09 | Java线程(上):Java线程的生命周期
通用生命周期
通用的线程生命周期基本上可以用下图这个“五态模型”来描述。这五态分别是:初始状态、可运行状态、运行状态、休眠状态和终止状态。
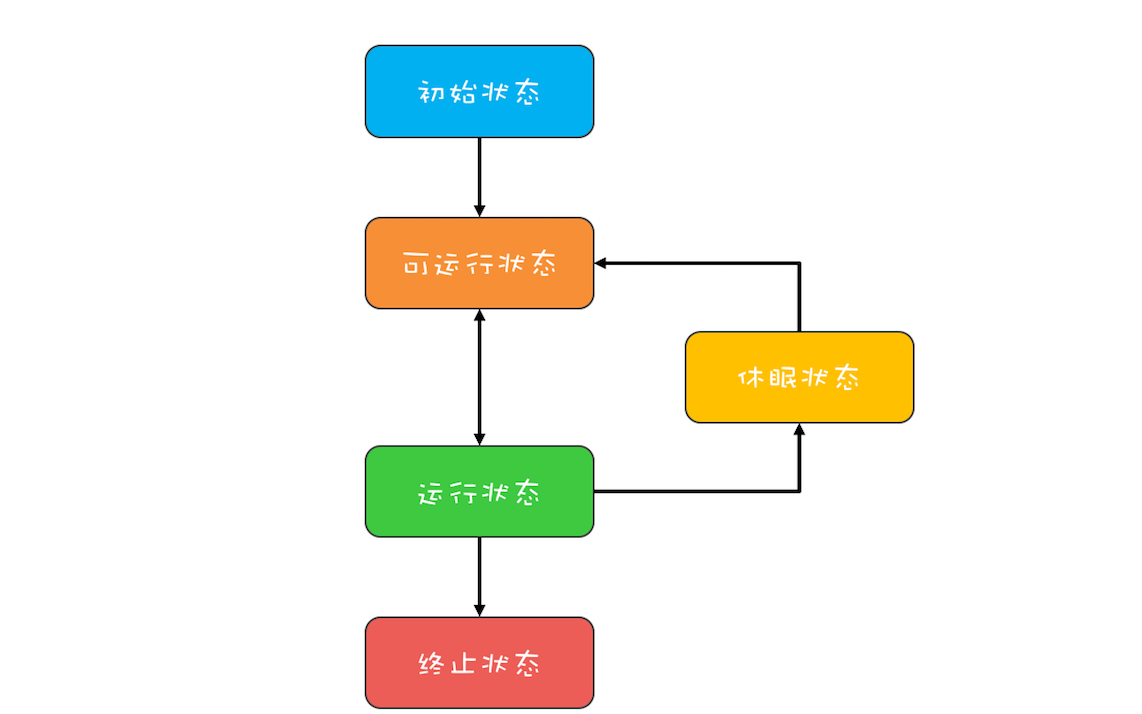
- 初始状态,指的是线程已经被创建,但是还不允许分配 CPU 执行。这个状态属于编程语言特有的,不过这里所谓的被创建,仅仅是在编程语言层面被创建,而在操作系统层面,真正的线程还没有创建。
- 可运行状态,指的是线程可以分配 CPU 执行。在这种状态下,真正的操作系统线程已经被成功创建了,所以可以分配 CPU 执行。
- 当有空闲的 CPU 时,操作系统会将其分配给一个处于可运行状态的线程,被分配到 CPU 的线程的状态就转换成了运行状态。
- 运行状态的线程如果调用一个阻塞的 API(例如以阻塞方式读文件)或者等待某个事件(例如条件变量),那么线程的状态就会转换到休眠状态,同时释放 CPU 使用权,休眠状态的线程永远没有机会获得 CPU 使用权。当等待的事件出现了,线程就会从休眠状态转换到可运行状态。
- 线程执行完或者出现异常就会进入终止状态,终止状态的线程不会切换到其他任何状态,进入终止状态也就意味着线程的生命周期结束了。
Java 中线程的生命周期
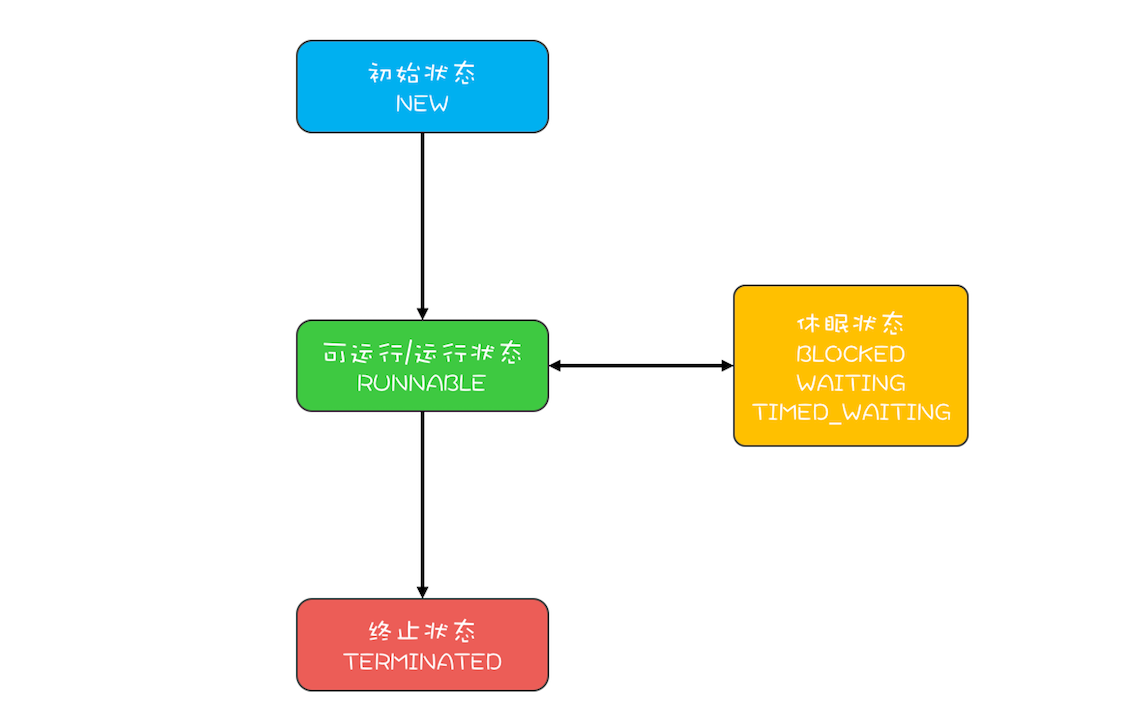
不同编程语言会有简化合并和细化拆分,Java语言把可运行状态和运行状态合并了(RUNNABLE),将休眠状态细化了(BLOCK、WAITING、TIMED_WAITING)
Java 语言中线程共有六种状态,分别是:
- NEW(初始化状态)
- RUNNABLE(可运行 / 运行状态)
- BLOCKED(阻塞状态)
- WAITING(无时限等待)
- TIMED_WAITING(有时限等待)
- TERMINATED(终止状态)
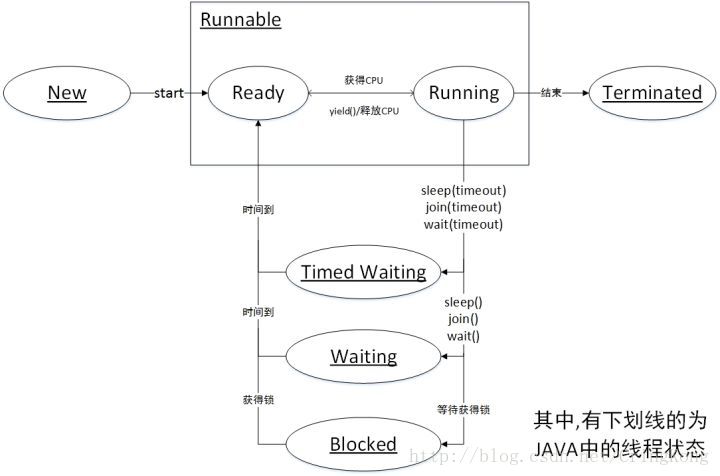
RUNNABLE 与 BLOCKED 的状态转换
只有一种场景会触发这种转换,就是线程等待 synchronized 的隐式锁。而当等待的线程获得 synchronized 隐式锁时,就又会从 BLOCKED 转换到 RUNNABLE 状态。
RUNNABLE 与 WAITING 的状态转换
- wait()
- Thread.join(),join() 是一种线程同步方法,例如有一个线程对象 thread A,当调用 A.join() 的时候,执行这条语句的线程会等待 thread A 执行完,而等待中的这个线程,其状态会从 RUNNABLE 转换到 WAITING。当线程 thread A 执行完,原来等待它的线程又会从 WAITING 状态转换到 RUNNABLE。
