import ( “fmt” “unsafe” )
type K struct { }
func main() { a := K{} b := int(0) //8 c := K{} fmt.Println(unsafe.Sizeof(a)) //a和c的地址一模一样 fmt.Printf(“%p\n”, &a) //0x110a5c0 fmt.Printf(“%p\n”, &b) fmt.Printf(“%p\n”, &c) //0x110a5c0 }
`runtime/malloc.go````go// base address for all 0-byte allocationsvar zerobase uintptr
空结构体
- 空结构体的地址均相同(不被包含在其他结构体时)
空结构体主要是为了节约内存
Go中部分数据的长度与系统字长有关
- 空结构体不占用空间
- 空结构体与map结合可以实现hashset
空结构体与channel结合可以当作纯信号(不携带任何信息的信号量)
数组、字符串、切片底层是一样的吗?
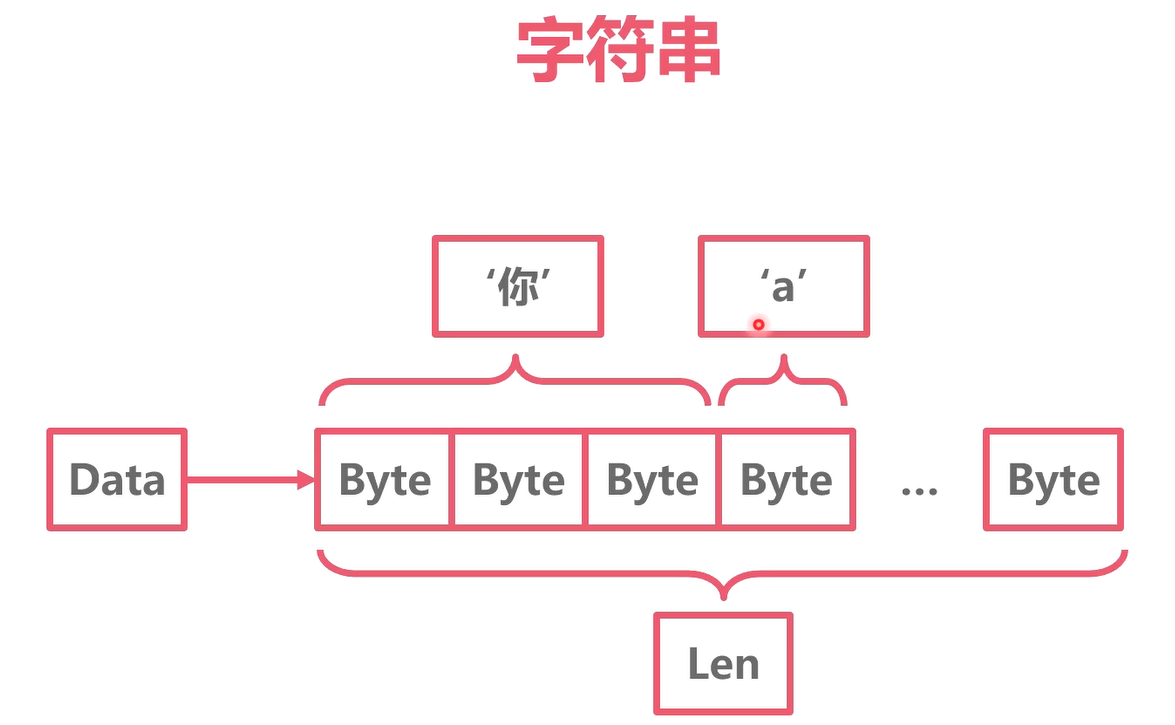
字符串
type stringStruct struct {str unsafe.Pointerlen int}
字符串本质是个结构体
- Data指针指向底层Byte数组
Len表示Byte数组的长度(字节数)
type StringHeader struct {Data uintptrLen int}
字符编码问题
所有的字符均使用Unicode字符集
-
Unicode
一种统一的字符集
- 囊括了159种文字的144679个字符
- 14万个字符至少需要3个字节表示
-
UTF-8
Unicode的一种变长格式
- 128个US-ASCII字符只需一个字节编码
- 西方常用字符需要两个字节
- 其他字符需要3个字节,极少需要4个字节
// Copyright 2016 The Go Authors. All rights reserved.// Use of this source code is governed by a BSD-style// license that can be found in the LICENSE file.package runtime// Numbers fundamental to the encoding.const (runeError = '\uFFFD' // the "error" Rune or "Unicode replacement character"runeSelf = 0x80 // characters below runeSelf are represented as themselves in a single byte.maxRune = '\U0010FFFF' // Maximum valid Unicode code point.)// Code points in the surrogate range are not valid for UTF-8.const (surrogateMin = 0xD800surrogateMax = 0xDFFF)const (t1 = 0x00 // 0000 0000tx = 0x80 // 1000 0000t2 = 0xC0 // 1100 0000t3 = 0xE0 // 1110 0000t4 = 0xF0 // 1111 0000t5 = 0xF8 // 1111 1000maskx = 0x3F // 0011 1111mask2 = 0x1F // 0001 1111mask3 = 0x0F // 0000 1111mask4 = 0x07 // 0000 0111rune1Max = 1<<7 - 1rune2Max = 1<<11 - 1rune3Max = 1<<16 - 1// The default lowest and highest continuation byte.locb = 0x80 // 1000 0000hicb = 0xBF // 1011 1111)// countrunes returns the number of runes in s.func countrunes(s string) int {n := 0for range s {n++}return n}// decoderune returns the non-ASCII rune at the start of// s[k:] and the index after the rune in s.//// decoderune assumes that caller has checked that// the to be decoded rune is a non-ASCII rune.//// If the string appears to be incomplete or decoding problems// are encountered (runeerror, k + 1) is returned to ensure// progress when decoderune is used to iterate over a string.func decoderune(s string, k int) (r rune, pos int) {pos = kif k >= len(s) {return runeError, k + 1}s = s[k:]switch {case t2 <= s[0] && s[0] < t3:// 0080-07FF two byte sequenceif len(s) > 1 && (locb <= s[1] && s[1] <= hicb) {r = rune(s[0]&mask2)<<6 | rune(s[1]&maskx)pos += 2if rune1Max < r {return}}case t3 <= s[0] && s[0] < t4:// 0800-FFFF three byte sequenceif len(s) > 2 && (locb <= s[1] && s[1] <= hicb) && (locb <= s[2] && s[2] <= hicb) {r = rune(s[0]&mask3)<<12 | rune(s[1]&maskx)<<6 | rune(s[2]&maskx)pos += 3if rune2Max < r && !