ThreadPool
组成部分
一个线程池包括以下四个基本组成部分:
- 线程池管理器(ThreadPool):用于创建并管理线程池,包括 创建线程池,销毁线程池,添加新任务;
- 工作线程(PoolWorker):线程池中线程,在没有任务时处于等待状态,可以循环的执行任务;
- 任务接口(Task):每个任务必须实现的接口,以供工作线程调度任务的执行,它主要规定了任务的入口,任务执行完后的收尾工作,任务的执行状态等;
- 任务队列(taskQueue):用于存放没有处理的任务。提供一种缓冲机制。
工作方式
线程池有一个工作队列,队列中包含了要分配给各线程的工作。当线程空闲时,就会从队列中认领工作。由于线程资源的创建与销毁开销很大,所以ThreadPool允许线程的重用,减少创建与销毁的次数,提高效率。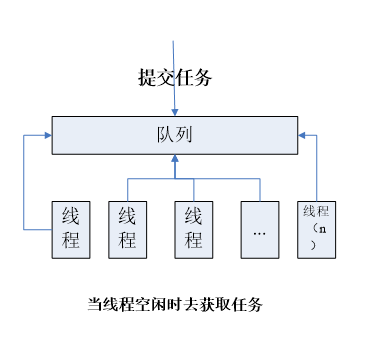
线程池任务执行流程:
- 当线程池小于corePoolSize时,新提交任务将创建一个新线程执行任务,即使此时线程池中存在空闲线程。
- 当线程池达到corePoolSize时,新提交任务将被放入workQueue中,等待线程池中任务调度执行
- 当workQueue已满,且maximumPoolSize>corePoolSize时,新提交任务会创建新线程执行任务
- 当提交任务数超过maximumPoolSize时,新提交任务由RejectedExecutionHandler处理
- 当线程池中超过corePoolSize线程,空闲时间达到keepAliveTime时,关闭空闲线程
- 当设置allowCoreThreadTimeOut(true)时,线程池中corePoolSize线程空闲时间达到keepAliveTime也将关闭
一般如果线程池任务队列采用LinkedBlockingQueue队列的话,那么不会拒绝任何任务(因为队列大小没有限制),这种情况下,ThreadPoolExecutor最多仅会按照最小线程数来创建线程,也就是说线程池大小被忽略了。 如果线程池任务队列采用ArrayBlockingQueue队列的话,那么ThreadPoolExecutor将会采取一个非常负责的算法,比如假定线程池的最小线程数为4,最大为8所用的ArrayBlockingQueue最大为10。随着任务到达并被放到队列中,线程池中最多运行4个线程(即最小线程数)。即使队列完全填满,也就是说有10个处于等待状态的任务,ThreadPoolExecutor也只会利用4个线程。如果队列已满,而又有新任务进来,此时才会启动一个新线程,这里不会因为队列已满而拒接该任务,相反会启动一个新线程。新线程会运行队列中的第一个任务,为新来的任务腾出空间。 这个算法背后的理念是:该池大部分时间仅使用核心线程(4个),即使有适量的任务在队列中等待运行。这时线程池就可以用作节流阀。如果挤压的请求变得非常多,这时该池就会尝试运行更多的线程来清理;这时第二个节流阀—最大线程数就起作用了。
常见类型
newCachedThreadPool
可缓存线程池程。
- 底层:返回ThreadPoolExecutor实例,corePoolSize为0;maximumPoolSize为Integer.MAX_VALUE;keepAliveTime为60L;unit为TimeUnit.SECONDS;workQueue为SynchronousQueue(同步队列)
- 通俗:当有新任务到来,则插入到SynchronousQueue中,由于SynchronousQueue是同步队列,因此会在池中寻找可用线程来执行,若有可以线程则执行,若没有可用线程则创建一个线程来执行该任务;若池中线程空闲时间超过指定大小,则该线程会被销毁。
-
newFixedThreadPool
定长线程池。
底层:返回ThreadPoolExecutor实例,接收参数为所设定线程数量nThread,corePoolSize为nThread,maximumPoolSize为nThread;keepAliveTime为0L(不限时);unit为:TimeUnit.MILLISECONDS;WorkQueue为:new LinkedBlockingQueue
()无解阻塞队列 - 通俗:创建可容纳固定数量线程的池子,每隔线程的存活时间是无限的,当池子满了就不在添加线程了;如果池中的所有线程均在繁忙状态,对于新任务会进入阻塞队列中(无界的阻塞队列)
-
newScheduledThreadPool
底层:创建ScheduledThreadPoolExecutor实例,corePoolSize为传递来的参数,maximumPoolSize为Integer.MAX_VALUE;keepAliveTime为0;unit为:TimeUnit.NANOSECONDS;workQueue为:new DelayedWorkQueue() 一个按超时时间升序排序的队列
- 通俗:创建一个固定大小的线程池,线程池内线程存活时间无限制,线程池可以支持定时及周期性任务执行,如果所有线程均处于繁忙状态,对于新任务会进入DelayedWorkQueue队列中,这是一种按照超时时间排序的队列结构
-
newSingleThreadExecutor
定长线程池,支持定时及周期性任务执行。
底层:FinalizableDelegatedExecutorService包装的ThreadPoolExecutor实例,corePoolSize为1;maximumPoolSize为1;keepAliveTime为0L;unit为:TimeUnit.MILLISECONDS;workQueue为:new LinkedBlockingQueue
