- 什么是 Prometheus 架构?">什么是 Prometheus 架构?
- 1)Prometheus Server">1)Prometheus Server
- 2)Time-Series Database (TSDB)">2)Time-Series Database (TSDB)
- 3)Prometheus Targets">3)Prometheus Targets
- 4)Prometheus Exporters">4)Prometheus Exporters
- 5)Prometheus Service Discovery">5)Prometheus Service Discovery
- 6)Prometheus Pushgateway">6)Prometheus Pushgateway
- 7)Prometheus Client Libraries">7)Prometheus Client Libraries
- 8)Prometheus Alertmanager">8)Prometheus Alertmanager
- 9)PromQL">9)PromQL
- 总结">总结
什么是 Prometheus 架构?
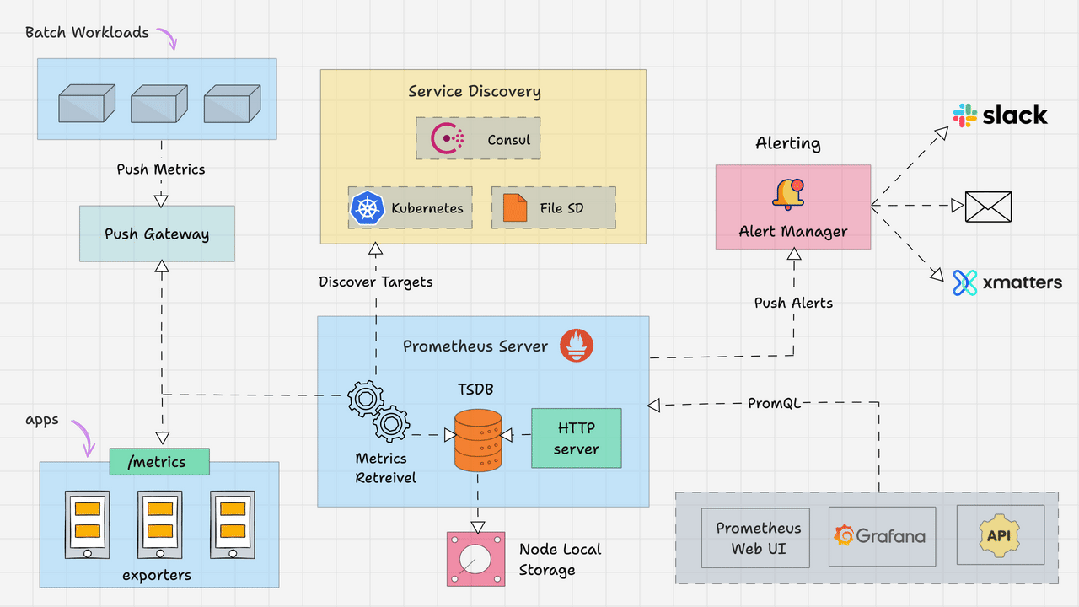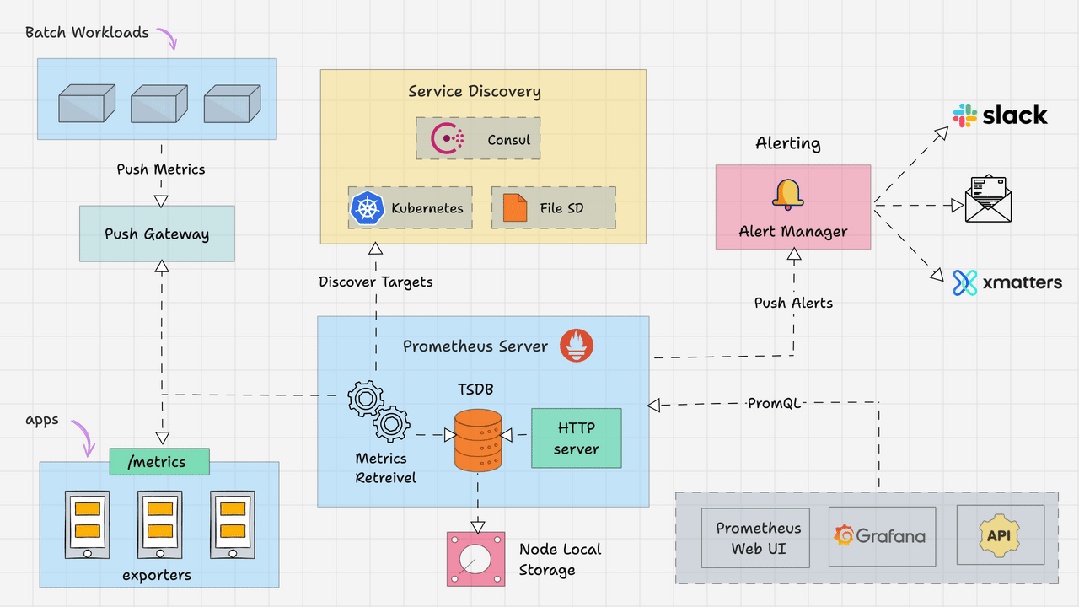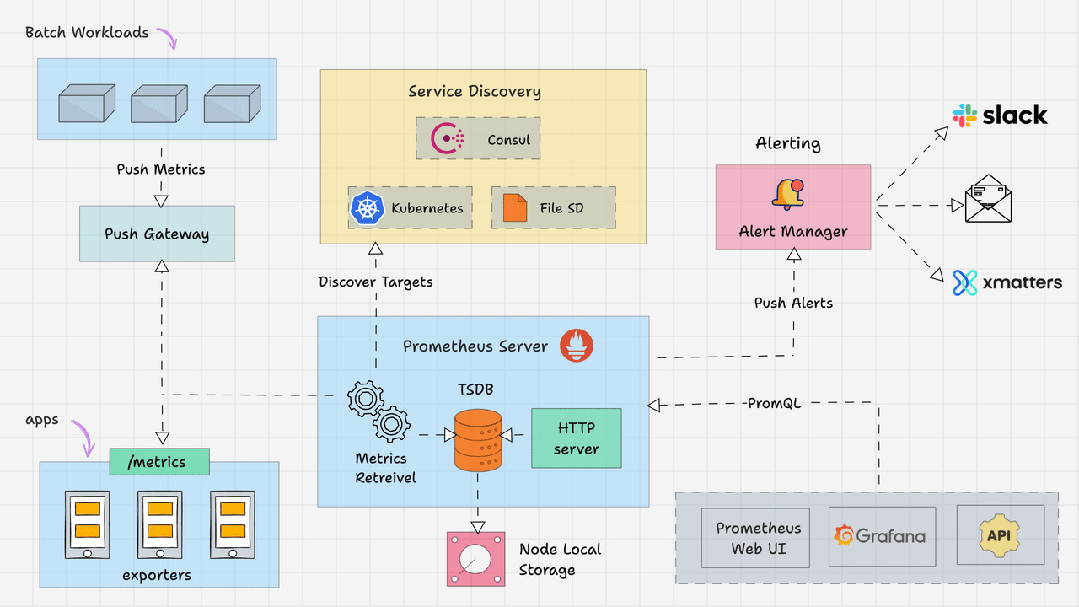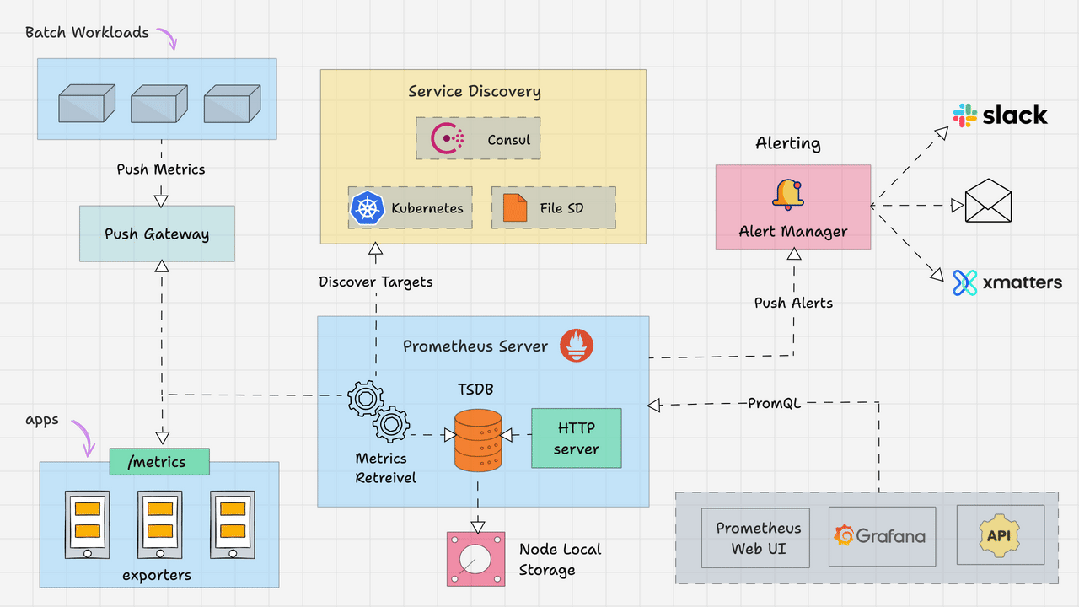
- Prometheus Server
- Service Discovery
- Time-Series Database(TSDB)
- Targets
- Exporters
- Push Gateway
- Alert Manager
- Client Libraries
- PromQL
1)Prometheus Server
Prometheus Server 是 Prometheus 监控系统的核心组件,负责收集、存储和提供时间序列数据。它通过 HTTP 协议周期性地从配置的目标(如服务器、服务和其他 Prometheus 兼容的系统)拉取指标数据,并将这些数据存储在本地的时间序列数据库中。
global:scrape_interval: 15sevaluation_interval: 15sscrape_timeout: 10srule_files:- 'rules/*.rules'scrape_configs:- job_name: 'prometheus'static_configs:- targets: ['localhost:9090']- job_name: 'node-exporter'static_configs:- targets: ['node-exporter:9100']alerting:alertmanagers:- static_configs:- targets: ['alertmanager:9093']