(surrogateMin <= r && r <= surrogateMax) {return}}case t4 <= s[0] && s[0] < t5:// 10000-1FFFFF four byte sequenceif len(s) > 3 && (locb <= s[1] && s[1] <= hicb) && (locb <= s[2] && s[2] <= hicb) && (locb <= s[3] && s[3] <= hicb) {r = rune(s[0]&mask4)<<18 | rune(s[1]&maskx)<<12 | rune(s[2]&maskx)<<6 | rune(s[3]&maskx)pos += 4if rune3Max < r && r <= maxRune {return}}}return runeError, k + 1}// encoderune writes into p (which must be large enough) the UTF-8 encoding of the rune.// It returns the number of bytes written.func encoderune(p []byte, r rune) int {// Negative values are erroneous. Making it unsigned addresses the problem.switch i := uint32(r); {case i <= rune1Max:p[0] = byte(r)return 1case i <= rune2Max:_ = p[1] // eliminate bounds checksp[0] = t2 | byte(r>>6)p[1] = tx | byte(r)&maskxreturn 2case i > maxRune, surrogateMin <= i && i <= surrogateMax:r = runeErrorfallthroughcase i <= rune3Max:_ = p[2] // eliminate bounds checksp[0] = t3 | byte(r>>12)p[1] = tx | byte(r>>6)&maskxp[2] = tx | byte(r)&maskxreturn 3default:_ = p[3] // eliminate bounds checksp[0] = t4 | byte(r>>18)p[1] = tx | byte(r>>12)&maskxp[2] = tx | byte(r>>6)&maskxp[3] = tx | byte(r)&maskxreturn 4}}
func main() {s := "世界" //utf-8 编码for _, v := range s {fmt.Printf("%c\n", v)}}
字符串的访问
- 对字符串使用len方法得到的是字节数不是字节数
- 对字符串直接使用下标访问,得到的是字节
- 字符串被range遍历,被解码为rune类型的字符
-
字符串的切分
需要切分时
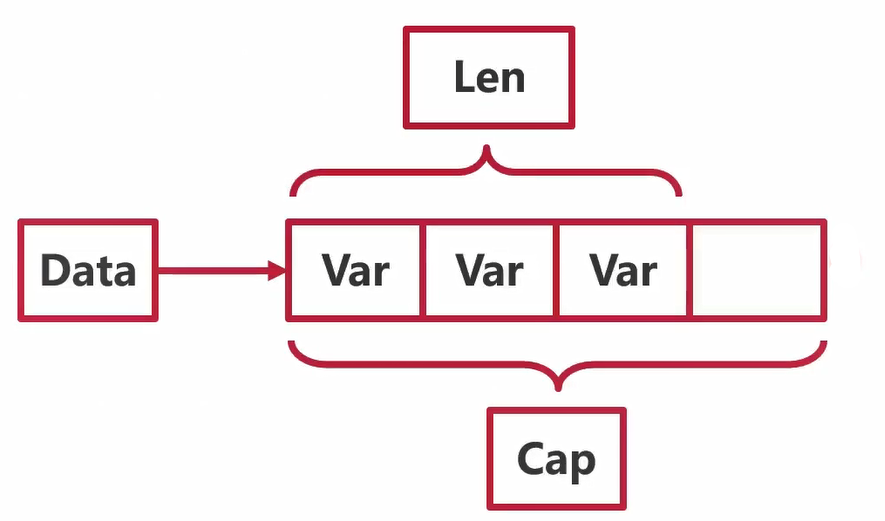
切片的本质是对数组的引用
type slice struct {array unsafe.Pointerlen intcap int}
切片的创建
根据数组创建
arr[0:3] or slice[0:3]
- 字面量:编译时插入创建数组的代码
slice := []int{1,2,3}
- make:运行时创建数组
slice := make([]int,10)
0x0014 00020 (代码路径\main2.go:11) LEAQ type.int(SB), AX0x001b 00027 (代码路径\main2.go:11) MOVL $3, BX0x0020 00032 (代码路径\main2.go:11) MOVQ BX, CX0x0023 00035 (代码路径\main2.go:11) PCDATA $1, $00x0023 00035 (代码路径\main2.go:11) CALL runtime.makeslice(SB)
arr := [10]int{0,1,2,3,4,5,6,7,8,9}slice := arr[1:4]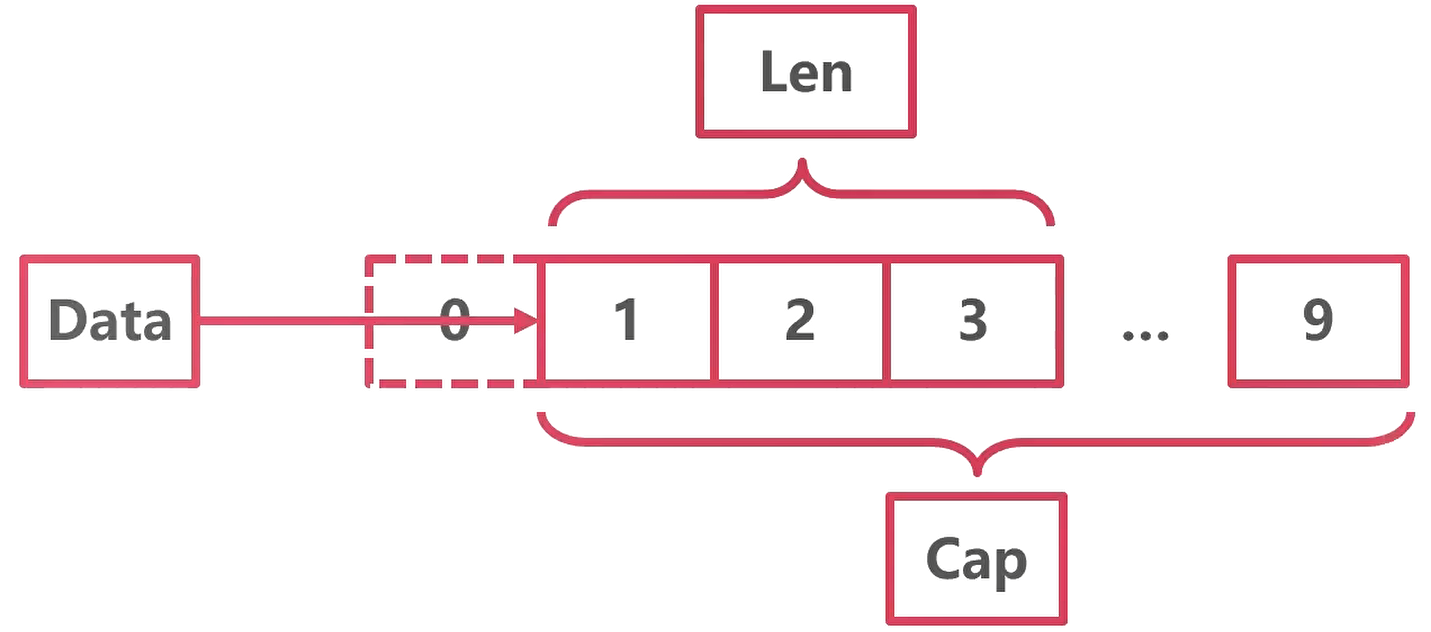
切片的访问
- 扩容时,编译时转为调用
runtime.growslice() - 如果期望容量大于当前容量的两倍,就会使用期望容量
- 如果当前切片的长度小于1024,将容量翻倍
- 如果当前切片的长度小于1024,每次增加25%
切片扩容时,并发不安全,注意切片并发要加锁
字符串与切片都是对底层数组的引用
- 字符串有UTF-8变长编码的特点
- 切片的容量和长度不同
- 切片追加时可能需要重建底层数组
map:重写Redis能用它吗?
Redis的本质是一个大的hashmap
