Kubernetes
如今行业中的公司似乎分为两个 Kubernetes 阵营:那些已经大量使用它来处理生产工作负载的公司,以及那些正在将其工作负载迁移到其中的公司。
Kubernetes 的问题在于它不像 Redis RabbitMQ 或 PostgreSQL 那样的单一系统。它是几个控制平面组件(例如 etcd、api 服务器)的组合,它们通过一组 VM 在用户(数据)平面上运行工作负载。乍一看,来自控制平面组件、虚拟机和工作负载的指标数量可能会让人不知所措。从这些指标中形成一个全面的可观察性堆栈需要具备管理 Kubernetes 集群的良好知识和经验。
那么如何处理海量的指标呢?阅读这篇文章可能是一个很好的起点🙂
这里介绍基于 k8s 元数据的最关键指标,这些元数据构成了监控工作负载并确保它们处于健康状态的良好基准。为了使这些指标可用,需要安装kube-state-metrics和 Prometheus 来抓取它公开的指标并将它们存储起来以供以后查询。在这里不介绍安装过程,但一个很好的引导是 Prometheus Helm Chart https://github.com/prometheus-community/helm-charts/tree/main/charts/prometheus,它使用默认设置安装两者。
监控的最关键的 Kubernetes 指标
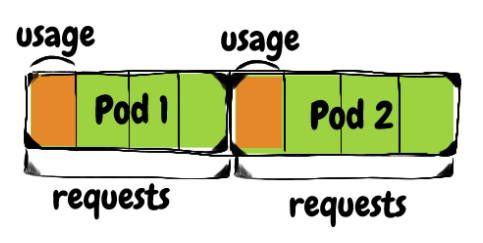
对于列出的每个指标,介绍指标的含义、为什么要关注它以及如何根据它设置高警。CPU / 内存请求与实际使用情况
每个容器都可以定义对 CPU 和内存的请求。Kubernetes 调度程序正在使用这些请求来确保它选择一个能够承载 Pod 的节点。它通过计算节点上未使用的资源来考虑其容量减去当前调度的 Pod 请求来实现这一点。 看一个更清楚的示例:假设有一个具有 8 个 CPU 内核的节点,运行 3 个 pod,每个 pod 带有一个请求 1 个 CPU 内核的容器。该节点有 5 个未预留的 CPU 内核供调度程序在分配 pod 时使用。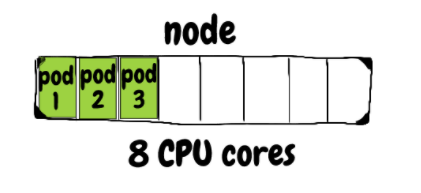
CPU / 内存限制与实际使用情况
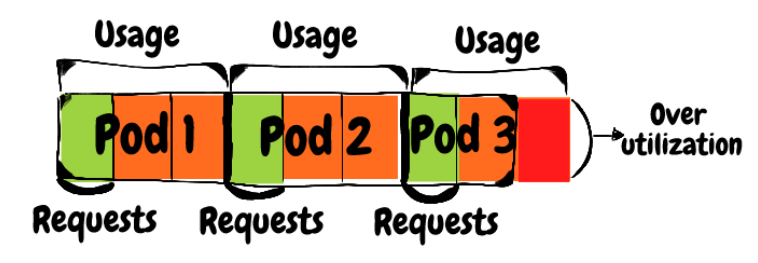
当调度程序使用资源请求将工作负载调度到节点中时,资源限制允许定义运行时工作负载资源使用的边界。 了解强制执行 CPU 和内存限制的方式非常重要,这样才能了解跨过它们的工作负载的影响:当容器达到 CPU 限制时,它将受到限制,这意味着它从操作系统获得的 CPU 周期少于它可能有并且最终导致执行时间变慢。托管 pod 的节点是否有空闲的 CPU 周期空闲并不重要——容器受到 docker 运行时的限制。 在不知不觉中被 CPU 节流是非常危险的。系统中服务调用延迟会上升,如果系统中的某个组件受到限制并且没有事先设置所需的可观察性,则可能很难查明根本原因。如果受限制的服务是业务中的核心流程,这种情况可能会导致部分服务中断或完全不可用。 内存限制的执行方式与 CPU 限制不同:当容器达到内存限制时,它会被 OOMKilled,这与由于节点上的内存不足而被 OOMKIlled 产生的效果相同:进程将丢弃运行中的请求,服务将容量不足,直到容器重新启动,然后它将有一个冷启动期。如果进程足够快地积累内存,它可能又会进入 CrashLoop 状态——这种状态表明进程要么在启动时崩溃,要么在一遍又一遍地启动后的短时间内崩溃。Crashlooping pod 通常会导致服务不可用。 如何解决呢?监控资源限制的方式类似于监控 CPU/内存请求的方式。目标应该是在第 90 个百分位的限制中达到 80% 的实际使用量。例如,如果 Pod 的 CPU 限制为 2 核,内存限制为 2GB,则告警应设置为 CPU 使用量为 1.6 核或内存使用量为 1.6GB。高于此值的任何内容都会导致工作负载根据超出的阈值受到限制或重新启动的风险。副本中不可用 Pod 的百分比