()无解阻塞队列 - 通俗:创建只有一个线程的线程池,且线程的存活时间是无限的;当该线程正繁忙时,对于新任务会进入阻塞队列中(无界的阻塞队列)
-
任务队列
BlockingQueue
任务队列(BlockingQueue)指存放被提交但尚未被执行的任务的队列。包括以下几种类型:直接提交的、有界的、无界的、优先任务队列。直接提交的任务队列(SynchronousQueue)
- SynchronousQueue没有容量。
提交的任务不会被真实的保存在队列中,而总是将新任务提交给线程执行。如果没有空闲的线程,则尝试创建新的线程。如果线程数大于最大值maximumPoolSize,则执行拒绝策略。
有界的任务队列(ArrayBlockingQueue)
创建队列时,指定队列的最大容量。
- 若有新的任务要执行,如果线程池中的线程数小于corePoolSize,则会优先创建新的线程。若大于corePoolSize,则会将新任务加入到等待队列中。
若等待队列已满,无法加入。如果总线程数不大于线程数最大值maximumPoolSize,则创建新的线程执行任务。若大于maximumPoolSize,则执行拒绝策略。
无界的任务队列(LinkedBlockingQueue)
与有界队列相比,除非系统资源耗尽,否则不存在任务入队失败的情况。
- 若有新的任务要执行,如果线程池中的线程数小于corePoolSize,线程池会创建新的线程。若大于corePoolSize,此时又没有空闲的线程资源,则任务直接进入等待队列。
- 当线程池中的线程数达到corePoolSize后,线程池不会创建新的线程。
- 若任务创建和处理的速度差异很大,无界队列将保持快速增长,直到耗尽系统内存。
使用无界队列将导致在所有 corePoolSize 线程都忙时,新任务在队列中等待。这样,创建的线程就不会超过 corePoolSize(因此,maximumPoolSize 的值也就无效了)。当每个任务完全独立于其他任务,即任务执行互不影响时,适合于使用无界队列;例如,在 Web 页服务器中。这种排队可用于处理瞬态突发请求,当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
优先任务队列(PriorityBlockingQueue)
带有执行优先级的队列。是一个特殊的无界队列。
- ArrayBlockingQueue和LinkedBlockingQueue都是按照先进先出算法来处理任务。而PriorityBlockingQueue可根据任务自身的优先级顺序先后执行(总是确保高优先级的任务先执行)。
延时任务队列(DelayedWorkQueue)
static class DelayedWorkQueue extends AbstractQueue<Runnable>implements BlockingQueue<Runnable> {...}
ForkJoinPool
组成类
- ForkJoinPool:充当fork/join框架里面的管理者,最原始的任务都要交给它才能处理。它负责控制整个fork/join有多少个workerThread,workerThread的创建,激活都是由它来掌控。它还负责workQueue队列的创建和分配,每当创建一个workerThread,它负责分配相应的workQueue。然后它把接到的活都交给workerThread去处理,它可以说是整个frok/join的容器。
- ForkJoinWorkerThread:fork/join里面真正干活的”工人”,本质是一个线程。里面有一个ForkJoinPool.WorkQueue的队列存放着它要干的活,接活之前它要向ForkJoinPool注册(registerWorker),拿到相应的workQueue。然后就从workQueue里面拿任务出来处理。它是依附于ForkJoinPool而存活,如果ForkJoinPool的销毁了,它也会跟着结束。
- ForkJoinPool.WorkQueue: 双端队列就是它,它负责存储接收的任务。
- ForkJoinTask:代表fork/join里面任务类型,我们一般用它的两个子类RecursiveTask、RecursiveAction。这两个区别在于RecursiveTask任务是有返回值,RecursiveAction没有返回值。任务的处理逻辑包括任务的切分都集中在compute()方法里面。
工作方式
使用一种分治算法,递归地将任务分割成更小的子任务,其中阈值可配置,然后把子任务分配给不同的线程执行并发执行,最后再把结果组合起来。[z1] 该用法常见于数组与集合的运算。
由于提交的任务不一定能够递归地分割成ForkJoinTask,且ForkJoinTask执行时间不等长,所以ForkJoinPool使用一种工作窃取的算法,允许空闲的线程“窃取”分配给另一个线程的工作。由于工作无法平均分配并执行。所以工作窃取算法能更高效地利用硬件资源。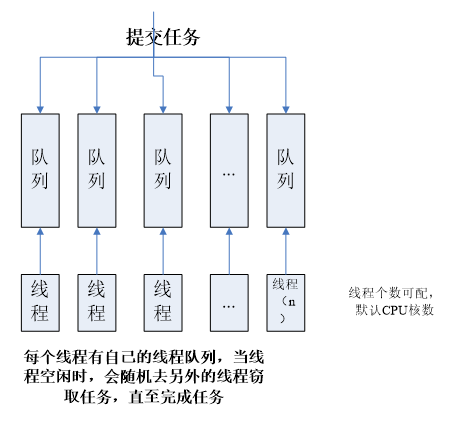
应用场景
ThreadPool:多见于线程并发,阻塞时延比较长的,这种线程池比较常用,一般设置的线程个数根据业务性能要求会比较多。 ForkJoinPool:特点是少量线程完成大量任务,一般用于非阻塞的,能快速处理的业务,或阻塞时延比较少的

若有收获,就点个赞吧
0 人点赞