HashMap的基本方案
- 开放寻址法
-
开放寻址法
拉链法
Go的map
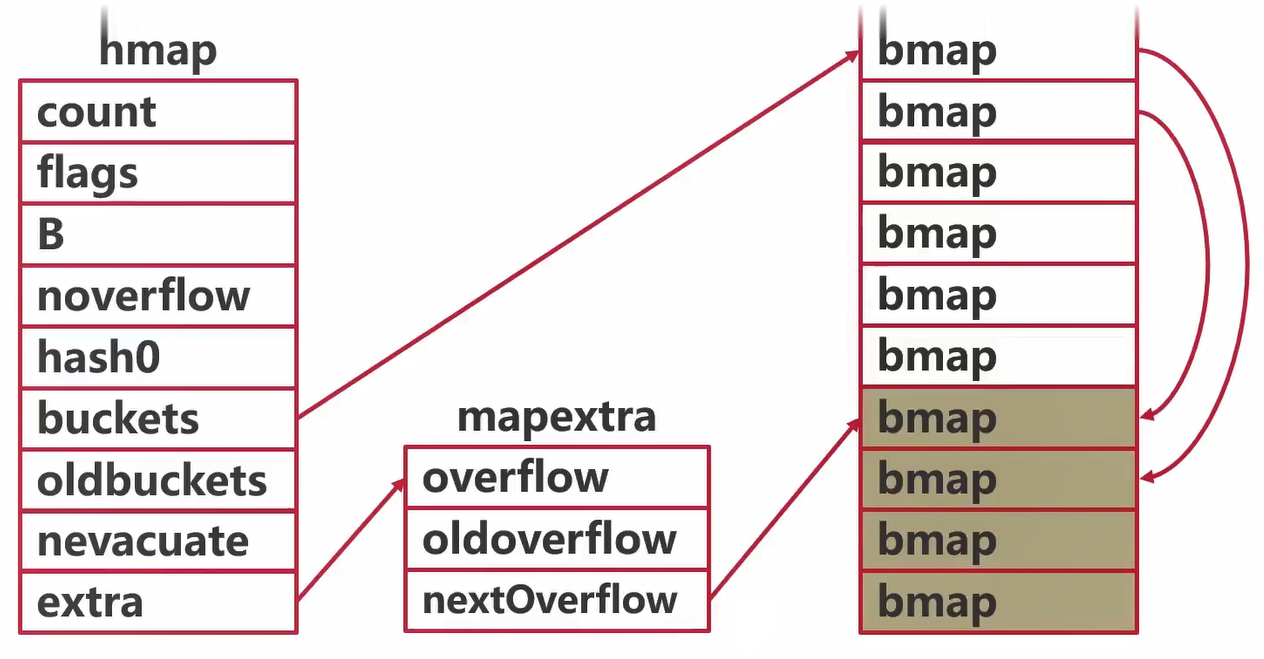
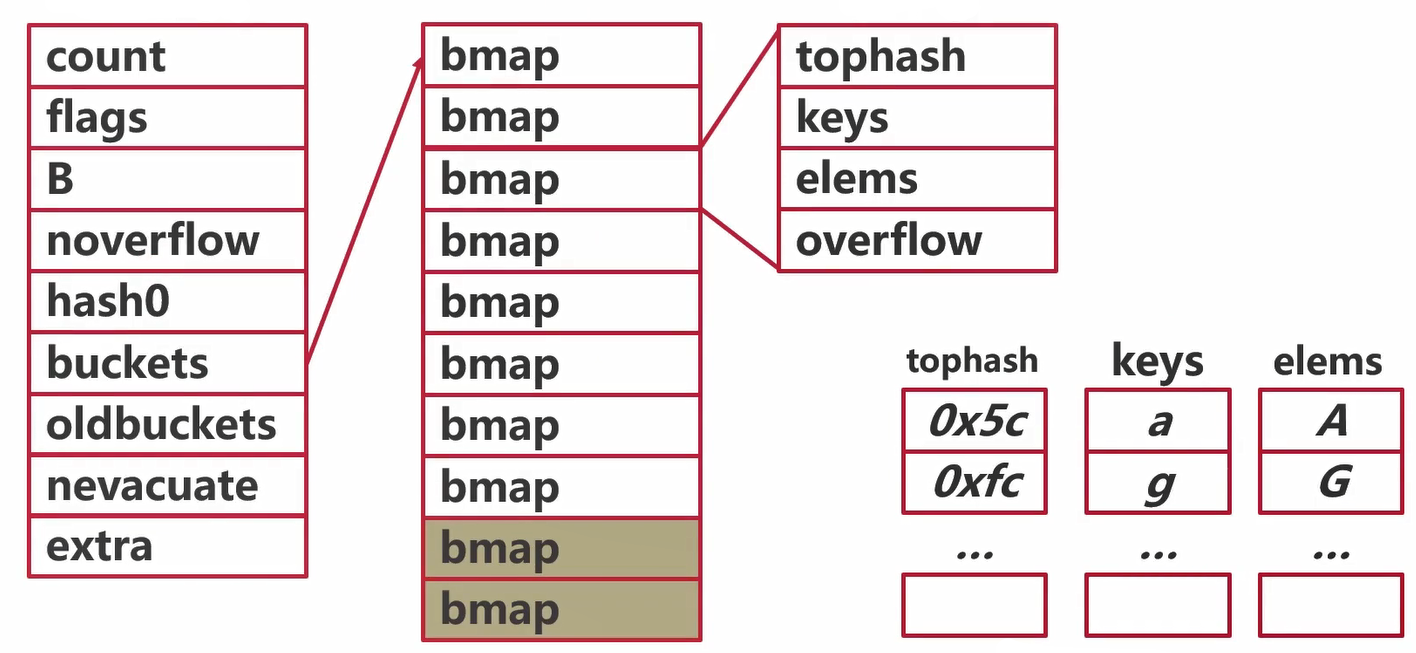
runtime.hmap// A header for a Go map.type hmap struct {// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.// Make sure this stays in sync with the compiler's definition.count int // # live cells == size of map. Must be first (used by len() builtin)flags uint8B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for detailshash0 uint32 // hash seedbuckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growingnevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)extra *mapextra // optional fields}
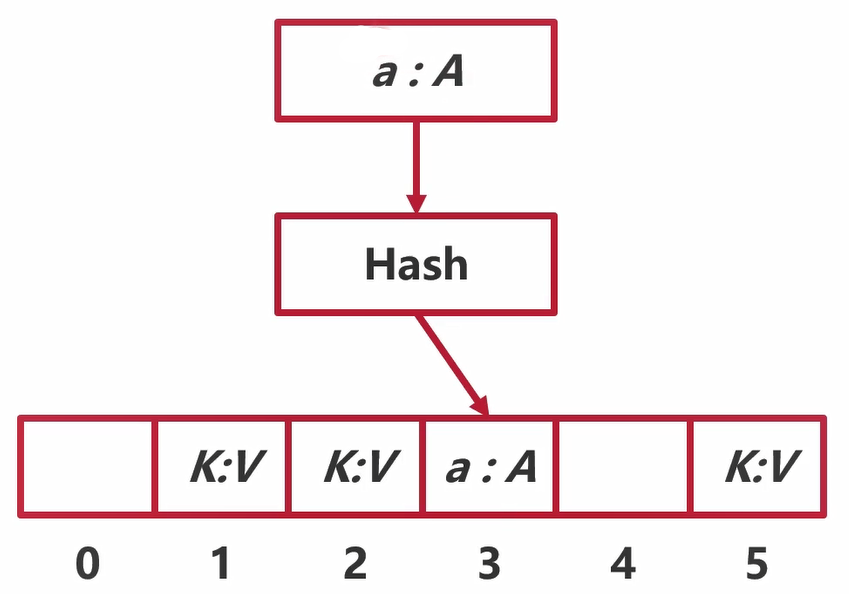
buckets指向由很多个bmap组成的数组

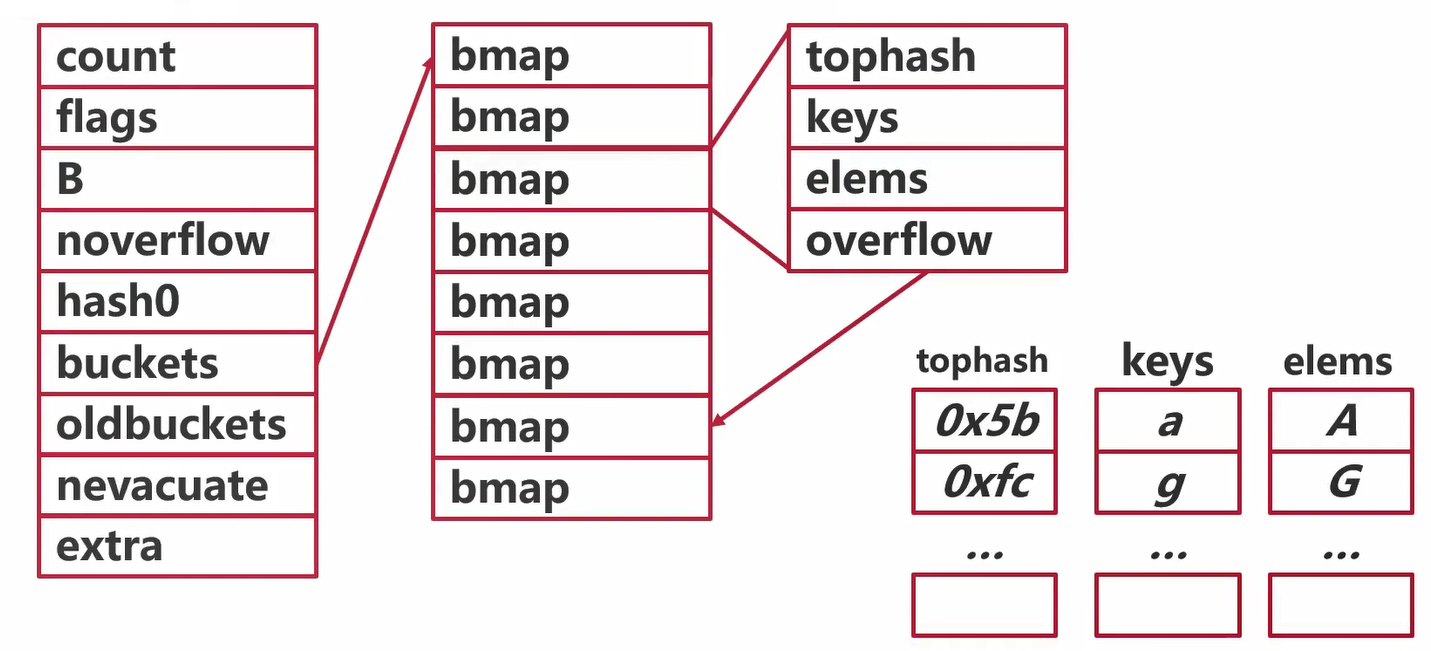
// mapextra holds fields that are not present on all maps.type mapextra struct {// If both key and elem do not contain pointers and are inline, then we mark bucket// type as containing no pointers. This avoids scanning such maps.// However, bmap.overflow is a pointer. In order to keep overflow buckets// alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow.// overflow and oldoverflow are only used if key and elem do not contain pointers.// overflow contains overflow buckets for hmap.buckets.// oldoverflow contains overflow buckets for hmap.oldbuckets.// The indirection allows to store a pointer to the slice in hiter.overflow *[]*bmapoldoverflow *[]*bmap// nextOverflow holds a pointer to a free overflow bucket.nextOverflow *bmap}
// A bucket for a Go map.type bmap struct {// tophash generally contains the top byte of the hash value// for each key in this bucket. If tophash[0] < minTopHash,// tophash[0] is a bucket evacuation state instead.tophash [bucketCnt]uint8// Followed by bucketCnt keys and then bucketCnt elems.// NOTE: packing all the keys together and then all the elems together makes the// code a bit more complicated than alternating key/elem/key/elem/... but it allows// us to eliminate padding which would be needed for, e.g., map[int64]int8.// Followed by an overflow pointer.}
tophash代表一个数组,数组中有8个hash值 keys字段代表一个数组,数组里面有8个key elems字段代表一个数组,数组里面有8个value overflow是一个指针,指向溢出桶,这个桶里面继续放K-V
map的初始化
0x0014 00020 (路径\main3.go:6) LEAQ type.map[string]int(SB), AX0x001b 00027 (路径\main3.go:6) MOVL $10, BX0x0020 00032 (路径\main3.go:6) XORL CX, CX0x0022 00034 (路径\main3.go:6) PCDATA $1, $00x0022 00034 (路径\main3.go:6) CALL runtime.makemap(SB)
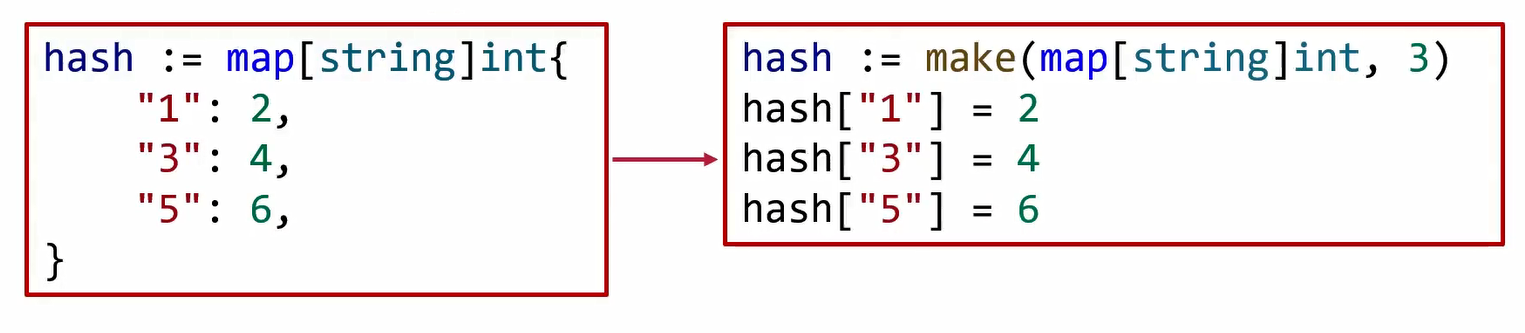
map的初始化:字面量
- 元素少于25个时,转化为简单赋值
编译时改成右侧的代码(代码优化?)
