https://my.oschina.net/mlgb/blog/495770
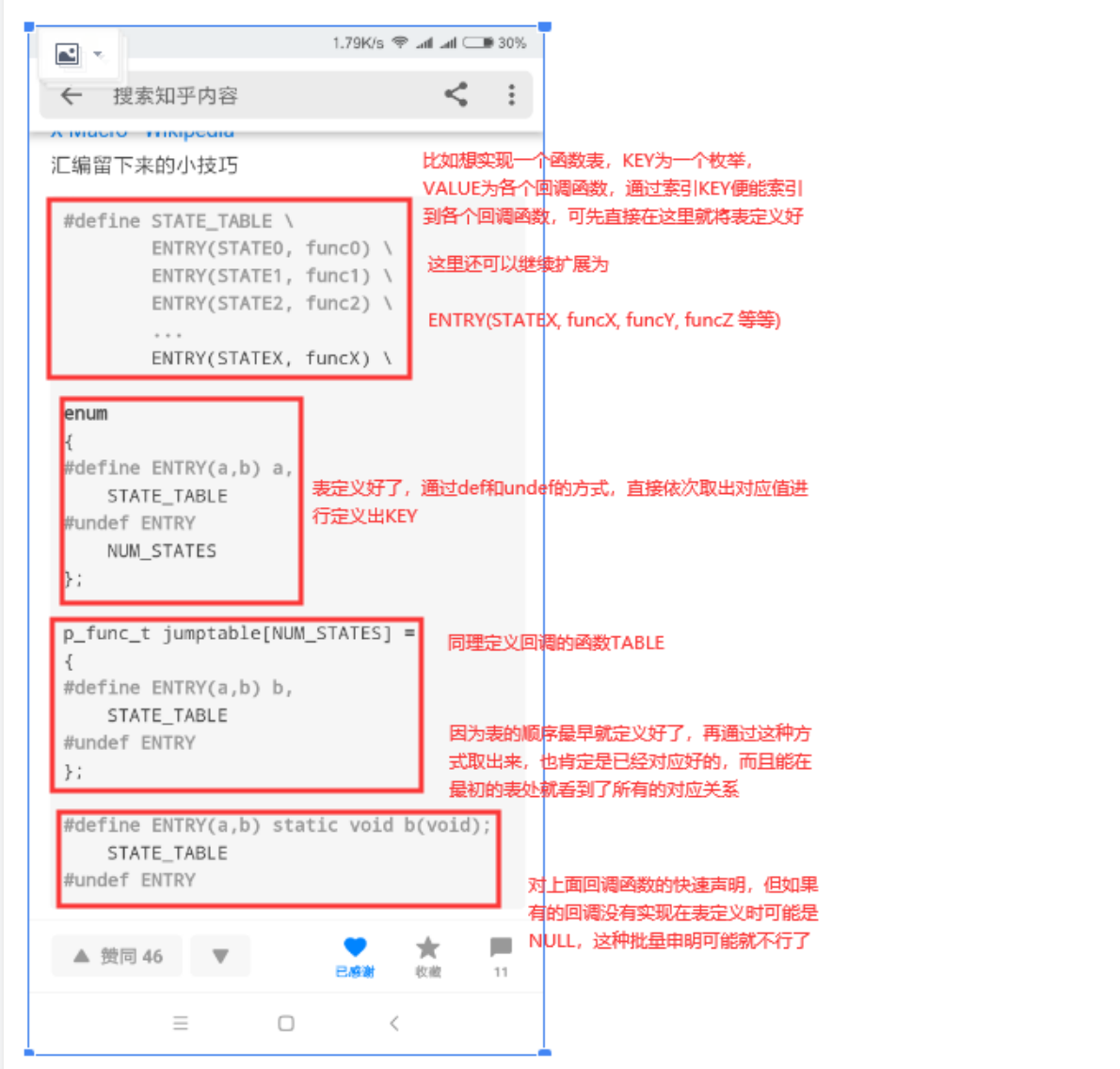
也即通过 #define 和 #undef 不断重新定义宏,然后分别取出相应的内容进行使用,便可方便使关联的信息在一起进行关联定义(定义成一个表,特别直观),一般就可用在头文件中进行大批量的信息注册,函数表注册等等
大量的函数表定义的话,也可以采用 函数表定义的形式,利用结构体来限定格式,也是也可以的,达到的目的都是一样,一些简单的使用X宏会更方便点,比较复杂的还是结构体形式会更集中一点
有些时候我们在程序中定义一些错误码时,常常会有一个随之对应的获取错误信息的函数。比如这样:
enum ErrorCode{ERROR_0,ERROR_1,ERROR_2,ERROR_3};const char* get_error_info(enum ErrorCode error_code){switch(error_code){case ERROR_0:return "error info 0";case ERROR_1:return "error info 1";case ERROR_2:return "error info 2";case ERROR_3:return "error info 3";}return "";}
还有一种方法是这样:
enum{ERROR_0,ERROR_1,ERROR_2,ERROR_3};const char* error_info[] ={"error info 0","error info 1","error info 2","error info 3"};
但以上这种方式若增加了ERROR_4后没有在error_info中增加响应内容,则造成数组下标越界!
于是有人创造了X宏的方式,这利用了C语言本身的预处理机制,可以方便的将相关联信息集中定义在一起
test.h
#ifndef _TEST_H_#define _TEST_H_// 定义表#define NUMBER \X(One,"One") \X(Two,"Two") \X(Three,"Three") \#define X(a,b) a,enum Number { NUMBER };#undef Xextern const char *NumberStrings[];#endif // _TEST_H_
test.c
#include "test.h"#define X(a, b) b,const char *NumberStrings[] = {NUMBER};#undef X
使用以上方法的时候就可以在头文件中扩展NUMBER宏的枚举和关联内容的定义。
这个技巧不局限于枚举与字符串的关联,也可以是枚举与任何类型的关联内容(比如函数表,比如注册ACL字段中字段的函数表,给每个字段一个枚举值,定义其字段名称,字段分配回调、释放回调、处理回调等等,统一关联在一张表中,极其方便直观)。

若有收获,就点个赞吧
0 人点赞