当部署应用程序时,可以设置它应该运行的所需副本(pod)的数量。有时,由于多种原因,某些 pod 可能不可用,例如:- 由于资源请求,某些 pod 可能不适合集群中任何正在运行的节点——这些 pod 将转换为 Pending 状态,直到节点释放资源来托管它们或满足要求的新节点加入集群。
- 一些 pod 可能无法通过 liveness/readiness 探测,这意味着它们要么重新启动(liveness),要么被从服务端点中剔除(readiness)。
- 某些 pod 可能会达到其资源限制并进入 Crashloop 状态。
- 由于各种原因,某些 pod 可能托管在故障节点上,如果节点不健康,则托管在其上的 pod 很可能无法正常运行。
HPA | 最大副本之外的所需副本
Horizontal Pod Autoscaler (HPA) 是一种 k8s 资源,允许根据定义的目标函数调整工作负载正在运行的副本数量。常见的用例是根据部署中 pod 的平均 CPU 使用率与 CPU 请求相比自动扩展。 当部署的副本数量达到 HPA 中定义的最大值时,可能会遇到需要更多 pod 但 HPA 无法扩展的情况。根据设置的放大功能,结果可能会有所不同。这里有 2 个例子可以更清楚地说明:- 如果扩展功能使用 CPU 使用率,则现有 pod 的 CPU 使用率将增加到达到极限并受到限制的程度。这最终会导致系统的吞吐量降低。
- 如果扩展功能使用自定义指标,例如队列中未处理消息的数量,则队列可能会开始充满未处理消息,从而在处理管道中引入延迟。
节点状态检查失败
kubelet 是一个运行在集群上每个节点上的 k8s 代理。在其职责中,kubelet 发布了一些指标(称为节点条件)来反映它运行的节点的健康状态:- 准备好— 如果节点健康并准备好接受 pod,则上报 true
- 磁盘压力— 如果节点的磁盘没有可用存储空间,则上报 true
- 内存压力— 如果节点内存不足,则上报 true
- PID压力— 如果节点上运行的进程太多,则上报 true
- 网络不可用— 如果节点的网络未正确配置,则上报 true
持久卷利用率
Persistent Volume (PV) 是一种 k8s 资源对象,表示可以附加和分离到系统中的 Pod 的存储块。PV 的实现是特定于平台的,例如,如果 Kubernetes 部署基于 AWS,则 PV 将由 EBS 卷表示。与每个块存储一样,它具有容量并且可能会被时间填满。 当一个进程使用一个没有可用空间的磁盘时,就会崩溃,因为故障可能以一百万种不同的方式表现出来,而堆栈跟踪并不总是导致根本原因。除了免于未来的故障之外,观察此指标还可用于规划随时间记录和添加数据的工作负载。Prometheus 是此类工作负载的一个很好的例子——当它将数据点写入其时间序列数据库时,磁盘中的可用空间量会减少。由于 Prometheus 写入数据的速率非常一致,因此很容易使用 PV 利用率指标来预测删除旧数据或购买更多磁盘容量所需的时间。 如何解决此类问题?kubelet 公开了 PV 使用情况和容量,因此它们之间的简单划分应该可以提供 PV 使用情况。建议一个合理的警报阈值有点困难,因为它实际上取决于利用率图的轨迹,但根据经验,应该提前两到三周预测到 PV 耗尽。总结
正如已经发现的那样,处理 Kubernetes 集群并不是一件容易的事。有大量可用的指标,需要大量的专业知识来选择重要的指标。 拥有一个监控集群关键指标的仪表盘既可以作为一种预防措施来避免出现问题,也可以作为一种工具来解决系统中的问题。
若有收获,就点个赞吧
0 人点赞