LockSupport.park()。调用 LockSupport.park() 方法,当前线程会阻塞,线程的状态会从 RUNNABLE 转换到 WAITING。调用 LockSupport.unpark(Thread thread) 可唤醒目标线程,目标线程的状态又会从 WAITING 状态转换到 RUNNABLE。
RUNNABLE 与 TIMED_WAITING 的状态转换
调用带超时参数的 Thread.sleep(long millis) 方法;
- 获得 synchronized 隐式锁的线程,调用带超时参数的 Object.wait(long timeout) 方法;
- 调用带超时参数的 Thread.join(long millis) 方法;
- 调用带超时参数的 LockSupport.parkNanos(Object blocker, long deadline) 方法;
- 调用带超时参数的 LockSupport.parkUntil(long deadline) 方法。
从 NEW 到 RUNNABLE 状态
Java 刚创建出来的 Thread 对象就是 NEW 状态,而创建 Thread 对象主要有两种方法。一种是继承 Thread 对象,重写 run() 方法。示例代码如下:
另一种是实现 Runnable 接口,重写 run() 方法,并将该实现类作为创建 Thread 对象的参数。示例代码如下:// 自定义线程对象class MyThread extends Thread {public void run() {// 线程需要执行的代码......}}// 创建线程对象MyThread myThread = new MyThread();
从 NEW 状态转换到 RUNNABLE 状态很简单,只要调用线程对象的 start() 方法就可以了,示例代码如下:// 实现Runnable接口class Runner implements Runnable {@Overridepublic void run() {// 线程需要执行的代码......}}// 创建线程对象Thread thread = new Thread(new Runner());
MyThread myThread = new MyThread();// 从NEW状态转换到RUNNABLE状态myThread.start();
从 RUNNABLE 到 TERMINATED 状态
线程执行完 run() 方法后,会自动转换到 TERMINATED 状态,当然如果执行 run() 方法的时候异常抛出,也会导致线程终止。有时候我们需要强制中断 run() 方法的执行,例如 run() 方法访问一个很慢的网络,我们等不下去了,想终止怎么办呢?Java 的 Thread 类里面倒是有个 stop() 方法,不过已经标记为 @Deprecated,所以不建议使用了。正确的姿势其实是调用 interrupt() 方法。
