33 | 我查这么多数据,会不会把数据库内存打爆?
由于 MySQL 采用的是边算边发的逻辑,因此对于数据量很大的查询结果来说,不会在 server 端保存完整的结果集。所以,如果客户端读结果不及时,会堵住 MySQL 的查询过程,但是不会把内存打爆。
- 获取一行,写到 net_buffer 中。这块内存的大小是由参数 net_buffer_length 定义的,默认是 16k。
- 重复获取行,直到 net_buffer 写满,调用网络接口发出去。
- 如果发送成功,就清空 net_buffer,然后继续取下一行,并写入 net_buffer。
- 如果发送函数返回 EAGAIN 或 WSAEWOULDBLOCK,就表示本地网络栈(socket send buffer)写满了,进入等待。直到网络栈重新可写,再继续发送。
sending data=正在执行这条语句;sending to client=正在把结果集返回给用户
全表扫描对 InnoDB 的影响
Buffer Pool 对查询的加速效果,依赖于一个重要的指标,即:内存命中率。InnoDB 内存管理用的是最近最少使用 (Least Recently Used, LRU) 算法的改进版本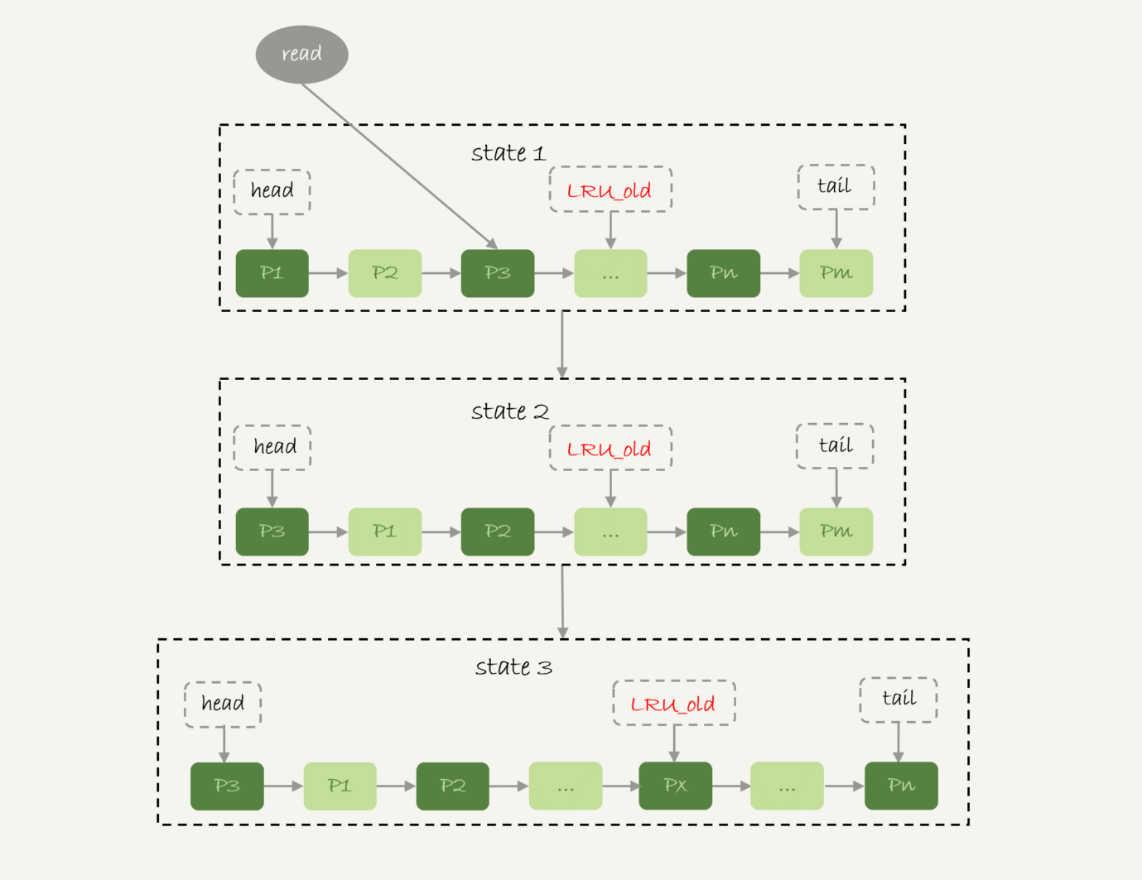
在 InnoDB 实现上,按照 5:3 的比例把整个 LRU 链表分成了 young 区域和 old 区域。图中 LRU_old 指向的就是 old 区域的第一个位置,是整个链表的 5/8 处。也就是说,靠近链表头部的 5/8 是 young 区域,靠近链表尾部的 3/8 是 old 区域。
- 扫描过程中,需要新插入的数据页,都被放到 old 区域 ;
- 一个数据页里面有多条记录,这个数据页会被多次访问到,但由于是顺序扫描,这个数据页第一次被访问和最后一次被访问的时间间隔不会超过 1 秒,因此还是会被保留在 old 区域;
- 再继续扫描后续的数据,之前的这个数据页之后也不会再被访问到,于是始终没有机会移到链表头部(也就是 young 区域),很快就会被淘汰出去。
34 | 到底可不可以使用join?