2)Time-Series Database (TSDB)
Prometheus 接收到的指标数据(如 CPU 使用率、内存占用、网络 I/O 等)随时间不断变化,这些数据被称为时间序列数据。因此,Prometheus 使用时间序列数据库(TSDB)来存储其所有数据。默认情况下,Prometheus 会以高效的格式(块)将其所有数据存储在本地磁盘中。随着时间的推移,它会自动压缩所有旧数据以节省存储空间,并具备删除旧数据的保留策略。TSDB 内置了一套机制来高效管理长期保存的数据。大家可以根据需要选择以下任意一种数据保留策略:- 基于时间的保留:数据将被保留指定的天数。默认保留期为 15 天。
- 基于大小的保留:可以设定 TSDB 可以容纳的最大数据量。一旦达到这个限制,Prometheus 将释放空间来容纳新数据。此外,Prometheus 还提供了远程存储选项,这对于实现存储可扩展性、长期数据存储、备份和灾难恢复等方面非常重要。
3)Prometheus Targets
<font style="color:rgb(0, 169, 113);background-color:rgb(249, 242, 244);">Target</font> 是 Prometheus 抓取指标的来源。目标可以是服务器、服务、Kubernetes Pod、应用程序端点等。
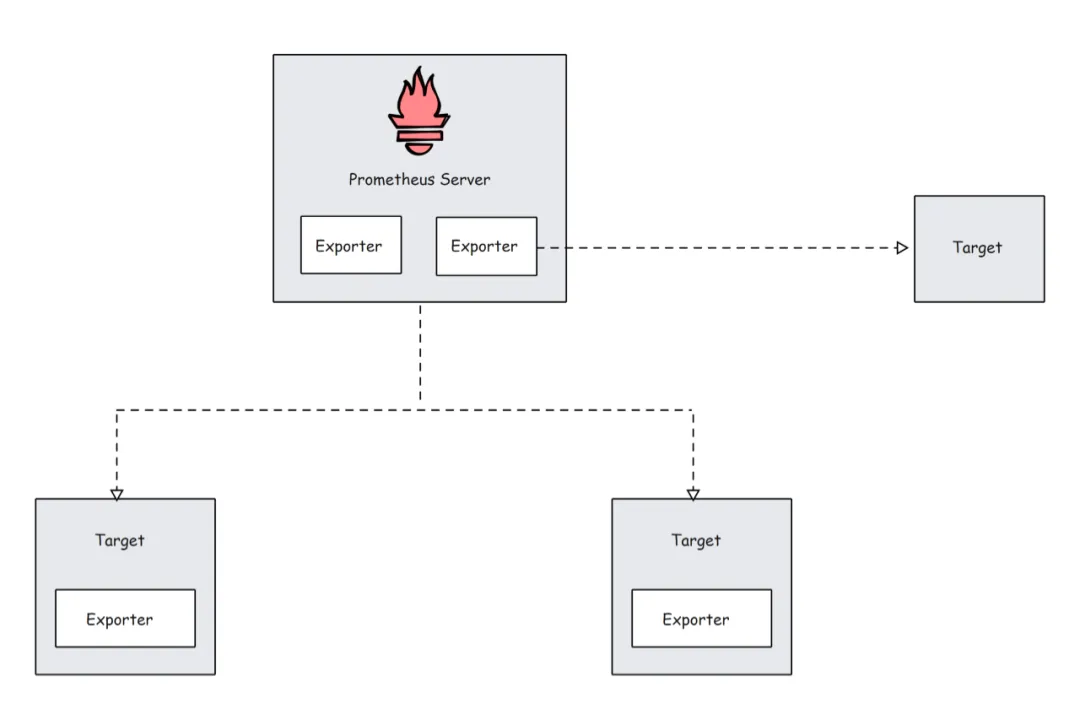
<font style="color:rgb(0, 169, 113);background-color:rgb(249, 242, 244);">/metrics</font> 路径下查找指标。大家也可以在目标配置中更改这一默认路径。这意味着,如果不指定自定义的指标路径,Prometheus 将会在 <font style="color:rgb(0, 169, 113);background-color:rgb(249, 242, 244);">/metrics</font> 路径下查找指标。
目标配置位于 Prometheus 配置文件中的 <font style="color:rgb(0, 169, 113);background-color:rgb(249, 242, 244);">scrape_configs</font> 部分。下面是一个配置示例:
从目标端点来看,Prometheus 需要特定文本格式的数据。每个指标都必须位于一个新行上。 通常这些