stop() 和 interrupt() 方法的主要区别
stop() 方法会真的杀死线程,不给线程喘息的机会,如果线程持有 ReentrantLock 锁,被 stop() 的线程并不会自动调用 ReentrantLock 的 unlock() 去释放锁,那其他线程就再也没机会获得ReentrantLock 锁。
而 interrupt() 方法就温柔多了,interrupt() 方法仅仅是通知线程,线程有机会执行一些后续操作,同时也可以无视这个通知。被 interrupt 的线程,是怎么收到通知的呢?一种是异常,另一种是主动检测(非抛出InterruptedException来响应中断的方法只是设置了一个标识位而已,处于阻塞状态的线程,没有办法在应用程序中执行代码主动检测,只能在阻塞的方法中处理中断信号)
当线程 A 处于 WAITING、TIMED_WAITING 状态时,如果其他线程调用线程 A 的 interrupt() 方法,会使线程 A 返回到 RUNNABLE 状态,同时线程 A 的代码会触发 InterruptedException 异常。上面我们提到转换到 WAITING、TIMED_WAITING 状态的触发条件,都是调用了类似 wait()、join()、sleep() 这样的方法,我们看这些方法的签名,发现都会 throws InterruptedException 这个异常。这个异常的触发条件就是:其他线程调用了该线程的 interrupt() 方法。
为什么java里的线程可以在阻塞的时候捕获中断异常并处理? 当Java的某个线程处于可中断的阻塞状态时,你用另一个线程调用该线程的interrupt()方法时,JVM会使该线程离开阻塞状态,并抛出一个异常。既然该线程已经离开阻塞状态,自然要参与到对CPU时间的争夺中,当获取到CPU时间时自然可以处理该异常。
Java线程和操作系统线程关系
课后思考题
下面代码的本意是当前线程被中断之后,退出while(true),你觉得这段代码是否正确呢?
Thread th = Thread.currentThread();while(true) {if(th.isInterrupted()) {break;}// 省略业务代码无数try {Thread.sleep(100);}catch (InterruptedException e){e.printStackTrace();}}
可能出现无限循环,线程在sleep期间被打断了,抛出这个异常会清除当前线程的中断标识,所以isInterrupted()返回的还是false。应该在catch中重置标志位:Thread.currentThread().interrupt();
10 | Java线程(中):创建多少线程才是合适的?