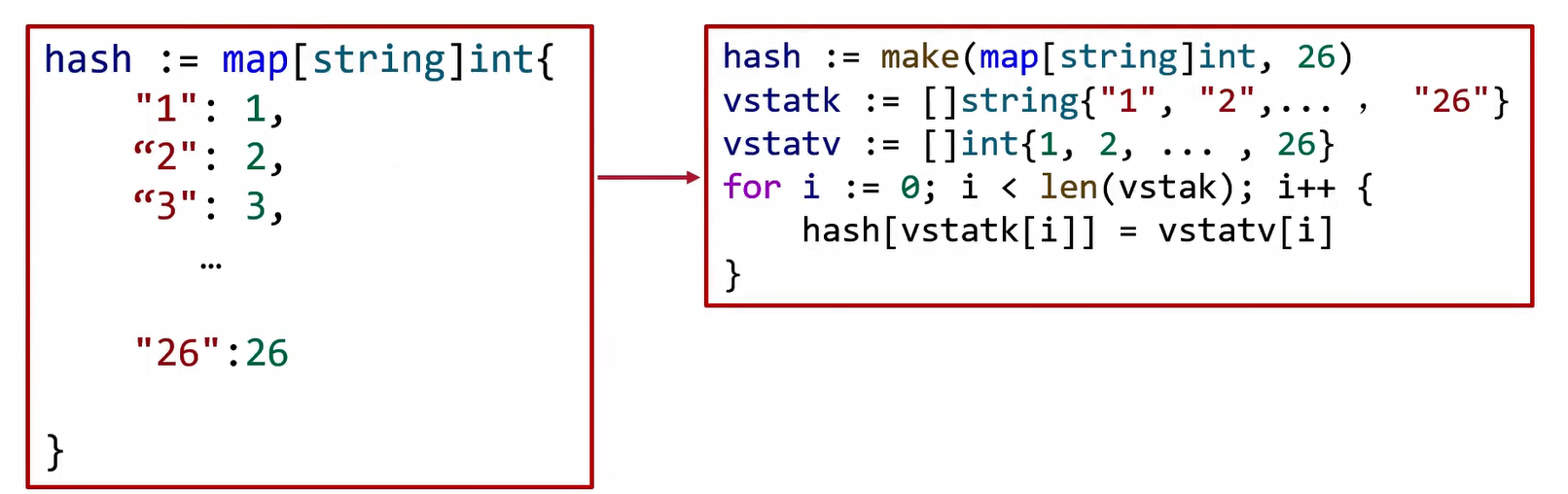
- 元素多于25个时,转化为循环赋值
map的访问
tophash数组中记录的值是八个key的hash值的高八位,为了快速遍历
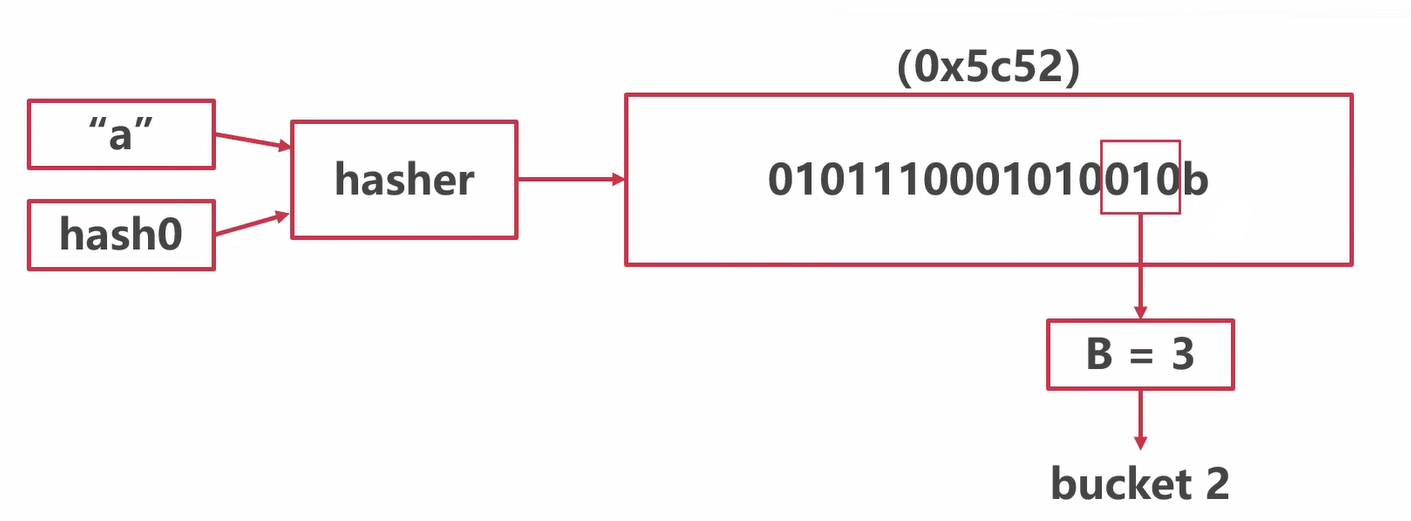
map的访问:计算桶号
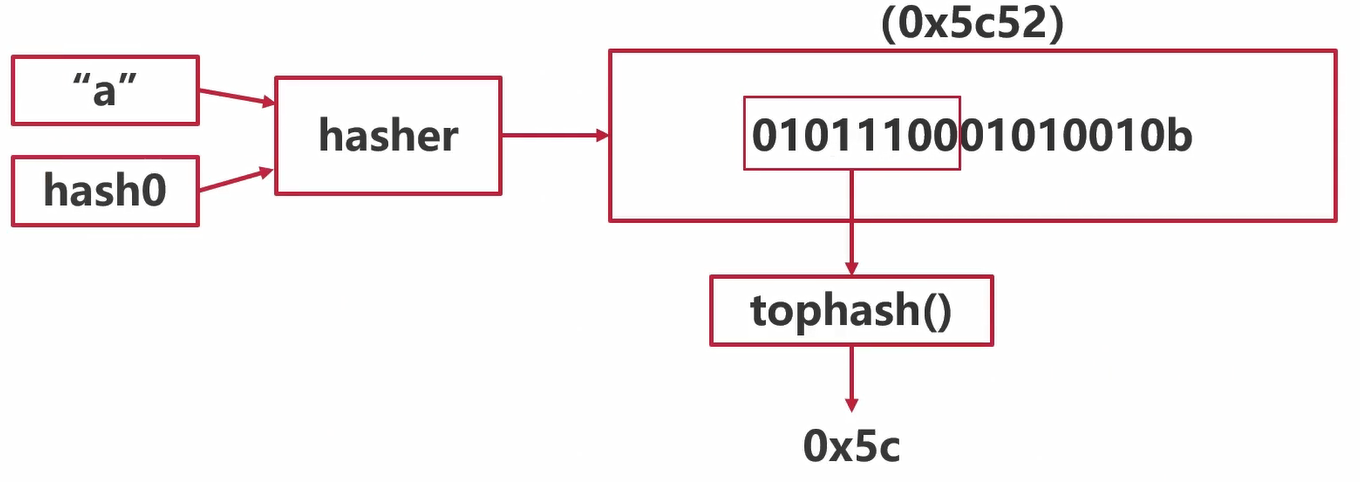
map的访问:计算tophash
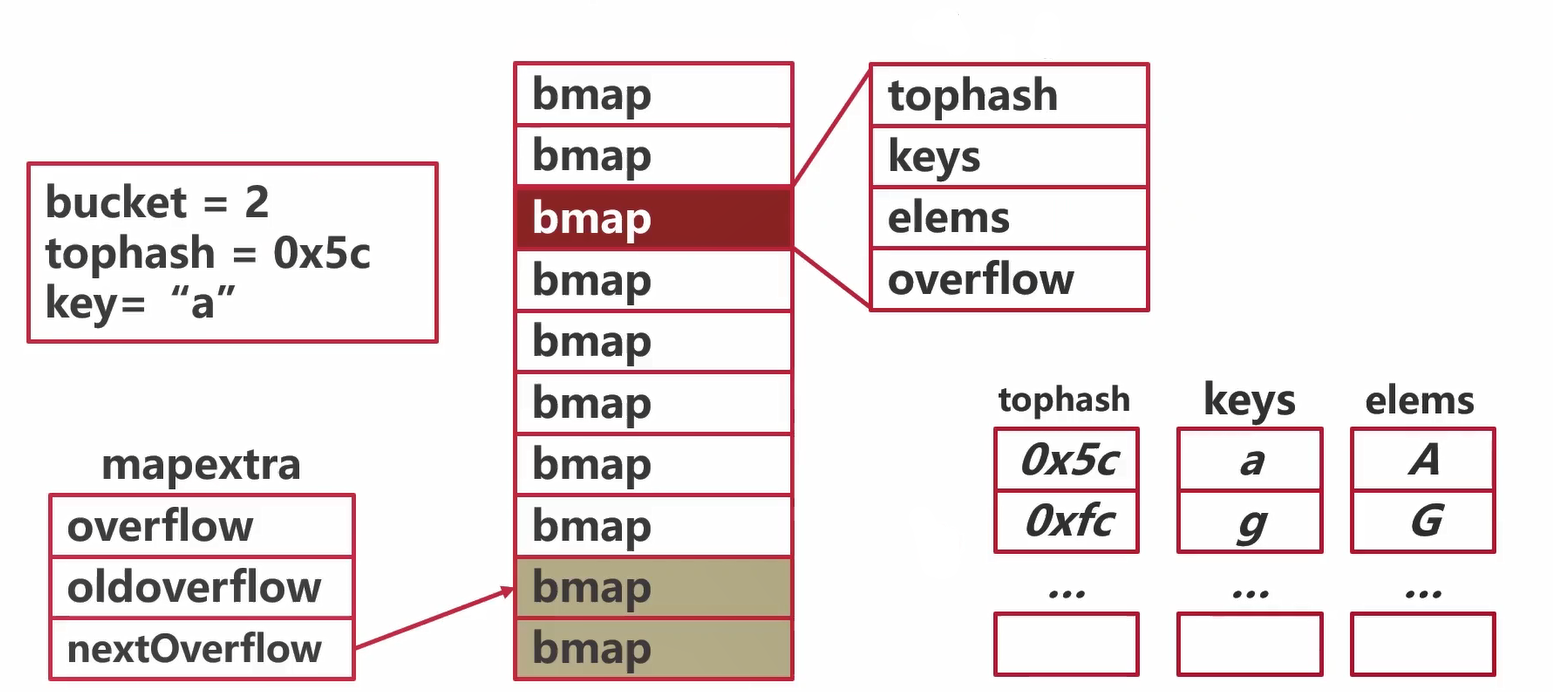
map的访问:匹配
可能遇到的特殊情况:
- 哈希碰撞比较厉害,hash的高八位是5c,但是key值hash之后不是5c,往后继续找5c,如果找遍这个tophash都没有找到其他的5c,去查看overflow溢出指针,如果有,说明这八个写满了,然后我们根据溢出指针指向的溢出桶,从溢出的桶中再去遍历,看能不能找到我们要的tophash。如果都没有表明查询的key值不存在在map当中。
map的写入

总结
- Go语言使用拉链实现了hashmap
- 每一个桶中存储键哈希的前八位(高八位,有助于快速遍历)
-
map为什么需要扩容?
哈希碰撞
map扩容
map溢出桶太多时会导致严重的性能下降
runtime.mapassign()可能会出发扩容的情况
等量扩容:数据不多但是溢出桶太多了(整理)
-
map扩容:Step 1
创建一组新桶
- oldbuckets指向原有的桶数组
- buckets指向新的桶数组
- map标记为扩容状态
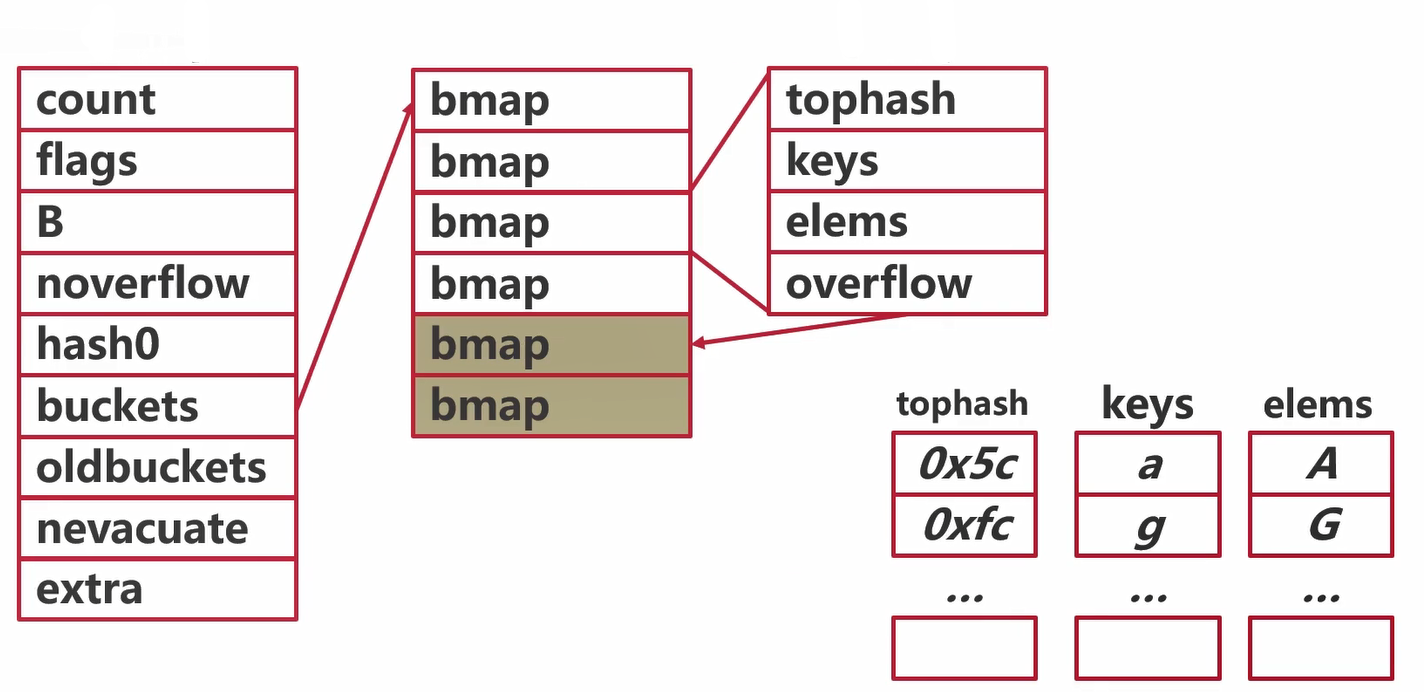
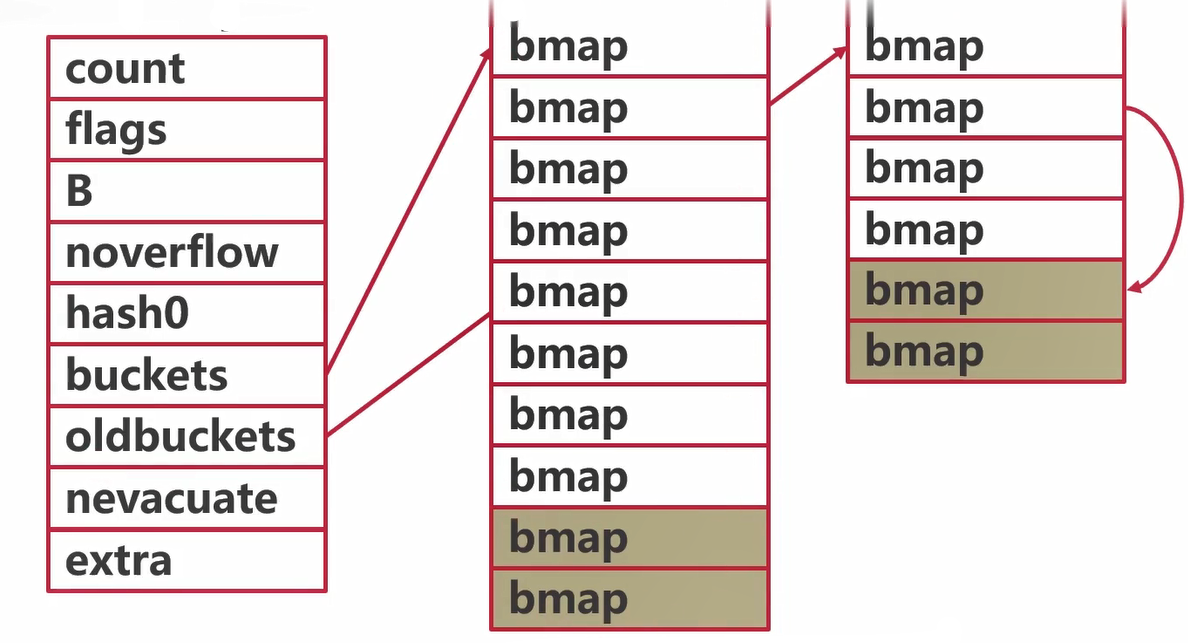
map扩容:Step 2
- 将所有的数据从旧桶驱逐到新桶
- 采用渐进式驱逐
- 每次操作一个旧桶,将旧桶数据驱逐到新桶
- 读取时不进行驱逐,只判断读取新桶还是旧桶
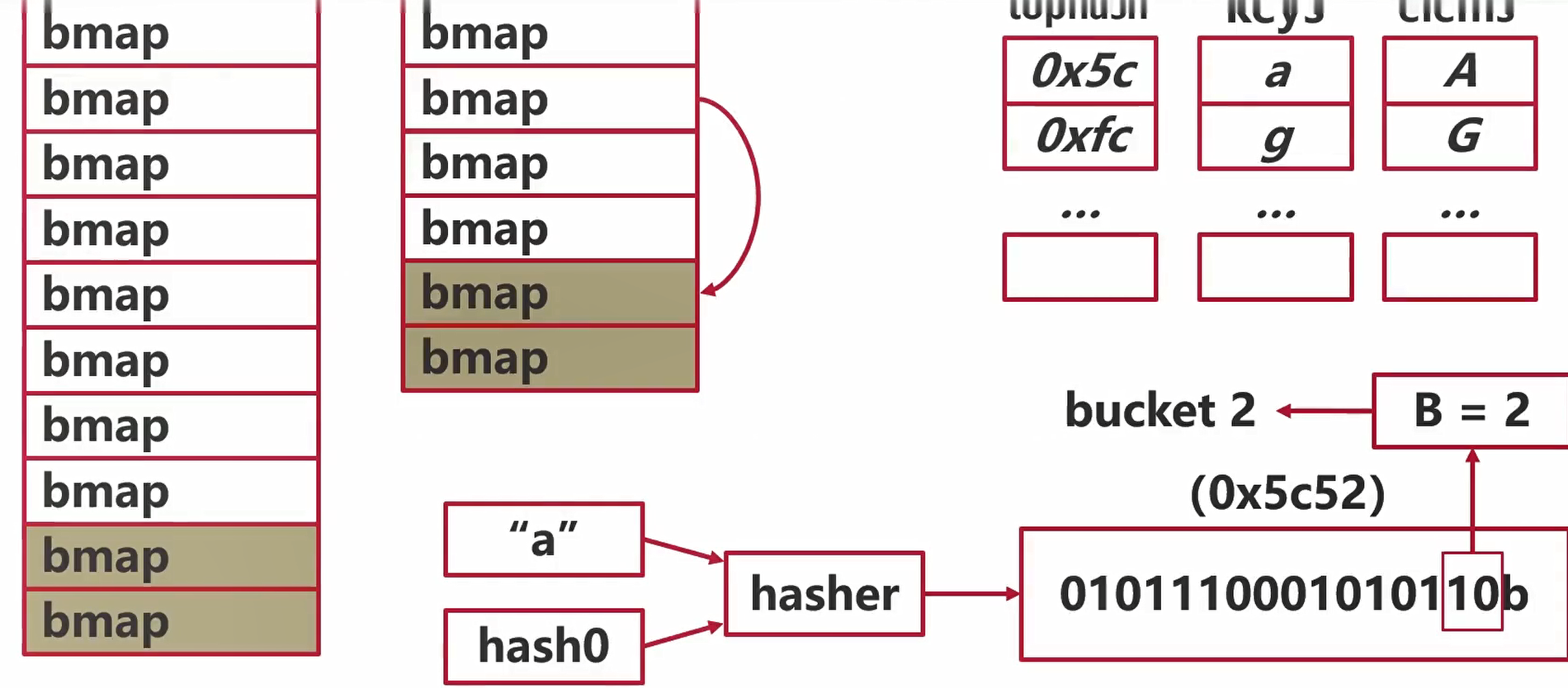
map扩容:Step 3
- 所有的旧桶驱逐完成后
- oldbuckets回收

总结
- 装载系数或者溢出桶的增加,会触发map扩容
- “扩容”可能并不是增加桶数,而是整理
-
怎么解决map的并发问题?
map的并发问题
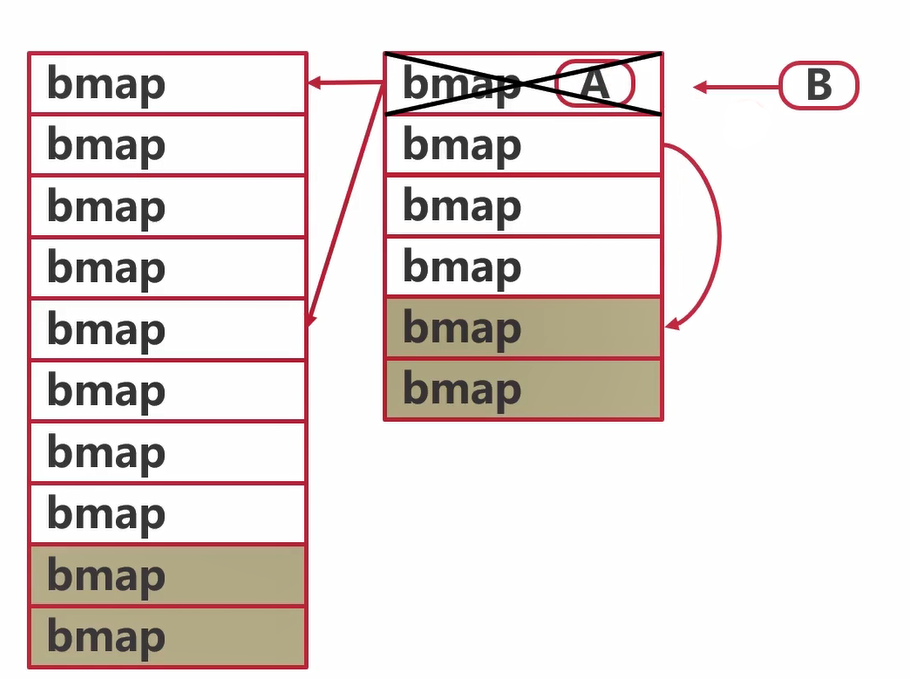
map的读写有并发问题
- A协程在桶中读数据时,B协程驱逐了这个桶
- A协程会读到错误的数据或者找不到数据 ```go package main
func main() { m := make(map[int]int) go func() { for { _ = m[1] } }()
go func() {for {m[2] = 2}}()select {}
}