scrape_configs:- job_name: 'node-exporter'static_configs:- targets: ['node-exporter1:9100', 'node-exporter2:9100']- job_name: 'my_custom_job'static_configs:- targets: ['my_service_address:port']metrics_path: '/custom_metrics'- job_name: 'blackbox-exporter'static_configs:- targets: ['blackbox-exporter1:9115', 'blackbox-exporter2:9115']metrics_path: /probe- job_name: 'snmp-exporter'static_configs:- targets: ['snmp-exporter1:9116', 'snmp-exporter2:9116']metrics_path: /snmp
<font style="color:rgb(0, 169, 113);background-color:rgb(249, 242, 244);">Exporter</font> 指标,使用在目标运行的各类 <font style="color:rgb(0, 169, 113);background-color:rgb(249, 242, 244);">Exporter</font> 在目标节点上暴漏这份数据。
4)Prometheus Exporters
<font style="color:rgb(0, 169, 113);background-color:rgb(249, 242, 244);">Exporter</font> 就像在目标上运行的代理。它将指标从特定系统转换为 Prometheus 可以理解的格式。它可以是系统指标,如 CPU、内存等,也可以是 Java JMX 指标、MySQL 指标等。
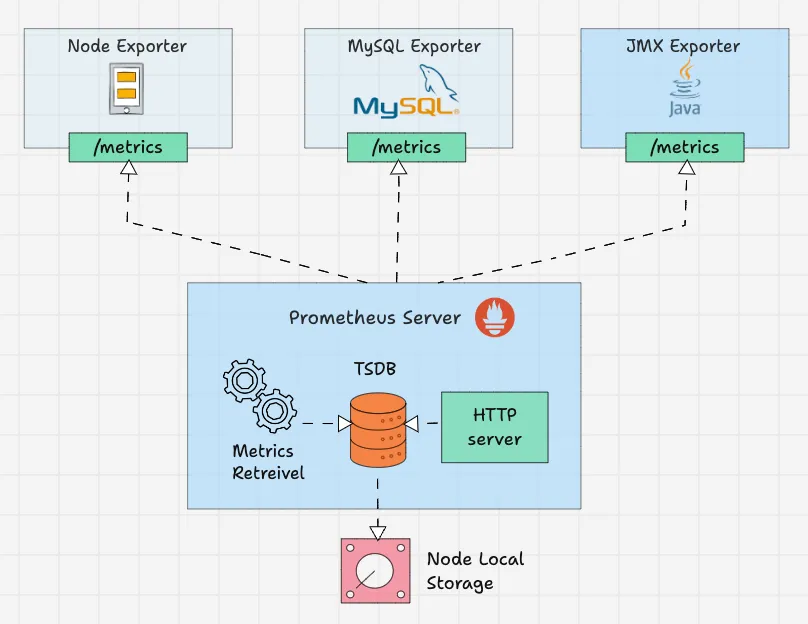
<font style="color:rgb(0, 169, 113);background-color:rgb(249, 242, 244);">/metrics</font> 路径(即 HTTP 端点)上公开。例如,如果您想要监控服务器的 CPU 使用率和内存使用情况,则需要在该服务器上安装 Node Exporter。Node Exporter 会将这些 CPU 和内存指标以 Prometheus 指标格式公开在 <font style="color:rgb(0, 169, 113);background-color:rgb(249, 242, 244);">/metrics</font> 路径上。一旦 Prometheus 抓取了这些指标,它就会结合指标名称、标签、数值和时间戳来生成结构化的数据。
