摘录自:为什么ElasticSearch比MySQL更适合全文索引
ps:文中对mysql联合索引索引的理解我认为有偏颇;另外根据mysql的join过程与es文中提及的跳表和bitmap方式,只要优化的好,虽然取交集的逻辑顺序查询没有es的交集方式好,但不一定慢(前提是内存足够大,mysql完全走内存)
基本术语
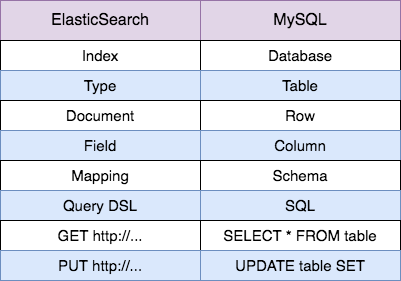
- ElasticSearch 中的类型 Type 类似于 MySQL 中的表 Table;需要注意,这个概念在 7.x 版本中被完全删除,而且概念上和 Table 也有较大差异;
- ElasticSearch 中的文档 Document 类似于 MySQL 中的数据行 Row,每个文档由多个字段 Filed 组成,这个Filed 就类似于 MySQL 的 Column;
- ElasticSearch 中的映射 Mapping 是对索引库中的索引字段及其数据类型进行定义,类似于关系型数据库中的表结构 Schema;
- ElasticSearch 使用自己的领域语言 Query DSL 来进行增删改查,而 MySQL 使用 SQL 语言进行上诉操作。es6及以上支持sql语义
倒排索引
倒排索引按照维基百科的描述,是存储文档内容到文档位置映射关系的数据库索引结构。
以书籍检索为例,假设有以下数据,每一行就是一个 Document,每个 Document 由 id,ISBN 号,作者名称和评分组成: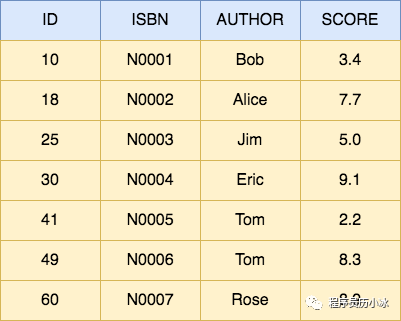
给上述数据按照 ISBN 和 Author 建立的倒排索引如下所示。倒排索引是每个字段分开建立的,相互独立。有两个专门的术语,分别是索引 Term 和倒排表 Posting List。字段的值就是 Term,比如 N0007,而 Term 对应的文档 ID 的列表就是 Posting List,对应图中红色的部分。
一般 Term 都是按照顺序排序的,比如 Author 名称就是按照字母序进行了排序,排序之后,当我们搜索某一个 Term 时,就不需要从头遍历,而是采用二分查找。一系列排序后的 Term 就组成了索引表 Term Dictionary。但是 Term Dictionary 往往很大,无法完整放入内存,这是为了更快的查询,还需要再给它创建索引,也就是 Term Index 。
ElasticSearch 使用 Burst-Trie 结构来实现 Term Index,它是一种前缀树 Trie 的一种变种,它主要是将后缀进行了压缩,降低了Trie的高度,从而获取更好查询性能。
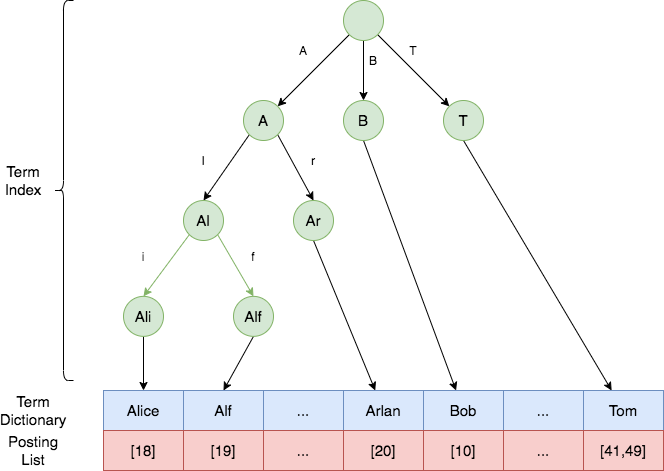
一般来说,Term Index 都是全部缓存在内存中,查询时,先通过其快速定位到 Term Dictionary 对应的大致范围,然后再进行磁盘读取查找对应的 Term,这样就大大减少了磁盘 I/O 的次数。
联合索引查询
比如上述书籍例子中,我们需要查询评分等于2.2并且作者名称叫 Tom的书籍。理论上,我们只需要分别按照 Score 和 Author 字段的倒排索引进行查询,获取响应的 Posting List,再将其做交集合并即可。
关于交集合并, ElasticSearch 则支持使用跳表 Skip List和 Bitset 的方式将数据集进行合并。
- 使用 Skip List 结构,同时遍历 Score 和 Author 查询出来的 Posting List,利用其 Skip List 结构,相互跳跃对比,得出合集。
