当有这个 flag 的时候,在函数 find_alive_thread 中,找活着的线程,遇到有这个 flag 的,就直接跳过。
PF_VCPU表示进程运行在虚拟 CPU 上。在函数 account_system_time 中,统计进程的系统运行时间,如果有这个 flag,就调用 account_guest_time,按照客户机的时间进行统计。
PF_FORKNOEXEC表示 fork 完了,还没有 exec。在 _do_fork 函数里面调用 copy_process,这个时候把 flag 设置为 PF_FORKNOEXEC。当 exec 中调用了 load_elf_binary 的时候,又把这个 flag 去掉。
进程调度
进程的状态切换往往涉及调度,下面这些字段都是用于调度的。为了让你理解 task_struct 进程管理的全貌,我先在这里列一下,咱们后面会有单独的章节讲解,这里你只要大概看一下里面的注释就好了。
// 是否在运行队列上int on_rq;// 优先级int prio;int static_prio;int normal_prio;unsigned int rt_priority;// 调度器类const struct sched_class *sched_class;// 调度实体struct sched_entity se;struct sched_rt_entity rt;struct sched_dl_entity dl;// 调度策略unsigned int policy;// 可以使用哪些 CPUint nr_cpus_allowed;cpumask_t cpus_allowed;struct sched_info sched_info;
运行统计信息
进程在用户态和内核态消耗的时间、上下文切换的次数等等。
u64 utime;// 用户态消耗的 CPU 时间u64 stime;// 内核态消耗的 CPU 时间unsigned long nvcsw;// 自愿 (voluntary) 上下文切换计数unsigned long nivcsw;// 非自愿 (involuntary) 上下文切换计数u64 start_time;// 进程启动时间,不包含睡眠时间u64 real_start_time;// 进程启动时间,包含睡眠时间
进程亲缘关系
任何一个进程都有父进程。所以,整个进程其实就是一棵进程树。而拥有同一父进程的所有进程都具有兄弟关系。
struct task_struct __rcu *real_parent; /* real parent process */struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */struct list_head children; /* list of my children */struct list_head sibling; /* linkage in my parent's children list */
- parent 指向其父进程。当它终止时,必须向它的父进程发送信号。
- children 表示链表的头部。链表中的所有元素都是它的子进程。
- sibling 用于把当前进程插入到兄弟链表中。
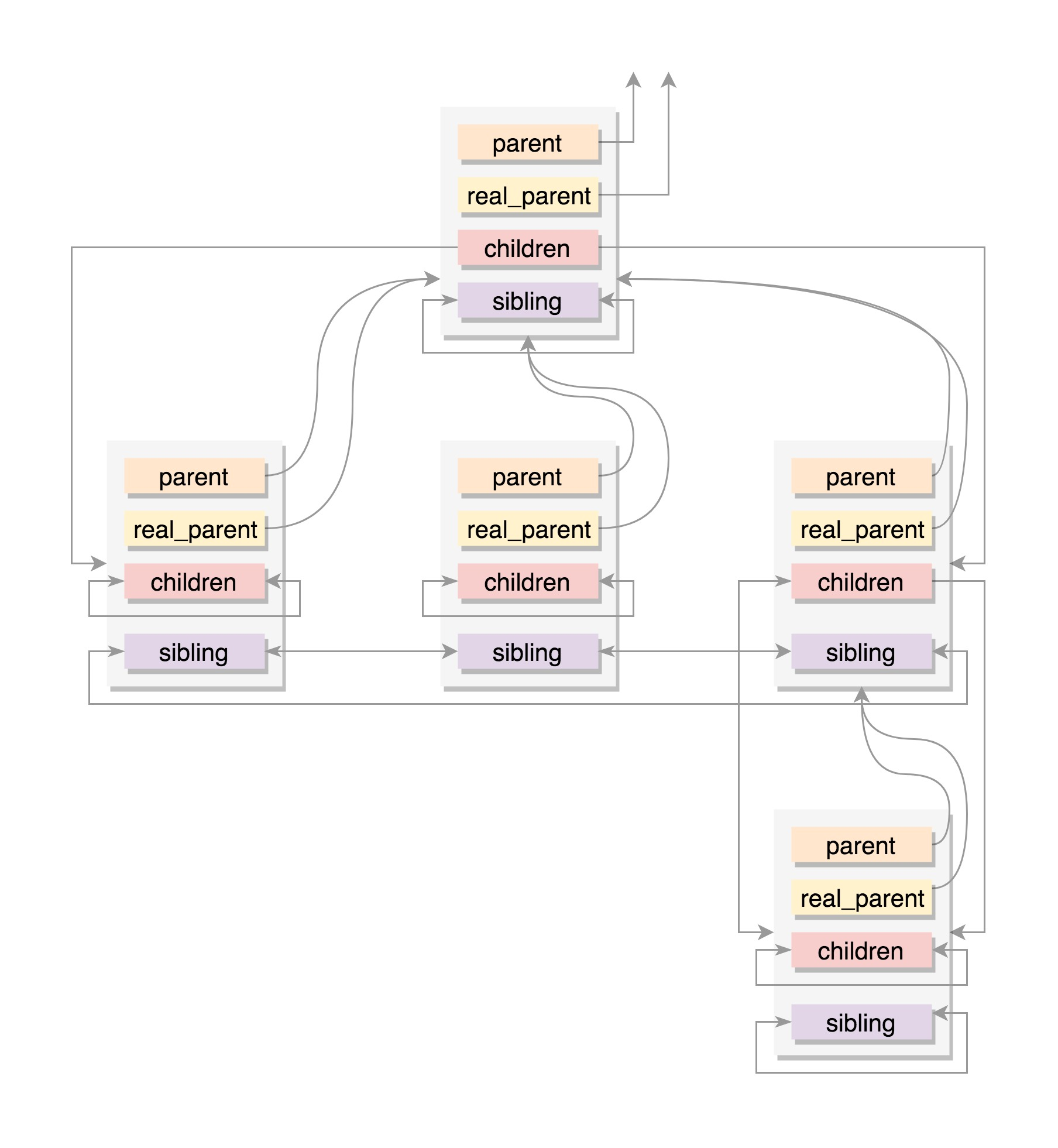
real_parent 和 parent 是一样的,但是也会有另外的情况存在。例如,bash 创建一个进程,那进程的 parent 和 real_parent 就都是 bash。如果在 bash 上使用 GDB 来 debug 一个进程,这个时候 GDB 是 real_parent,bash 是这个进程的 parent。
进程权限