Prometheus 社区提供了大量的 Exporters,不过只有部分得到了 Prometheus 官方的支持与维护。如果大家谁有更特定的需求或者想要采集某些特定的服务指标,可能就需要自己创建一个定制化的 Exporter。Prometheus 将 Exporters 分类为不同的类别,如数据库、硬件监控、问题跟踪系统、持续集成工具、消息队列系统、存储解决方案、公开 Prometheus 指标的软件以及各种第三方工具等。可以从官方文档中找到每个类别的 Exporter 列表。
在 Prometheus 的配置文件中,所有 Exporter 的详细信息都将在 <font style="color:rgb(0, 169, 113);background-color:rgb(249, 242, 244);">scrape_configs</font> 部分给出。这部分配置定义了 Prometheus 如何发现和抓取指标数据。
scrape_configs:- job_name: 'node-exporter'static_configs:- targets: ['node-exporter1:9100', 'node-exporter2:9100']- job_name: 'blackbox-exporter'static_configs:- targets: ['blackbox-exporter1:9115', 'blackbox-exporter2:9115']metrics_path: /probe- job_name: 'snmp-exporter'static_configs:- targets: ['snmp-exporter1:9116', 'snmp-exporter2:9116']metrics_path: /snmp
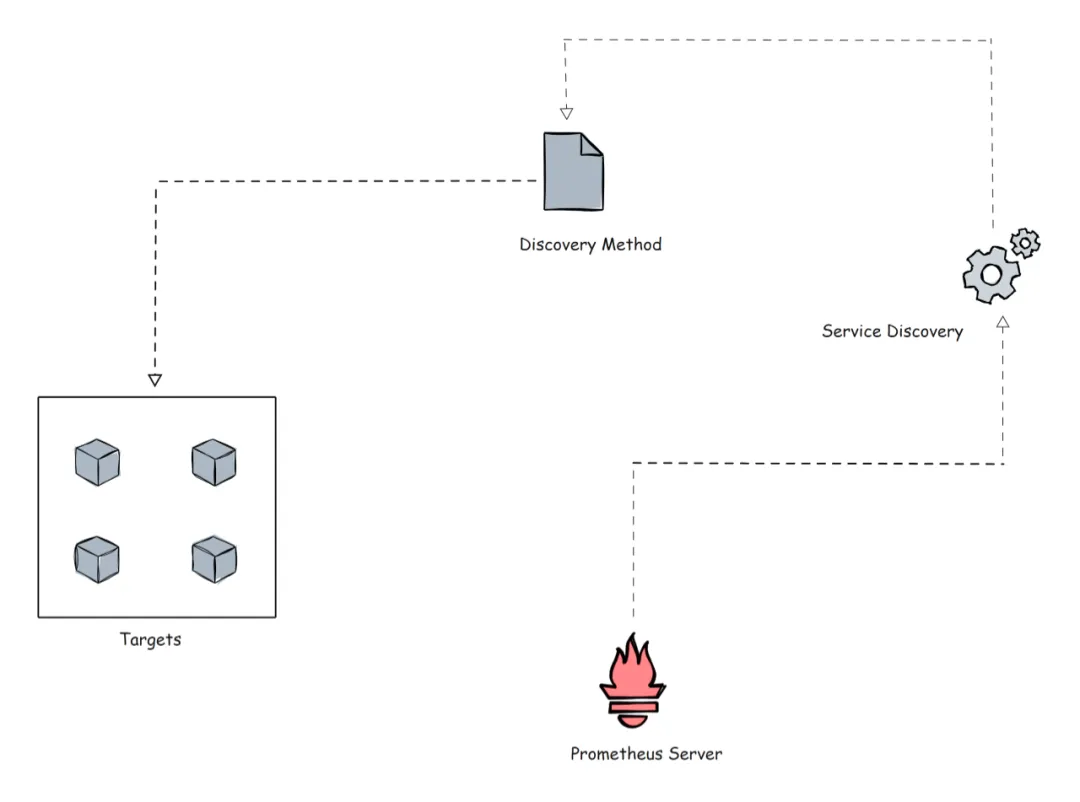
5)Prometheus Service Discovery
Prometheus 采用两种主要方式从监控目标中收集指标数据:- 静态配置:当监控目标拥有固定的 IP 地址或 DNS 端点时,可以通过直接指定这些端点的方式来进行配置。这种方式适用于那些不经常变化的监控目标。
- 服务发现:在自动伸缩系统或像 Kubernetes 这样的分布式环境中,监控目标通常不具备静态的 IP 地址或 DNS 端点。在这种场景下,Prometheus 支持服务发现机制 来动态识别和更新监控目标列表。通过服务发现,新的目标会被自动添加到 Prometheus 的配置中,而不再可用的目标则会被自动移除,确保监控配置始终保持最新状态。
<font style="color:rgb(0, 169, 113);background-color:rgb(249, 242, 244);">kubernetes_sd_configs</font> 配置文件的 Kubernetes 服务发现示例:
Kubernetes 是动态目标的典型示例。由于 Kubernetes 集群中的目标(如 Pod)往往是短暂存在的,因此不适合使用静态目标配置方法。 在 Kubernetes 中,除了经典的静态配置