- 使用 Bitset 结构,对 Score 和 Author 查询出来的 Posting List 的值计算出各自的 Bitset,然后进行 AND 操作。
跳表合并策略
ElasticSearch 在存储 Posting List 数据时,就保存了对应的多级跳表结构响应的数据,这也体现了其空间换时间的基本思想。
比如,按照 Score 查出来的 Posting List 为[2,3,4,5,7,9,10,11],按照 Author 查出来的结果为 [3,8,9,12,13],则二者的跳表结构如下图所示。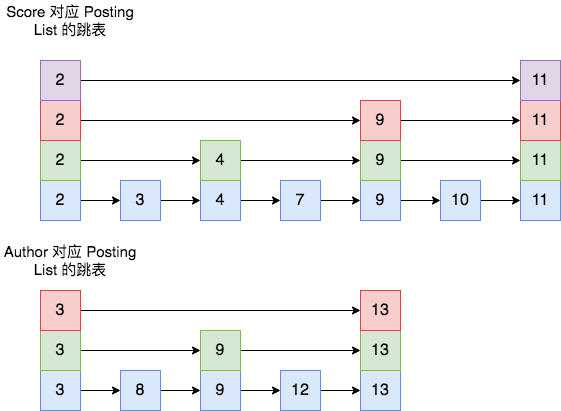
具体合并过程则是先选最短的 posting list,也就是 Author 的结果集,从其最小的一个 id 开始,将其作为当前最大值。然后依次剩余 posting list 中查找大于或等于该值的位置。在查询过程中,每个 posting list 都可以根据当前 id 通过 skip list 快速跳过不符合的 id 值,加速整个合并取交集的过程。
跳表的基本概念,它是一种可以进行二分查找的有序链表。跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。首先在最高级索引上查找最后一个小于当前查找元素的位置,然后再跳到次高级索引继续查找,直到跳到最底层为止,通过这种方式,加快了查询的速度。
Bitset 合并策略
将一些查询条件对应的结果集 posting list 进行内存缓存,也就是所谓的 Filter Cache,为了后续再次复用。
为了减少内存缓存所消耗的内存空间大小,ElasticSearch 没有使用单纯的数组和 bitset 来存储 posting list,而是使用要压缩效率更高的 Roaring Bitmap。
给定含有40亿个不重复的位于[0, 2^32 - 1]区间内的整数的集合,如何快速判定某个数是否在该集合内?
如果我们要使用 unsigned long 数组来存储它的话,也就需要消耗 40亿 * 32 位 = 160 Byte,大致是 16000 MB。
如果要使用位图 Bitset 来存储的话,即某个数位于原集合内,就将它对应的位图内的比特置为1,否则保持为0。这样只需要消耗 2 ^ 32 位 = 512 MB,这可只有原来的 3.2 % 左右。
但是,Bitset 也有其缺陷,也就是稀疏存储的问题,比如上述集合并不是 40亿,而是只有2,3个,那么 Bitset 中只有少数几位是1,其他位都是 0,但是它仍然占用了 512 MB。
而 RoaringBitmap 就是为了解决稀疏存储的问题。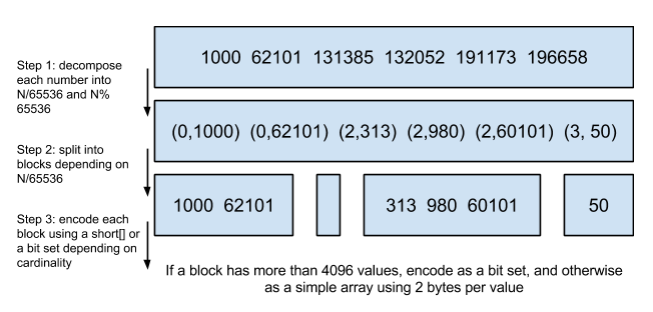
首先,如上图所示,计算出32位无符号整数和 65536 的除数和余数。其含义表示,将32位无符号整数按照高16位分桶,即最多可能有2^16=65536个桶,术语为 container。存储数据时,按照数据的高16位找到 container(找不到就会新建一个),再将低16位放入container中。也就是说,一个 RoaringBitmap 就是很多container的集合。
然后 container 内具体的存储结构要根据存入其内数据的基数来决定。
- 基数小于 2 ^ 12 次方即 4096时,使用unsigned short类型的有序数组来存储,最大消耗空间就是 8 KB。
- 基数大于 4096 时,则使用大小为 2 ^ 16 次方的普通 bitset 来存储,固定消耗 8 KB。当然,有些时候也会对 bitset 进行行程长度编码(RLE)压缩,进一步减少空间占用。

若有收获,就点个赞吧
0 人点赞