为什么要使用多线程?
使用多线程的主要目的是为了降低延迟、提高吞吐量。在并发编程领域,提升性能本质上就是提升硬件的利用率,再具体点来说,就是提升 I/O 的利用率和 CPU 的利用率。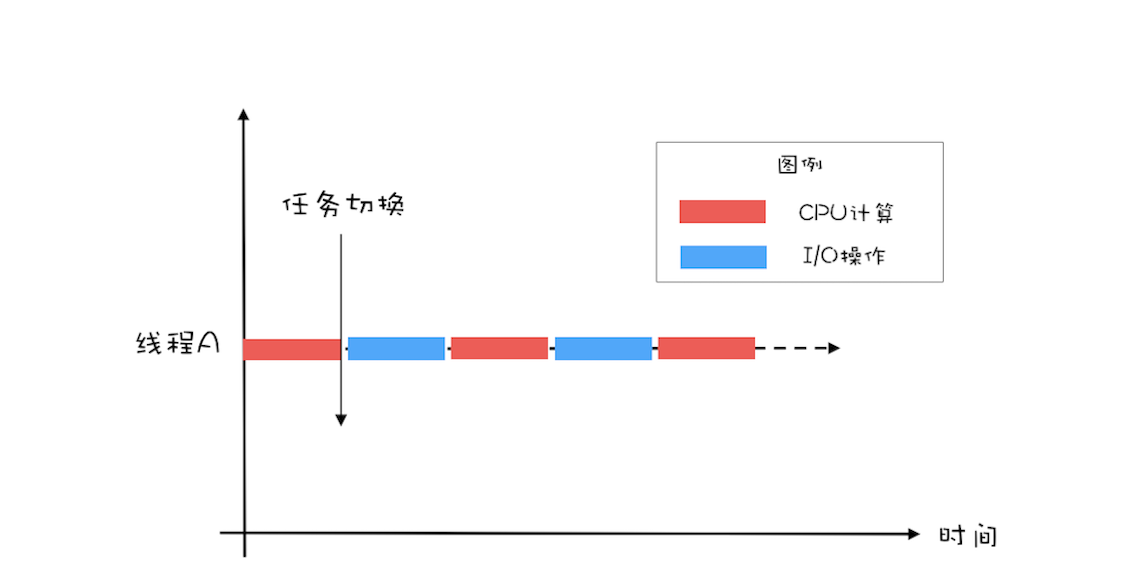 单线程执行示意图
单线程执行示意图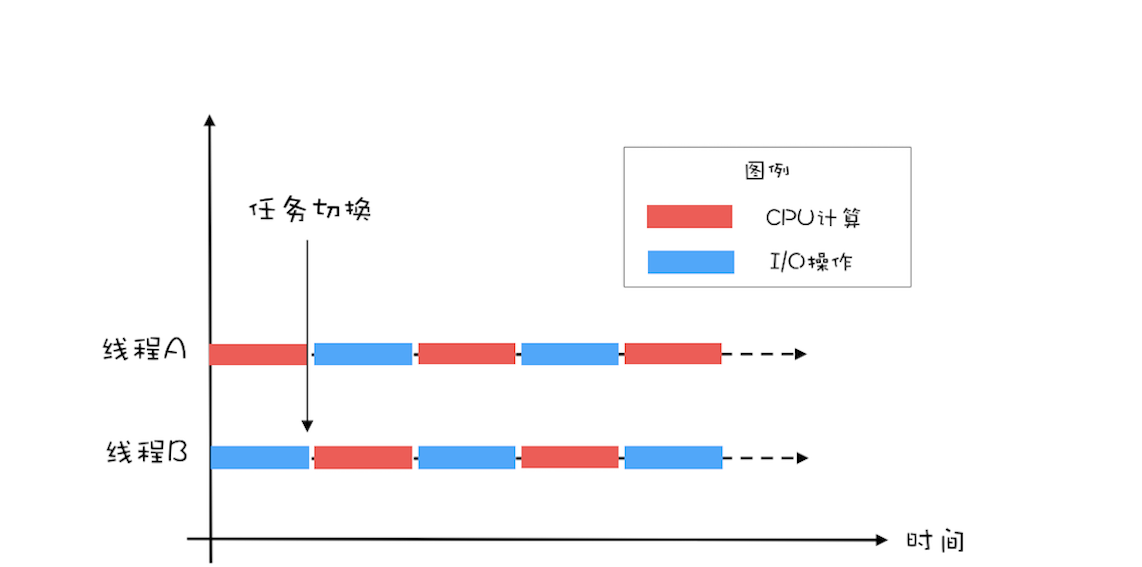 二线程执行示意图,将 CPU 的利用率和 I/O 设备的利用率都提升到了 100%
二线程执行示意图,将 CPU 的利用率和 I/O 设备的利用率都提升到了 100%
创建多少线程合适?