<a name="jhzbP"></a>## map并发问题解决方案- 给map加锁(mutex)- 使用sync.Map<a name="MbgYY"></a>## sync.Map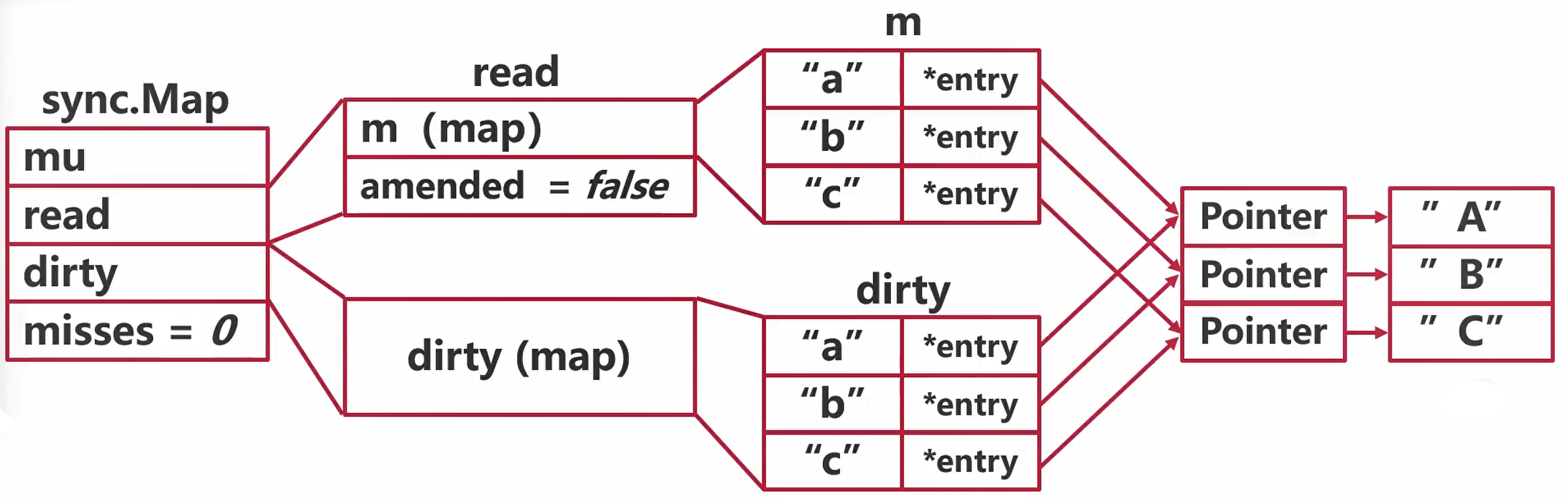```gotype Map struct {mu Mutex// read contains the portion of the map's contents that are safe for// concurrent access (with or without mu held).//// The read field itself is always safe to load, but must only be stored with// mu held.//// Entries stored in read may be updated concurrently without mu, but updating// a previously-expunged entry requires that the entry be copied to the dirty// map and unexpunged with mu held.read atomic.Value // readOnly// dirty contains the portion of the map's contents that require mu to be// held. To ensure that the dirty map can be promoted to the read map quickly,// it also includes all of the non-expunged entries in the read map.//// Expunged entries are not stored in the dirty map. An expunged entry in the// clean map must be unexpunged and added to the dirty map before a new value// can be stored to it.//// If the dirty map is nil, the next write to the map will initialize it by// making a shallow copy of the clean map, omitting stale entries.dirty map[any]*entry// misses counts the number of loads since the read map was last updated that// needed to lock mu to determine whether the key was present.