scrape_configs:- job_name: 'kubernetes-pods'kubernetes_sd_configs:- role: podrelabel_configs:- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]action: keepregex: true- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]action: replaceregex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2target_label: __address__- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_pod_name]action: replacetarget_label: kubernetes_pod_name
<font style="color:rgb(0, 169, 113);background-color:rgb(249, 242, 244);">static_configs</font> 外,还有一种基于文件的服务发现方法 <font style="color:rgb(0, 169, 113);background-color:rgb(249, 242, 244);">file_sd_configs</font>。这种方法虽然主要用于静态目标,但它与经典静态配置的主要区别在于,您需要创建单独的 JSON 或 YAML 文件,并将目标信息保存在这些文件中。Prometheus 会读取这些文件来识别目标。
除此之外,还有多种服务发现方法可供选择,例如:
<font style="color:rgb(0, 169, 113);background-color:rgb(249, 242, 244);">consul_sd_configs</font>:Prometheus 从 Consul 获取目标的详细信息。<font style="color:rgb(0, 169, 113);background-color:rgb(249, 242, 244);">ec2_sd_configs</font>:适用于 Amazon EC2 环境中的目标发现。
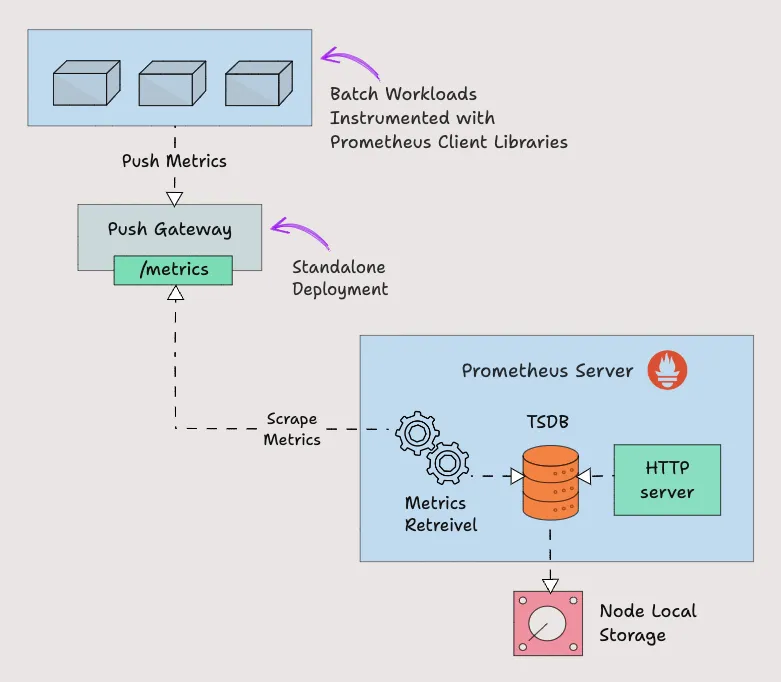
6)Prometheus Pushgateway