I/O 密集型程序和 CPU 密集型程序,计算最佳线程数的方法是不同的。
- 对于 CPU 密集型计算,多线程本质上是提升多核 CPU 的利用率,所以对于一个 4 核的 CPU,每个核一个线程,理论上创建 4 个线程就可以了,再多创建线程也只是增加线程切换的成本。所以,对于 CPU 密集型的计算场景,理论上“线程的数量 =CPU 核数”就是最合适的。不过在工程上,线程的数量一般会设置为“CPU 核数 +1”
- 对于 I/O 密集型的计算场景,最佳线程数 =CPU 核数 * [ 1 +(I/O 耗时 / CPU 耗时)]
**
如何测试IO/CPU 这个耗时比例
比较简单的工具就是apm了
摘录自评论:
个人觉得公式话性能问题有些不妥,定性的io密集或者cpu密集很难在定量的维度上反应出性能瓶颈,而且公式上忽略了线程数增加带来的cpu消耗,性能优化还是要定量比较好,这样不会盲目,比如io已经成为了瓶颈,增加线程或许带来不了性能提升,这个时候是不是可以考虑用cpu换取带宽,压缩数据,或者逻辑上少发送一些。最后一个问题,我的答案是大部分应用环境是合理的,老师也说了是积累了一些调优经验后给出的方案,没有特殊需求,初始值我会选大家都在用伪标准
11 | Java线程(下):为什么局部变量是线程安全的?
局部变量存哪里?
例如,有三个方法 A、B、C,他们的调用关系是 A->B->C(A 调用 B,B 调用 C),在运行时,会构建出下面这样的调用栈。每个方法在调用栈里都有自己的独立空间,称为栈帧,每个栈帧里都有对应方法需要的参数和返回地址。当调用方法时,会创建新的栈帧,并压入调用栈;当方法返回时,对应的栈帧就会被自动弹出。也就是说,栈帧和方法是同生共死的。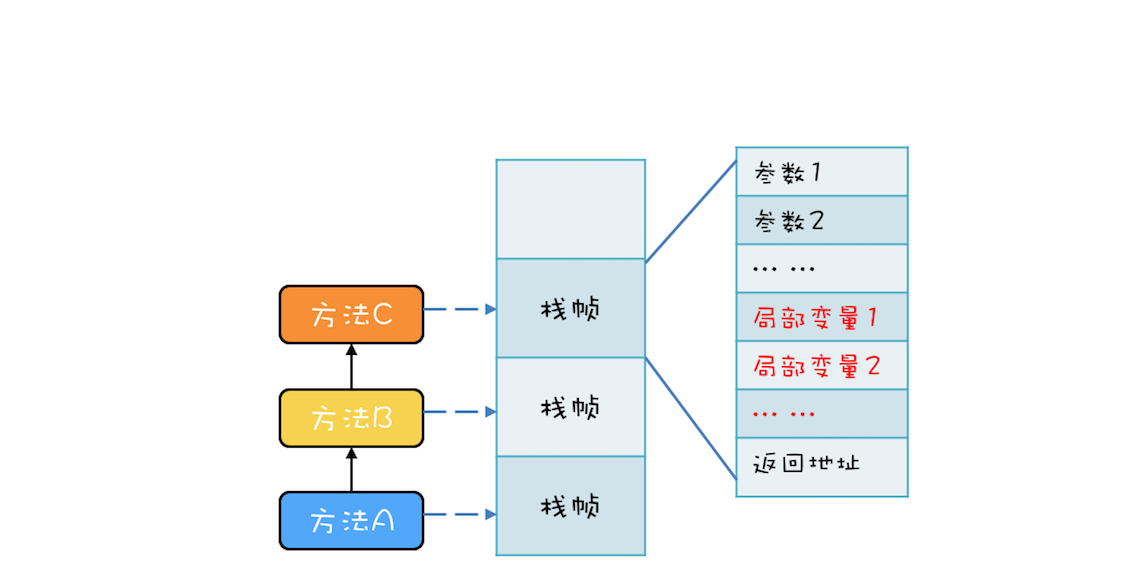
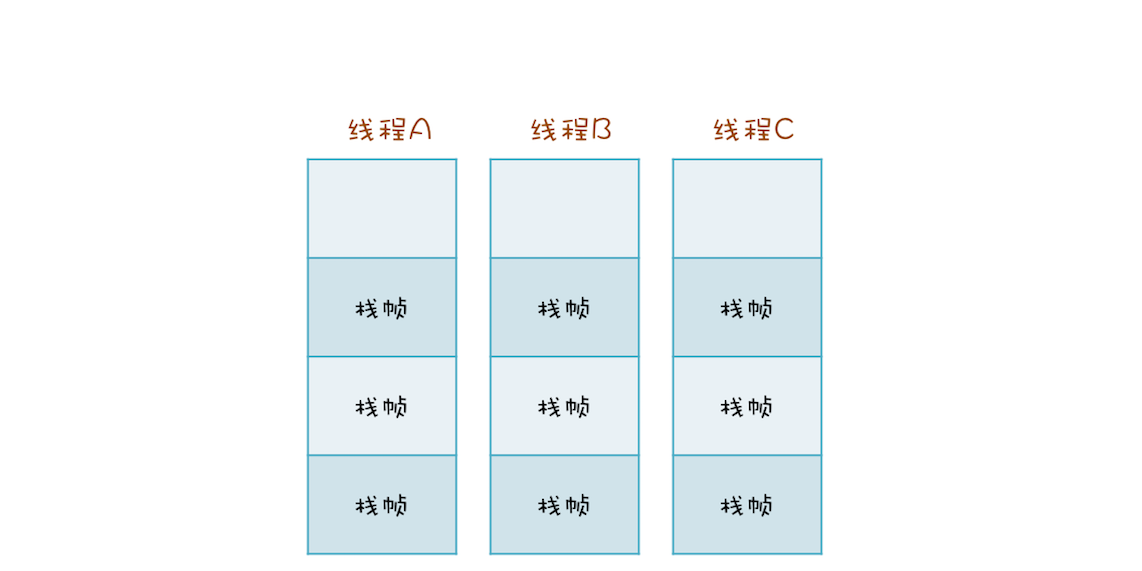
调用栈与线程
每个线程都有自己独立的调用栈
线程封闭