在 Linux 里面,对于进程权限的定义如下:
/* Objective and real subjective task credentials (COW): */const struct cred __rcu *real_cred;/* Effective (overridable) subjective task credentials (COW): */const struct cred __rcu *cred;
“操作”,就是一个对象对另一个对象进行某些动作。当动作要实施的时候,就要审核权限,当两边的权限匹配上了,就可以实施操作。其中,real_cred 就是说明谁能操作我这个进程,而 cred 就是说明我这个进程能够操作谁。
这里 cred 的定义如下:
struct cred {......kuid_t uid; /* real UID of the task */kgid_t gid; /* real GID of the task */kuid_t suid; /* saved UID of the task */kgid_t sgid; /* saved GID of the task */kuid_t euid; /* effective UID of the task */kgid_t egid; /* effective GID of the task */kuid_t fsuid; /* UID for VFS ops */kgid_t fsgid; /* GID for VFS ops */......kernel_cap_t cap_inheritable; /* caps our children can inherit */kernel_cap_t cap_permitted; /* caps we're permitted */kernel_cap_t cap_effective; /* caps we can actually use */kernel_cap_t cap_bset; /* capability bounding set */kernel_cap_t cap_ambient; /* Ambient capability set */......} __randomize_layout;
从这里的定义可以看出,大部分是关于用户和用户所属的用户组信息。
第一个是 uid 和 gid,注释是 real user/group id。一般情况下,谁启动的进程,就是谁的 ID。但是权限审核的时候,往往不比较这两个,也就是说不大起作用。
第二个是 euid 和 egid,注释是 effective user/group id。一看这个名字,就知道这个是起“作用”的。当这个进程要操作消息队列、共享内存、信号量等对象的时候,其实就是在比较这个用户和组是否有权限。
第三个是 fsuid 和 fsgid,也就是filesystem user/group id。这个是对文件操作会审核的权限。
一般说来,fsuid、euid,和 uid 是一样的,fsgid、egid,和 gid 也是一样的。因为谁启动的进程,就应该审核启动的用户到底有没有这个权限。
我们可以通过`chmod u+s program 命令,给这个游戏程序设置set-user-ID的标识位,把游戏的权限变成rwsr-xr-x【原本是rwxr-xr-x】`。这个时候,用户 A 再启动这个游戏的时候,创建的进程 uid 当然还是用户 A,但是 euid 和 fsuid 就不是用户 A 了,因为看到了 set-user-id 标识,就改为文件的所有者的 ID,也就是说,euid 和 fsuid 都改成用户 B 了,这样就能够将通关结果保存下来。