Prometheus 默认采用 pull(拉取)模式来收集指标数据。但在某些特殊场景下,可能需要将指标主动推送给 Prometheus。例如,在 Kubernetes 中运行的 cronjob 执行批处理作业,这类作业可能每天只运行几分钟以处理特定事件。在这种情况下,Prometheus 的常规 pull 模式可能无法及时捕捉到服务级别的指标数据。因此,需要采用 push(推送)模式,而不是被动等待 Prometheus 拉取指标。 为了实现指标的推送,Prometheus 提供了一个名为 Pushgateway 的解决方案。Pushgateway 本质上是一个中介组件,它接受来自批处理作业或其他短寿命任务的指标数据,并将这些数据保持一段时间,直到 Prometheus 主动拉取它们。 具体来说,Pushgateway 需要作为一个独立的服务运行。批处理作业可以使用 HTTP API 将指标推送到 Pushgateway。随后,Pushgateway 会在<font style="color:rgb(0, 169, 113);background-color:rgb(249, 242, 244);">/metrics</font> 端点上公开这些指标。Prometheus 会定期从 Pushgateway 中抓取这些指标,确保即使对于短暂运行的任务也能实现有效的监控。
通过这种方式,Prometheus 能够与临时运行的作业或服务无缝集成,确保即便是在非连续运行的服务中也能实现指标数据的收集和监控。
<font style="color:rgb(0, 169, 113);background-color:rgb(249, 242, 244);">scrape_configs</font> 部分下进行配置。
为了将指标发送到 Pushgateway,需要使用 Prometheus 客户端库,并对应用程序或脚本进行
scrape_configs:- job_name: 'pushgateway'honor_labels: truestatic_configs:- targets: [pushgateway.monitoring.svc:9091]
<font style="color:rgb(0, 169, 113);background-color:rgb(249, 242, 244);">instrumentation</font>,以便公开所需的指标,实现实时监控和数据分析。
7)Prometheus Client Libraries
Prometheus 客户端库是一组软件库,用于在应用程序代码中进行 instrumentation(埋点插桩),以便以 Prometheus 能够理解的方式公开指标。如果您需要自行埋点或想要创建自定义的 Exporter,那么客户端库将是必不可少的工具。 一个非常典型的用例是需要将指标推送到 Pushgateway 的批处理作业。在这种情况下,批处理作业可以使用 Prometheus 客户端库来埋点,并以 Prometheus 格式公开指标。下面是一个使用 Python 客户端库的示例,该示例公开了一个名为<font style="color:rgb(0, 169, 113);background-color:rgb(249, 242, 244);">batch_job_records_processed_total</font> 的自定义指标:
