V2.0
直接上脑图: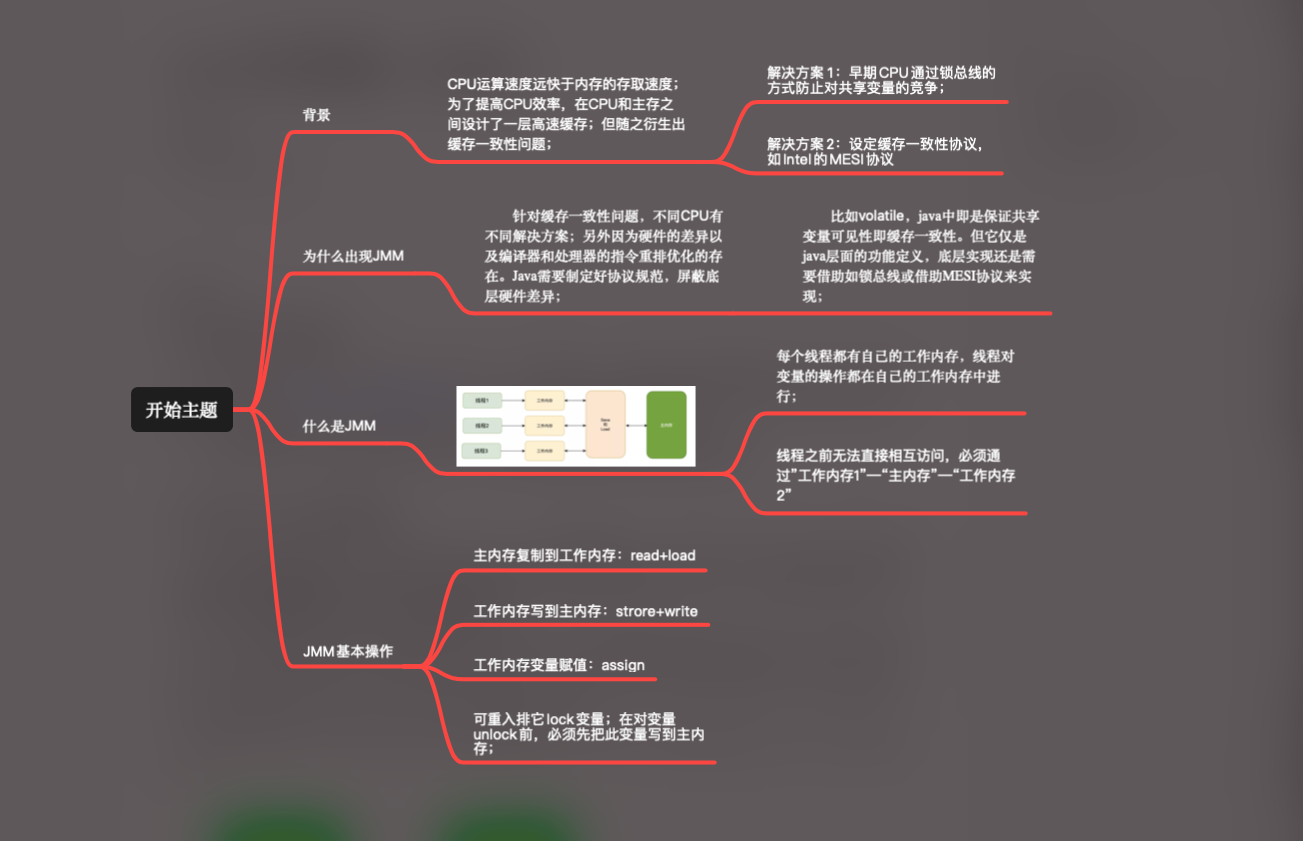
[1] 当面试官问起Java内存模型[OL].https://mp.weixin.qq.com/s/Xk1rNCc7m-38S75oOsl4tg
V1.0
什么是内存模型
内存模型是为了解决多线程下”非可见性”、”非有序性”、”非原子性”的问题而提出的(关于多线程这些问题,可以查看《java实战编程》01章)。为了保证共享内存的正确性(可见性、有序性、原子性),内存模型定义了共享内存系统中多线程程序读写操作行为的规范。
内存模型解决并发问题主要采用两种方式:限制处理器优化和使用内存屏障。
什么是Java内存模型
Java程序是需要运行在Java虚拟机上面的,Java内存模型(Java Memory Model ,JMM)就是一种符合内存模型规范的,屏蔽了各种硬件和操作系统的访问差异的,保证了Java程序在各种平台下对内存的访问都能保证效果一致的机制及规范。
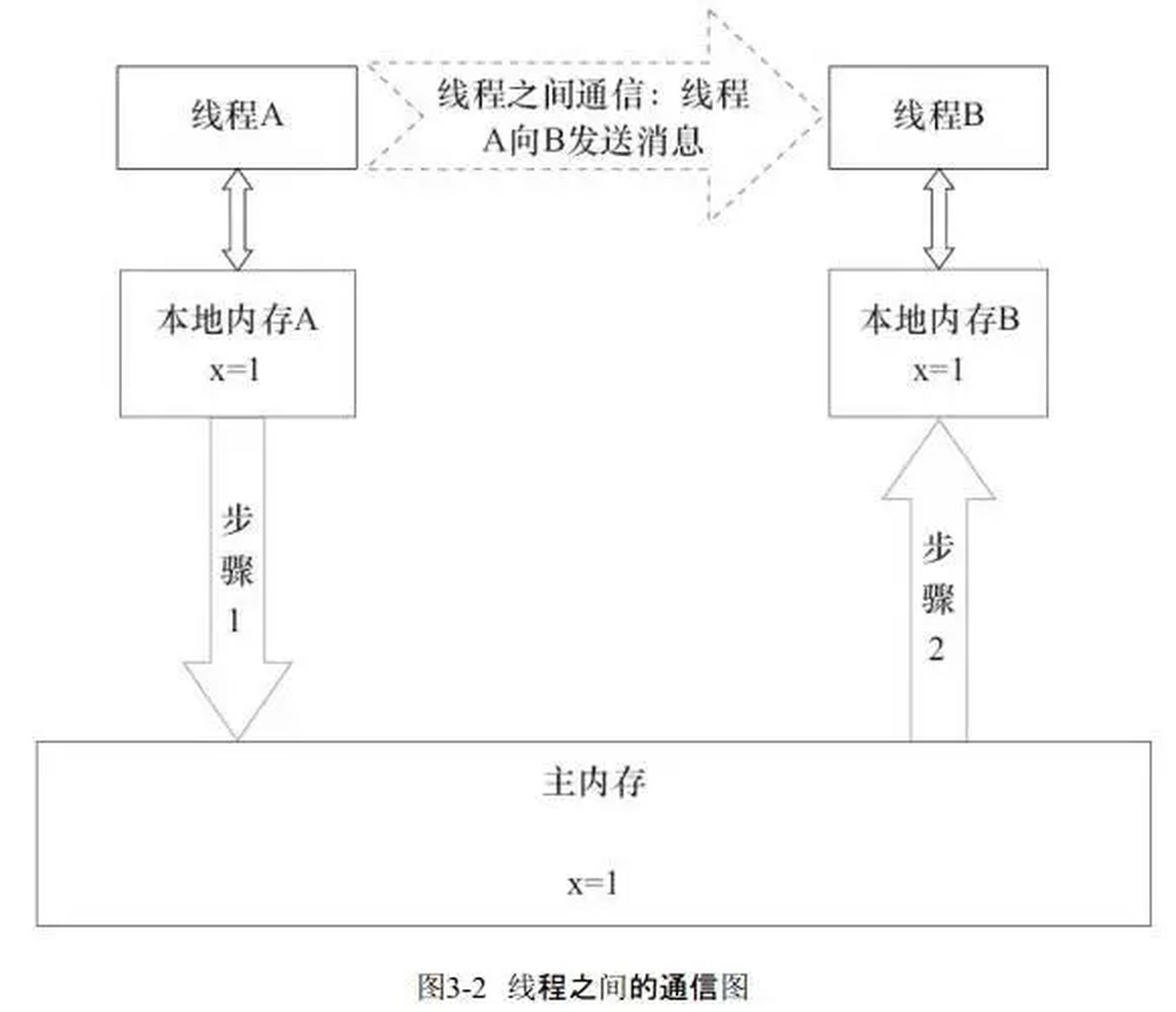
Java内存模型规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存,线程的工作内存中保存了该线程中是用到的变量的主内存副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量的传递均需要自己的工作内存和主存之间进行数据同步进行。
而JMM就作用于工作内存和主存之间数据同步过程。他规定了如何做数据同步以及什么时候做数据同步。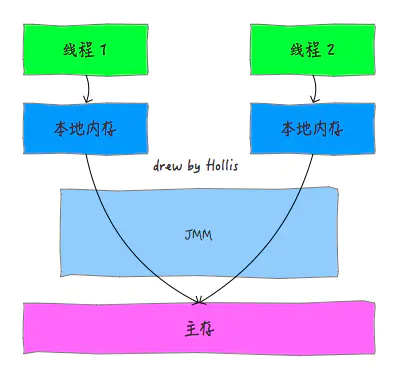
特别需要注意的是,主内存和工作内存与JVM内存结构中的Java堆、栈、方法区等并不是同一个层次的内存划分,无法直接类比。《深入理解Java虚拟机》中认为,如果一定要勉强对应起来的话,从变量、主内存、工作内存的定义来看,主内存主要对应于Java堆中的对象实例数据部分。工作内存则对应于虚拟机栈中的部分区域。
所以,再来总结下,JMM是一种规范,目的是解决由于多线程通过共享内存进行通信时,存在的本地内存数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行等带来的问题。
Java内存模型定义了以下八种操作
- lock(锁定):作用于主内存的变量,把一个变量标识为一条线程独占状态。
- unlock(解锁):作用于主内存变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
- read(读取):作用于主内存变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的load动作使用
- load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
- use(使用):作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
- assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
- store(存储):作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作。
- write(写入):作用于主内存的变量,它把store操作从工作内存中一个变量的值传送到主内存的变量中。
什么时候进行主内存和工作内存的同步,那么就涉及到happend-before原则,具体参看《java实战编程》02 另外此处的工作线程,我更倾向直白地说是cpu缓存。 TLAB是为了解决指针碰撞,让每个线程有私有的分配指针,即私有区域;所以线程本身是没内存概念的。
Java内存模型的实现
在Java中提供了一系列和并发处理相关的关键字,比如volatile、synchronized、final、concurren包等。其实这些就是Java内存模型封装了底层的实现后提供给程序员使用的一些关键字。
在开发多线程的代码的时候,我们可以直接使用synchronized等关键字来控制并发,从来就不需要关心底层的编译器优化、缓存一致性等问题。所以,Java内存模型,除了定义了一套规范,还提供了一系列原语,封装了底层实现后,供开发者直接使用。

若有收获,就点个赞吧
0 人点赞