Index Nested-Loop Join
“可以使用被驱动表的索引”。
可以看到,在这条语句里,被驱动表 t2 的字段 a 上有索引,join 过程用上了这个索引,因此这个语句的执行流程是这样的:
- 从表 t1 中读入一行数据 R;
- 从数据行 R 中,取出 a 字段到表 t2 里去查找;
- 取出表 t2 中满足条件的行,跟 R 组成一行,作为结果集的一部分;
- 重复执行步骤 1 到 3,直到表 t1 的末尾循环结束。
这个过程是先遍历表 t1,然后根据从表 t1 中取出的每行数据中的 a 值,去表 t2 中查找满足条件的记录。在形式上,这个过程就跟我们写程序时的嵌套查询类似,并且可以用上被驱动表的索引,所以我们称之为“Index Nested-Loop Join”,简称 NLJ。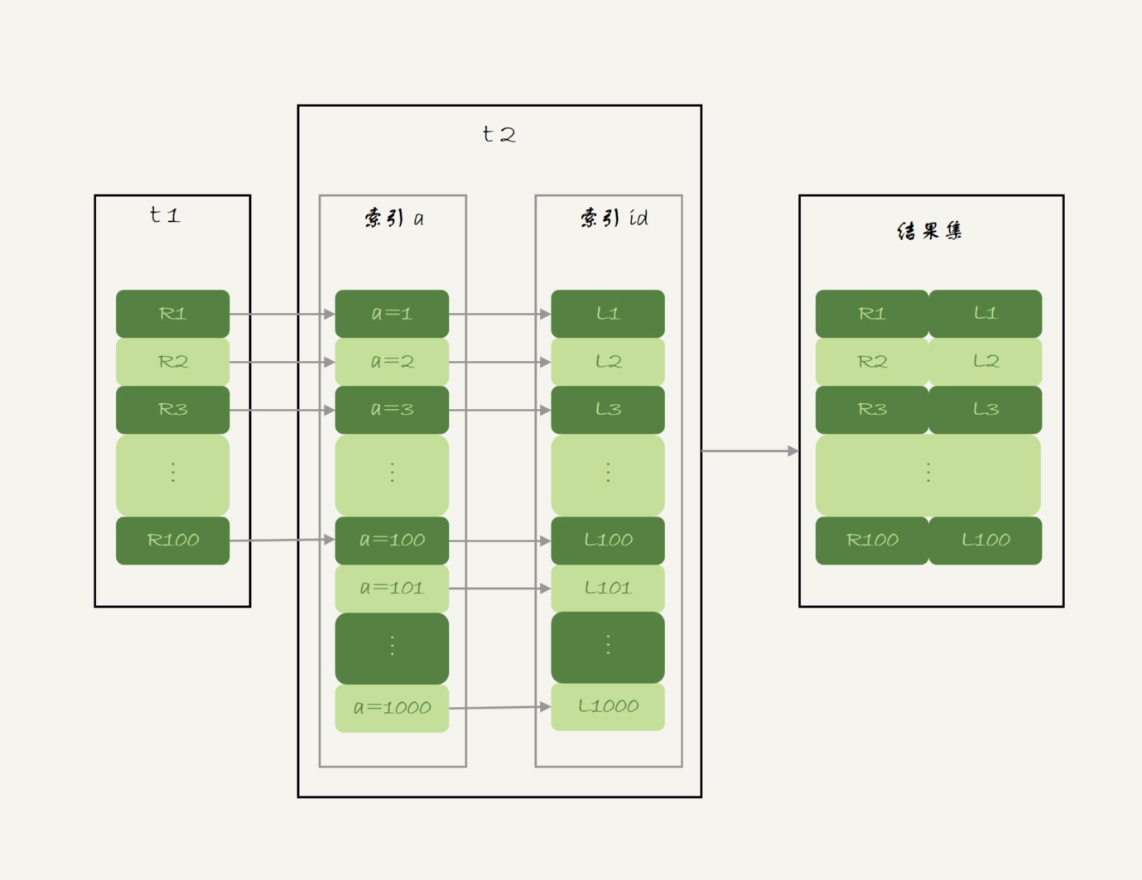
怎么选择驱动表? 在这个 join 语句执行过程中,驱动表是走全表扫描,而被驱动表是走树搜索。 假设被驱动表的行数是 M。每次在被驱动表查一行数据,要先搜索索引 a,再搜索主键索引。每次搜索一棵树近似复杂度是以 2 为底的 M 的对数,记为 log2M,所以在被驱动表上查一行的时间复杂度是 2log2M。 假设驱动表的行数是 N,执行过程就要扫描驱动表 N 行,然后对于每一行,到被驱动表上匹配一次。因此整个执行过程,近似复杂度是 N + N2*log2M。显然,N 对扫描行数的影响更大,因此应该让小表来做驱动表。
Simple Nested-Loop Join
被驱动表没有可用的索引
这个 SQL 请求就要扫描表 t2 多达 100 次,总共扫描 100*1000=10 万行。这还只是两个小表,如果 t1 和 t2 都是 10 万行的表(当然了,这也还是属于小表的范围),就要扫描 100 亿行,这个算法看上去太“笨重”了。
当然,MySQL 也没有使用这个 Simple Nested-Loop Join 算法,而是使用了另一个叫作“Block Nested-Loop Join”的算法,简称 BNL。
Block Nested-Loop Join
join buffer大/一次能加载进内存
被驱动表上没有可用的索引,算法的流程是这样的:
- 把表 t1 的数据读入线程内存 join_buffer 中,由于我们这个语句中写的是 select *,因此是把整个表 t1 放入了内存;