通过这种方式,您可以确保批处理作业能够将指标数据发送到 Pushgateway,进而被 Prometheus 服务器抓取,实现实时监控和数据分析。
from prometheus_client import CollectorRegistry, Gauge, push_to_gateway# 初始化 Prometheus 客户端库registry = CollectorRegistry()# 创建一个自定义指标gauge = Gauge('batch_job_records_processed_total', 'Total records processed by the batch job', registry=registry)# 更新指标值gauge.set(12345) # 假设批处理作业处理了 12345 条记录# 将指标推送到 Pushgatewaypush_to_gateway('pushgateway.example.com:9091', job='batch_job', registry=registry)
8)Prometheus Alertmanager
Alertmanager 是 Prometheus 监控系统中的一个关键组件。它的主要职责是根据 Prometheus 警报规则中定义的指标阈值来处理和发送警报。警报最初由 Prometheus 进程触发,并随后发送到 Alertmanager。Alertmanager 对接收到的警报执行以下操作:
- Alert Deduplication(警报去重):消除重复警报,确保相同的警报不会多次发送给接收者。
- Grouping(警报分组):将相关的警报归类到一组中,以便更高效地管理和通知。
- Silencing(静默处理):在预定的时间段内静默特定警报,例如在维护窗口期间。
- Routing(路由):根据警报的严重程度和其他规则,将警报路由到适当的接收者或通知渠道。
- Inhibition(抑制):当存在更高严重性的警报时,抑制较低严重性的警报,避免过多的通知干扰重要警报的传达。
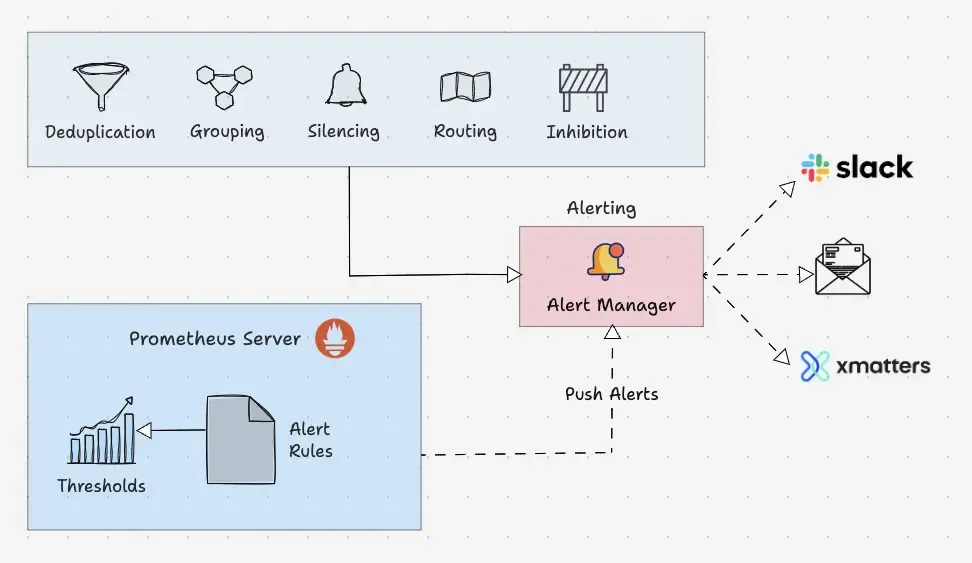
再来看一下 Alertmanager 路由配置示例:
node.rules: |groups:- name: node.rulesrules:- alert: NodeFilesystemUsageexpr: |100 - (node_filesystem_avail_bytes / node_filesystem_size_bytes) * 100 > 85for: 1mlabels:severity: warningannotations:summary: 'Instance {{ $labels.instance }} : {{ $labels.mountpoint }} 分区使用率过高'description: '{{ $labels.instance }} 主机名:{{ $labels.hostname }} : {{ $labels.mountpoint }} 分区使用大于85% (当前值: {{ $value }})'- alert: NodeMemoryUsageexpr: |100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 88for: 1mlabels:severity: warningannotations:summary: 'Instance {{ $labels.instance }} 内存使用率过高'description: '{{ $labels.instance }} 主机名:{{ $labels.hostname }} 内存使用大于88% (当前值: {{ $value }})'
Alertmanager 支持大多数消息和通知系统,例如 企微、钉钉、电话、短信、邮件 等,将警报作为通知发送给接收者。
receivers:- name: 'wechat'wechat_configs:- corp_id: 'ww187XXXXXXXXecc4'send_resolved: trueto_party: '413'to_user: 'XXXXX'agent_id: 10XXXX5api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'api_secret: 'IVRfzG15S6XXXXXXXXXXXXBdY3fyocuDP-tc'
9)PromQL
PromQL(Prometheus Query Language)是 Prometheus 监控系统中用于查询时间序列数据的一种强大而灵活的语言。PromQL 允许用户以简洁、直观的方式查询和聚合时间序列数据,以满足各种监控和分析需求。

PromQL 是 Prometheus 监控系统中的查询语言,具有以下特点:
- 简洁易用:设计直观,易于学习和使用。
- 强大的聚合功能:支持多种聚合操作,如求和、平均值、最大值等。
- 灵活的时间范围选择:能够选择特定时间范围内的数据进行查询。
- 标签过滤:通过标签选择器进行精细的数据筛选。
- 向量操作:支持向量间的数学运算和时间序列的变换。
总结
如上概述了 Prometheus 架构的主要组件,并介绍了 Prometheus 配置的基本概览。Prometheus 是一个非常实用的解决方案,它提供了丰富的配置选项,基本能够根据具体的监控需求和环境定制其行为,是可观察环节中重要的一环。
若有收获,就点个赞吧
0 人点赞