//// Once enough misses have occurred to cover the cost of copying the dirty// map, the dirty map will be promoted to the read map (in the unamended// state) and the next store to the map will make a new dirty copy.misses int}// readOnly is an immutable struct stored atomically in the Map.read field.type readOnly struct {//*entry -> unsafe.Pointerm map[any]*entryamended bool // true if the dirty map contains some key not in m.}type entry struct {// p points to the interface{} value stored for the entry.//// If p == nil, the entry has been deleted, and either m.dirty == nil or// m.dirty[key] is e.//// If p == expunged, the entry has been deleted, m.dirty != nil, and the entry// is missing from m.dirty.//// Otherwise, the entry is valid and recorded in m.read.m[key] and, if m.dirty// != nil, in m.dirty[key].//// An entry can be deleted by atomic replacement with nil: when m.dirty is// next created, it will atomically replace nil with expunged and leave// m.dirty[key] unset.//// An entry's associated value can be updated by atomic replacement, provided// p != expunged. If p == expunged, an entry's associated value can be updated// only after first setting m.dirty[key] = e so that lookups using the dirty// map find the entry.p unsafe.Pointer // *interface{}}
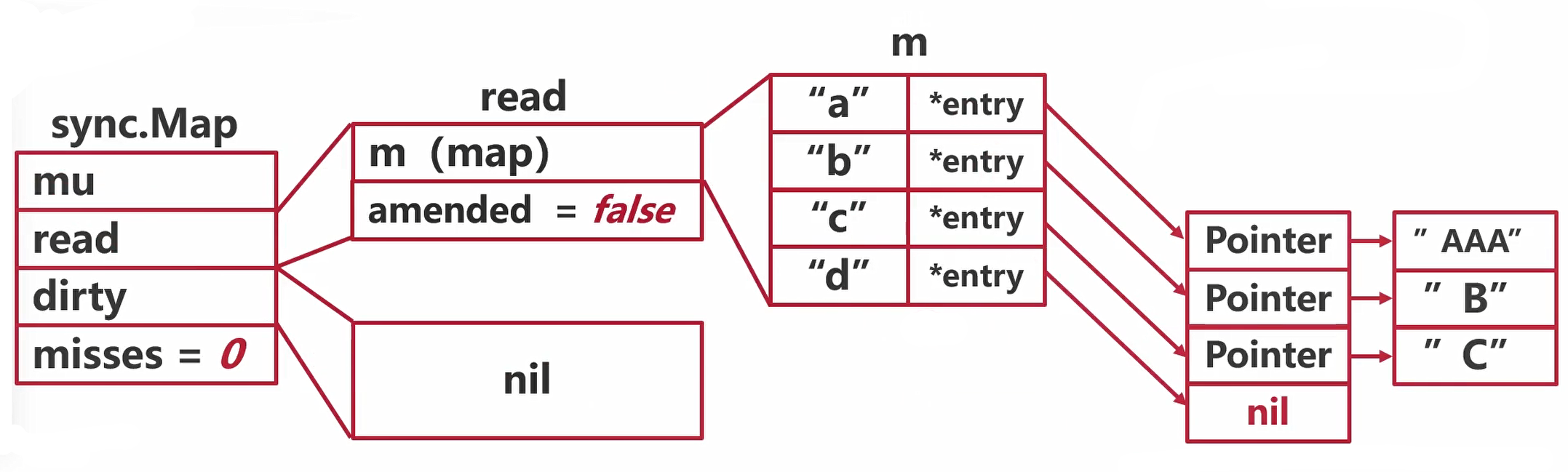
sync.Map正常读写
“a” -> “AAA”
read->m(map)->hash->高八位、找桶号(B)-> buckets->bmap->[tophash、key、elems、overflow]->找到值
"a"->*entry->Pointer->value->”A”
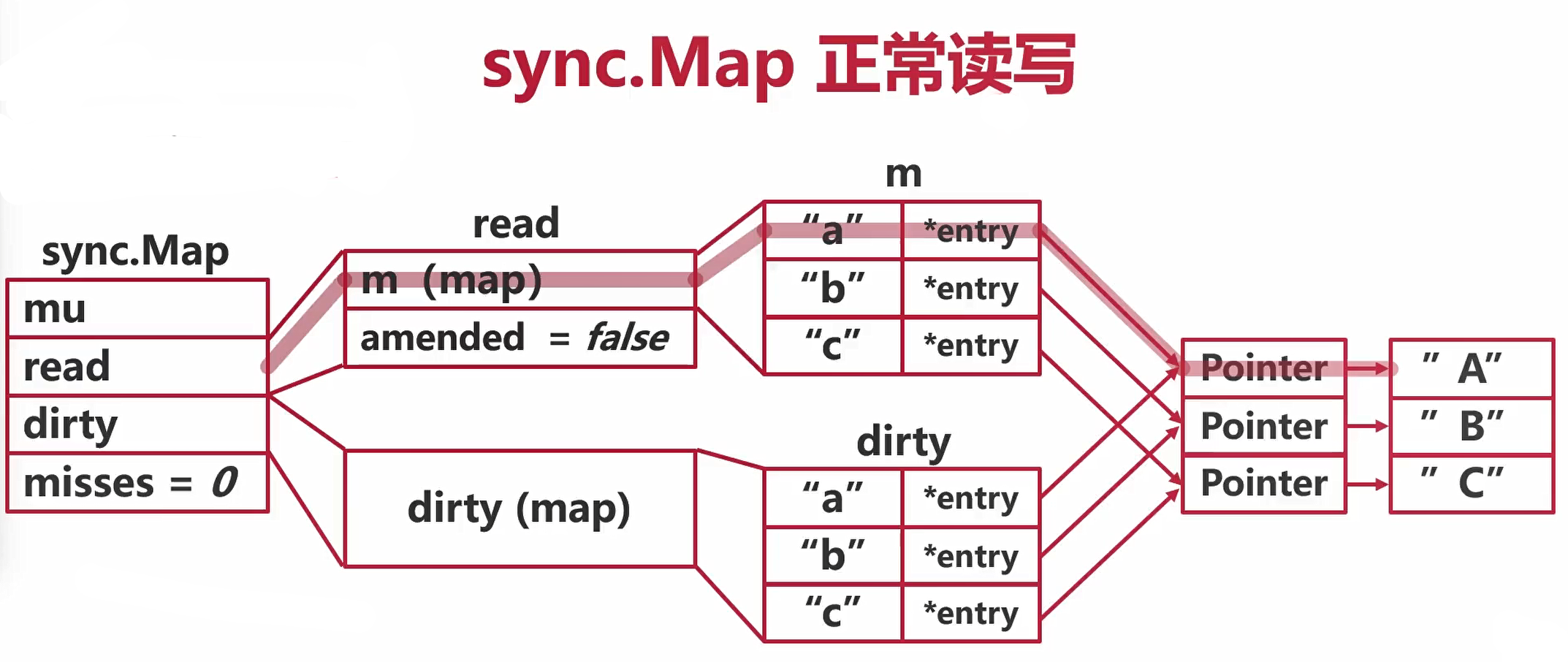
sync.Map追加
“d” -> “D”

read->m(map)->没找到->mu加锁->锁住dirty(map)->上锁以后操作dirty(map)->同时只能有一个协程去操作dirty(map)->给dirty(map)做追加->上方的amended的值置为
**true**

Sync.Map追加后读写

read->m(map)->没查找到
"d"->状态量amended = true->读dirty(map)->读取到->misses++ 当misses追加到len(dirty)
Sync.Map dirty提升

dirty变成新的read map

misses置0

amended =
falsenil->dirty(map)后面如果有追加会重建这个dirty(map)
Sync.Map 删除
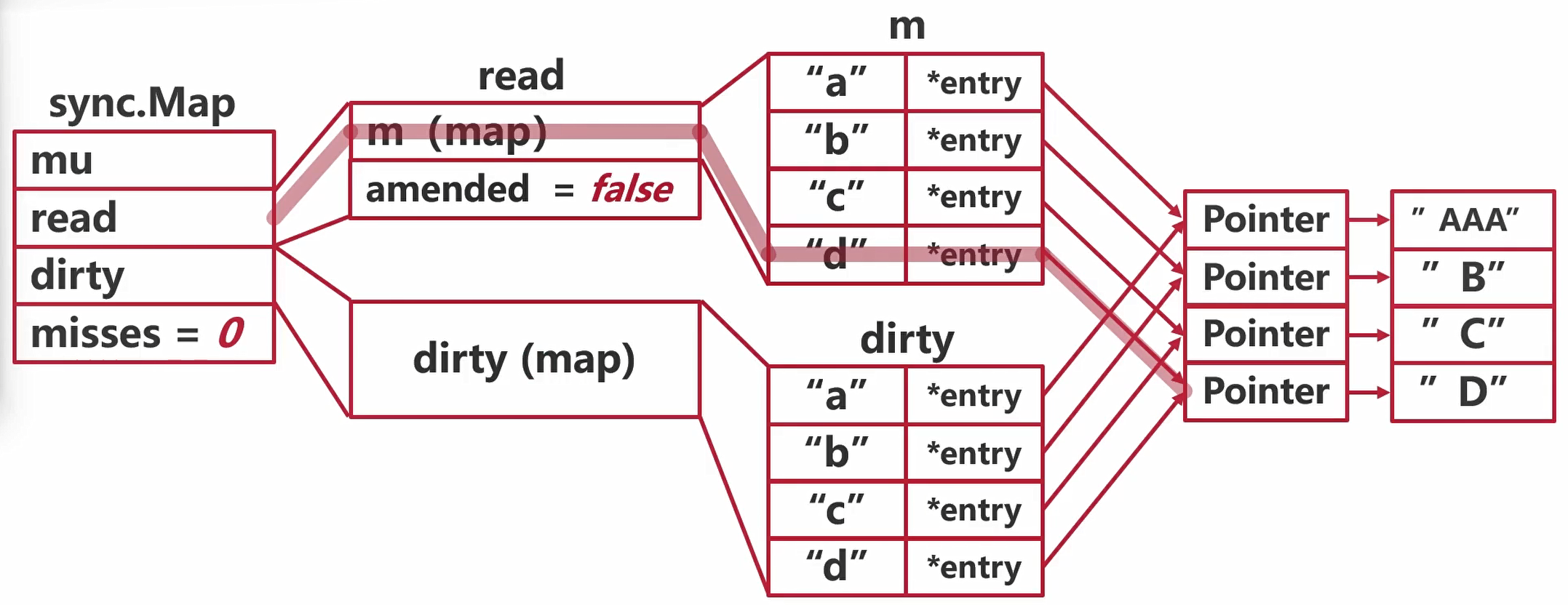

Sync.Map 追加后删除
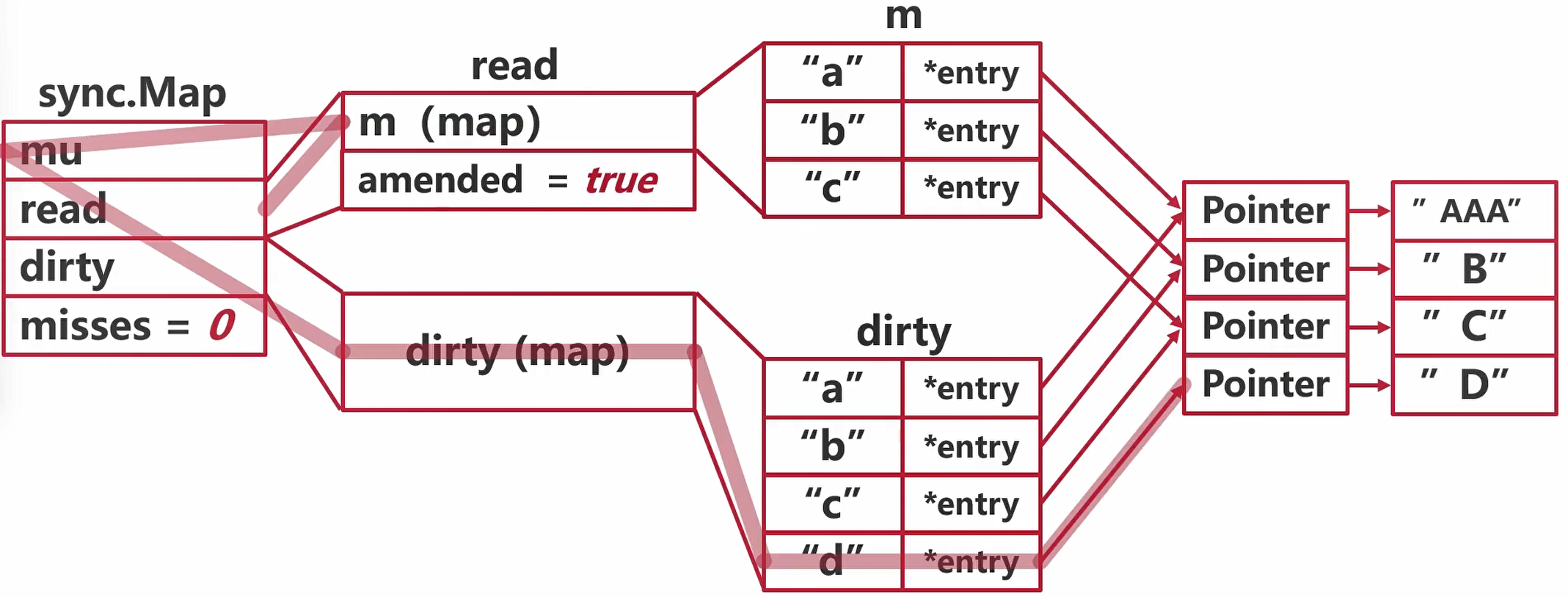

Sync.Map 删除后提升dirty
不重建新的
"d"expunged擦除、删去

普通读写和追加分离
普通的读写不涉及扩容,它一涉及扩容就要有并发问题,所以说普通读写不涉及扩容走上上面的read map,涉及扩容走下面dirty map,走下面的时候要加锁,保证只有一个协程能同时走下边,这样的话就能避免map扩容的并发问题,走完下面之后,你还会出现下面和上面不一致的问题,通过查看amended和misses信号量,来确定是否需要dirty map提升。
总结
- map在扩容时会有并发问题
- sync.Map使用两个map,分离了扩容问题
- 不会引发扩容的操作(查、改、删)使用read map
- 可能引发扩容的操作(新增)使用dirty map
sync.Map在写多读多追加少的情况下,sync.Map性能会好
接口:隐式更好还是显式更好?
Go隐式接口特点
只要实现了接口的全部方法,就是自动实现接口
- 可以在不修改代码的情况下抽象出新的接口 ```go type iface struct { tab *itab data unsafe.Pointer }