- 扫描表 t2,把表 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回。

在这个过程中,对表 t1 和 t2 都做了一次全表扫描,因此总的扫描行数是 1100。由于 join_buffer 是以无序数组的方式组织的,因此对表 t2 中的每一行,都要做 100 次判断,总共需要在内存中做的判断次数是:100*1000=10 万次。
使用 Simple Nested-Loop Join 算法进行查询,扫描行数也是 10 万行。因此,从时间复杂度上来说,这两个算法是一样的。但是,Block Nested-Loop Join 算法的这 10 万次判断是内存操作,速度上会快很多,性能也更好。
假设小表的行数是 N,大表的行数是 M,那么在这个算法里:
- 两个表都做一次全表扫描,所以总的扫描行数是 M+N;
- 内存中的判断次数是 M*N。
可以看到,调换这两个算式中的 M 和 N 没差别,因此这时候选择大表还是小表做驱动表,执行耗时是一样的。
join buffer不足分段加载内存
执行过程就变成了:
- 扫描表 t1,顺序读取数据行放入 join_buffer 中,放完第 88 行 join_buffer 满了,继续第 2 步;
- 扫描表 t2,把 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回;
- 清空 join_buffer;
- 继续扫描表 t1,顺序读取最后的 12 行数据放入 join_buffer 中,继续执行第 2 步。
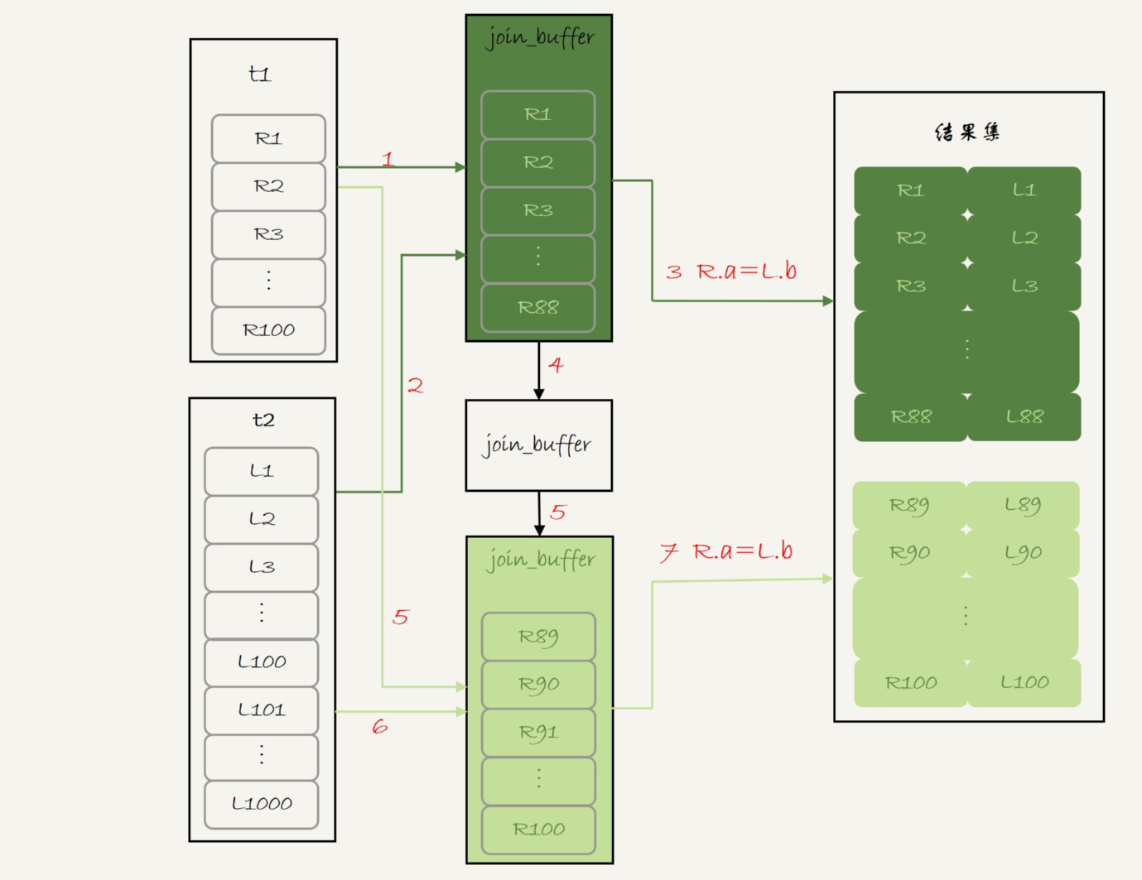
这个流程才体现出了这个算法名字中“Block”的由来,表示“分块去 join”。
假设,驱动表的数据行数是 N,需要分 K 段才能完成算法流程,被驱动表的数据行数是 M。注意,这里的 K 不是常数,N 越大 K 就会越大,因此把 K 表示为λ*N,显然λ的取值范围是 (0,1)。
所以,在这个算法的执行过程中:
- 扫描行数是 N+λNM;
- 内存判断 N*M 次。
当然,你会发现,在 N+λNM 这个式子里,λ才是影响扫描行数的关键因素,这个值越小越好。