在 Linux 里面,一个进程可以随时通过 setuid 设置用户 ID,所以,游戏程序的用户 B 的 ID 还会保存在一个地方,这就是 suid 和 sgid,也就是 saved uid 和 save gid。这样就可以很方便地使用 setuid,通过设置 uid 或者 suid 来改变权限。
除了以用户和用户组控制权限,Linux 还有另一个机制就是capabilities。
原来控制进程的权限,要么是高权限的 root 用户,要么是一般权限的普通用户,这时候的问题是,root 用户权限太大,而普通用户权限太小。有时候一个普通用户想做一点高权限的事情,必须给他整个 root 的权限。这个太不安全了。
于是,我们引入新的机制 capabilities,用位图表示权限,在capability.h 可以找到定义的权限。我这里列举几个。
#define CAP_CHOWN 0#define CAP_KILL 5#define CAP_NET_BIND_SERVICE 10#define CAP_NET_RAW 13#define CAP_SYS_MODULE 16#define CAP_SYS_RAWIO 17#define CAP_SYS_BOOT 22#define CAP_SYS_TIME 25#define CAP_AUDIT_READ 37#define CAP_LAST_CAP CAP_AUDIT_READ
对于普通用户运行的进程,当有这个权限的时候,就能做这些操作;没有的时候,就不能做,这样粒度要小很多。
cap_permitted 表示进程能够使用的权限。但是真正起作用的是 cap_effective。cap_permitted 中可以包含 cap_effective 中没有的权限。一个进程可以在必要的时候,放弃自己的某些权限,这样更加安全。假设自己因为代码漏洞被攻破了,但是如果啥也干不了,就没办法进一步突破。
cap_inheritable 表示当可执行文件的扩展属性设置了 inheritable 位时,调用 exec 执行该程序会继承调用者的 inheritable 集合,并将其加入到 permitted 集合。但在非 root 用户下执行 exec 时,通常不会保留 inheritable 集合,但是往往又是非 root 用户,才想保留权限,所以非常鸡肋。
cap_bset,也就是 capability bounding set,是系统中所有进程允许保留的权限。如果这个集合中不存在某个权限,那么系统中的所有进程都没有这个权限。即使以超级用户权限执行的进程,也是一样的。
这样有很多好处。例如,系统启动以后,将加载内核模块的权限去掉,那所有进程都不能加载内核模块。这样,即便这台机器被攻破,也做不了太多有害的事情。
cap_ambient 是比较新加入内核的,就是为了解决 cap_inheritable 鸡肋的状况,也就是,非 root 用户进程使用 exec 执行一个程序的时候,如何保留权限的问题。当执行 exec 的时候,cap_ambient 会被添加到 cap_permitted 中,同时设置到 cap_effective 中。
内存管理
每个进程都有自己独立的虚拟内存空间,这需要有一个数据结构来表示,就是 mm_struct。
struct mm_struct *mm;struct mm_struct *active_mm;
文件与文件系统
每个进程有一个文件系统的数据结构,还有一个打开文件的数据结构。
/* Filesystem information: */struct fs_struct *fs;/* Open file information: */struct files_struct *files;

若有收获,就点个赞吧
0 人点赞