type itab struct { inter interfacetype _type type hash uint32 // copy of _type.hash. Used for type switches. [4]byte fun [1]uintptr // variable sized. fun[0]==0 means _type does not implement inter. }
```gopackage mainimport ("fmt")type Car interface {Driver()}type TrafficTool interface {Driver()Run()}type Truck struct {Model string}func (t Truck) Driver() {fmt.Println(t.Model)}func main() {//1.一个接口的值在底层是如何表示的//c的底层表示是iface//data 指针指向的才是我们新建的结构体var c Car = Truck{}truck := c.(Truck)//tool := c.(TrafficTool)fmt.Printf("%p\n", c)fmt.Printf("%+p\n", truck)//fmt.Printf("%p\n", tool)switch c.(type) {//case Truck:// fmt.Println("Truck")//case Car:// fmt.Println("Car")case TrafficTool:fmt.Println("TrafficTool")}}
接口值的底层表示
- 接口数据使用runtime.iface表示
- iface记录了数据的地址
-
类型断言
类型断言是一个使用在接口值上的操作
- 可以将接口值转换为其他类型值(实现或者兼容接口)
- 可以配合switch进行类型判断
软式的类型转化结构体和指针实现接口
| | 结构体实现接口 | 结构体指针实现接口 | | —- | —- | —- | | 结构体初始化变量 | 通过 | 不通过 | | 结构体指针初始化变量 | 通过 | 通过 |
空接口值
- runtime.eface结构体
- 空接口底层不是普通接口
-
空接口的用途
空接口的最大用途是作为任意类型的函数入参
-
总结
Go的隐式接口更加方便系统的扩展和重构
- 结构体和指针都可以实现接口
-
nil、空接口、空结构体有什么区别?
nil
nil是空,并不一定是
"空指针"- nil是6种类型的”零值”
-
空结构体
空结构体是Go中非常特殊的类型
- 空结构体的值不是nil
-
空接口
空接口不一定是”nil 接口”
总结
内存对齐是如何优化程序效率的?
总结
本章小结

若有收获,就点个赞吧
0 人点赞