刚刚我们说了 N 越大,分段数 K 越大。那么,N 固定的时候,什么参数会影响 K 的大小呢?(也就是λ的大小)答案是 join_buffer_size。join_buffer_size 越大,一次可以放入的行越多,分成的段数也就越少,对被驱动表的全表扫描次数就越少。
这就是为什么,你可能会看到一些建议告诉你,如果你的 join 语句很慢,就把 join_buffer_size 改大。
什么叫作“小表”
- 过滤后实际行数
- 参与查询的字段个数
在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过滤完成之后,计算参与 join 的各个字段的总数据量,数据量小的那个表,就是“小表”,应该作为驱动表。
43 | 要不要使用分区表?
CREATE TABLE `t` (`ftime` datetime NOT NULL,`c` int(11) DEFAULT NULL,KEY (`ftime`)) ENGINE=InnoDB DEFAULT CHARSET=latin1PARTITION BY RANGE (YEAR(ftime))(PARTITION p_2017 VALUES LESS THAN (2017) ENGINE = InnoDB,PARTITION p_2018 VALUES LESS THAN (2018) ENGINE = InnoDB,PARTITION p_2019 VALUES LESS THAN (2019) ENGINE = InnoDB,PARTITION p_others VALUES LESS THAN MAXVALUE ENGINE = InnoDB);insert into t values('2017-4-1',1),('2018-4-1',1);
对于引擎层来说,是4个表;对于Server层来说,这是1个表。
缺点:在 server 层,认为这是同一张表,因此所有分区共用同一个 MDL 锁,在做 DDL 的时候,影响会更大(相比手工分区,代码业务逻辑层分区)。
优点:分区表对业务透明
考虑点:
- 分区并不是越细越好。实际上,单表或者单分区的数据一千万行,只要没有特别大的索引,对于现在的硬件能力来说都已经是小表了。
- 查询需要跨多个分区取数据,查询性能就会比较慢,基本上就不是分区表本身的问题,而是数据量的问题或者说是使用方式的问题了。

若有收获,就点个赞吧
0 人点赞
