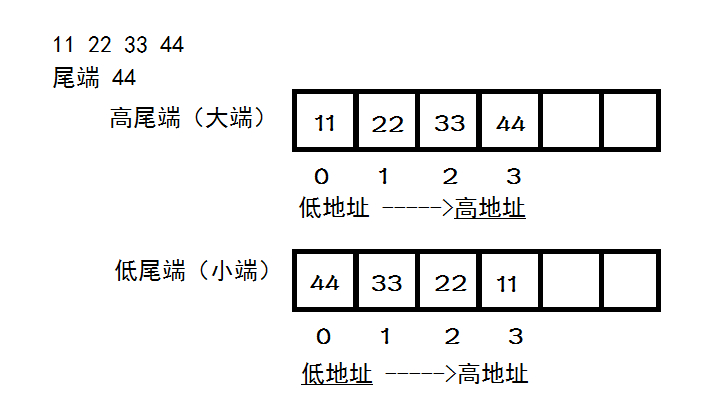
- 大端模式:数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中。
- 小端模式:数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中。
- 所以只有同时拥有多个字节构成的才有大小端概念,比如int、short、long等同时多个字节的类型,而char,或者字符串是没有这个概念的
- 换个说法就是大小端决定了多字节数据在系统中的读取、存储顺序,若实际的数据存储(如从报文中获取的数据)与当前系统的顺序不一致,必然将导致错误
- 若自己处理大小端问题时,一定不能以默认的指针偏移来进行处理(比如解析IP,如下示例),除非引入了一些大小端的编译宏做了控制,否则就以取值的方式来进行操作,因为如何取值就是系统自身决定的
/* 主机序IP打印(取值计算,无关大小端),以 %d.%d.%d.%d的形式 */#define BYOD_IPV4_STR(HOST_IPV4) \(HOST_IPV4 >> 24) & 0xFF, \(HOST_IPV4 >> 16) & 0xFF, \(HOST_IPV4 >> 8) & 0xFF, \HOST_IPV4 & 0xFF
在进行网络通信时是否需要进行字节序转换?
相同字节序的平台在进行网络通信时可以不进行字节序转换,但是跨平台进行网络数据通信时必须进行字节序转换。
原因如下:网络协议规定接收到得第一个字节是高字节,存放到低地址,所以发送时会首先去低地址取数据的高字节。
小端模式的多字节数据在存放时,低地址存放的是低字节,而被发送方网络协议函数发送时会首先去低地址取数据(想要取高字节,真正取得是低字节),接收方网络协议函数接收时会将接收到的第一个字节存放到低地址(想要接收高字节,真正接收的是低字节),所以最后双方都正确的收发了数据。
而相同平台进行通信时,如果双方都进行转换最后虽然能够正确收发数据,但是所做的转换是没有意义的,造成资源的浪费。
而不同平台进行通信时必须进行转换,不转换会造成错误的收发数据,字节序转换函数会根据当前平台的存储模式做出相应正确的转换,如果当前平台是大端,则直接返回不进行转换,如果当前平台是小端,会将接收到得网络字节序进行转换。
编码时正确的处理流程**
- 首先仅有多字节的数据才有大小端的概念
- 从网络数据中接受处理时,必须调用转换接口(如 ntohl 把unsigned long类型从网络序转换到主机序 ),转换为主机序再处理
- 有数据需要发送到网络中时,必须调用转换接口(如 htonl 把unsigned long类型从主机序转换到网络序),转换为网络序再发送
ntohl 或 htonl 等转换接口,会自动判断是否需要进行大小端的转换**
转换接口
网络字节顺序是TCP/IP中规定好的一种数据表示格式,它与具体的CPU类型、操作系统等无关,从而可以保证数据在不同主机之间传输时能够被正确解释。网络字节顺序采用big endian排序方式。
为了进行转换 bsd socket提供了转换的函数 有下面四个:16位数据
- ntohs 把unsigned short类型从网络序转换到主机序
- htons 把unsigned short类型从主机序转换到网络序
- 32位数据
//也可以直接操作指针赋值 int IntChangeBytes(int value) { int tmp_value; uint8_t index_1, index_2;
index_1 = (uint8_t *)&tmp_value;index_2 = (uint8_t *)&value;*index_1 = *(index_2+3);*(index_1+1) = *(index_2+2);*(index_1+2) = *(index_2+1);*(index_1+3) = *index_2;return tmp_value;
} ```

若有收获,就点个赞吧
0 人点赞