线程封闭,比较官方的解释是:仅在单线程内访问数据。方法里的局部变量,因为不会和其他线程共享就是线程封闭。
采用线程封闭技术的案例非常多,例如从数据库连接池里获取的连接 Connection,在 JDBC 规范里并没有要求这个 Connection 必须是线程安全的。数据库连接池通过线程封闭技术,保证一个 Connection 一旦被一个线程获取之后,在这个线程关闭 Connection 之前的这段时间里,不会再分配给其他线程,从而保证了 Connection 不会有并发问题。
课后思考题
递归调用太深,可能导致栈溢出。你思考一下原因是什么?有哪些解决方案呢?
每调用一次方法就会在栈内创建一个栈帧,方法结束就弹出栈帧,但是栈的大小不是无限大的。解决办法:1.用循环替代递归(DFS -> BFS) 2.限制递归次数 3.使用尾递归,尾递归是指在方法返回时只调用自己本身,且不能包含表达式。
12 | 如何用面向对象思想写好并发程序?
封装共享变量
面向对象思想里面有一个很重要的特性是封装,封装的通俗解释就是将属性和实现细节封装在对象内部,外界对象只能通过目标对象提供的公共方法来间接访问这些内部属性。利用面向对象思想写并发程序的思路,将共享变量作为对象属性封装在内部,对所有公共方法制定并发访问策略。
识别共享变量间的约束条件
共享变量之间的约束条件,反映在代码里,基本上都会有 if 语句,所以,一定要特别注意竞态条件。
制定并发访问策略
- 避免共享:避免共享的技术主要是利于线程本地存储以及为每个任务分配独立的线程。
- 不变模式:这个在 Java 领域应用的很少,但在其他领域却有着广泛的应用,例如 Actor 模式、CSP 模式以及函数式编程的基础都是不变模式。
- 管程及其他同步工具:Java 领域万能的解决方案是管程,但是对于很多特定场景,使用 Java 并发包提供的读写锁、并发容器等同步工具会更好。
13 | 理论基础模块热点问题答疑

若有收获,就点个赞吧
0 人点赞
